Python数据结构之Pandas学习
- Pandas是一个强大的Python数据分析的工具包,是基于Numpy构建的
- Pandas的主要功能
- 具备对其功能的数据结构DataFrame、Series
- 集成时间序列功能
- 提供丰富的数学运算和操作
- 灵活处理缺失数据
- 安装方法:pip install pandas
- 引用方法:import pandas as pd
import pandas as pd
Pandas 里面的数据结构是「多维数据表」,学习它可以类比这 NumPy 里的「多维数组」。1/2/3 维的「多维数据表」分别叫做 Series (系列), DataFrame (数据帧) 和 Panel (面板),和1/2/3 维的「多维数组」的类比关系如下。
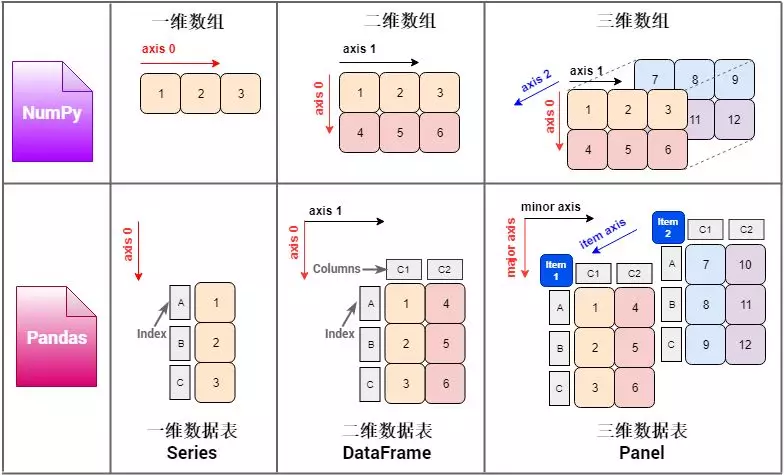
对比 NumPy (np) 和 Pandas (pd) 每个维度下的数据结构,不难看出
pd 多维数据表 = np 多维数组 + 描述
其中
- Series = 1darray + index
- DataFrame = 2darray + index + columns
- Panel = 3darray + index + columns + item
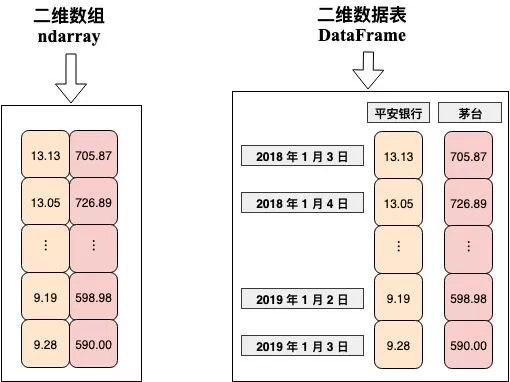
每个维度上的「索引」使得「多维数据表」比「多维数组」涵盖更多的信息,如下图,左边的 2d array 仅仅储存了一组数值 (具体代表什么意思却不知道),而右边的 DataFrame 一看就知道这是平安银行和茅台从 2018-1-3 到 2019-1-3 的价格。
和学习 numpy 一样,学习 pandas 还是遵循的 Python 里「万物皆对象」的原则,既然把数据表当对象,我们就按着数据表的创建、数据表的存载、数据表的获取、数据表的合并和连接、数据表的重塑和透视、和数据表的分组和整合来学习Pandas。
1 数据表的创建
数据表有三大类型:
- Series: 一维数据,类似于 python 中的基本数据的 list 或 NumPy 中的 1D array。Pandas 里最基本的数据结构
- DataFrame: 二维数据,类似于 R 中的 data.frame 或 Matlab 中的 Tables。DataFrame 是 Series 的容器
- Panel:三维数据。Panel 是 DataFrame 的容器
最常见的数据类型是二维的 DataFrame,其中
- 每行代表一个示例 (instance)
- 每列代表一个特征 (feature)
DataFrame 可理解成是 Series 的容器,每一列都是一个 Series,或者 Series 是只有一列的 DataFrame。
Panel 可理解成是 DataFrame 的容器。
创建 pandas 数据表,有两种方式:
- 1.按步就班的用 pd.Series(), pd.DataFrame() 和 pd.Panel()
- 2.一步登天的用万矿里面的 WindPy API 读取
1.1 按部就班法
一维Series
创建 Series 只需用下面一行代码
pd.Series( x, index=idx )
其中 x 可以是
-
1.列表 (list)
-
2.numpy 数组 (ndarray)
-
3.字典 (dict)
-
x 是位置参数
-
index 是默认参数,默认值为 idx = range(0, len(x))
用列表创建
s = pd.Series([27.2, 27.65, 27.70, 28])
s
0 27.20
1 27.65
2 27.70
3 28.00
dtype: float64
在创建 Series 时,如果不显性设定 index,那么 Python 给定一个默认从 0 到 N-1 的值,其中 N 是 x 的长度。
Series s 也是一个对象,用 dir(s) 可看出关于 Series 所有的属性和内置函数,其中最重要的是
- 用 s.values 打印 s 中的元素
- 用 s.index 打印 s 中的元素对应的索引
s.values
array([27.2 , 27.65, 27.7 , 28. ])
s.index
RangeIndex(start=0, stop=4, step=1)
dates = pd.date_range('20190401',periods=4) # 创建 2019 年 4 月 1 日到 2019 年 4 月 4 日的日期,作为索引
s2 = pd.Series( [27.2, 27.65, 27.70, 28], index=dates ) # 创建一维Series
s2
2019-04-01 27.20
2019-04-02 27.65
2019-04-03 27.70
2019-04-04 28.00
Freq: D, dtype: float64
s2.index
DatetimeIndex(['2019-04-01', '2019-04-02', '2019-04-03', '2019-04-04'], dtype='datetime64[ns]', freq='D')
显然,s2 比 s 包含的信息更多,这是 s2 的索引是一组日期对象,数据类型是 datetime64,频率是 D (天)。
还可以给 s2 命名,例如叫“海底捞股价”。
s2.name = '海底捞股价'
s2
2019-04-01 27.20
2019-04-02 27.65
2019-04-03 27.70
2019-04-04 28.00
Freq: D, Name: 海底捞股价, dtype: float64
help(pd.date_range)
Help on function date_range in module pandas.core.indexes.datetimes:
date_range(start=None, end=None, periods=None, freq=None, tz=None, normalize=False, name=None, closed=None, **kwargs) -> pandas.core.indexes.datetimes.DatetimeIndex
Return a fixed frequency DatetimeIndex.
Parameters
----------
start : str or datetime-like, optional
Left bound for generating dates.
end : str or datetime-like, optional
Right bound for generating dates.
periods : int, optional
Number of periods to generate.
freq : str or DateOffset, default 'D'
Frequency strings can have multiples, e.g. '5H'. See
:ref:`here ` for a list of
frequency aliases.
tz : str or tzinfo, optional
Time zone name for returning localized DatetimeIndex, for example
'Asia/Hong_Kong'. By default, the resulting DatetimeIndex is
timezone-naive.
normalize : bool, default False
Normalize start/end dates to midnight before generating date range.
name : str, default None
Name of the resulting DatetimeIndex.
closed : {None, 'left', 'right'}, optional
Make the interval closed with respect to the given frequency to
the 'left', 'right', or both sides (None, the default).
**kwargs
For compatibility. Has no effect on the result.
Returns
-------
rng : DatetimeIndex
See Also
--------
DatetimeIndex : An immutable container for datetimes.
timedelta_range : Return a fixed frequency TimedeltaIndex.
period_range : Return a fixed frequency PeriodIndex.
interval_range : Return a fixed frequency IntervalIndex.
Notes
-----
Of the four parameters ``start``, ``end``, ``periods``, and ``freq``,
exactly three must be specified. If ``freq`` is omitted, the resulting
``DatetimeIndex`` will have ``periods`` linearly spaced elements between
``start`` and ``end`` (closed on both sides).
To learn more about the frequency strings, please see `this link
`__.
Examples
--------
**Specifying the values**
The next four examples generate the same `DatetimeIndex`, but vary
the combination of `start`, `end` and `periods`.
Specify `start` and `end`, with the default daily frequency.
>>> pd.date_range(start='1/1/2018', end='1/08/2018')
DatetimeIndex(['2018-01-01', '2018-01-02', '2018-01-03', '2018-01-04',
'2018-01-05', '2018-01-06', '2018-01-07', '2018-01-08'],
dtype='datetime64[ns]', freq='D')
Specify `start` and `periods`, the number of periods (days).
>>> pd.date_range(start='1/1/2018', periods=8)
DatetimeIndex(['2018-01-01', '2018-01-02', '2018-01-03', '2018-01-04',
'2018-01-05', '2018-01-06', '2018-01-07', '2018-01-08'],
dtype='datetime64[ns]', freq='D')
Specify `end` and `periods`, the number of periods (days).
>>> pd.date_range(end='1/1/2018', periods=8)
DatetimeIndex(['2017-12-25', '2017-12-26', '2017-12-27', '2017-12-28',
'2017-12-29', '2017-12-30', '2017-12-31', '2018-01-01'],
dtype='datetime64[ns]', freq='D')
Specify `start`, `end`, and `periods`; the frequency is generated
automatically (linearly spaced).
>>> pd.date_range(start='2018-04-24', end='2018-04-27', periods=3)
DatetimeIndex(['2018-04-24 00:00:00', '2018-04-25 12:00:00',
'2018-04-27 00:00:00'],
dtype='datetime64[ns]', freq=None)
**Other Parameters**
Changed the `freq` (frequency) to ``'M'`` (month end frequency).
>>> pd.date_range(start='1/1/2018', periods=5, freq='M')
DatetimeIndex(['2018-01-31', '2018-02-28', '2018-03-31', '2018-04-30',
'2018-05-31'],
dtype='datetime64[ns]', freq='M')
Multiples are allowed
>>> pd.date_range(start='1/1/2018', periods=5, freq='3M')
DatetimeIndex(['2018-01-31', '2018-04-30', '2018-07-31', '2018-10-31',
'2019-01-31'],
dtype='datetime64[ns]', freq='3M')
`freq` can also be specified as an Offset object.
>>> pd.date_range(start='1/1/2018', periods=5, freq=pd.offsets.MonthEnd(3))
DatetimeIndex(['2018-01-31', '2018-04-30', '2018-07-31', '2018-10-31',
'2019-01-31'],
dtype='datetime64[ns]', freq='3M')
Specify `tz` to set the timezone.
>>> pd.date_range(start='1/1/2018', periods=5, tz='Asia/Tokyo')
DatetimeIndex(['2018-01-01 00:00:00+09:00', '2018-01-02 00:00:00+09:00',
'2018-01-03 00:00:00+09:00', '2018-01-04 00:00:00+09:00',
'2018-01-05 00:00:00+09:00'],
dtype='datetime64[ns, Asia/Tokyo]', freq='D')
`closed` controls whether to include `start` and `end` that are on the
boundary. The default includes boundary points on either end.
>>> pd.date_range(start='2017-01-01', end='2017-01-04', closed=None)
DatetimeIndex(['2017-01-01', '2017-01-02', '2017-01-03', '2017-01-04'],
dtype='datetime64[ns]', freq='D')
Use ``closed='left'`` to exclude `end` if it falls on the boundary.
>>> pd.date_range(start='2017-01-01', end='2017-01-04', closed='left')
DatetimeIndex(['2017-01-01', '2017-01-02', '2017-01-03'],
dtype='datetime64[ns]', freq='D')
Use ``closed='right'`` to exclude `start` if it falls on the boundary.
>>> pd.date_range(start='2017-01-01', end='2017-01-04', closed='right')
DatetimeIndex(['2017-01-02', '2017-01-03', '2017-01-04'],
dtype='datetime64[ns]', freq='D')
用numpy数组创建
import numpy as np
s = pd.Series( np.array([27.2, 27.65, 27.70, 28, 28, np.nan]) )
s
0 27.20
1 27.65
2 27.70
3 28.00
4 28.00
5 NaN
dtype: float64
Series 中另外 5 个属性或内置函数的用法:
- len: s 里的元素个数
- shape: s 的形状 (用元组表示)
- count: s 里不含 nan 的元素个数
- unique: 返回 s 里不重复的元素
- value_counts: 统计 s 里非 nan 元素的出现次数
print( 'The length is', len(s) ) # series的长度
print( 'The shape is', s.shape ) # series的形状,结果用元组表示
print( 'The count is', s.count() ) # series中元素个数(不含nan)
The length is 6
The shape is (6,)
The count is 5
s.unique() # series去重,返回不重复元素
array([27.2 , 27.65, 27.7 , 28. , nan])
s.value_counts() # 统计series里面每个元素出现的次数,默认不含nan
28.00 2
27.70 1
27.65 1
27.20 1
dtype: int64
s.value_counts(dropna=False) # 统计series里面元素出现的次数,包含nan
28.00 2
27.70 1
27.65 1
27.20 1
NaN 1
dtype: int64
用字典创建series
创建 Series 还可以用字典。字典的「键值对」的「键」自动变成了 Series 的索引 (index),而「值」自动变成了Series 的值 (values)。
data_dict = { 'BABA': 187.07, 'PDD': 21.83, 'JD': 30.79, 'BIDU': 184.77 } # 创建一个字典
s3 = pd.Series(data_dict, name='中概股') # 用字典创建series
s3.index.name = '股票代号' # 给series的index命名
s3
股票代号
BABA 187.07
PDD 21.83
JD 30.79
BIDU 184.77
Name: 中概股, dtype: float64
stock = ['FB', 'BABA', 'PDD', 'JD'] # 创建一个列表
s4 = pd.Series( data_dict, index=stock ) # 用这个列表作为上述字典的index,但是列表内容与字典的“键”不完全匹配
s4
FB NaN
BABA 187.07
PDD 21.83
JD 30.79
dtype: float64
index里多加了脸书 (FB),而 data_dict 字典中没有 FB 这个键,因此生成的 s4 在 FB 索引下对应的值为 NaN。再者,index里没有百度 (BIDU),因此 s4 里面没有 BIDU 对应的值 (即便 data_dict 里面有)。
当两个 Series 进行某种操作时,比如相加,Python 会自动对齐不同 Series 的 index.
