百度最强中文AI作画大模型
前言
最近文生图领域的发展可谓是分生水起,这主要是得益于最近大火的扩散模型,之前笔者也写过一篇关于文本生产3D模型的文章,大家感兴趣的可以穿梭:
https://zhuanlan.zhihu.com/p/570332906
今天要给大家介绍的这一篇paper是百度最新的文生图佳作:ERNIE-ViLG 2.0,其在diffusion的model基础上进行了两方面设计:融入语言和图像知识进行增强、混合降噪专家网络。
ERNIE-ViLG 2.0目前在文本生成图像公开权威评测集 MS-COCO取得了SOTA, 尤其是在中文领域展现出了超强优势。
论文链接:https://arxiv.org/pdf/2210.15257.pdf
体验链接:https://wenxin.baidu.com/ernie-vilg
demo
在开始之前先给大家展示几个demo,感受一波,学起来更有动力~
可以看到不论是轮廓还是上色都是很棒的,而且很细节的描述都能捕捉到,比如最后一幅画中的光从右边打来。
更多的demo大家感兴趣的话可以自己去体验体验~
方法
整体框架如下
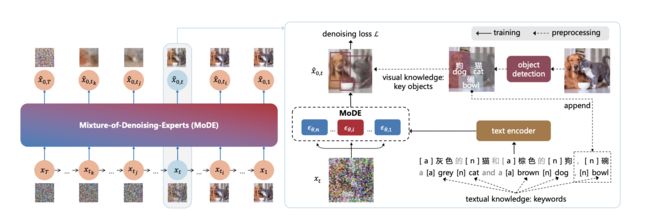
- 扩散模型
在开始介绍作者提出的创新点之前,不得不先介绍下扩散模型,作者是在其基础上针对性的设计了两点。
要详细介绍扩散模型的话,其实设计到很多数学知识,而他的思想逻辑实际上很好理解,基本上两句话就可以介绍清楚。
关于扩散模型这里就按照本篇paper中的介绍方式给大家从大的逻辑上介绍一下吧,如果有同学还是对细节更感兴趣,还是建议去看扩散模型的原paper或者其他大牛的讲解,现在扩散模型很火,网上资料多多,笔者就不再叙述了,也怕从根源上误导到大家。
它的过程大致就是:给图片不断的加噪声,然后再不断的去噪声。而这个噪声就是人为的取了一个最常见的数学分布:高斯噪声。
x就是图片的表征,每一步t都是在不断的叠加一个噪声,经过不断的叠加噪声(从高斯分布随机采样),图片就是越来越模糊。那么很明显,如果我们能够得到每一步的确切噪声,那么就能够回推出一开始的图片,也就是复原。
再解释一下这个逻辑:在随机叠加噪声的时候是随机采样的,而为了复原,我们需要训练一个去噪网络,而这个所谓的网络其实就是在拟合每一步这个随机采样的噪声值,因为拿到了噪声值就可以一步步往回推理直到复原。
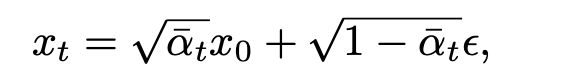
好了现在的重点变成了:怎么能够精确得到这些噪声呢?
