大数据集群监控体系架构
背景
企业级的数据集群往往有PB 级的数据、成百上千的各类型运算任务 在一套集群上运行。 所以它的维护是充满挑战的: 庞大的数据量、复杂的运算逻辑、相互关联的大数据组件、数以万计的运行任务 都是要克服的难点。 SRE 如果不想被动的话,就必须做好各式监控。预防风险、提前发现风险、然后分析问题、进而针对性的处理问题。
凡是成体量的分布式系统,一旦出现性能问题,往往很难在短时间内作出有效处理。 所以 监控要前置,有趋势预测、有风险评估 才行。
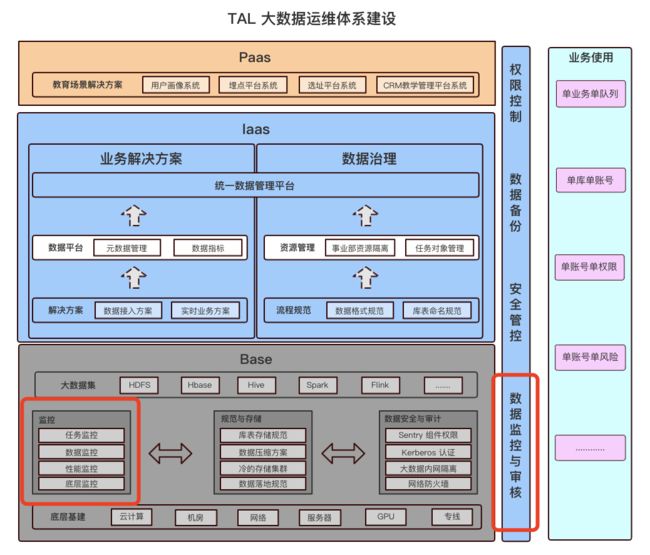
一、大数据监控体系
截止目前,集团数据中台下离线数据集群 近 千台 物理机,数据存量近数10 PB+,每天数据增量 百TB+ ,运行任务 11w + ,Hdfs、Hive 等大数据组件 10+ 套。 那么如何对这些集群组件具有较强的掌控力? 我们需要一套 成体系 的监控方案。
1.1、 Not Only Monitor
首先,我们要明确监控在 好未来大数据运维体系中 是怎样的定位。 在整个体系中,监控处于承上启下,贯穿全局的角色。
这里为什么说 Not Only Monitor 呢 ? 是因为数据监控所包含的范围其实很大,不只是传统的运维底层监控。 还包含了比如 数据质量监控、任务状态监控、组件性能监控、趋势预测监控、同比环比分析 等。
1.2、大数据监控体系整体架构
整个大数据集群的监控体系分为如下七个维度:
| 监控维度 | 主要监控项 |
| 底层基础监控 | 机房 与 网络(路由器、交换机等)、专线、服务器(CPU、内存、IO、磁盘、文件等)各类型日常的基础监控 |
| 服务状态监控 | 各类型标准组件存活状态(从业务的 SLB、Nginx、Java、Hdfs、Hive、ZK 等组件存活状态) |
| 组件性能监控 | 每种组件的 Metrics 性能监控,以 Hive 为例 (QPS、RPC、Metastore Canary、connection 等) |
| Runtime监控 | 顾名思义,模拟客户端去 不间断循环 与 各式 组件发起基本请求与操作,确认组件状态,比如 每隔5 分钟去 与 HDFS 交互,完成 新增、修改、删除、查询 等基本操作,并获得操作结果状态与响应时间。 |
| 集群指标监控 | 集群的 核心指标监控,比如 文件大小分布、集群整体计算资源、集群整体存储资源 等指标。 |
| 趋势预测监控 | 存储与计算 同比、环比 上涨趋势、小文件同比环比上涨趋势、SLA 趋势预测 |
| 任务状态监控 | 任务状态、任务占用资源、任务延迟 等。 |
其实上面每个维度,都包含了很多的监控项 与 监控指标,而针对不同的 告警 维度,它的监控方式也不尽相同。
-
一些监控是不断读取它的状态,比如常见的 CPU 、内存,然后设定阈值触发告警动作。
-
一些监控是需要有时序性的聚合统计,比如 HDFS 存储增量,当增量斜率比平时高的时候触发告警动作。
-
一些监控是需要和其他监控做 与 操作,或者 联动,同时满足才会触发告警动作。
-
等等 。。。
针对这些不同的监控指标,单纯的一个监控组件 或者 数据采集方式是不能满足的。 光靠开源的监控手段也无法全部覆盖,所以我们做了各式组件 + 自研的监控脚本与程序去实现整体的监控框架。
整个7 个维度,我们按照不同的框架与组件实现,主要分为两个实现。