s3 + s4
BABA 374.14
BIDU NaN
FB NaN
JD 61.58
PDD 43.66
dtype: float64
**注:**nan加上任何数值都是nan。
二维 DataFrame
创建 DataFrame 只需用下面一行代码
pd.DataFrame( x, index=idx,columns=col )
其中 x 可以是
- 二维列表 (list)
- 二维 numpy 数组 (ndarray)
- 字典 (dict),其值是一维列表、numpy 数组或 Series
- 另外一个 DataFrame
pd.DataFrame( x, index=idx,columns=col )里面
- x 是位置参数
- index 是默认参数,默认值为 idx = range(0, x.shape[0])
- columns 是默认参数,默认值为 col = range(0, x.shape[1])
# 用列表或numpy数组创建DataFrame
df1 = pd.DataFrame( [[1, 2, 3], [4, 5, 6]] )
df1
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 1 | 2 | 3 |
| 1 | 4 | 5 | 6 |
df1 = pd.DataFrame( np.array([[1, 2, 3], [4, 5, 6]]) )
df1
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 1 | 2 | 3 |
| 1 | 4 | 5 | 6 |
在创建 DataFrame 时,如果不显性设定 index 和 columns 时,那么Python 给它们默认值,其中
- index = 0 到 r-1,r 是 x 的行数
- colmns = 0 到 c-1,c 是 x 的列数
# 用户对象为列表的字典创建DataFrame
symbol = ['BABA', 'JD', 'AAPL', 'MS', 'GS', 'WMT']
data = {'行业': ['电商', '电商', '科技', '金融', '金融', '零售'],
'价格': [176.92, 25.95, 172.97, 41.79, 196.00, 99.55],
'交易量': [16175610, 27113291, 18913154, 10132145, 2626634, 8086946],
'雇员': [101550, 175336, 100000, 60348, 36600, 2200000]}
df2 = pd.DataFrame( data, index=symbol )
df2.name='美股'
df2.index.name = '代号'
df2
| 行业 | 价格 | 交易量 | 雇员 | |
|---|---|---|---|---|
| 代号 | ||||
| BABA | 电商 | 176.92 | 16175610 | 101550 |
| JD | 电商 | 25.95 | 27113291 | 175336 |
| AAPL | 科技 | 172.97 | 18913154 | 100000 |
| MS | 金融 | 41.79 | 10132145 | 60348 |
| GS | 金融 | 196.00 | 2626634 | 36600 |
| WMT | 零售 | 99.55 | 8086946 | 2200000 |
字典的「键值对」的「键」自动变成了 DataFrame 的栏 (columns),而「值」自动变成了 DataFrame 的值 (values),而其索引 (index) 需要另外定义。
df2.values
array([['电商', 176.92, 16175610, 101550],
['电商', 25.95, 27113291, 175336],
['科技', 172.97, 18913154, 100000],
['金融', 41.79, 10132145, 60348],
['金融', 196.0, 2626634, 36600],
['零售', 99.55, 8086946, 2200000]], dtype=object)
**注:**每一行是一个实例
df2.columns
Index(['行业', '价格', '交易量', '雇员'], dtype='object')
df2.index
Index(['BABA', 'JD', 'AAPL', 'MS', 'GS', 'WMT'], dtype='object', name='代号')
查看DataFrame
我们可以从头或从尾部查看 DataFrame 的 n 行,分别用 df2.head() 和 df2.tail(n),如果没有设定 n,默认值为 5 行
df2.head()
| 行业 | 价格 | 交易量 | 雇员 | |
|---|---|---|---|---|
| 代号 | ||||
| BABA | 电商 | 176.92 | 16175610 | 101550 |
| JD | 电商 | 25.95 | 27113291 | 175336 |
| AAPL | 科技 | 172.97 | 18913154 | 100000 |
| MS | 金融 | 41.79 | 10132145 | 60348 |
| GS | 金融 | 196.00 | 2626634 | 36600 |
df2.tail()
| 行业 | 价格 | 交易量 | 雇员 | |
|---|---|---|---|---|
| 代号 | ||||
| JD | 电商 | 25.95 | 27113291 | 175336 |
| AAPL | 科技 | 172.97 | 18913154 | 100000 |
| MS | 金融 | 41.79 | 10132145 | 60348 |
| GS | 金融 | 196.00 | 2626634 | 36600 |
| WMT | 零售 | 99.55 | 8086946 | 2200000 |
统计DataFrame
用 df2.describe() 还可以看看 DataFrame 每栏的统计数据。
df2.describe()
| 价格 | 交易量 | 雇员 | |
|---|---|---|---|
| count | 6.000000 | 6.000000e+00 | 6.000000e+00 |
| mean | 118.863333 | 1.384130e+07 | 4.456390e+05 |
| std | 73.748714 | 8.717312e+06 | 8.607522e+05 |
| min | 25.950000 | 2.626634e+06 | 3.660000e+04 |
| 25% | 56.230000 | 8.598246e+06 | 7.026100e+04 |
| 50% | 136.260000 | 1.315388e+07 | 1.007750e+05 |
| 75% | 175.932500 | 1.822877e+07 | 1.568895e+05 |
| max | 196.000000 | 2.711329e+07 | 2.200000e+06 |
函数 describe() 只对「数值型变量」有用 (没有对「字符型变量」行业栏做统计),统计量分别包括个数、均值、标准差、最小值,25-50-75 百分数值,最大值。
- 数据是否有缺失值 (每个栏下的 count 是否相等)
- 数据是否有异常值 (最小值 min 和最大值 max 是否太极端)
升维DataFrame
我们用 MultiIndex.from_tuples() 还可以赋予 DataFrame 多层索引 (实际上增加了维度,多层索引的 DataFrame 实际上是三维数据)
df2.index = pd.MultiIndex.from_tuples(
[('中国公司','BABA'), ('中国公司','JD'),
('美国公司','AAPL'), ('美国公司','MS'),
('美国公司','GS'), ('美国公司','WMT')] )
df2
| 行业 | 价格 | 交易量 | 雇员 | ||
|---|---|---|---|---|---|
| 中国公司 | BABA | 电商 | 176.92 | 16175610 | 101550 |
| JD | 电商 | 25.95 | 27113291 | 175336 | |
| 美国公司 | AAPL | 科技 | 172.97 | 18913154 | 100000 |
| MS | 金融 | 41.79 | 10132145 | 60348 | |
| GS | 金融 | 196.00 | 2626634 | 36600 | |
| WMT | 零售 | 99.55 | 8086946 | 2200000 |
在 MultiIndex.from_tuples() 中传递一个「元组的列表」,每个元组,比如 (‘中国公司’, ‘BABA’),第一个元素中国公司是第一层 index,第二个元素BABA是第二层 index。
df2.loc[('中国公司','BABA'),]
行业 电商
价格 176.92
交易量 16175610
雇员 101550
Name: (中国公司, BABA), dtype: object
三维Panel (pd.Panel已弃用,使用pd.MultiIndex)
dates = pd.date_range('20190401',periods=4)
data = {'开盘价': [27.2, 27.65, 27.70, 28],
'收盘价': [27.1, 27.55, 27.45, 28.1]}
df1 = pd.DataFrame( data, index=dates )
data = {'开盘价': [367, 369.8, 378.2, 380.6],
'收盘价': [369.5, 370.1, 380, 382.1]}
df2 = pd.DataFrame( data, index=dates )
df = pd.concat([df1, df2])# 首先用 concat() 函数 (下帖的内容) 将 df1 和 df2 连接起来;
code = ['海底捞', '腾讯']
midx = [ (c, d) for c in code for d in dates ] # 再用「列表解析法」生成 midx,它是一个元组的列表,c 是股票代码,d 是日期;
df.index =pd.MultiIndex.from_tuples( midx ) # 最后放入 MultiIndex.from_tuples() 生成有多层索引的 DataFrame。
df
| 开盘价 | 收盘价 | ||
|---|---|---|---|
| 海底捞 | 2019-04-01 | 27.20 | 27.10 |
| 2019-04-02 | 27.65 | 27.55 | |
| 2019-04-03 | 27.70 | 27.45 | |
| 2019-04-04 | 28.00 | 28.10 | |
| 腾讯 | 2019-04-01 | 367.00 | 369.50 |
| 2019-04-02 | 369.80 | 370.10 | |
| 2019-04-03 | 378.20 | 380.00 | |
| 2019-04-04 | 380.60 | 382.10 |
2 数据表的存载
数据表的「保存」和「加载」
- 保存只是为了下次再用处理好的 DataFrame
- 加载可以不用重新再定义 DataFrame
DataFrame 可以被保存为 Excel, csv, SQL 和 HDF5 格式,其语句一看就懂,用 to_数据格式,具体如下:
- to_excel()
- to_csv()
- to_sql()
- to_hdf()
如果要加载某种格式的数据到 DataFrame 里,用 read_数据格式,具体如下:
- read_excel()
- read_csv()
- read_sql()
- read_hdf()
Excel格式
用 pd.to_excel 函数将 DataFrame 保存为 .xlsx 格式,并保存到 ‘Sheet1’ 中
df.to_excel('文件名','表名')
用 pd.read_excel()函数 即可加载该文件并存成 DataFrame 形式
pd.read_excel( '文件名','表名' )
df = pd.DataFrame(np.array([[1, 2, 3], [4, 5, 6]]))
df.to_excel('pd_excel.xlsx', sheet_name='Sheet1', index=False)
df1 = pd.read_excel('pd_excel.xlsx', sheet_name='Sheet1')
df1
| 0 | 1 | 2 | |
|---|---|---|---|
| 0 | 1 | 2 | 3 |
| 1 | 4 | 5 | 6 |
csv格式
用 pd.to_csv 函数将 DataFrame 保存为 .csv 格式,注意如果 index 没有特意设定,最后不要把 index 值存到 csv 文件中。具体写法如下:
pd.to_csv( '文件名',index=False )
用 pd.read_csv()函数 即可加载该文件并存成 DataFrame 形式
pd.read_csv( '文件名' )
data = {'Code': ['BABA', '00700.HK', 'AAPL', '600519.SH'],
'Name': ['阿里巴巴', '腾讯', '苹果', '茅台'],
'Market': ['US', 'HK', 'US', 'SH'],
'Price': [185.35, 380.2, 197, 900.2],
'Currency': ['USD', 'HKD', 'USD', 'CNY']}
df = pd.DataFrame(data)
df.to_csv('pd_csv.csv', index=False)
df2 = pd.read_csv('pd_csv.csv')
df2
| Code | Name | Market | Price | Currency | |
|---|---|---|---|---|---|
| 0 | BABA | 阿里巴巴 | US | 185.35 | USD |
| 1 | 00700.HK | 腾讯 | HK | 380.20 | HKD |
| 2 | AAPL | 苹果 | US | 197.00 | USD |
| 3 | 600519.SH | 茅台 | SH | 900.20 | CNY |
3 数据表的索引和切片
Series的索引/切片跟 numpy 数组很类似。
DataFrame 的索引和切片如下:
symbol = ['BABA', 'JD', 'AAPL', 'MS', 'GS', 'WMT']
data = {'行业': ['电商', '电商', '科技', '金融', '金融', '零售'],
'价格': [176.92, 25.95, 172.97, 41.79, 196.00, 99.55],
'交易量': [16175610, 27113291, 18913154, 10132145, 2626634, 8086946],
'雇员': [101550, 175336, 100000, 60348, 36600, 2200000]}
df = pd.DataFrame( data, index=symbol )
df.name='美股'
df.index.name = '代号'
df
| 行业 | 价格 | 交易量 | 雇员 | |
|---|---|---|---|---|
| 代号 | ||||
| BABA | 电商 | 176.92 | 16175610 | 101550 |
| JD | 电商 | 25.95 | 27113291 | 175336 |
| AAPL | 科技 | 172.97 | 18913154 | 100000 |
| MS | 金融 | 41.79 | 10132145 | 60348 |
| GS | 金融 | 196.00 | 2626634 | 36600 |
| WMT | 零售 | 99.55 | 8086946 | 2200000 |
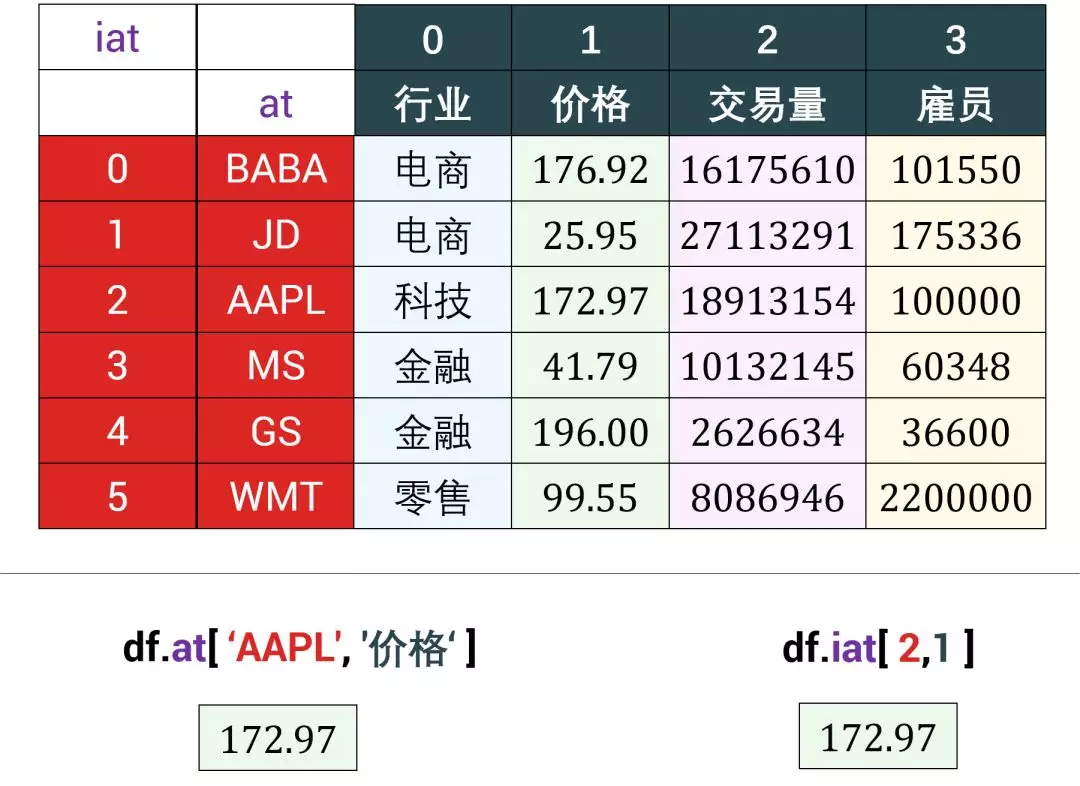
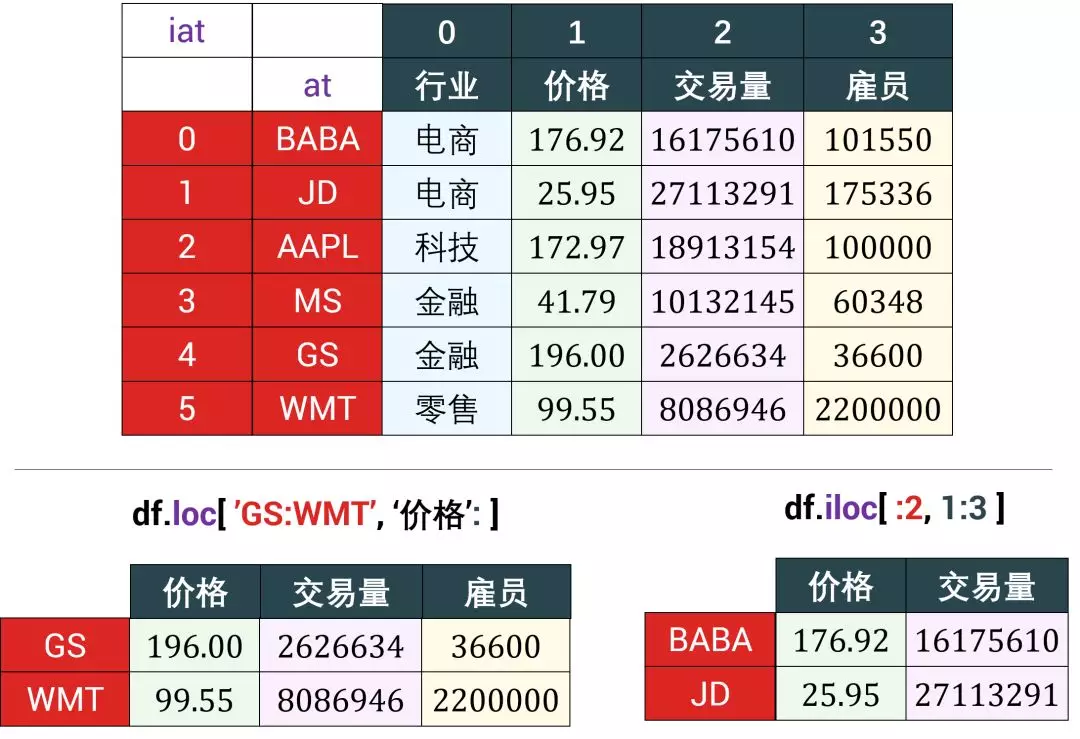
用不同颜色标注了 df 的 index, columns 和 values,视图如下:
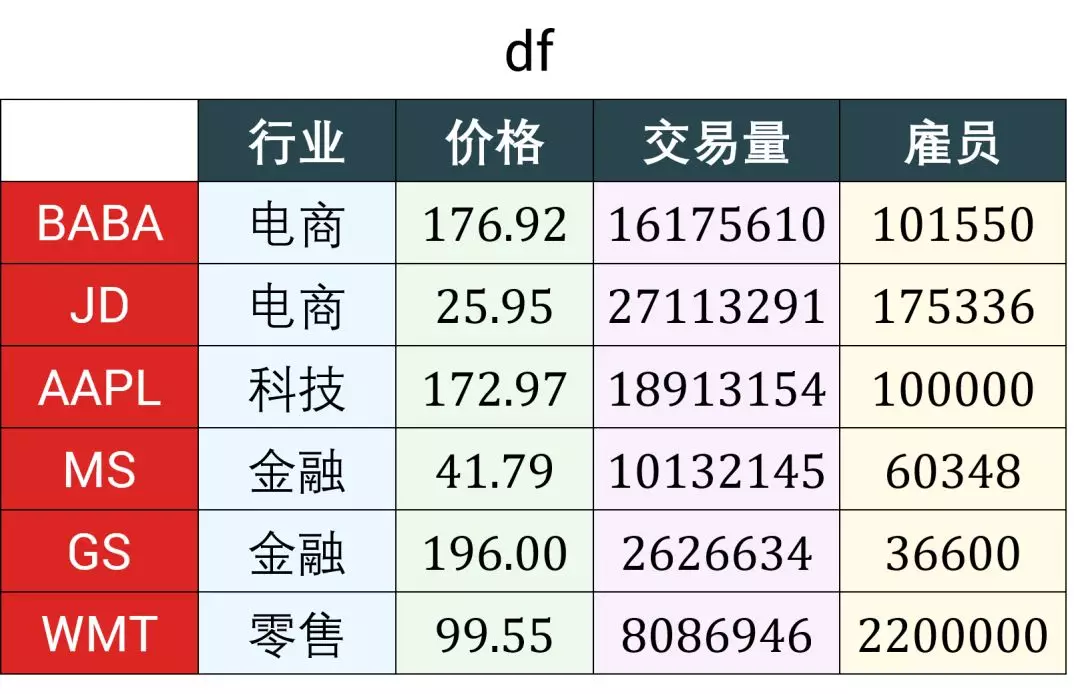
DataFrame 的索引或切片可以基于标签 (label-based) ,也可以基于位置 (position-based),不像 numpy 数组的索引或切片只基于位置。
DataFrame 的索引或切片有四大类:
- 索引单元素:
- 基于标签的 at
- 基于位置的 iat
- 切片 columns:
- 用 . 来切片单列
- 用 [] 来切片单列或多列
- 基于标签的 loc
- 基于位置的 iloc
- 切片 index:
- 用 [] 来切片单行或多行
- 基于标签的 loc
- 基于位置的 iloc
- 切片 index 和 columns:
- 基于标签的 loc
- 基于位置的 iloc
总体规律,基于标签就用 at 和 loc,基于位置就用 iat 和 iloc。下面我们来一类类分析:
3.1 索引单元素
两种方法来索引单元素,情况 1 基于标签 at,情况 2 基于位置 iat。
- 情况 1 - df.at[‘idx_i’, ‘attr_j’]
- 情况 2 - df.iat[i, j]
df.at['AAPL','价格'] # 用 at 获取「行标签」为 'AAPL' 和「列标签」为 ‘价格’ 对应的元素。
172.97
df.iat[2,1] # 用 iat 获取第 3 行第 2 列对应的元素。
172.97
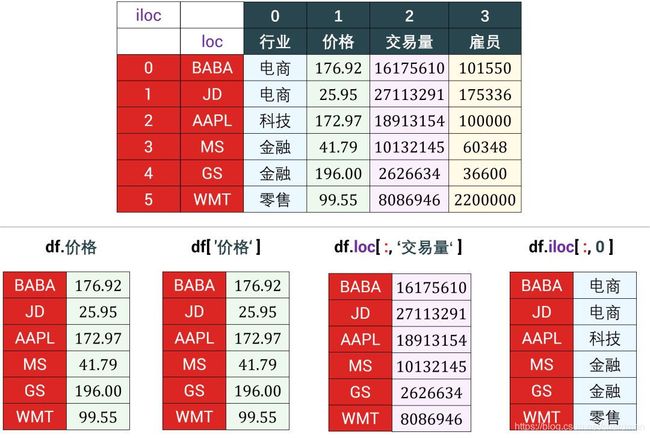
3.2 切片columns
切片单个column
切片单个 columns 会返回一个 Series,有以下四种情况。
-
情况 1 - df.attr_i
-
情况 2 - df[‘attr_i’]
-
情况 3 - df.loc[:, ‘attr_i’]
-
情况 4 - df.iloc[:, i]
-
情况 1 记住就可以了,没什么可说的。
-
情况 2 非常像二维 numpy 数组 arr 的切片,用 arr[i] 就能获取 arr 在「轴 0」上的第 i 个元素 (一个 1darray),同理 df[‘attr_i’] 也能获取 df 的第 i 个 Series。
-
情况 3 和 4 的 loc 和 iloc 可类比于上面的 at 和 iat。带 i 的基于位置 (位置用整数表示,i 也泛指整数),不带 i 的基于标签。里面的冒号 : 代表所有的 index (和 numpy 数组里的冒号意思相同)。
建议,如果追求简洁和方便,用 . 和 [];如果追求一致和清晰,用 loc 和 iloc。
# 情况1:用 . 获取「价格」那一栏下的 Series。
df.价格
代号
BABA 176.92
JD 25.95
AAPL 172.97
MS 41.79