那就是直接监督训练吧:
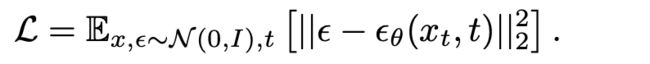
可以看到直接设计一个网络,然后每一步监督训练,具体的这个网络的输入是当前这一步对应的图片表征,输出就是这一步采样叠加的噪声。
有了这个训练好的模型,inference的时候便可以推理得到图片在t步的预测值
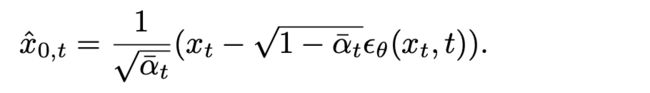
具体到没一步的推理往回推理公式:

上面就是扩散模型的去噪过程。
那上面说的“直接设计一个网络”中的网络是什么网络呢?答案是:U-Net。
它的核心是一个cross-modal attention网络
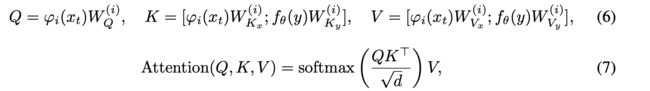
(x,y)分别代表一对图文训练pair,可以非常清晰的看到K、V是图文的concatenated表征,Q是图片的表征。
- 融入语言和图像知识进行增强
再经过前面的解释,这里我们正式的看一下作者提出的第一个设计:
(1)文本知识
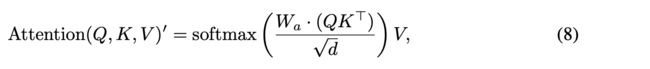
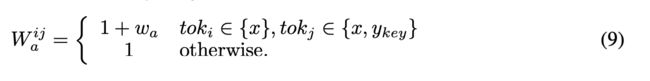
通过公式(8)可以看到在计算attention的时候,作者多加了一个权重W项,具体的它是一个可学习网络矩阵,其中的每一个具体元素值ij,代表着image tokens i和 text tokens j的权重。
可以看到如果是非关键token,它的值是1,如果是关键token那么就会累积一个可学习的权重。
具体的什么是关键token呢?作者这里考虑了形容词和名词,凡是形容词和名词的,会在对应的输入开头拼接一个[a]和[n],如上图中的“灰色的”和“猫”的开头。
(2)视觉知识
视觉知识这里,作者具体是采用了目标检测手段。
具体的融合手段是放在了上述拟合高斯噪声loss那里,如下:
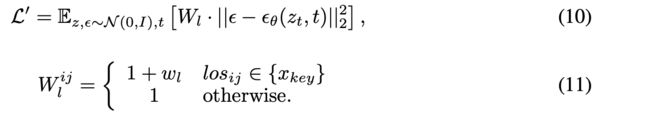
在之前的基础上,又是同样的手段即多加了一个权重W,同理如果对应的image和text token是关键物体(目标检测),那么就要着重惩罚此时的loss,也就是说这是关键物体,一定得给我画出来呀。
说到这里,就会遇到另外一个问题:图片中目标检测出来的物体,文本中没有对应的描述,这个时候怎么办?
那就强行在文本后面append追加上这个目标,如上图框架中的“碗”。
除此之外,为了进一步增加泛化性,作者还用了一个images-text的模型,通过图片生成对应的文本,用这个文本随机代替原先给扩散模型训练(images,text)pair中的text。
这样的话文本中会包含一些图片中的重要目标。
- 混合降噪专家网络
接下来接着第二点设计
这里就更好理解一点,看到扩散模型去噪那里,每一步都是用的同样的模型或者说同一套参数,这里其实每一步应该关注的点是不一样的,所以说应该个性化。
具体的作者这里每一步都对应自己的参数,而是进行了分组,每一组其实就是连续的几步step,同一个组内对应一套参数。
那具体多少组呢?也就是paper中提到的MoDE,多专家网络,其实就是多少组,可以想象得到理论上来说越多越个性化,越效果好。
实验
paper也做了很多实验和case分析,大家感兴趣的可以去详细看看,这里给一下设计的两个点的对应消融实验结果吧
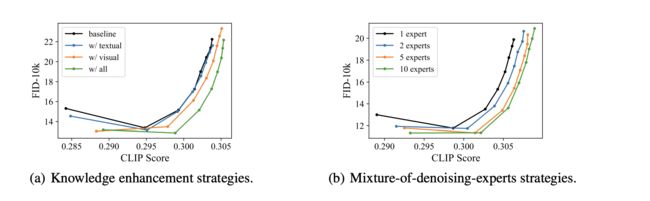
总结
融入知识是ERNIE系列的老手段了,也是起家的本领,怎么把更多更细粒度的知识融入到模型是ERNIE一直坚持创新的点,其已经在各个领域模型发光发热,大家对模型感兴趣的可以持续关注~
欢迎关注,下期再见啦~
知乎,csdn,github,微信公众号
本文由 mdnice 多平台发布