产品经理也能动手实践的AI(八)- Resnet Unet GANS RNN
正文共: 2336字 22图
预计阅读时间: 6分钟

最后一节课了,很多更细致的内容会在part2展开,新的part2会在6月28号放出来,据说共7节,并且会有2节专门讲swift。

1.概览
更细致的创建Databunch
从头创建一个CNN
ResNet
U-net
GAN
RNN
2.1 核心机器学习概念
很多,但是都一笔带过,说在part2中详细讲解
2.2 FastAI
split_none:创建databunch的过程,不划分训练/验证组时也要进行这样一个文件转化
data.one_batch:获取一个batch的数据
2.3 Python
PIL/Pillow:Python Imaging Library
parallel:并行处理任务,可以变快
3.1 创建DataBunch详细讲解
共分4个步骤:创建图片合集、训练集划分、打标签、(图片变形)、创建数据集

3.2 从头创建一个卷积神经网络
初始图片是28x28的尺寸,因为stride是2,所以每一次Conv2d后尺寸就会缩小一倍,但是kernel有8个,所以输出的channel有8个。
最后Flatten将矩阵转化成一个10个数的vector,从而可以和结果0-9进行比对。
model = nn.Sequential(nn.Conv2d(1, 8, kernel_size=3, stride=2, padding=1), # 14x14nn.BatchNorm2d(8),nn.ReLU(),nn.Conv2d(8, 16, kernel_size=3, stride=2, padding=1), # 7x7nn.BatchNorm2d(16),nn.ReLU(),nn.Conv2d(16, 32, kernel_size=3, stride=2, padding=1), # 4x4nn.BatchNorm2d(32),nn.ReLU(),nn.Conv2d(32, 16, kernel_size=3, stride=2, padding=1), # 2x2nn.BatchNorm2d(16),nn.ReLU(),nn.Conv2d(16, 10, kernel_size=3, stride=2, padding=1), # 1x1nn.BatchNorm2d(10),Flatten() # remove (1,1) grid)
3.3 ResNet
是不是层越多,效果越好呢?实验证明并不是,但为什么呢?也许是方法不对,所以就发现了ResNet

这就是ResNet的核心,一个ResBlock的工作原理:2个卷积层之后,把结果和输入值相加
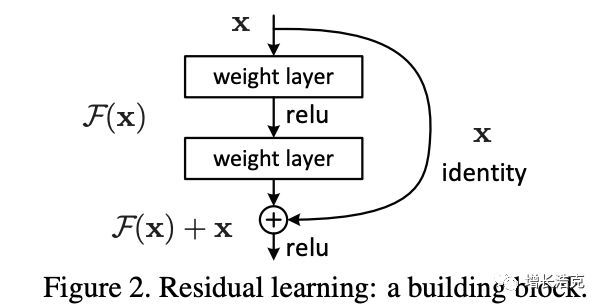

为什么ResNet的效果好,如下图y轴表示的是loss,ResNet可以更平滑的找到低点

近些年还流行一个DenseNet,适用于小规模数据/图像分割,可以达到更好的效果。而它和ResNet的唯一区别就是最后相加的时候,采取合并的方式,cat([x,x.orig])。
3.4 U-net
看形状就知道这是U-net,而且很容易看出分2部分,下降的部分和stride 2 的cnn一样,叫做encoder;
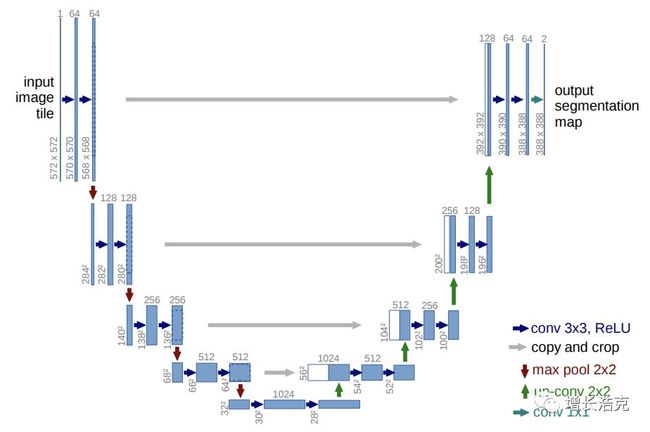
而上升的部分,叫decoder,类似于放大一张图,试想一下可以有几种方式:
相当于Stride = 0.5的conv,但是一个4像素的图像和45个白点合成的图像,就像是被稀释过一样,并没有什么意义,所以这种方式不好

nearest neighbor interpolation:无脑复制,不好不坏

bilinear interpolation:根据周围8个点取均值,有点好
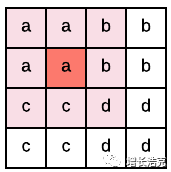
cross connection: 用下降过程对应结果,合并到上升过程,如图白色部分,非常好