GS 196.00
WMT 99.55
Name: 价格, dtype: float64
# 情况 2:用 [] 获取「价格」属性下的 Series。
df['价格']
代号
BABA 176.92
JD 25.95
AAPL 172.97
MS 41.79
GS 196.00
WMT 99.55
Name: 价格, dtype: float64
# 情况 3:用 loc 获取「交易量」属性下的 Series。
df.loc[:, '交易量']
代号
BABA 16175610
JD 27113291
AAPL 18913154
MS 10132145
GS 2626634
WMT 8086946
Name: 交易量, dtype: int64
# 情况 4:用 iloc 获取第 1 列下的 Series。
df.iloc[:, 0]
代号
BABA 电商
JD 电商
AAPL 科技
MS 金融
GS 金融
WMT 零售
Name: 行业, dtype: object
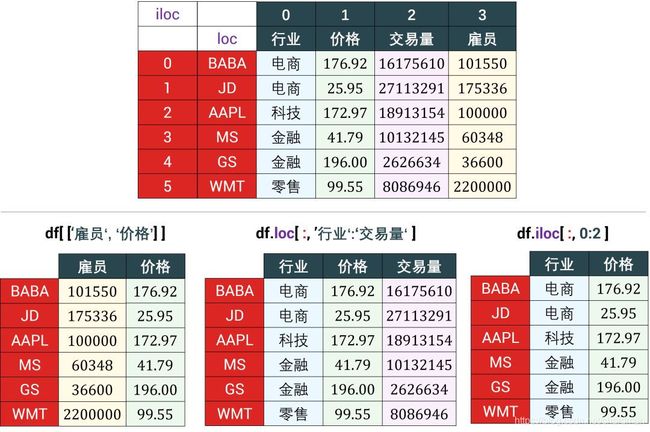
切片多个 columns
切片多个 columns 会返回一个 sub-DataFrame (原 DataFrame 的子集),有以下三种情况。
- 情况 1 - df[[‘attr_i’, ‘attr_j’]]
- 情况 2 - df.loc[:, ‘attr_i’:‘attr_j’]
- 情况 3 - df.iloc[:, i:j]
和切片单个 columns 相比:
- 情况 1 用一个列表来储存一组属性 ‘attr_i’, ‘attr_j’,然后在放进中括号 [] 里获取它们
- 情况 2 用 ‘attr_i’:‘attr_j’ 来获取从属性 i 到属性 j 的 sub-DataFrame
- 情况 3 用 i:j 来获取从列 i 到列 j-1 的 sub-DataFrame
# 情况1:用 [] 获取「雇员」和「价格」两个属性下的 sub-DataFrame。
df[ ['雇员', '价格'] ]
| 雇员 | 价格 | |
|---|---|---|
| 代号 | ||
| BABA | 101550 | 176.92 |
| JD | 175336 | 25.95 |
| AAPL | 100000 | 172.97 |
| MS | 60348 | 41.79 |
| GS | 36600 | 196.00 |
| WMT | 2200000 | 99.55 |
# 情况2:用 loc 获取从属性 ‘行业’ 到 ‘交易量‘ 的 sub-DataFrame。
df.loc[:, '行业':'交易量']
| 行业 | 价格 | 交易量 | |
|---|---|---|---|
| 代号 | |||
| BABA | 电商 | 176.92 | 16175610 |
| JD | 电商 | 25.95 | 27113291 |
| AAPL | 科技 | 172.97 | 18913154 |
| MS | 金融 | 41.79 | 10132145 |
| GS | 金融 | 196.00 | 2626634 |
| WMT | 零售 | 99.55 | 8086946 |
# 情况3:用 iloc 获取第 1 和 2 列下的 sub-DataFrame。
df.iloc[:, 0:2]
| 行业 | 价格 | |
|---|---|---|
| 代号 | ||
| BABA | 电商 | 176.92 |
| JD | 电商 | 25.95 |
| AAPL | 科技 | 172.97 |
| MS | 金融 | 41.79 |
| GS | 金融 | 196.00 |
| WMT | 零售 | 99.55 |
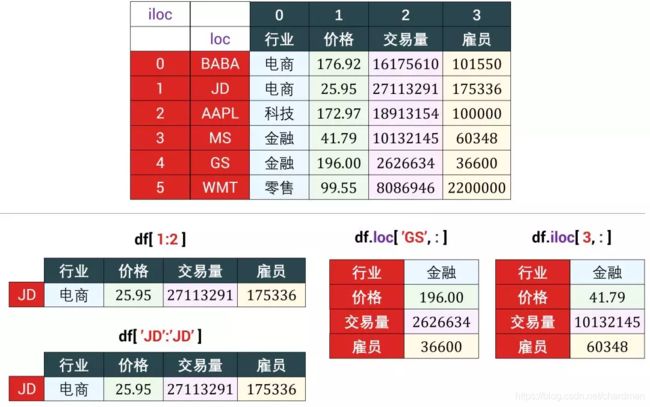
3.2 切片index
单个切片index
切片单个 index 有时会返回一行,有以下两种情况。
- 情况 1 - df.loc[‘idx_i’, :]
- 情况 2 - df.iloc[i, :]
- 情况 3 - df[i:i+1](必须有":")
- 情况 4 - df[‘idx_i’:‘idx_i’](必须有":")
情况 1 和 2 的 loc 和 iloc 可类比于上面的 at 和 iat。带 i 的基于位置 (位置用整数表示,i 也泛指整数),不带 i 的基于标签。里面的冒号 : 代表所有的 columns (和 numpy 数组里的冒号意思相同)。
情况3和情况4容易混淆,不建议使用。
# 情况1:用 loc 获取标签为 ‘GS‘ 的 Series。
df.loc[ 'GS', : ]
行业 金融
价格 196
交易量 2626634
雇员 36600
Name: GS, dtype: object
# 情况2:用 iloc 获取第 4 行下的 Series。
df.iloc[4, :]
行业 金融
价格 196
交易量 2626634
雇员 36600
Name: GS, dtype: object
# 情况3:用 [1:2] 获取第 2 行的 sub-DataFrame (只有一行)。
df[1:2]
| 行业 | 价格 | 交易量 | 雇员 | |
|---|---|---|---|---|
| 代号 | ||||
| JD | 电商 | 25.95 | 27113291 | 175336 |
# 情况4:用 ['JD':'JD'] 获取标签为 'JD' 的 sub-DataFrame (只有一行)。
df['JD':'JD']
| 行业 | 价格 | 交易量 | 雇员 | |
|---|---|---|---|---|
| 代号 | ||||
| JD | 电商 | 25.95 | 27113291 | 175336 |
切片多个index
切片多个 index 会返回一个 sub-DataFrame,有以下四种情况。
- 情况 1 - df[i:j]
- 情况 2 - df[‘idx_i’:‘idx_j’]
- 情况 3 - df.loc[‘idx_i’:‘idx_j’, :]
- 情况 4 - df.iloc[i:j, :]
建议,只用 loc 和 iloc。情况 1 和 2 的 df[] 很容易混淆中括号 [] 里的到底是切片 index 还是 columns。
# 情况1:用 [1:4] 获取第 2 到 4 行的 sub-DataFrame。
df[ 1:4 ]
| 行业 | 价格 | 交易量 | 雇员 | |
|---|---|---|---|---|
| 代号 | ||||
| JD | 电商 | 25.95 | 27113291 | 175336 |
| AAPL | 科技 | 172.97 | 18913154 | 100000 |
| MS | 金融 | 41.79 | 10132145 | 60348 |
# 情况2:用 ['GS':'WMT'] 获取标签从'GS' 到 'WMT' 的 sub-DataFrame。
df[ 'GS':'WMT' ]
| 行业 | 价格 | 交易量 | 雇员 | |
|---|---|---|---|---|
| 代号 | ||||
| GS | 金融 | 196.00 | 2626634 | 36600 |
| WMT | 零售 | 99.55 | 8086946 | 2200000 |
# 情况3:用 loc 获取标签从 ‘MS‘ 到 'GS' 的 sub-DataFrame。
df.loc[ 'MS':'GS', : ]
| 行业 | 价格 | 交易量 | 雇员 | |
|---|---|---|---|---|
| 代号 | ||||
| MS | 金融 | 41.79 | 10132145 | 60348 |
| GS | 金融 | 196.00 | 2626634 | 36600 |
注意‘MS’:’GS’ 要按着 index 里面元素的顺序,要不然会返回一个空的 DataFrame,比如:
df.loc[ 'MS':'JD', : ]
| 行业 | 价格 | 交易量 | 雇员 | |
|---|---|---|---|---|
| 代号 |
# 情况4:用 iloc 获取第 2 到 3 行的 sub-DataFrame。
df.iloc[ 1:3, : ]
| 行业 | 价格 | 交易量 | 雇员 | |
|---|---|---|---|---|
| 代号 | ||||
| JD | 电商 | 25.95 | 27113291 | 175336 |
| AAPL | 科技 | 172.97 | 18913154 | 100000 |

3.4 切片多个index和columns
切片多个 index 和 columns 会返回一个 sub-DataFrame,有以下两种情况。
- 情况 1 - df.loc[‘idx_i’:‘idx_j’, ‘attr_k’:‘attr_l’]
- 情况 2 - df.iloc[i:j, k:l]
# 情况1:用 loc 获取行标签从 ‘GS‘ 到 'WMT',列标签从'价格'到最后的 sub-DataFrame。
df.loc[ 'GS':'WMT', '价格': ]
| 价格 | 交易量 | 雇员 | |
|---|---|---|---|
| 代号 | |||
| GS | 196.00 | 2626634 | 36600 |
| WMT | 99.55 | 8086946 | 2200000 |
# 情况2:用 iloc 获取第 1 到 2 行,第 1 到 2 列的 sub-DataFrame。
df.iloc[ :2, 1:3 ]
| 价格 | 交易量 | |
|---|---|---|
| 代号 | ||
| BABA | 176.92 | 16175610 |
| JD | 25.95 | 27113291 |
3.5 高级索引
高级索引 (advanced indexing) 可以用布尔索引 (boolean indexing) 和调用函数 (callable function) 来实现,两种方法都返回一组“正确”的索引,而且可以和 loc , iloc , [] 一起套用,具体形式有以下常见几种:
- df.loc[布尔索引, :]
- df.iloc[布尔索引, :]
- df[布尔索引]
- df.loc[调用函数, :]
- df.iloc[调用函数, :]
- df[调用函数]
还有以下罕见几种:
- df.loc[:, 布尔索引]
- df.iloc[:, 布尔索引]
- df.loc[:, 调用函数]
- df.iloc[:, 调用函数]
布尔索引
# 当我们要过滤掉雇员小于 100,000 人的公司,我们可以用 loc 加上布尔索引。
print( df.雇员 >= 100000 )
df.loc[ df.雇员 >= 100000, : ]
代号
BABA True
JD True
AAPL True
MS False
GS False
WMT True
Name: 雇员, dtype: bool
| 行业 | 价格 | 交易量 | 雇员 | |
|---|---|---|---|---|
| 代号 | ||||
| BABA | 电商 | 176.92 | 16175610 | 101550 |
| JD | 电商 | 25.95 | 27113291 | 175336 |
| AAPL | 科技 | 172.97 | 18913154 | 100000 |
| WMT | 零售 | 99.55 | 8086946 | 2200000 |
# 一种更简便的表达形式是用 df[],但可能会引起「到底在切片 index 还是 columns」的歧义。
df[ df.雇员 >= 100000 ]
| 行业 | 价格 | 交易量 | 雇员 | |
|---|---|---|---|---|
| 代号 | ||||
| BABA | 电商 | 176.92 | 16175610 | 101550 |
| JD | 电商 | 25.95 | 27113291 | 175336 |
| AAPL | 科技 | 172.97 | 18913154 | 100000 |
| WMT | 零售 | 99.55 | 8086946 | 2200000 |
# 找到所有值为整数型的 columns
print( df.dtypes == 'int64' )
df.loc[ :, df.dtypes == 'int64' ]
行业 False
价格 False
交易量 True
雇员 True
dtype: bool
| 交易量 | 雇员 | |
|---|---|---|
| 代号 | ||
| BABA | 16175610 | 101550 |
| JD | 27113291 | 175336 |
| AAPL | 18913154 | 100000 |
| MS | 10132145 | 60348 |
| GS | 2626634 | 36600 |
| WMT | 8086946 | 2200000 |
调用函数
调用函数是只能有一个参数 (DataFrame, Series) 并返回一组索引的函数。
# 当我们要找出交易量大于平均交易量的所有公司,我们可以用 loc 加上匿名函数 (这里 x 代表 df)。
df.loc[ lambda x: x.交易量 > x.交易量.mean() , : ]
| 行业 | 价格 | 交易量 | 雇员 | |
|---|---|---|---|---|
| 代号 | ||||
| BABA | 电商 | 176.92 | 16175610 | 101550 |
| JD | 电商 | 25.95 | 27113291 | 175336 |
| AAPL | 科技 | 172.97 | 18913154 | 100000 |
# 在上面基础上再加一个条件 -- 价格要在 100 之上 (这里 x 还是代表 df)
df.loc[ lambda x: (x.交易量 > x.交易量.mean()) & (x.价格 > 100), : ]
| 行业 | 价格 | 交易量 | 雇员 | |
|---|---|---|---|---|
| 代号 | ||||
| BABA | 电商 | 176.92 | 16175610 | 101550 |
| AAPL | 科技 | 172.97 | 18913154 | 100000 |
3.6 多层索引
多层索引Series
首先定义一个 Series,注意它的 index 是一个二维列表,列表第一行 dates 作为第一层索引,第二行 codes 作为第二层索引。
price = [190,32,196,192,200,189,31,30,199]
dates = ['2019-04-01']*3 + ['2019-04-02']*2\
+['2019-04-03']*2 + ['2019-04-04']*2
codes = ['BABA','JD','GS','BABA','GS','BABA','JD','JD','GS']
data = pd.Series( price,
index=[ dates, codes ])
data
2019-04-01 BABA 190
JD 32
GS 196
2019-04-02 BABA 192
GS 200
2019-04-03 BABA 189
JD 31
2019-04-04 JD 30
GS 199
dtype: int64
data.index # 输出是一个 MultiIndex 的对象,里面有 levels 和 labels 二类信息。
MultiIndex([('2019-04-01', 'BABA'),
('2019-04-01', 'JD'),
('2019-04-01', 'GS'),
('2019-04-02', 'BABA'),
('2019-04-02', 'GS'),
('2019-04-03', 'BABA'),
('2019-04-03', 'JD'),
('2019-04-04', 'JD'),
('2019-04-04', 'GS')],
)
索引既然分多层,那么肯定分「内层」和「外层」把,levels 就是描述层的先后的。levels 是一个二维列表,每一行只存储着「唯一」的索引信息:
- dates 是第一层索引,有 4 个「唯一」元素
- codes 是第二层索引,有 3 个「唯一」元素
但是 data 里面有九行啊,4 个 dates 和 3 个 codes 怎么能描述这九行信息呢?这就需要 labels 了。labels 也是一个二维列表:
- 第一行储存 dates 每个元素在 data 里的位置索引
- 第二行储存 codes 每个元素在 data 里的位置索引
# 用 [] 加第一层索引可以获取第一层信息。
data['2019-04-02']
BABA 192
GS 200
dtype: int64
# 用 loc 加第一层索引也可以切片获取第一层信息
data.loc['2019-04-02':'2019-04-04']
2019-04-02 BABA 192
GS 200
2019-04-03 BABA 189
JD 31
2019-04-04 JD 30
GS 199
dtype: int64
# loc 中的冒号 : 表示第一层所有元素,‘GS’ 表示第二层标签为 ‘GS’。
data.loc[ :, 'GS' ]
2019-04-01 196
2019-04-02 200
2019-04-04 199
dtype: int64
多层索引DataFrame
data = [ ['电商', 101550, 176.92, 16175610],
['电商', 175336, 25.95, 27113291],
['金融', 60348, 41.79, 10132145],
['金融', 36600, 196.00, 2626634] ]
midx = pd.MultiIndex(
levels=[['中国','美国'],
['BABA', 'JD', 'GS', 'MS']],
codes=[[0,0,1,1],[0,1,2,3]],
names=['地区', '代号'])
mcol = pd.MultiIndex(
levels=[['公司数据','交易数据'],
['行业','雇员','价格','交易量']],
codes=[[0,0,1,1],[0,1,2,3]],
names=['概括','细分'])
df = pd.DataFrame(data, index=midx, columns=mcol)
df
| 概括 | 公司数据 | 交易数据 | |||
|---|---|---|---|---|---|
| 细分 | 行业 | 雇员 | 价格 | 交易量 | |
| 地区 | 代号 | ||||
| 中国 | BABA | 电商 | 101550 | 176.92 | 16175610 |
| JD | 电商 | 175336 | 25.95 | 27113291 | |
| 美国 | GS | 金融 | 60348 | 41.79 | 10132145 |
| MS | 金融 | 36600 | 196.00 | 2626634 | |
这个 DataFrame 的 index 和 columns 都有两层,严格来说是个四维数据。
codes的解释:
如果令a = [‘中国’,‘美国’],b = [‘BABA’, ‘JD’, ‘GS’, ‘MS’]
- codes的第一个[0,0,1,1]就表示a[0],a[0],a[1],a[1],即[‘中国’,‘中国’,‘美国’,‘美国’];