二、基础监控实现
2.1、基础监控框架
基础监控包含:底层基础监控、服务状态监控、组件性能监控、Runtime监控 这四部分。 我们用 Zabbix + Prometheus + 基于 Flask 框架的 Exporter + Python Runtime Monitor 框架体系:

基础监控框架 主要分为 3 大块,我们分别简单介绍一下。
2.2、第一块:基于 Zabbix 的底层基础监控
这部分比较简单,就是基于 Zabbix + 云监控 对所有的 网络、服务器 进行实时监控数据收集。
因为我们同时负责了不同的事业部 与 部门的运维工作,所以进行了 分组、分模版、分告警渠道 的形式,实现对不同部门的告警。 但同时为了避免重复维护,我们尽量复用告警模版。
比如培优大数据、数据中台业务侧的 很多业务类型的告警都是类似的,所有的项目模块都需要对 Java 进程,Nginx 进程进行监控,那我们就划分两个 分组,同时和 一个 Java 进程告警模版相关联。 而不是创建两个:
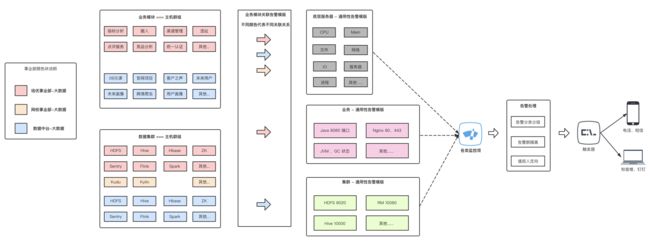 如上,业务模块 对应的 主机群组,不同的主机群组可以 复用 相同的告警模版。 比如不管是培优还是网校、不管是业务还是集群、底层服务器的 CPU、内存等基础监控都得有。 所以就可以复用同一个告警模版。
如上,业务模块 对应的 主机群组,不同的主机群组可以 复用 相同的告警模版。 比如不管是培优还是网校、不管是业务还是集群、底层服务器的 CPU、内存等基础监控都得有。 所以就可以复用同一个告警模版。
PS: 有时候会遇到 相同告警模版,相同监控项,但是监控阈值不同。 比如 虽然业务服务器 和 大数据集群服务器 都需要监控 CPU ,但是业务服务器只要超过 65% ,我们就认为是异常,但是大数据服务器在高峰期可能长时间处于 90% 左右的 CPU 利用率,那么它的阈值要更高,并且持续时长也要更高些。
对于 Zabbix 我们只是力求把它用好,尽可能通过 划分组、复用模版 的方式让它更清晰、整洁、高效。
2.3、第二块:基于 Prometheus + AlertManager + Grafana 的集群性能监控
对 大数据 组件的性能监控,我们借助 Prometheus + AlertManager + Grafana 的架构方式。 主要分为四个简要步骤:
-
自建 Flask exporter ,从 Cloudera Manager 的 API 中取出各式组件需要监控的 Metrics 。
-
通过 Alertmanager 对需要的 metrics 进行告警。
-
自建 知音楼 + 电话告警 API 供 Alertmanager 调用。
-
将 Prometheus data source 接入 Grafana 做报表展示。
这里具体的代码与实现细节,不展开了,否则太多,主要是将大概的思路和实现方式以及官网地址交待清楚:
2.3.1、明确要获取的 Metrics
首先我们要明确有哪些Metrics 可以供我们获取,从官网我们可以看到每个组件自带的各种类型的 Metrics:

是的,因为我们用的是 CDH 版的集群,所以不用跑去查每个组件的接口与调用类型 等。 可以直接走 CM 的 API 去调用获取。 CM API 对应的官方文档里面有大量的接口调用方式,包括一些动作、状态、Metrics 获取等。这里我们暂时只关注 Metrics 获取,我们会发现,官方文档中所有的 Metrics 获取都建议我们走时序型接口:

这里贴一个最简单的 Python 代码调用示例如下:
[root@aly-bigdata-hadoop-op-manager01 cdh_exporter]# cat test.py
import os
import requests
import pdb
import urllib
import json
import re,pdb
uri = "http://admin:[email protected]:7180/api/v11/timeseries?query="
cut_metrics_list = ['health_good_rate']
if __name__ == "__main__":
for key in cut_metrics_list:
url = "%sselect%s%s" % (uri, '%20', key)
request = requests.get(url=url)
jsondata = json.loads(request.text)
print(jsondata)
得到的结果如下(代码有点多,截图表示了):
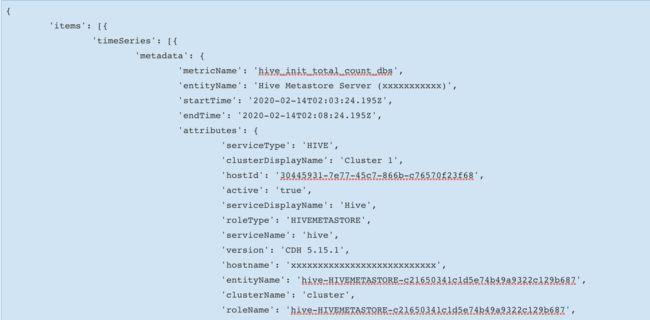
如上,我们就可以获取到对应 Metrics 相关值 。
2.3.2、 自建 Exporter 从 CM 获取想要 Metrics 数据
用 Python 自建写一个 Exporter ,获取数据吐到 Prometheus ,因为涉及到的 Metrics 很多,所以采取多线程并发的方式去获取。
这里主要借助 Python的这个库:https://github.com/prometheus/client_python#instrumenting ,非常简单,这里就不再详细赘述。

总体来说,开 30个线程并发,取 几百个 Item,最终入Prometheus 的时候大概 几万个 Metric ,总共需要约 8 s 多。
2.3.3、配置 AlertManager,实现自定义知音楼告警
数据入到 Prometheus 之后,我们当然要去设置针对一些Metrics 的告警阈值,这里借助和Prometheus 的告警插件 AlertManager。
AlertManager 的安装很简单,这里不再详赘,关于相关配置可以参考官方文档:https://prometheus.io/docs/alerting/configuration/
2.3.4、自定义告警网关
正如上面所说,我们自己实现一个简单的告警接收器,用 Flask 实现,可以让 AlertManager 通过 5000 端口调用发送钉钉告警,这里主要是要注意处理发送与接收格式。 将告警格式处理为我们能简单易懂的格式,非常简单,具体代码这里就不再详细赘述,贴上格式对齐片段截图。

这样,我们的 组件 Metrics 数据就已经到 Prometheus 里面了,对应可以收到相关的 告警 与 恢复信息,当然单纯的收到告警信息不行,我们需要一个有维度的监控展示。
Grafana 是很好的选择,我们只需要将 Prometheus 作为 Datasource 纳入 Grafana,即可构建丰富的报表展示:

2.4、第三块:Runtime Monitor
