深度学习中端到端(end-to-end)简要理解
端到端(end-to-end)简要理解
- 端到端
-
- 好处
- 不同领域的端到端
- 目标检测
-
-
- 非end-to-end方法
- end-to-end方法
- CV计算机视觉
- 语音识别
-
- 非端到端
- 端到端
-
- 参考
端到端
端到端指的是输入是原始数据,输出是最后的结果。而原来的输入端不是直接的原始数据(raw data),而是在原始数据中提取的特征(features)。这一点在图像问题上尤为突出,因为图像像素数太多,数据维度高,会产生维度灾难,所以原来一个思路是手工提取(hand-crafted functions)图像的一些关键特征,这实际就是就一个降维的过程。
经典机器学习方式是以人类的先验知识将raw数据预处理成feature,然后对feature进行分类。分类结果十分取决于feature的好坏。所以过去的机器学习专家将大部分时间花费在设计feature上。那时的机器学习有个更合适的名字叫feature engineering(特征工程)。
那么特征如何提取?特征提取的好坏异常关键,甚至比学习算法还重要,举个例子,对一系列人的数据分类,分类结果是性别,如果你提取的特征是头发的颜色,无论分类算法如何,分类效果都不会好,如果你提取的特征是头发的长短,这个特征就会好很多,但是还是会有错误,如果你提取了一个超强特征,比如染色体的数据,那你的分类基本就不会错了。
这就意味着,特征需要足够的经验去设计,这在数据量越来越大的情况下也越来越困难。于是就出现了端到端网络,特征可以自己去学习,所以特征提取这一步也就融入到算法当中,不需要人来干预了。
随着深度学习、神经网络的发展,让网络自己学习如何抓取feature效果更佳。由于多层神经网络被证明能够耦合任意非线性函数,通过一些配置能让网络去做以前需要人工参与的特征设计这些工作,然后配置合适的功能如classifier,regression,而现在神经网络可以通过配置layers的参数达到这些功能,整个输入到最终输出无需太多人工设置,从raw data到最终输出特征。于是兴起了representation learning。这种方式对数据的拟合更加灵活。
相对于深度学习,传统机器学习的流程往往由多个独立的模块组成,比如在一个典型的自然语言处理(Natural Language Processing)问题中,包括分词、词性标注、句法分析、语义分析等多个独立步骤,每个步骤是一个独立的任务,其结果的好坏会影响到下一步骤,从而影响整个训练的结果,这是非端到端的。
而深度学习模型在训练过程中,从输入端(输入数据)到输出端会得到一个预测结果,与真实结果相比较会得到一个误差,这个误差会在模型中的每一层传递(反向传播),每一层的表示都会根据这个误差来做调整,直到模型收敛或达到预期的效果才结束,这是端到端的。即,端到端的学习,就是把特征提取的任务也交给模型去做,直接输入原始数据或者经过些微预处理的数据,让模型自己进行特征提取。

好处
一个程序包括很多函数,一个做法是一个个实现这个函数,然后组成一个程序,另一个做法肯定是写成一个函数,在传统编程领域,后者一般是肯定会受到鄙视。但是在深度学习领域,更宽泛的说可微分编程领域,后者有极大的意义,它把所有模块放在一起,可以当成一个整体来训练,在前向推理的时候,可以一次性得到你想要的结果。这样做有什么意义?误差理论告诉我们误差传播的途径本身会导致误差的累积,多个阶段一定会导致误差累积,e2e训练能减少误差传播的途径,联合优化。
通过缩减人工预处理和后续处理,尽可能使模型从原始输入到最终输出,给模型更多可以根据数据自动调节的空间,增加模型的整体契合度。
不同领域的端到端
目标检测
非end-to-end方法
目前目标检测领域,效果最好,影响力最大的是RCNN框架,这种方法需要先在图像中提取可能含有目标的候选框(region proposal), 然后将这些候选框输入到CNN模型,让CNN判断候选框中是否真的有目标,以及目标的类别是什么。在我们看到的结果中,往往是类似与下图这种,在整幅图中用矩形框标记目标的位置和大小,并且告诉我们框中的物体是什么。
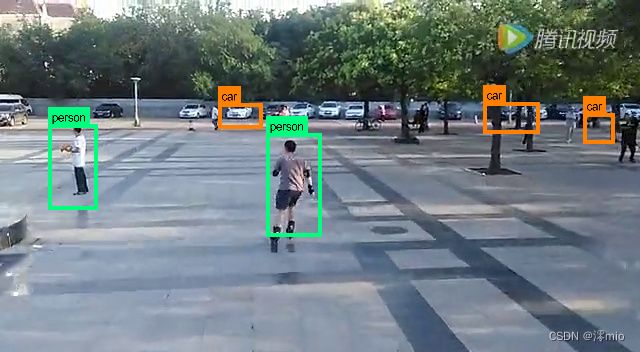