- codes的第二个[0,1,2,3]就表示b[0],b[1],b[2],b[3],即[‘BABA’, ‘JD’, ‘GS’, ‘MS’]
所以index组成了[(‘中国’,‘BABA’),(‘中国’,‘JD’),(‘美国’,‘GS’),(‘美国’,‘MS’)]。
# 在第一层 columns 的 ‘公司数据’ 和第二层 columns 的 ‘行业’ 做索引,得到一个含两层 index 的 Series。
df['公司数据','行业']
地区 代号
中国 BABA 电商
JD 电商
美国 GS 金融
MS 金融
Name: (公司数据, 行业), dtype: object
# 在第一层 index 的 ‘中国’ 做切片,得到一个含两层 columns 的 DataFrame。
df.loc['中国']
| 概括 | 公司数据 | 交易数据 | ||
|---|---|---|---|---|
| 细分 | 行业 | 雇员 | 价格 | 交易量 |
| 代号 | ||||
| BABA | 电商 | 101550 | 176.92 | 16175610 |
| JD | 电商 | 175336 | 25.95 | 27113291 |
df.loc['中国'].loc['BABA':'JD']
| 概括 | 公司数据 | 交易数据 | ||
|---|---|---|---|---|
| 细分 | 行业 | 雇员 | 价格 | 交易量 |
| 代号 | ||||
| BABA | 电商 | 101550 | 176.92 | 16175610 |
| JD | 电商 | 175336 | 25.95 | 27113291 |
调位 level
可用 swaplevel 调整index level,column level 的顺序
df.swaplevel('地区', '代号')
| 概括 | 公司数据 | 交易数据 | |||
|---|---|---|---|---|---|
| 细分 | 行业 | 雇员 | 价格 | 交易量 | |
| 代号 | 地区 | ||||
| BABA | 中国 | 电商 | 101550 | 176.92 | 16175610 |
| JD | 中国 | 电商 | 175336 | 25.95 | 27113291 |
| GS | 美国 | 金融 | 60348 | 41.79 | 10132145 |
| MS | 美国 | 金融 | 36600 | 196.00 | 2626634 |
df.columns.swaplevel('概括','细分')
df
| 细分 | 行业 | 雇员 | 价格 | 交易量 | |
|---|---|---|---|---|---|
| 概括 | 公司数据 | 公司数据 | 交易数据 | 交易数据 | |
| 地区 | 代号 | ||||
| 中国 | BABA | 电商 | 101550 | 176.92 | 16175610 |
| JD | 电商 | 175336 | 25.95 | 27113291 | |
| 美国 | GS | 金融 | 60348 | 41.79 | 10132145 |
| MS | 金融 | 36600 | 196.00 | 2626634 |
df.columns = df.columns.swaplevel(0,1)
df
| 概括 | 公司数据 | 交易数据 | |||
|---|---|---|---|---|---|
| 细分 | 行业 | 雇员 | 价格 | 交易量 | |
| 地区 | 代号 | ||||
| 中国 | BABA | 电商 | 101550 | 176.92 | 16175610 |
| JD | 电商 | 175336 | 25.95 | 27113291 | |
| 美国 | GS | 金融 | 60348 | 41.79 | 10132145 |
| MS | 金融 | 36600 | 196.00 | 2626634 | |
重设 index
一个 DataFrame 的一个或者多个 columns 适合做 index,这时可用 set_index 将它们设置为 index,如果要将 index 还原成 columns,那么用 reset_index 。
data = {'地区': ['中国', '中国', '美国', '美国'],
'代号': ['BABA', 'JD', 'MS', 'GS'],
'行业': ['电商', '电商', '金融', '金融'],
'价格': [176.92, 25.95, 41.79, 196.00],
'交易量': [16175610, 27113291, 10132145, 2626634],
'雇员': [101550, 175336, 60348, 36600] }
df = pd.DataFrame( data )
df
| 地区 | 代号 | 行业 | 价格 | 交易量 | 雇员 | |
|---|---|---|---|---|---|---|
| 0 | 中国 | BABA | 电商 | 176.92 | 16175610 | 101550 |
| 1 | 中国 | JD | 电商 | 25.95 | 27113291 | 175336 |
| 2 | 美国 | MS | 金融 | 41.79 | 10132145 | 60348 |
| 3 | 美国 | GS | 金融 | 196.00 | 2626634 | 36600 |
df2 = df.set_index( ['地区','代号'] ) #将地区和代号设为index
df2
| 行业 | 价格 | 交易量 | 雇员 | ||
|---|---|---|---|---|---|
| 地区 | 代号 | ||||
| 中国 | BABA | 电商 | 176.92 | 16175610 | 101550 |
| JD | 电商 | 25.95 | 27113291 | 175336 | |
| 美国 | MS | 金融 | 41.79 | 10132145 | 60348 |
| GS | 金融 | 196.00 | 2626634 | 36600 |
df2.reset_index() # 用reset_index()函数,可以将所有index重设成columns
| 地区 | 代号 | 行业 | 价格 | 交易量 | 雇员 | |
|---|---|---|---|---|---|---|
| 0 | 中国 | BABA | 电商 | 176.92 | 16175610 | 101550 |
| 1 | 中国 | JD | 电商 | 25.95 | 27113291 | 175336 |
| 2 | 美国 | MS | 金融 | 41.79 | 10132145 | 60348 |
| 3 | 美国 | GS | 金融 | 196.00 | 2626634 | 36600 |
4 数据表的合并和连接
数据表可以按「键」合并,用 merge 函数;可以按「轴」来连接,用 concat 函数。
4.1 合并
按键 (key) 合并可以分「单键合并」和「多键合并」。
单键合并
单键合并用 merge 函数,语法如下:
pd.merge( df1, df2, how=s, on=c )
c 是 df1 和 df2 共有的一栏,合并方式 (how=s) 有四种:
- 左连接 (left join):合并之后显示 df1 的所有行
- 右连接 (right join):合并之后显示 df2 的所有行
- 外连接 (outer join):合并所有行 (默认情况)
- 内连接 (inner join):合并 df1 和 df2 共有的所有行
首先创建两个 DataFrame:
- df_price:4 天的价格 (2019-01-01 到 2019-01-04)
- df_volume:5 天的交易量 (2019-01-02 到 2019-01-06)
df_price = pd.DataFrame( {'Date': pd.date_range('2019-1-1', periods=4),
'Adj Close': [24.42, 25.00, 25.25, 25.64]})
df_price
| Date | Adj Close | |
|---|---|---|
| 0 | 2019-01-01 | 24.42 |
| 1 | 2019-01-02 | 25.00 |
| 2 | 2019-01-03 | 25.25 |
| 3 | 2019-01-04 | 25.64 |
df_volume = pd.DataFrame( {'Date': pd.date_range('2019-1-2', periods=5),
'Volume' : [56081400, 99455500, 83028700, 100234000, 73829000]})
df_volume
| Date | Volume | |
|---|---|---|
| 0 | 2019-01-02 | 56081400 |
| 1 | 2019-01-03 | 99455500 |
| 2 | 2019-01-04 | 83028700 |
| 3 | 2019-01-05 | 100234000 |
| 4 | 2019-01-06 | 73829000 |
# left:合并后显示第一个数据表的所有行
pd.merge( df_price, df_volume, how='left' )
| Date | Adj Close | Volume | |
|---|---|---|---|
| 0 | 2019-01-01 | 24.42 | NaN |
| 1 | 2019-01-02 | 25.00 | 56081400.0 |
| 2 | 2019-01-03 | 25.25 | 99455500.0 |
| 3 | 2019-01-04 | 25.64 | 83028700.0 |
按 df_price 里 Date 栏里的值来合并数据
- df_volume 里 Date 栏里没有 2019-01-01,因此 Volume 为 NaN
- df_volume 里 Date 栏里的 2019-01-05 和 2019-01-06 不在 df_price 里 Date 栏,因此丢弃
# right: 合并后显示第二个数据表的所有行
pd.merge( df_price, df_volume, how='right' )
| Date | Adj Close | Volume | |
|---|---|---|---|
| 0 | 2019-01-02 | 25.00 | 56081400 |
| 1 | 2019-01-03 | 25.25 | 99455500 |
| 2 | 2019-01-04 | 25.64 | 83028700 |
| 3 | 2019-01-05 | NaN | 100234000 |
| 4 | 2019-01-06 | NaN | 73829000 |
按 df_volume 里 Date 栏里的值来合并数据
- df_price 里 Date 栏里没有 2019-01-05 和 2019-01-06,因此 Adj Close 为 NaN
- df_price 里 Date 栏里的 2019-01-01 不在 df_volume 里 Date 栏,因此丢弃
# outer:合并之后显示两个数据表所有的行
pd.merge( df_price, df_volume, how='outer' )
| Date | Adj Close | Volume | |
|---|---|---|---|
| 0 | 2019-01-01 | 24.42 | NaN |
| 1 | 2019-01-02 | 25.00 | 56081400.0 |
| 2 | 2019-01-03 | 25.25 | 99455500.0 |
| 3 | 2019-01-04 | 25.64 | 83028700.0 |
| 4 | 2019-01-05 | NaN | 100234000.0 |
| 5 | 2019-01-06 | NaN | 73829000.0 |
按 df_price 和 df_volume 里 Date 栏里的所有值来合并数据
- df_price 里 Date 栏里没有 2019-01-05 和 2019-01-06,因此 Adj Close 为 NaN
- df_volume 里 Date 栏里没有 2019-01-01,因此 Volume 为 NaN
# inner:合并了两个数据表共有的行
pd.merge( df_price, df_volume, how='inner' )
| Date | Adj Close | Volume | |
|---|---|---|---|
| 0 | 2019-01-02 | 25.00 | 56081400 |
| 1 | 2019-01-03 | 25.25 | 99455500 |
| 2 | 2019-01-04 | 25.64 | 83028700 |
按 df_price 和 df_volume 里 Date 栏里的共有值来合并数据
- df_price 里 Date 栏里的 2019-01-01 不在 df_volume 里 Date 栏,因此丢弃
- df_volume 里 Date 栏里的 2019-01-05 和 2019-01-06 不在 df_price 里 Date 栏,因此丢弃
多建合并
多键合并用的语法和单键合并一样,只不过 on=c 中的 c 是多栏。
pd.merge( df1, df2, how=s, on=c )
首先创建两个 DataFrame:
- portfolio1:3 笔产品 FX Option, FX Swap 和 IR Option 的数量
- portfolio2:4 笔产品 FX Option (重复名称), FX Swap 和 IR Swap 的数量
porfolio1 = pd.DataFrame({'Asset': ['FX', 'FX', 'IR'],
'Instrument': ['Option', 'Swap', 'Option'],
'Number': [1, 2, 3]})
porfolio1
| Asset | Instrument | Number | |
|---|---|---|---|
| 0 | FX | Option | 1 |
| 1 | FX | Swap | 2 |
| 2 | IR | Option | 3 |
porfolio2 = pd.DataFrame({'Asset': ['FX', 'FX', 'FX', 'IR'],
'Instrument': ['Option', 'Option', 'Swap', 'Swap'],
'Number': [4, 5, 6, 7]})
porfolio2
| Asset | Instrument | Number | |
|---|---|---|---|
| 0 | FX | Option | 4 |
| 1 | FX | Option | 5 |
| 2 | FX | Swap | 6 |
| 3 | IR | Swap | 7 |
# 在 'Asset' 和 'Instrument' 两个键上做外合并
pd.merge( porfolio1, porfolio2,
on=['Asset','Instrument'],
how='outer')
| Asset | Instrument | Number_x | Number_y | |
|---|---|---|---|---|
| 0 | FX | Option | 1.0 | 4.0 |
| 1 | FX | Option | 1.0 | 5.0 |
| 2 | FX | Swap | 2.0 | 6.0 |
| 3 | IR | Option | 3.0 | NaN |
| 4 | IR | Swap | NaN | 7.0 |
df1 和 df2 中两个键都有 FX Option 和 FX Swap,因此可以合并它们中 number 那栏。
- df1 中有 IR Option 而 df2 中没有,因此 Number_y 栏下的值为 NaN
- df2 中有 IR Swap 而 df1 中没有,因此 Number_x 栏下的值为 NaN
注:当 df1 和 df2 有两个相同的列 (Asset 和 Instrument) 时,单单只对一列 (Asset) 做合并产出的 DataFrame 会有另一列 (Instrument) 重复的名称。这时 merge 函数给重复的名称加个后缀 _x, _y 等等。
pd.merge( porfolio1, porfolio2,
on='Asset' )
| Asset | Instrument_x | Number_x | Instrument_y | Number_y | |
|---|---|---|---|---|---|
| 0 | FX | Option | 1 | Option | 4 |
| 1 | FX | Option | 1 | Option | 5 |
| 2 | FX | Option | 1 | Swap | 6 |
| 3 | FX | Swap | 2 | Option | 4 |
| 4 | FX | Swap | 2 | Option | 5 |
| 5 | FX | Swap | 2 | Swap | 6 |
| 6 | IR | Option | 3 | Swap | 7 |
如果觉得后缀 _x, _y 没有什么具体含义时,可以设定 suffixes 来改后缀。比如 df1 和 df2 存储的是 portoflio1 和 portfolio2 的产品信息,那么将后缀该成 ‘1’ 和 ‘2’ 更贴切。
pd.merge( porfolio1, porfolio2,
on=['Asset','Instrument'],
suffixes=('1','2'))
| Asset | Instrument | Number1 | Number2 | |
|---|---|---|---|---|
| 0 | FX | Option | 1 | 4 |
| 1 | FX | Option | 1 | 5 |
| 2 | FX | Swap | 2 | 6 |
4.2 连接
Numpy 数组可相互连接,用 np.concat;同理,Series 也可相互连接,DataFrame 也可相互连接,用 pd.concat。
连接Series
在 concat 函数也可设定参数 axis,
- axis = 0 (默认),沿着轴 0 (行) 连接,得到一个更长的 Series
- axis = 1,沿着轴 1 (列) 连接,得到一个 DataFrame
被连接的 Series 它们的 index 可以重复 (overlapping),也可以不同。
s1 = pd.Series([0, 1], index=['a', 'b'])
s2 = pd.Series([2, 3, 4], index=['c', 'd', 'e'])
s3 = pd.Series([5, 6], index=['f', 'g'])
pd.concat([s1, s2, s3]) # 连接s1,s2,s3,默认axis=0
a 0
b 1
c 2
d 3
e 4
f 5
g 6
dtype: int64
pd.concat([s1, s2, s3], axis=1)
| 0 | 1 | 2 | |
|---|---|---|---|