所谓 Runtime Monitor 其实给它的定位 是 轻量级的模拟客户端交互 监控程序。 即用 Python 编写客户端,循环的每隔一段时间 去 和 HDFS 、Hive 等组件进行基本交互。
与每个核心组件进行 链接、新增、修改、更新、删除 等基本操作,每次一个小闭环。
这样做的意义在于兜底。 因为我们虽然加了很多基础监控,但是你不能 100% 确定采集到的 Metrics 是准确、无延迟 并且高可用的。 我们线上曾经出现过 Zabbix 自己挂了,从而所有基础告警本身失效,从而漏报核心业务模块故障的 Case 。
Runtime Monitor 作为一个客观独立存在的 小闭环,它确保你的服务最基础的核心 能力在正常运行。 一旦Runtime Monitor 出现异常,那往往是线上服务就出现核心异常了。
Runtime 最好做成一个 体系化的 架构,不要变成 东一个小脚本、西一个 小定时。
具体这块的代码架构这里就不再详细赘述了。
截止目前,基础监控三大块 就讲完了。 其实每一块都有很多细节,这里主要是想同步监控的 框架和 维度,后续可能会单独针对每一块做一些专项深入的交流和分享。
三、监控升级
基础监控三大块是生命线,它能保证对基础环境运行状态的监测。 但还不够,集群指标监控、趋势预测监控、任务运行监控 也是我们必须要关注的东西,这些是属于升级监控。
升级监控体系略微复杂一些,需要有一些数据采集、聚合、分析 等能力。 而且一些集群数据需要有 运维数仓,进行 T+1 的任务计算,以及 多指标关联分析等。
这里我们用到了 ES、Kakfa、Logstash、Flink、Hive 各种分析组件,也基于 Flask 框架进行了很多数据加工,甚至运用了一些大数据思想。 给一些核心组件 比如 NameNode RPC 做了 运维画像。 引入了 Dr Elephant 对集群的任务进行了 各式分析。
目前增强监控体系如下:

如上,升级监控分为了很多模块,详细的我们留在下篇再进行分享,这里我们先简单附上升级监控的一些结果。
CPU、内存的 周环比、集群存储剩余可用时长预测、每日各维度数据增量:
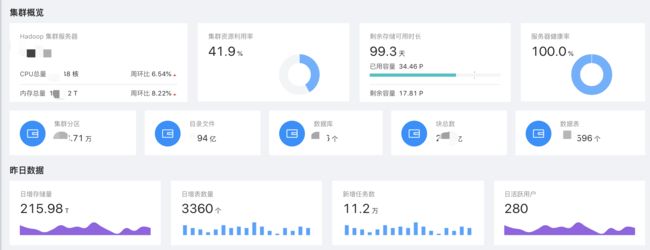
数据表分布、活跃用户分布、活跃任务分布等:
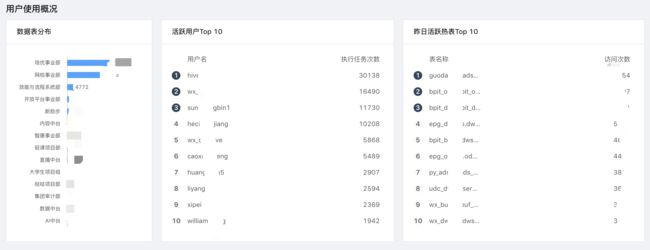
任务相关分布分析: 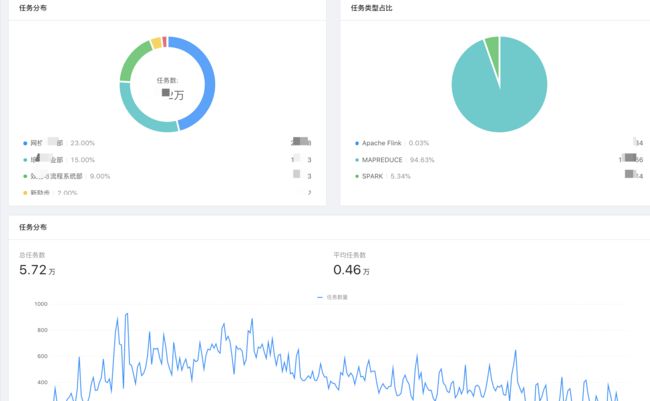
还有很多,包括实现方式,这里就不再展开了,下篇会专门再专门讲一下 升级监控的架构 与 具体实现原理与细节。
四、漫谈 告警收敛 与 告警分级
其实光是告警收敛 和 告警分级 每个都可以单拉出来,有很多内容。 很重要,做深了也很有挑战。 我自己这方面的经验也不深,只是做了一些简单的探索和实践。 这里将仅有的实践和大家探讨一下。
我觉得一条有效的 告警,它的 生命旅程 是非常坎坷的,理想情况下它 应该经历 这样的旅程:
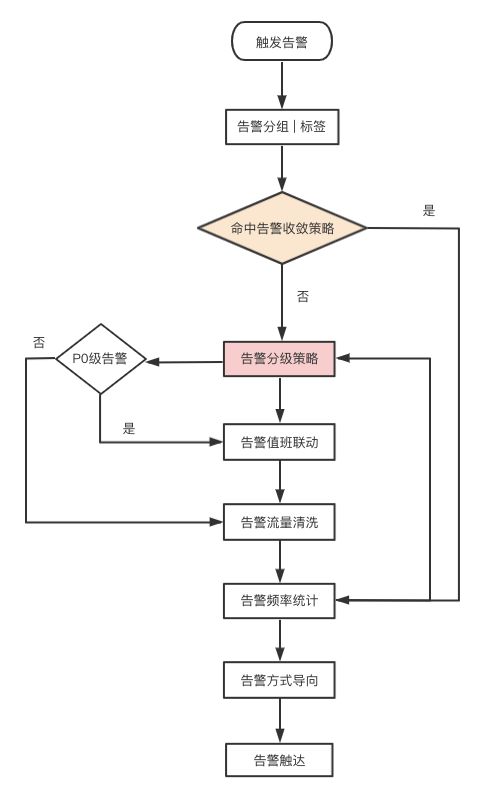
如上,它得经过一层层的筛选、过滤、汇总、定向 才发给真正需要知道它的人,从而实现自己的生命价值。
这里我将告警收敛 和 告警分级都标注出来了,下面谈谈。 其他的这里就不再展开了,其实做好监控是非常复杂的一件事情。 如何与组织树和值班信息联动,如何进行 告警的分类分级统计,如何进行告警流量清洗,这些都是很值得深入研究的。