这种标记的过程有两部分组成,一是目标所在位置及大小,二是目标的类别。在整个算法中,目标位置和大小其实是包含在region proposal的过程里,而类别的判定则是在CNN中来判定的。
end-to-end方法
end-to-end方法的典型代表就是有名的yolo。前面的方法中,CNN本质的作用还是用来分类,定位的功能其并没有做到。而yolo这种方法就是只通过CNN网络,就能够实现目标的定位和识别。也就是原始图像输入到CNN网络中,直接输出图像中所有目标的位置和目标的类别。这种方法就是end-to-end(端对端)的方法,一端输入我的原始图像,一端输出我想得到的结果。只关心输入和输出,中间的步骤全部都不管。
CV计算机视觉
在图像领域,CNN就是一个很典型的端到端结构。输入图像,输出可以做分类,可以做补全,做各种任务。这之中的具体细节都不需要人工干预,这就是End-to-end。
对于CV视觉领域而言,end-to-end一词多用于基于视觉的机器控制方面,具体表现是,神经网络的输入为原始图片,神经网络的输出为(可以直接控制机器的)控制指令。
语音识别
非端到端
传统的语音识别系统,由声学模型、发音词典、语言模型。其中声学模型和语言模型是需要训练的。
这些模块的训练一般都是独立进行的,各有各的目标函数。
比如声学模型的训练目标是最大化训练语音的概率;语言模型的训练目标是最小化 困惑度(perplexity)。
由于各个模块在训练时不能互相取长补短,训练的目标函数又与系统整体的性能指标(一般是词错误率 WER)有偏差,这样训练出的网络往往达不到最优性能。
传统的语音识别需要把语音转换成语音特征向量,然后把这组向量通过机器学习,分类到各种音节上(根据语言模型),然后通过音节,还原出最大概率的语音原本要表达的单词,一般包括以下模块:
特征提取模块 (Feature Extraction):该模块的主要任务是从输入信号中提取特征,供声学模型处理。一般也包括了一些信号处理技术,尽可能降低环境噪声、说话人等因素对特征造成的影响,把语音变成向量。
声学模型 (Acoustic Model): 用于识别语音向量
发音词典 (Pronnuciation Dictionary):发音词典包含系统所能处理的词汇集及其发音。发音词典提供了声学模型与语言模型间的联系。
语言模型 (Language Model):语言模型对系统所针对的语言进行建模。
解码器 (Decoder):任务是对输入的信号,根据声学、语言模型及词典,寻找能够以最大概率输出该信号的词串。
传统的语音识别中的语音模型和语言模型是分别训练的,缺点是不一定能够总体上提高识别率。
端到端

端到端学习的思路则非常简单:音频→学习算法→转录结果;而现在,我们可以直接通过深度学习将语音直接对标到我们最终显示出来的文本。通过深度学习自己的特征学习功能来完成从特征提取到音节表达的整个过程。在给定了足够的有标注的训练数据时(语音数据以及对应的文本数据),端到端的语音识别方法的效果会很好。
端到端训练(end-to-end training):
一般指的是在训练好语言模型后,将声学模型和语言模型接在一起,以 WER 或它的一种近似为目标函数去训练声学模型。由于训练声学模型时要计算系统整体的输出,所以称为「端到端」训练。可以看出这种方法并没有彻底解决问题,因为语言模型还是独立训练的。
端到端模型(end-to-end models):
系统中不再有独立的声学模型、发音词典、语言模型等模块,而是从输入端(语音波形或特征序列)到输出端(单词或字符序列)直接用一个神经网络相连,让这个神经网络来承担原先所有模块的功能。典型的代表如使用 CTC 的 EESEN、使用注意力机制的 Listen, Attend and Spell [2]。这种模型非常简洁,但灵活性就差一些:一般来说用于训练语言模型的文本数据比较容易大量获取,但不与语音配对的文本数据无法用于训练端到端的模型。因此,端到端模型也常常再外接一个语言模型,用于在解码时调整候选输出的排名(rescoring)。
参考
https://www.cnblogs.com/zeze/p/7798080.html
https://blog.csdn.net/langb2014/article/details/53019350
https://www.zhihu.com/question/50454339