| a | 0.0 | NaN | NaN |
| b | 1.0 | NaN | NaN |
| c | NaN | 2.0 | NaN |
| d | NaN | 3.0 | NaN |
| e | NaN | 4.0 | NaN |
| f | NaN | NaN | 5.0 |
| g | NaN | NaN | 6.0 |
# 将 s1 和 s3 沿「轴 0」连接来创建 s4,这样 s4 和 s1 的 index 是有重复的。
s4 = pd.concat([s1,s3])
s4
a 0
b 1
f 5
g 6
dtype: int64
pd.concat([s1, s4]) # 沿axis=0连接的时候,允许index重复
a 0
b 1
a 0
b 1
f 5
g 6
dtype: int64
可以将 s1 和 s4 沿「轴 1」内连接 (即只连接它们共有 index 对应的值)
pd.concat([s1, s4], axis=1, join='inner')
| 0 | 1 | |
|---|---|---|
| a | 0 | 0 |
| b | 1 | 1 |
可以将 n 个 Series 沿「轴 0」连接起来,再赋予 3 个 keys 创建多层 Series
pd.concat( [s1, s1, s3], keys=['one','two','three'])
one a 0
b 1
two a 0
b 1
three f 5
g 6
dtype: int64
连接 DataFrame
连接 DataFrame 的逻辑和连接 Series 的一模一样。
沿着行连接
df1 = pd.DataFrame( np.arange(12).reshape(3,4),
columns=['a','b','c','d'])
df1
| a | b | c | d | |
|---|---|---|---|---|
| 0 | 0 | 1 | 2 | 3 |
| 1 | 4 | 5 | 6 | 7 |
| 2 | 8 | 9 | 10 | 11 |
df2 = pd.DataFrame( np.arange(6).reshape(2,3),
columns=['b','d','a'])
df2
| b | d | a | |
|---|---|---|---|
| 0 | 0 | 1 | 2 |
| 1 | 3 | 4 | 5 |
沿着行连接分两步
- 先把 df1 和 df2 列标签补齐
- 再把 df1 和 df2 纵向连起来
pd.concat( [df1, df2] )
| a | b | c | d | |
|---|---|---|---|---|
| 0 | 0 | 1 | 2.0 | 3 |
| 1 | 4 | 5 | 6.0 | 7 |
| 2 | 8 | 9 | 10.0 | 11 |
| 0 | 2 | 0 | NaN | 1 |
| 1 | 5 | 3 | NaN | 4 |
得到的 DataFrame 的 index = [0,1,2,0,1],有重复值。如果 index 不包含重要信息 (如上例),可以将 ignore_index 设置为 True,这样就得到默认的 index 值了。
pd.concat( [df1, df2], ignore_index=True )
| a | b | c | d | |
|---|---|---|---|---|
| 0 | 0 | 1 | 2.0 | 3 |
| 1 | 4 | 5 | 6.0 | 7 |
| 2 | 8 | 9 | 10.0 | 11 |
| 3 | 2 | 0 | NaN | 1 |
| 4 | 5 | 3 | NaN | 4 |
pd.concat( [df1, df2], join='inner', ignore_index=True) # 也可以只取相同的部分
| a | b | d | |
|---|---|---|---|
| 0 | 0 | 1 | 3 |
| 1 | 4 | 5 | 7 |
| 2 | 8 | 9 | 11 |
| 3 | 2 | 0 | 1 |
| 4 | 5 | 3 | 4 |
沿着列连接
df1 = pd.DataFrame( np.arange(6).reshape(3,2),
index=['a','b','c'],
columns=['one','two'] )
df1
| one | two | |
|---|---|---|
| a | 0 | 1 |
| b | 2 | 3 |
| c | 4 | 5 |
df2 = pd.DataFrame( 5 + np.arange(4).reshape(2,2),
index=['a','c'],
columns=['three','four'])
df2
| three | four | |
|---|---|---|
| a | 5 | 6 |
| c | 7 | 8 |
沿着列连接分两步
- 先把 df1 和 df2 行标签补齐
- 再把 df1 和 df2 横向连起来
pd.concat([df1,df2], axis=1)
| one | two | three | four | |
|---|---|---|---|---|
| a | 0 | 1 | 5.0 | 6.0 |
| b | 2 | 3 | NaN | NaN |
| c | 4 | 5 | 7.0 | 8.0 |
5 数据表的重塑和透视
重塑 (reshape) 和透视 (pivot) 两个操作只改变数据表的布局 (layout):
- 重塑用 stack 和 unstack 函数 (互为逆转操作)
- 透视用 pivot 和 melt 函数 (互为逆转操作)
5.1 重塑
DataFrame 和「多层索引的 Series」其实维度是一样,只是展示形式不同。而重塑就是通过改变数据表里面的「行索引」和「列索引」来改变展示形式。
- 列索引 → 行索引,用 stack 函数
- 行索引 → 列索引,用 unstack 函数
单层DataFrame
创建 DataFrame df (1 层行索引,1 层列索引)
symbol = ['JD', 'AAPL']
data = {'行业': ['电商', '科技'],
'价格': [25.95, 172.97],
'交易量': [27113291, 18913154]}
df = pd.DataFrame( data, index=symbol )
df.columns.name = '特征'
df.index.name = '代号'
df
| 特征 | 行业 | 价格 | 交易量 |
|---|---|---|---|
| 代号 | |||
| JD | 电商 | 25.95 | 27113291 |
| AAPL | 科技 | 172.97 | 18913154 |
- 行索引 = [JD, AAPL],名称是代号
- 列索引 = [行业, 价格, 交易量],名称是特征
stack: 列索引 → 行索引
列索引 (特征) 变成了行索引,原来的 DataFrame 变成了两层 Series (第一层索引是代号,第二层索引是特征)。
c2i_Series = df.stack()
c2i_Series
代号 特征
JD 行业 电商
价格 25.95
交易量 27113291
AAPL 行业 科技
价格 172.97
交易量 18913154
dtype: object
unstack: 行索引 → 列索引
行索引 (代号) 变成了列索引,原来的 DataFrame df 也变成了两层 Series (第一层索引是特征,第二层索引是代号)。
i2c_Series = df.unstack()
i2c_Series
特征 代号
行业 JD 电商
AAPL 科技
价格 JD 25.95
AAPL 172.97
交易量 JD 27113291
AAPL 18913154
dtype: object
df.index, df.columns
(Index(['JD', 'AAPL'], dtype='object', name='代号'),
Index(['行业', '价格', '交易量'], dtype='object', name='特征'))
c2i_Series.index
MultiIndex([( 'JD', '行业'),
( 'JD', '价格'),
( 'JD', '交易量'),
('AAPL', '行业'),
('AAPL', '价格'),
('AAPL', '交易量')],
names=['代号', '特征'])
i2c_Series.index
MultiIndex([( '行业', 'JD'),
( '行业', 'AAPL'),
( '价格', 'JD'),
( '价格', 'AAPL'),
('交易量', 'JD'),
('交易量', 'AAPL')],
names=['特征', '代号'])
定义
- r = [JD, AAPL],名称是代号
- c = [行业, 价格, 交易量],名称是特征
那么
- df 的行索引 = r
- df 的列索引 = c
- c2i_Series 的索引 = [r, c]
- i2c_Series 的索引 = [c, r]
规律:
- 当用 stack 将 df 变成 c2i_Series 时,df 的列索引 c 加在其行索引 r 后面得到 [r, c] 做为 c2i_Series 的多层索引
- 当用 unstack 将 df 变成 i2c_Series 时,df 的行索引 r 加在其列索引 c 后面得到 [c, r] 做为 i2c_Series 的多层索引
基于层和名称来 unstack
对于多层索引的 Series,unstack 哪一层有两种方法来确定:
- 基于层 (level-based)
- 基于名称 (name-based)
1. 基于层来 unstack() 时,没有填层数,默认为最后一层。
c2i_Series.unstack()
| 特征 | 行业 | 价格 | 交易量 |
|---|---|---|---|
| 代号 | |||
| JD | 电商 | 25.95 | 27113291 |
| AAPL | 科技 | 172.97 | 18913154 |
c2i_Series 的最后一层 (看上面它的 MultiIndex) 就是 [行业, 价格, 交易量],从行索引转成列索引得到上面的 DataFrame。
2. 基于层来 unstack() 时,选择第一层 (参数放 0)
c2i_Series.unstack(0)
| 代号 | JD | AAPL |
|---|---|---|
| 特征 | ||
| 行业 | 电商 | 科技 |
| 价格 | 25.95 | 172.97 |
| 交易量 | 27113291 | 18913154 |
c2i_Series 的第一层 (看上面它的 MultiIndex) 就是 [JD, AAPL],从行索引转成列索引得到上面的 DataFrame。
3. 基于名称来 unstack
c2i_Series.unstack('代号')
| 代号 | JD | AAPL |
|---|---|---|
| 特征 | ||
| 行业 | 电商 | 科技 |
| 价格 | 25.95 | 172.97 |
| 交易量 | 27113291 | 18913154 |
c2i_Series 的代号层 (看上面它的 MultiIndex) 就是 [JD, AAPL],从行索引转成列索引得到上面的 DataFrame。
多层DataFrame
data = [ ['电商', 101550, 176.92],
['电商', 175336, 25.95],
['金融', 60348, 41.79],
['金融', 36600, 196.00] ]
midx = pd.MultiIndex( levels=[['中国','美国'],
['BABA', 'JD', 'GS', 'MS']],
codes=[[0,0,1,1],[0,1,2,3]],
names = ['地区', '代号'])
mcol = pd.Index(['行业','雇员','价格'], name='特征')
df = pd.DataFrame( data, index=midx, columns=mcol )
df
| 特征 | 行业 | 雇员 | 价格 | |
|---|---|---|---|---|
| 地区 | 代号 | |||
| 中国 | BABA | 电商 | 101550 | 176.92 |
| JD | 电商 | 175336 | 25.95 | |
| 美国 | GS | 金融 | 60348 | 41.79 |
| MS | 金融 | 36600 | 196.00 |
- 行索引第一层 = r1 = [中国, 美国],名称是地区
- 行索引第二层 = r2 = [BABA, JD, GS, MS],名称是代号
- 列索引 = c = [行业, 雇员, 价格],名称是特征
df.index, df.columns
(MultiIndex([('中国', 'BABA'),
('中国', 'JD'),
('美国', 'GS'),
('美国', 'MS')],
names=['地区', '代号']),
Index(['行业', '雇员', '价格'], dtype='object', name='特征'))
这个时候
- df 的行索引 = [r1, r2]
- df 的列索引 = c
1. 基于层来 unstack() 时,选择第一层 (参数放 0)
df.unstack(0)
| 特征 | 行业 | 雇员 | 价格 | |||
|---|---|---|---|---|---|---|
| 地区 | 中国 | 美国 | 中国 | 美国 | 中国 | 美国 |
| 代号 | ||||||
| BABA | 电商 | NaN | 101550.0 | NaN | 176.92 | NaN |
| JD | 电商 | NaN | 175336.0 | NaN | 25.95 | NaN |
| GS | NaN | 金融 | NaN | 60348.0 | NaN | 41.79 |
| MS | NaN | 金融 | NaN | 36600.0 | NaN | 196.00 |
df 被 unstack(0) 之后变成 (行 → 列)
- 行索引 = r2
- 列索引 = [c, r1]
重塑后的 DataFrame 这时行索引只有一层 (代号),而列索引有两层,第一层是特征,第二层是地区。
2. 基于层来 unstack() 时,选择第二层 (参数放 1)
df.unstack(1)
| 特征 | 行业 | 雇员 | 价格 | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 代号 | BABA | JD | GS | MS | BABA | JD | GS | MS | BABA | JD | GS | MS |
| 地区 | ||||||||||||
| 中国 | 电商 | 电商 | NaN | NaN | 101550.0 | 175336.0 | NaN | NaN | 176.92 | 25.95 | NaN | NaN |
| 美国 | NaN | NaN | 金融 | 金融 | NaN | NaN | 60348.0 | 36600.0 | NaN | NaN | 41.79 | 196.0 |
df 被 unstack(1) 之后变成 (行 → 列)
- 行索引 = r1
- 列索引 = [c, r2]
重塑后的 DataFrame 这时行索引只有一层 (地区),而列索引有两层,第一层是地区,第二层是代号。
3. 基于层先 unstack(0) 再 stack(0)
df.unstack(0).stack(0)
| 地区 | 中国 | 美国 | |
|---|---|---|---|
| 代号 | 特征 | ||
| BABA | 价格 | 176.92 | NaN |
| 行业 | 电商 | NaN | |
| 雇员 | 101550 | NaN | |
| JD | 价格 | 25.95 | NaN |
| 行业 | 电商 | NaN | |
| 雇员 | 175336 | NaN | |
| GS | 价格 | NaN | 41.79 |
| 行业 | NaN | 金融 | |
| 雇员 | NaN | 60348 | |
| MS | 价格 | NaN | 196 |
| 行业 | NaN | 金融 | |
| 雇员 | NaN | 36600 |
df 被 unstack(0) 之后变成 (行 → 列)
- 行索引 = r2
- 列索引 = [c, r1]
再被 stack(0) 之后变成 (列 → 行)
- 行索引 = [r2, c]
- 列索引 = r1
重塑后的 DataFrame 这时行索引有两层,第一层是代号,第二层是特征,而列索引只有一层 (地区)。
4. 基于层先 unstack(0) 再 stack(1)
df.unstack(0).stack(1)
| 特征 | 行业 | 雇员 | 价格 | |
|---|---|---|---|---|
| 代号 | 地区 | |||
| BABA | 中国 | 电商 | 101550.0 | 176.92 |
| JD | 中国 | 电商 | 175336.0 | 25.95 |
| GS | 美国 | 金融 | 60348.0 | 41.79 |
| MS | 美国 | 金融 | 36600.0 | 196.00 |
df 被 unstack(0) 之后变成 (行 → 列)
- 行索引 = r2
- 列索引 = [c, r1]
再被 stack(1) 之后变成 (列 → 行)
- 行索引 = [r2, r1]
- 列索引 = c
重塑后的 DataFrame 这时行索引有两层,第一层是代号,第二层是地区,而列索引只有一层 (特征)。
5. 基于层被 stack(),没有填层数,默认为最后一层。
df.stack()
地区 代号 特征
中国 BABA 行业 电商
雇员 101550
价格 176.92
JD 行业 电商
雇员 175336
价格 25.95
美国 GS 行业 金融
雇员 60348
价格 41.79
MS 行业 金融
雇员 36600
价格 196
dtype: object
df 被 stack() 之后变成 (列 → 行)
- 行索引 = [r1, r2, c]
- 列索引 = []
重塑后的 Series 只有行索引,有三层,第一层是地区,第二层是代号,第三层是特征。
6. 基于层被 unstack() 两次,没有填层数,默认为最后一层。
df.unstack().unstack()
特征 代号 地区
行业 BABA 中国 电商
美国 NaN
JD 中国 电商
美国 NaN
GS 中国 NaN
美国 金融
MS 中国 NaN
美国 金融
雇员 BABA 中国 101550
美国 NaN
JD 中国 175336
美国 NaN
GS 中国 NaN
美国 60348
MS 中国 NaN
美国 36600
价格 BABA 中国 176.92
美国 NaN
JD 中国 25.95
美国 NaN
GS 中国 NaN
美国 41.79
MS 中国 NaN
美国 196
dtype: object
df 被第一次 unstack() 之后变成 (行 → 列)
- 行索引 = r1
- 列索引 = [c, r2]
df 被第二次 unstack() 之后变成 (行 → 列)
- 行索引 = []
- 列索引 = [c, r2, r1]