4.1、监控告警收敛
我经常给伙伴们强调的一句话: 理想情况下,要么不报,只要报出来那就是一定是需要我们立刻关注处理的。
-
目前,我们负责 四个事业部、十几个部门、4套大数据集群、各种组件,所以分了将近 12 个 告警群。
-
每天的告警消息数大概 平均保持在 60 - 100 之间。
-
每天有效告警只占所有告警的不到 10%。
-
而由于大数据夜间是高峰期,所以一些核心报警是加了电话通知的,如果你不想半夜被叫醒却发现是误报,那就必须要进行告警收敛。
其实告警收敛的核心目的是提升告警有效性,确保问题能在第一时间得到妥善处理。
目前我们的高级收敛做的比较糙,主要分为三部分:
-
Zabbix 部分就单纯的根据进一步细分 主机群组 和 监控模版,比如 Datanode 独立一个基础监控,将阈值调高,不至于频繁告警。
-
Prometheus 本身是支持 告警分组 与 告警收敛的,就 基于 Prometheus 的告警分组特性进行了一些常态化的告警收敛。
-
自建升级监控 目前 是根据一些简单计算公式进行收敛策略,我一直觉得这块其实大有可为,后面我们逐步要做 DataOps 和 AiOPS 的时候可以基于Flink 等通过大量的实时算法策略做告警收敛。
这里也附上我对告警收敛的一点思考。 首先,它是一个细活,当到一定规模和体量的时候,必然要深入算法,去建模,对监控流量进行分析。从而达到 类似 AIOPS 的效果,进行故障自愈和智能巡检等效果。 而想要做到这一步还是要有比较专业的团队去聚焦,做监控平台。 而监控平台一个很大的挑战将会是,平台如何有通用的产品能力,去适配不同业务场景的监控告警 功能。
4.2、监控告警分级
监控告警分级也是至关重要的,当监控的东西越来越多的时候,就得给这些家伙进行分级管理了。 有些监控告警是 P0 级,它很重要,一旦出现就需要引起我们的高度重视,快速响应,一般我们要求是触发电话通知,并通知到对应的值班人、负责人等。 而有些监控项它更多的是偏提示或者预警,那么就要做好分类管理。
针对线上的一些告警,进行了如下分类分级(内容太多,这里只截取了一小部分):

如上,根据不同的监控项、监控类型,分别针对线上的监控做了告警分级处理。
我们规定,所有的 P0 级告警,全部走 电话 + 知音楼 通知,所有的 P1 级告警都走 对应的知音楼核心群通知。 P2 及以上告警收敛覆盖率要达到 80%。
| 监控告警级别 | 监控告警通知对象 | 监控告警响应要求 | 监控告警通知方式 |
| P0 | 值班人 + 组长 | 5分钟之内 | 电话、知音楼核心告警群 |
| P1 | 值班人 | 5 - 15 分钟之内 | 知音楼核心告警群 |
| P2 及 以上 | 值班人 | 保持关注 | 知音楼告警群 |
好的告警分级 能减轻运维人员自己的负担,也能使告警更有效清晰。 但如何打造一套完整的告警分级体系,还需要贴合业务场景 并且有监控数据分析,综合去评定。 一旦有了这样的体系,那么后面要做的就是不断补充完善这个体系。 出故障的时候也能按图索骥,根据监控告警分级策略不断打磨完善。
关于基础监控体系,就先谈到到这里,篇幅有限,感觉文章中很多点,都可以单拉出来去进一步讨论。
未完待续 ~
作者:好未来高级专家王鑫宇
关于好未来技术更多内容请:微信扫码关注「好未来技术」微信公众号