更多细节请参考源代码
UnetBlock DynamicUnet
unet_learner
3.5 GAN
GAN的本质就是一个具备复杂的loss function的神经网络,本课讲解了这个loss fn是如何一步步进化的:
MSE loss:只比较生成图像和目标图像每个像素点的MSE,能实现去水印的效果,但是并没有让图片变清晰
Critic:增加一个评论家的角色,训练成可以鉴别清晰和模糊图像的神经网络,然后将区分效果作为loss,也就是越分不清哪张图是清晰的,loss就越低。所以这样图片就清晰了,但是动物的眼睛还是模糊的
Feature loss/Perceptual loss:来衡量图片特征的接近程度,运用pytorch的hook函数,将训练过程中每个Activations的特征值存下来,进行比较
GAN:将generator和critic整合到一起,相当于Generator每次输出图片,都用于critic的训练,而critic训练好的模型,可以作为generator的loss function

Crappify:把高质量图片处理成低质量图片(function)
Generator:目标是生成高质量图片(Model)
Critic:高低质量图片分类器(Model)
3.6 RNN 递归神经网络/循环神经网络
这里的例子是,根据一句话预测下一个单词。
先从一个最基本的神经网络开始,了解图形和箭头的含义
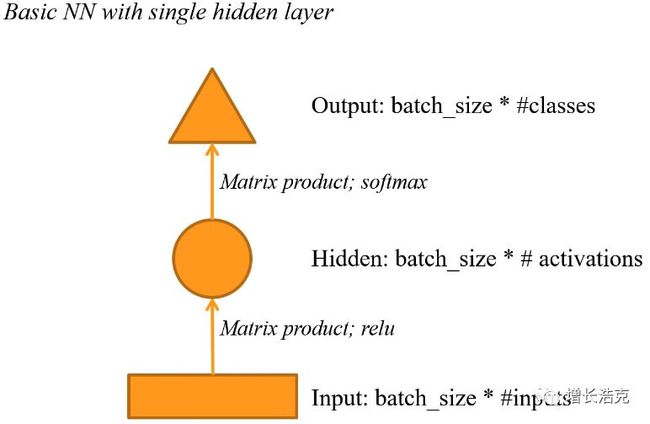
然后搭建一个最基本的原型,根据单词1,2,预测单词3

然后再下一步,根据单词123预测4

于是找到规律,根据n-1个单词,预测第n个单词
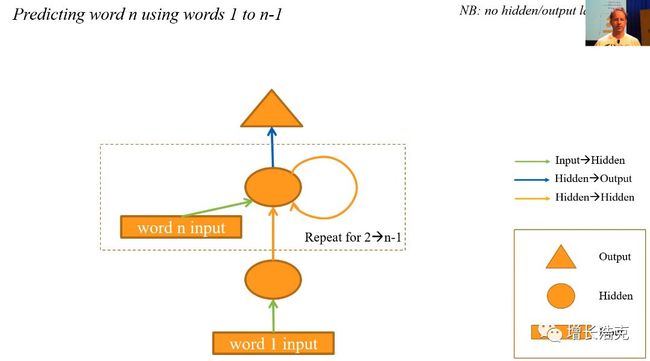
然后发现预测第n个词时,不用每次都把之前n-1个单词算一遍,他们有之前算过的,所以可以存下来,作为输入值,在下一次预测时会用到
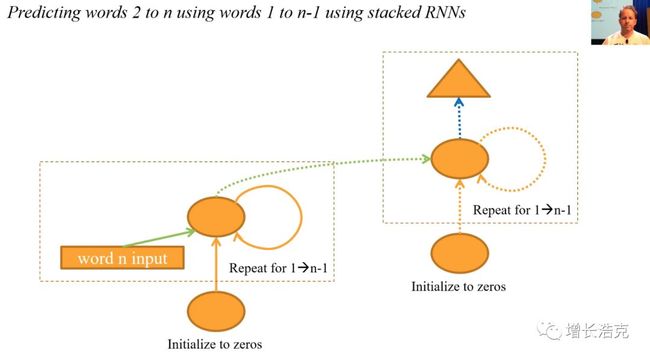
于是生成了一个结构,每次输出前的Activation都可以作为下一次运算的输入值,就是有个递归关系的RNN

相关阅读
产品经理也能动手实践的AI (一)|(二)|(三)|(四)|(五)|(六)|(七)
人人都能搞懂的AI (一)|(二)|(三)|(四)
![]()
如果你喜欢思考,别忘记关注+置顶公众号哦!
我是Hawk,8年产品经理,目前专注AI机器学习。

好看的人都点了在看 