重塑后的 Series 只有列索引 (实际上是个转置的 Series),有三层,第一层是特征,第二层是代号,第三层是地区。
5.2 透视
数据源表通常只包含行和列,那么经常有重复值出现在各列下,因而导致源表不能传递有价值的信息。这时可用「透视」方法调整源表的布局用作更清晰的展示。
透视表是用来汇总其它表的数据:
- 首先把源表分组,将不同值当做行 (row)、列 (column) 和值 (value)
- 然后对各组内数据做汇总操作如排序、平均、累加、计数等
这种动态将·「源表」得到想要「终表」的旋转 (pivoting) 过程,使透视表得以命名。
在 Pandas 里透视的方法有两种:
- 用 pivot 函数将「一张长表」变「多张宽表」
- 用 melt 函数将「多张宽表」变「一张长表」
data = pd.read_csv('Stock.csv', parse_dates=[0], dayfirst=True)
data
| Date | Symbol | Open | High | Low | Close | Volume | |
|---|---|---|---|---|---|---|---|
| 0 | 2021-01-15 | GS | 301.19 | 304.86 | 296.88 | 301.01 | 3860000 |
| 1 | 2021-01-15 | FB | 247.90 | 253.86 | 247.16 | 251.36 | 24940000 |
| 2 | 2021-01-15 | AAPL | 128.78 | 130.22 | 127.00 | 127.14 | 111600000 |
| 3 | 2021-01-15 | JD | 89.81 | 89.89 | 87.21 | 87.77 | 8860000 |
| 4 | 2021-01-15 | BABA | 246.25 | 246.99 | 242.15 | 243.46 | 21560000 |
| ... | ... | ... | ... | ... | ... | ... | ... |
| 96 | 2021-02-12 | GS | 301.99 | 306.70 | 301.77 | 306.32 | 1980000 |
| 97 | 2021-02-12 | FB | 270.52 | 271.18 | 268.34 | 270.50 | 9100000 |
| 98 | 2021-02-12 | AAPL | 134.35 | 135.53 | 133.69 | 135.37 | 60150000 |
| 99 | 2021-02-12 | JD | 98.79 | 99.76 | 97.81 | 99.31 | 3230000 |
| 100 | 2021-02-12 | BABA | 269.09 | 270.25 | 265.68 | 267.85 | 9360000 |
101 rows × 7 columns
从长到宽 (pivot)
当我们做数据分析时,只关注不同股票在不同日期下的 Adj Close,那么可用 pivot 函数可将原始 data「透视」成一个新的 DataFrame,起名 close_price。在 pivot 函数中
- 将 index 设置成 ‘Date’
- 将 columns 设置成 ‘Symbol’
- 将 values 设置 ‘Adj Close’
close_price 实际上把 data[‘Date’] 和 data[‘Symbol’] 的唯一值当成支点(pivot 就是支点的意思) 创建一个 DataFrame,其中
- 行标签 = 2021-01-15,…,2021-02-12
- 列标签 = AAPL, JD, BABA, FB, GS
在把 data[‘Close’] 的值放在以如上的行标签和列标签创建的 close_price 来展示。
close_price = data.pivot( index='Date',
columns='Symbol',
values='Close' )
close_price
| Symbol | AAPL | BABA | FB | GS | JD |
|---|---|---|---|---|---|
| Date | |||||
| 2021-01-15 | 127.14 | 243.46 | 251.36 | 301.01 | 87.77 |
| 2021-01-19 | 127.83 | 251.65 | 261.10 | 294.20 | 91.15 |
| 2021-01-20 | 132.03 | 265.49 | 267.48 | 290.47 | 95.31 |
| 2021-01-21 | 136.87 | 260.00 | 272.87 | 289.37 | 95.10 |
| 2021-01-22 | 139.07 | 258.62 | 274.50 | 289.39 | 94.91 |
| 2021-01-24 | NaN | 258.62 | NaN | NaN | NaN |
| 2021-01-25 | 142.92 | 261.38 | 278.01 | 283.04 | 98.38 |
| 2021-01-26 | 143.16 | 265.92 | 282.05 | 281.76 | 96.97 |
| 2021-01-27 | 142.06 | 260.25 | 272.14 | 273.33 | 90.09 |
| 2021-01-28 | 137.09 | 260.76 | 265.00 | 275.02 | 91.41 |
| 2021-01-29 | 131.96 | 253.83 | 258.33 | 271.17 | 88.69 |
| 2021-02-01 | 134.14 | 264.69 | 262.01 | 274.73 | 91.27 |
| 2021-02-02 | 134.99 | 254.50 | 267.08 | 286.97 | 95.42 |
| 2021-02-03 | 133.94 | 263.43 | 266.65 | 288.55 | 95.50 |
| 2021-02-04 | 137.39 | 266.96 | 266.49 | 293.75 | 94.63 |
| 2021-02-05 | 136.76 | 265.67 | 268.10 | 293.50 | 96.64 |
| 2021-02-08 | 136.91 | 262.59 | 266.58 | 300.15 | 94.57 |
| 2021-02-09 | 136.01 | 266.49 | 269.45 | 300.46 | 97.07 |
| 2021-02-10 | 135.39 | 267.79 | 271.87 | 304.28 | 98.77 |
| 2021-02-11 | 135.13 | 268.93 | 270.39 | 302.32 | 99.00 |
| 2021-02-12 | 135.37 | 267.85 | 270.50 | 306.32 | 99.31 |
如果觉得 Close 不够,还想加个 Volume 看看,那么就把 values 设置成 [‘Close’, ‘Volume’]。这时支点还是 data[‘Date’] 和 data[‘Symbol’],但是要透视的值增加到 data[[‘Close’, ‘Volume’]] 了。pivot 函数返回的是两个透视表。
data.pivot( index='Date',
columns='Symbol',
values=['Close','Volume'] )
| Close | Volume | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Symbol | AAPL | BABA | FB | GS | JD | AAPL | BABA | FB | GS | JD |
| Date | ||||||||||
| 2021-01-15 | 127.14 | 243.46 | 251.36 | 301.01 | 87.77 | 111600000.0 | 21560000.0 | 24940000.0 | 3860000.0 | 8860000.0 |
| 2021-01-19 | 127.83 | 251.65 | 261.10 | 294.20 | 91.15 | 90760000.0 | 23680000.0 | 28030000.0 | 6730000.0 | 10810000.0 |
| 2021-01-20 | 132.03 | 265.49 | 267.48 | 290.47 | 95.31 | 104320000.0 | 44640000.0 | 25200000.0 | 4790000.0 | 15500000.0 |
| 2021-01-21 | 136.87 | 260.00 | 272.87 | 289.37 | 95.10 | 120530000.0 | 20710000.0 | 20840000.0 | 2520000.0 | 7340000.0 |
| 2021-01-22 | 139.07 | 258.62 | 274.50 | 289.39 | 94.91 | 114460000.0 | 13520000.0 | 21950000.0 | 2570000.0 | 6950000.0 |
| 2021-01-24 | NaN | 258.62 | NaN | NaN | NaN | NaN | 0.0 | NaN | NaN | NaN |
| 2021-01-25 | 142.92 | 261.38 | 278.01 | 283.04 | 98.38 | 157610000.0 | 19480000.0 | 19090000.0 | 4580000.0 | 16410000.0 |
| 2021-01-26 | 143.16 | 265.92 | 282.05 | 281.76 | 96.97 | 98390000.0 | 14680000.0 | 19370000.0 | 3300000.0 | 8250000.0 |
| 2021-01-27 | 142.06 | 260.25 | 272.14 | 273.33 | 90.09 | 140840000.0 | 16050000.0 | 35350000.0 | 3890000.0 | 16060000.0 |
| 2021-01-28 | 137.09 | 260.76 | 265.00 | 275.02 | 91.41 | 142620000.0 | 10240000.0 | 37760000.0 | 3780000.0 | 11250000.0 |
| 2021-01-29 | 131.96 | 253.83 | 258.33 | 271.17 | 88.69 | 177520000.0 | 14690000.0 | 30390000.0 | 3410000.0 | 10860000.0 |
| 2021-02-01 | 134.14 | 264.69 | 262.01 | 274.73 | 91.27 | 106240000.0 | 15290000.0 | 22910000.0 | 2320000.0 | 7450000.0 |
| 2021-02-02 | 134.99 | 254.50 | 267.08 | 286.97 | 95.42 | 83310000.0 | 30530000.0 | 17320000.0 | 5200000.0 | 11520000.0 |
| 2021-02-03 | 133.94 | 263.43 | 266.65 | 288.55 | 95.50 | 89880000.0 | 29180000.0 | 14220000.0 | 2710000.0 | 7330000.0 |
| 2021-02-04 | 137.39 | 266.96 | 266.49 | 293.75 | 94.63 | 84180000.0 | 16760000.0 | 16060000.0 | 2990000.0 | 5340000.0 |
| 2021-02-05 | 136.76 | 265.67 | 268.10 | 293.50 | 96.64 | 75690000.0 | 11020000.0 | 12450000.0 | 2940000.0 | 5820000.0 |
| 2021-02-08 | 136.91 | 262.59 | 266.58 | 300.15 | 94.57 | 71300000.0 | 10520000.0 | 13760000.0 | 2820000.0 | 5690000.0 |
| 2021-02-09 | 136.01 | 266.49 | 269.45 | 300.46 | 97.07 | 76770000.0 | 12300000.0 | 14610000.0 | 2060000.0 | 5790000.0 |
| 2021-02-10 | 135.39 | 267.79 | 271.87 | 304.28 | 98.77 | 73050000.0 | 12860000.0 | 14690000.0 | 3090000.0 | 8630000.0 |
| 2021-02-11 | 135.13 | 268.93 | 270.39 | 302.32 | 99.00 | 64280000.0 | 15000000.0 | 12830000.0 | 1900000.0 | 4460000.0 |
| 2021-02-12 | 135.37 | 267.85 | 270.50 | 306.32 | 99.31 | 60150000.0 | 9360000.0 | 9100000.0 | 1980000.0 | 3230000.0 |
如果不设置 values 参数,那么 pivot 函数返回的是六个透视表。(源表 data 有八列,两列当了支点,剩下六列用来透视)
all_pivot = data.pivot( index='Date',
columns='Symbol' )
all_pivot
| Open | High | ... | Close | Volume | |||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Symbol | AAPL | BABA | FB | GS | JD | AAPL | BABA | FB | GS | JD | ... | AAPL | BABA | FB | GS | JD | AAPL | BABA | FB | GS | JD |
| Date | |||||||||||||||||||||
| 2021-01-15 | 128.78 | 246.25 | 247.90 | 301.19 | 89.81 | 130.22 | 246.99 | 253.86 | 304.86 | 89.89 | ... | 127.14 | 243.46 | 251.36 | 301.01 | 87.77 | 111600000.0 | 21560000.0 | 24940000.0 | 3860000.0 | 8860000.0 |
| 2021-01-19 | 127.78 | 249.62 | 256.64 | 304.75 | 90.53 | 128.71 | 252.88 | 262.19 | 306.09 | 91.42 | ... | 127.83 | 251.65 | 261.10 | 294.20 | 91.15 | 90760000.0 | 23680000.0 | 28030000.0 | 6730000.0 | 10810000.0 |
| 2021-01-20 | 128.66 | 267.50 | 268.93 | 295.82 | 93.72 | 132.49 | 269.00 | 270.32 | 297.45 | 95.72 | ... | 132.03 | 265.49 | 267.48 | 290.47 | 95.31 | 104320000.0 | 44640000.0 | 25200000.0 | 4790000.0 | 15500000.0 |
| 2021-01-21 | 133.80 | 264.13 | 269.26 | 290.45 | 95.40 | 139.67 | 264.60 | 273.60 | 292.74 | 95.57 | ... | 136.87 | 260.00 | 272.87 | 289.37 | 95.10 | 120530000.0 | 20710000.0 | 20840000.0 | 2520000.0 | 7340000.0 |
| 2021-01-22 | 136.28 | 256.80 | 272.01 | 286.69 | 93.95 | 139.85 | 260.33 | 278.47 | 290.59 | 95.55 | ... | 139.07 | 258.62 | 274.50 | 289.39 | 94.91 | 114460000.0 | 13520000.0 | 21950000.0 | 2570000.0 | 6950000.0 |
| 2021-01-24 | NaN | 258.62 | NaN | NaN | NaN | NaN | 258.62 | NaN | NaN | NaN | ... | NaN | 258.62 | NaN | NaN | NaN | NaN | 0.0 | NaN | NaN | NaN |
| 2021-01-25 | 143.07 | 263.90 | 278.57 | 289.39 | 99.44 | 145.09 | 265.12 | 280.07 | 289.39 | 101.68 | ... | 142.92 | 261.38 | 278.01 | 283.04 | 98.38 | 157610000.0 | 19480000.0 | 19090000.0 | 4580000.0 | 16410000.0 |
| 2021-01-26 | 143.60 | 263.74 | 278.35 | 284.04 | 99.25 | 144.30 | 265.92 | 285.33 | 285.73 | 99.27 | ... | 143.16 | 265.92 | 282.05 | 281.76 | 96.97 | 98390000.0 | 14680000.0 | 19370000.0 | 3300000.0 | 8250000.0 |
| 2021-01-27 | 143.43 | 265.00 | 283.10 | 276.89 | 93.49 | 144.30 | 265.82 | 283.18 | 277.30 | 94.37 | ... | 142.06 | 260.25 | 272.14 | 273.33 | 90.09 | 140840000.0 | 16050000.0 | 35350000.0 | 3890000.0 | 16060000.0 |
| 2021-01-28 | 139.52 | 259.39 | 277.84 | 274.61 | 90.15 | 141.99 | 261.55 | 286.69 | 279.82 | 92.16 | ... | 137.09 | 260.76 | 265.00 | 275.02 | 91.41 | 142620000.0 | 10240000.0 | 37760000.0 | 3780000.0 | 11250000.0 |
| 2021-01-29 | 135.83 | 256.03 | 265.30 | 274.27 | 89.98 | 136.74 | 258.90 | 266.56 | 277.40 | 91.80 | ... | 131.96 | 253.83 | 258.33 | 271.17 | 88.69 | 177520000.0 | 14690000.0 | 30390000.0 | 3410000.0 | 10860000.0 |
| 2021-02-01 | 133.75 | 257.74 | 260.07 | 273.07 | 90.17 | 135.38 | 264.99 | 264.14 | 276.78 | 91.80 | ... | 134.14 | 264.69 | 262.01 | 274.73 | 91.27 | 106240000.0 | 15290000.0 | 22910000.0 | 2320000.0 | 7450000.0 |
| 2021-02-02 | 135.73 | 264.45 | 264.52 | 278.38 | 94.88 | 136.31 | 264.45 | 268.80 | 288.22 | 95.99 | ... | 134.99 | 254.50 | 267.08 | 286.97 | 95.42 | 83310000.0 | 30530000.0 | 17320000.0 | 5200000.0 | 11520000.0 |
| 2021-02-03 | 135.76 | 264.79 | 265.51 | 286.42 | 96.45 | 135.77 | 268.14 | 269.17 | 289.75 | 97.42 | ... | 133.94 | 263.43 | 266.65 | 288.55 | 95.50 | 89880000.0 | 29180000.0 | 14220000.0 | 2710000.0 | 7330000.0 |
| 2021-02-04 | 136.30 | 269.50 | 267.48 | 289.94 | 95.78 | 137.40 | 269.70 | 268.04 | 295.80 | 95.96 | ... | 137.39 | 266.96 | 266.49 | 293.75 | 94.63 | 84180000.0 | 16760000.0 | 16060000.0 | 2990000.0 | 5340000.0 |
| 2021-02-05 | 137.35 | 264.61 | 266.80 | 295.00 | 95.24 | 137.42 | 266.45 | 269.17 | 297.24 | 96.82 | ... | 136.76 | 265.67 | 268.10 | 293.50 | 96.64 | 75690000.0 | 11020000.0 | 12450000.0 | 2940000.0 | 5820000.0 |
| 2021-02-08 | 136.03 | 264.98 | 268.56 | 295.00 | 95.60 | 136.96 | 265.00 | 269.81 | 300.89 | 95.68 | ... | 136.91 | 262.59 | 266.58 | 300.15 | 94.57 | 71300000.0 | 10520000.0 | 13760000.0 | 2820000.0 | 5690000.0 |
| 2021-02-09 | 136.66 | 263.00 | 266.59 | 299.60 | 94.90 | 137.87 | 267.20 | 273.30 | 302.45 | 97.53 | ... | 136.01 | 266.49 | 269.45 | 300.46 | 97.07 | 76770000.0 | 12300000.0 | 14610000.0 | 2060000.0 | 5790000.0 |
| 2021-02-10 | 136.46 | 268.70 | 272.74 | 300.00 | 98.80 | 136.98 | 270.40 | 273.73 | 305.18 | 100.47 | ... | 135.39 | 267.79 | 271.87 | 304.28 | 98.77 | 73050000.0 | 12860000.0 | 14690000.0 | 3090000.0 | 8630000.0 |
| 2021-02-11 | 135.94 | 268.75 | 271.95 | 303.98 | 99.77 | 136.36 | 274.26 | 273.50 | 305.01 | 99.81 | ... | 135.13 | 268.93 | 270.39 | 302.32 | 99.00 | 64280000.0 | 15000000.0 | 12830000.0 | 1900000.0 | 4460000.0 |
| 2021-02-12 | 134.35 | 269.09 | 270.52 | 301.99 | 98.79 | 135.53 | 270.25 | 271.18 | 306.70 | 99.76 | ... | 135.37 | 267.85 | 270.50 | 306.32 | 99.31 | 60150000.0 | 9360000.0 | 9100000.0 | 1980000.0 | 3230000.0 |
21 rows × 25 columns
再继续观察下,all_pivot 实际上是个多层 DataFrame (有多层 columns)。假设我们要获取 2021-02-11 和 2021-01-12 两天的 BABA 和 FB 的开盘价,用以下「多层索引和切片」的方法。
all_pivot['Open'].iloc[-2:,1:3]
| Symbol | BABA | FB |
|---|---|---|
| Date | ||
| 2021-02-11 | 268.75 | 271.95 |
| 2021-02-12 | 269.09 | 270.52 |
从宽到长 (melt)
pivot 逆反操作是 melt。
- 前者将「一张长表」变成「多张宽表」
- 后者将「多张宽表」变成「一张长表」
具体来说,函数 melt 实际是将「源表」转化成 id-variable 类型的 DataFrame
- Date 和 Symbol 列当成 id
- 其他列 Open, High, Low, Close 和 Volume 当成 variable,而它们对应的值当成 value
melted_data = pd.melt( data, id_vars=['Date','Symbol'] )
melted_data.head(5).append(melted_data.tail(5))
| Date | Symbol | variable | value | |
|---|---|---|---|---|
| 0 | 2021-01-15 | GS | Open | 301.19 |
| 1 | 2021-01-15 | FB | Open | 247.90 |
| 2 | 2021-01-15 | AAPL | Open | 128.78 |
| 3 | 2021-01-15 | JD | Open | 89.81 |
| 4 | 2021-01-15 | BABA | Open | 246.25 |
| 500 | 2021-02-12 | GS | Volume | 1980000.00 |
| 501 | 2021-02-12 | FB | Volume | 9100000.00 |
| 502 | 2021-02-12 | AAPL | Volume | 60150000.00 |
| 503 | 2021-02-12 | JD | Volume | 3230000.00 |
| 504 | 2021-02-12 | BABA | Volume | 9360000.00 |
新生成的 DataFrame 有 525 行 (21 × 5 × 5)
- 21 = data[‘Date’] 有 21 个日期
- 5 = data[‘Symbol’] 有 5 只股票
- 5 = Open, High, Low, Close 和 Volume 这 5 个变量
在新表 melted_data 中
- 在参数 id_vars 设置的 Date 和 Symbol 还保持为 columns
- 此外还多出两个 columns,一个叫 variable,一个叫 value
- variable 列下的值为 Open, High, Low, Close, Adj Close 和 Volume
- value 列下的值为前者在「源表 data」中的值
melted_data[ lambda x: (x.Date=='2021-2-1')
& ((x.Symbol=='BABA')|(x.Symbol=='FB')) ]
| Date | Symbol | variable | value | |
|---|---|---|---|---|
| 52 | 2021-02-01 | FB | Open | 260.07 |
| 55 | 2021-02-01 | BABA | Open | 257.74 |
| 153 | 2021-02-01 | FB | High | 264.14 |
| 156 | 2021-02-01 | BABA | High | 264.99 |
| 254 | 2021-02-01 | FB | Low | 255.12 |
| 257 | 2021-02-01 | BABA | Low | 255.33 |
| 355 | 2021-02-01 | FB | Close | 262.01 |
| 358 | 2021-02-01 | BABA | Close | 264.69 |
| 456 | 2021-02-01 | FB | Volume | 22910000.00 |
| 459 | 2021-02-01 | BABA | Volume | 15290000.00 |
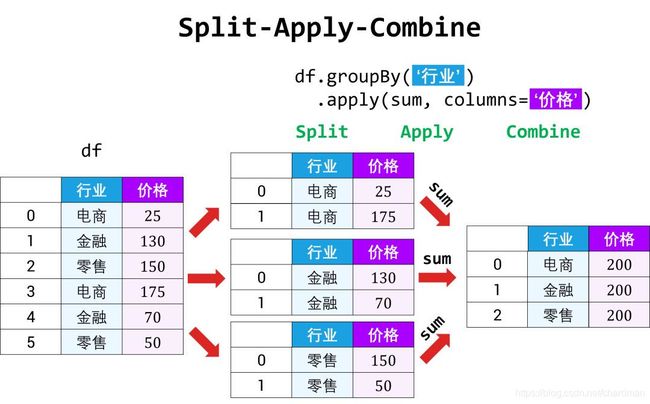
6 数据表的分组和整合
DataFrame 中的数据可以根据某些规则分组,然后在每组的数据上计算出不同统计量。这种操作称之为 split-apply-combine。
data = pd.read_csv('Stock.csv', parse_dates=[0])
data.head(3).append(data.tail(3))
| Date | Symbol | Open | High | Low | Close | Volume | |
|---|---|---|---|---|---|---|---|
| 0 | 2021-01-15 | GS | 301.19 | 304.86 | 296.88 | 301.01 | 3860000 |
| 1 | 2021-01-15 | FB | 247.90 | 253.86 | 247.16 | 251.36 | 24940000 |
| 2 | 2021-01-15 | AAPL | 128.78 | 130.22 | 127.00 | 127.14 | 111600000 |
| 98 | 2021-02-12 | AAPL | 134.35 | 135.53 | 133.69 | 135.37 | 60150000 |
| 99 | 2021-02-12 | JD | 98.79 | 99.76 | 97.81 | 99.31 | 3230000 |
| 100 | 2021-02-12 | BABA | 269.09 | 270.25 | 265.68 | 267.85 | 9360000 |
我们目前只对 Close 感兴趣,而且想知道在哪一年份或哪一月份每支股票的 Close 是多少。因此我们需要做两件事:
- 只保留 ‘Date’, ‘Symbol’ 和 ‘ Close‘
- 从 ‘Date’ 中获取 ‘Year’ 和 ‘Month’ 的信息并插入表中
data1 = data[['Date', 'Symbol', 'Close']]
data1.insert( 1, 'Year', pd.DatetimeIndex(data1['Date']).year )
data1.insert( 2, 'Month', pd.DatetimeIndex(data1['Date']).month )
data1.head(3).append(data1.tail(3))
| Date | Year | Month | Symbol | Close | |
|---|---|---|---|---|---|
| 0 | 2021-01-15 | 2021 | 1 | GS | 301.01 |
| 1 | 2021-01-15 | 2021 | 1 | FB | 251.36 |
| 2 | 2021-01-15 | 2021 | 1 | AAPL | 127.14 |
| 98 | 2021-02-12 | 2021 | 2 | AAPL | 135.37 |
| 99 | 2021-02-12 | 2021 | 2 | JD | 99.31 |
| 100 | 2021-02-12 | 2021 | 2 | BABA | 267.85 |
6.1 分组
用某一特定标签 (label) 将数据 (data) 分组的语法如下:
data.groupBy( label )
grouped = data1.groupby('Symbol')
grouped
「万物皆对象」,这个 grouped 也不例外,可以用 dir() 来查看它的「属性」和「内置方法」。包括以下几种:
- ngroups: 组的个数 (int)
- size(): 每组元素的个数 (Series)
- groups: 每组元素在原 DataFrame 中的索引信息 (dict)
- get_groups(label): 标签 label 对应的数据 (DataFrame)
grouped.ngroups # 5只股票,分为5组
5
grouped.size() # 每只股票含20或21条信息
Symbol
AAPL 20
BABA 21
FB 20
GS 20
JD 20
dtype: int64
grouped.groups # 每一组各自的索引
{'AAPL': [2, 7, 12, 17, 22, 28, 33, 38, 43, 48, 53, 58, 63, 68, 73, 78, 83, 88, 93, 98], 'BABA': [4, 9, 14, 19, 24, 25, 30, 35, 40, 45, 50, 55, 60, 65, 70, 75, 80, 85, 90, 95, 100], 'FB': [1, 6, 11, 16, 21, 27, 32, 37, 42, 47, 52, 57, 62, 67, 72, 77, 82, 87, 92, 97], 'GS': [0, 5, 10, 15, 20, 26, 31, 36, 41, 46, 51, 56, 61, 66, 71, 76, 81, 86, 91, 96], 'JD': [3, 8, 13, 18, 23, 29, 34, 39, 44, 49, 54, 59, 64, 69, 74, 79, 84, 89, 94, 99]}
grouped.get_group('GS').head() # 可以查看每一组的数据
| Date | Year | Month | Symbol | Close | |
|---|---|---|---|---|---|
| 0 | 2021-01-15 | 2021 | 1 | GS | 301.01 |
| 5 | 2021-01-19 | 2021 | 1 | GS | 294.20 |
| 10 | 2021-01-20 | 2021 | 1 | GS | 290.47 |
| 15 | 2021-01-21 | 2021 | 1 | GS | 289.37 |
| 20 | 2021-01-22 | 2021 | 1 | GS | 289.39 |
# 定义个 print_groups 函数便于打印组的名字和前五行信息。
def print_groups( group_obj ):
for name, group in group_obj:
print( name )
print( group.head() )
print_groups( grouped )
AAPL
Date Year Month Symbol Close
2 2021-01-15 2021 1 AAPL 127.14
7 2021-01-19 2021 1 AAPL 127.83
12 2021-01-20 2021 1 AAPL 132.03
17 2021-01-21 2021 1 AAPL 136.87
22 2021-01-22 2021 1 AAPL 139.07
BABA
Date Year Month Symbol Close
4 2021-01-15 2021 1 BABA 243.46
9 2021-01-19 2021 1 BABA 251.65
14 2021-01-20 2021 1 BABA 265.49
19 2021-01-21 2021 1 BABA 260.00
24 2021-01-22 2021 1 BABA 258.62
FB
Date Year Month Symbol Close
1 2021-01-15 2021 1 FB 251.36
6 2021-01-19 2021 1 FB 261.10
11 2021-01-20 2021 1 FB 267.48
16 2021-01-21 2021 1 FB 272.87
21 2021-01-22 2021 1 FB 274.50
GS
Date Year Month Symbol Close
0 2021-01-15 2021 1 GS 301.01
5 2021-01-19 2021 1 GS 294.20
10 2021-01-20 2021 1 GS 290.47
15 2021-01-21 2021 1 GS 289.37
20 2021-01-22 2021 1 GS 289.39
JD
Date Year Month Symbol Close
3 2021-01-15 2021 1 JD 87.77
8 2021-01-19 2021 1 JD 91.15
13 2021-01-20 2021 1 JD 95.31
18 2021-01-21 2021 1 JD 95.10
23 2021-01-22 2021 1 JD 94.91
多标签分组
groupBy 函数除了支持单标签分组,也支持多标签分组 (将标签放入一个列表中)。
grouped2 = data1.groupby(['Symbol', 'Year', 'Month'])
print_groups( grouped2 )
('AAPL', 2021, 1)
Date Year Month Symbol Close
2 2021-01-15 2021 1 AAPL 127.14
7 2021-01-19 2021 1 AAPL 127.83
12 2021-01-20 2021 1 AAPL 132.03
17 2021-01-21 2021 1 AAPL 136.87
22 2021-01-22 2021 1 AAPL 139.07
('AAPL', 2021, 2)
Date Year Month Symbol Close
53 2021-02-01 2021 2 AAPL 134.14
58 2021-02-02 2021 2 AAPL 134.99
63 2021-02-03 2021 2 AAPL 133.94
68 2021-02-04 2021 2 AAPL 137.39
73 2021-02-05 2021 2 AAPL 136.76
('BABA', 2021, 1)
Date Year Month Symbol Close
4 2021-01-15 2021 1 BABA 243.46
9 2021-01-19 2021 1 BABA 251.65
14 2021-01-20 2021 1 BABA 265.49
19 2021-01-21 2021 1 BABA 260.00
24 2021-01-22 2021 1 BABA 258.62
('BABA', 2021, 2)
Date Year Month Symbol Close
55 2021-02-01 2021 2 BABA 264.69
60 2021-02-02 2021 2 BABA 254.50
65 2021-02-03 2021 2 BABA 263.43
70 2021-02-04 2021 2 BABA 266.96
75 2021-02-05 2021 2 BABA 265.67
('FB', 2021, 1)
Date Year Month Symbol Close
1 2021-01-15 2021 1 FB 251.36
6 2021-01-19 2021 1 FB 261.10
11 2021-01-20 2021 1 FB 267.48
16 2021-01-21 2021 1 FB 272.87
21 2021-01-22 2021 1 FB 274.50
('FB', 2021, 2)
Date Year Month Symbol Close
52 2021-02-01 2021 2 FB 262.01
57 2021-02-02 2021 2 FB 267.08
62 2021-02-03 2021 2 FB 266.65
67 2021-02-04 2021 2 FB 266.49
72 2021-02-05 2021 2 FB 268.10
('GS', 2021, 1)
Date Year Month Symbol Close
0 2021-01-15 2021 1 GS 301.01
5 2021-01-19 2021 1 GS 294.20
10 2021-01-20 2021 1 GS 290.47
15 2021-01-21 2021 1 GS 289.37
20 2021-01-22 2021 1 GS 289.39
('GS', 2021, 2)
Date Year Month Symbol Close
51 2021-02-01 2021 2 GS 274.73
56 2021-02-02 2021 2 GS 286.97
61 2021-02-03 2021 2 GS 288.55
66 2021-02-04 2021 2 GS 293.75
71 2021-02-05 2021 2 GS 293.50
('JD', 2021, 1)
Date Year Month Symbol Close
3 2021-01-15 2021 1 JD 87.77
8 2021-01-19 2021 1 JD 91.15
13 2021-01-20 2021 1 JD 95.31
18 2021-01-21 2021 1 JD 95.10
23 2021-01-22 2021 1 JD 94.91
('JD', 2021, 2)
Date Year Month Symbol Close
54 2021-02-01 2021 2 JD 91.27
59 2021-02-02 2021 2 JD 95.42
64 2021-02-03 2021 2 JD 95.50
69 2021-02-04 2021 2 JD 94.63
74 2021-02-05 2021 2 JD 96.64
data2 = data1.set_index(['Symbol', 'Year', 'Month'])
data2.head().append(data2.tail())
| Date | Close | |||
|---|---|---|---|---|
| Symbol | Year | Month | ||
| GS | 2021 | 1 | 2021-01-15 | 301.01 |
| FB | 2021 | 1 | 2021-01-15 | 251.36 |
| AAPL | 2021 | 1 | 2021-01-15 | 127.14 |
| JD | 2021 | 1 | 2021-01-15 | 87.77 |
| BABA | 2021 | 1 | 2021-01-15 | 243.46 |
| GS | 2021 | 2 | 2021-02-12 | 306.32 |
| FB | 2021 | 2 | 2021-02-12 | 270.50 |
| AAPL | 2021 | 2 | 2021-02-12 | 135.37 |
| JD | 2021 | 2 | 2021-02-12 | 99.31 |
| BABA | 2021 | 2 | 2021-02-12 | 267.85 |
对 data1 重设索引之后,产出是一个有 multi-index 的 DataFrame,记做 data2。由于有多层索引,这时我们根据索引的 level 来分组,下面 level = 1 就是对第一层 (Year) 进行分组。
grouped3 = data2.groupby(level=1)
print_groups( grouped3 )
2021
Date Close
Symbol Year Month
GS 2021 1 2021-01-15 301.01
FB 2021 1 2021-01-15 251.36
AAPL 2021 1 2021-01-15 127.14
JD 2021 1 2021-01-15 87.77
BABA 2021 1 2021-01-15 243.46
多层索引中的任意个数的索引也可以用来分组,下面 level = [0,2] 就是对第零层 (Symbol) 和第二层 (Month) 进行分组。
grouped4 = data2.groupby(level=[0, 2])
print_groups( grouped4 )
('AAPL', 1)
Date Close
Symbol Year Month
AAPL 2021 1 2021-01-15 127.14
1 2021-01-19 127.83
1 2021-01-20 132.03
1 2021-01-21 136.87
1 2021-01-22 139.07
('AAPL', 2)
Date Close
Symbol Year Month
AAPL 2021 2 2021-02-01 134.14
2 2021-02-02 134.99
2 2021-02-03 133.94
2 2021-02-04 137.39
2 2021-02-05 136.76
('BABA', 1)
Date Close
Symbol Year Month
BABA 2021 1 2021-01-15 243.46
1 2021-01-19 251.65
1 2021-01-20 265.49
1 2021-01-21 260.00
1 2021-01-22 258.62
('BABA', 2)
Date Close
Symbol Year Month
BABA 2021 2 2021-02-01 264.69
2 2021-02-02 254.50
2 2021-02-03 263.43
2 2021-02-04 266.96
2 2021-02-05 265.67
('FB', 1)
Date Close
Symbol Year Month
FB 2021 1 2021-01-15 251.36
1 2021-01-19 261.10
1 2021-01-20 267.48
1 2021-01-21 272.87
1 2021-01-22 274.50
('FB', 2)
Date Close
Symbol Year Month
FB 2021 2 2021-02-01 262.01
2 2021-02-02 267.08
2 2021-02-03 266.65
2 2021-02-04 266.49
2 2021-02-05 268.10
('GS', 1)
Date Close
Symbol Year Month
GS 2021 1 2021-01-15 301.01
1 2021-01-19 294.20
1 2021-01-20 290.47
1 2021-01-21 289.37
1 2021-01-22 289.39
('GS', 2)
Date Close
Symbol Year Month
GS 2021 2 2021-02-01 274.73
2 2021-02-02 286.97
2 2021-02-03 288.55
2 2021-02-04 293.75
2 2021-02-05 293.50
('JD', 1)
Date Close
Symbol Year Month
JD 2021 1 2021-01-15 87.77
1 2021-01-19 91.15
1 2021-01-20 95.31
1 2021-01-21 95.10
1 2021-01-22 94.91
('JD', 2)
Date Close
Symbol Year Month
JD 2021 2 2021-02-01 91.27
2 2021-02-02 95.42
2 2021-02-03 95.50
2 2021-02-04 94.63
2 2021-02-05 96.64
6.3整合 (aggregating)
分组之后,最主要的目的就是为了整合(aggregating)
grouped.size()
Symbol
AAPL 20
BABA 21
FB 20
GS 20
JD 20
dtype: int64
grouped.mean()
| Year | Month | Close | |
|---|---|---|---|
| Symbol | |||
| AAPL | 2021.0 | 1.50000 | 135.808000 |
| BABA | 2021.0 | 1.47619 | 261.375238 |
| FB | 2021.0 | 1.50000 | 268.098000 |
| GS | 2021.0 | 1.50000 | 289.989500 |
| JD | 2021.0 | 1.50000 | 94.598000 |
除了上述方法,整合还可以用内置函数 aggregate() 或 agg() 作用到「组对象」上。
print_groups(grouped4)
('AAPL', 1)
Date Close
Symbol Year Month
AAPL 2021 1 2021-01-15 127.14
1 2021-01-19 127.83
1 2021-01-20 132.03
1 2021-01-21 136.87
1 2021-01-22 139.07
('AAPL', 2)
Date Close
Symbol Year Month
AAPL 2021 2 2021-02-01 134.14
2 2021-02-02 134.99
2 2021-02-03 133.94
2 2021-02-04 137.39
2 2021-02-05 136.76
('BABA', 1)
Date Close
Symbol Year Month
BABA 2021 1 2021-01-15 243.46
1 2021-01-19 251.65
1 2021-01-20 265.49
1 2021-01-21 260.00
1 2021-01-22 258.62
('BABA', 2)
Date Close
Symbol Year Month
BABA 2021 2 2021-02-01 264.69
2 2021-02-02 254.50
2 2021-02-03 263.43
2 2021-02-04 266.96
2 2021-02-05 265.67
('FB', 1)
Date Close
Symbol Year Month
FB 2021 1 2021-01-15 251.36
1 2021-01-19 261.10
1 2021-01-20 267.48
1 2021-01-21 272.87
1 2021-01-22 274.50
('FB', 2)
Date Close
Symbol Year Month
FB 2021 2 2021-02-01 262.01
2 2021-02-02 267.08
2 2021-02-03 266.65
2 2021-02-04 266.49
2 2021-02-05 268.10
('GS', 1)
Date Close
Symbol Year Month
GS 2021 1 2021-01-15 301.01
1 2021-01-19 294.20
1 2021-01-20 290.47
1 2021-01-21 289.37
1 2021-01-22 289.39
('GS', 2)
Date Close
Symbol Year Month
GS 2021 2 2021-02-01 274.73
2 2021-02-02 286.97
2 2021-02-03 288.55
2 2021-02-04 293.75
2 2021-02-05 293.50
('JD', 1)
Date Close
Symbol Year Month
JD 2021 1 2021-01-15 87.77
1 2021-01-19 91.15
1 2021-01-20 95.31
1 2021-01-21 95.10
1 2021-01-22 94.91
('JD', 2)
Date Close
Symbol Year Month
JD 2021 2 2021-02-01 91.27
2 2021-02-02 95.42
2 2021-02-03 95.50
2 2021-02-04 94.63
2 2021-02-05 96.64
result = grouped4.agg( np.mean )
result.head().append(result.tail())
| Close | ||
|---|---|---|
| Symbol | Month | |
| AAPL | 1 | 136.013 |
| 2 | 135.603 | |
| BABA | 1 | 258.180 |
| 2 | 264.890 | |
| FB | 1 | 268.284 |
| 2 | 267.912 | |
| GS | 1 | 284.876 |
| 2 | 295.103 | |
| JD | 1 | 92.978 |
| 2 | 96.218 |
函数 agg() 其实是一个高阶函数,里面的参数可以是另外一个函数,比如上例的 np.mean。上面代码对每只股票在每年每个月上求均值。
grouped4.mean()
| Close | ||
|---|---|---|
| Symbol | Month | |
| AAPL | 1 | 136.013 |
| 2 | 135.603 | |
| BABA | 1 | 258.180 |
| 2 | 264.890 | |
| FB | 1 | 268.284 |
| 2 | 267.912 | |
| GS | 1 | 284.876 |
| 2 | 295.103 | |
| JD | 1 | 92.978 |
| 2 | 96.218 |
result = grouped4.agg( [np.mean, np.std] ) # agg()函数与直接使用mean()函数不同的是,它可以有多个参数函数,可以同时进行多种统计
result.head().append(result.tail())
| Close | |||
|---|---|---|---|
| mean | std | ||
| Symbol | Month | ||
| AAPL | 1 | 136.013 | 6.005320 |
| 2 | 135.603 | 1.155230 | |
| BABA | 1 | 258.180 | 6.453421 |
| 2 | 264.890 | 4.168136 | |
| FB | 1 | 268.284 | 9.470313 |
| 2 | 267.912 | 2.824881 | |
| GS | 1 | 284.876 | 9.721075 |
| 2 | 295.103 | 9.688711 | |
| JD | 1 | 92.978 | 3.627708 |
| 2 | 96.218 | 2.485276 | |
既然 agg() 是高阶函数,参数当然也可以是匿名函数 (lambda 函数),下面我们定义一个对 grouped 里面每个标签下求最大值和最小值,再求差。注意 lambda 函数里面的 x 就是 grouped。
result = grouped.agg( lambda x: np.max(x)-np.min(x) )
result.head().append(result.tail())
| Date | Year | Month | Close | |
|---|---|---|---|---|
| Symbol | ||||
| AAPL | 28 days | 0 | 1 | 16.02 |
| BABA | 28 days | 0 | 1 | 25.47 |
| FB | 28 days | 0 | 1 | 30.69 |
| GS | 28 days | 0 | 1 | 35.15 |
| JD | 28 days | 0 | 1 | 11.54 |
| AAPL | 28 days | 0 | 1 | 16.02 |
| BABA | 28 days | 0 | 1 | 25.47 |
| FB | 28 days | 0 | 1 | 30.69 |
| GS | 28 days | 0 | 1 | 35.15 |
| JD | 28 days | 0 | 1 | 11.54 |
上面代码对每只股票在 Date, Year, Month 和 Close 上求「最大值」和「最小值」的差。
真正有价值的信息在 Close 那一栏,但我们来验证一下其他几栏。
- Date: 28 days,合理,最大日期-最小日期
- Year: 0,合理,都是2021年
- Month: 1,合理,2 月- 1 月
6.4 split-apply-combine
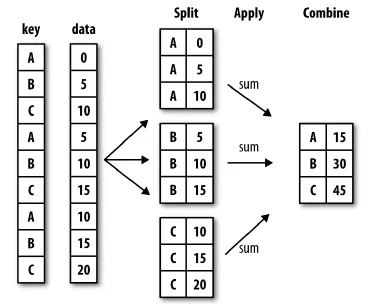
split-apply-combine 过程有三步:
- 根据 key 来 split 成 n 组
- 将函数 apply 到每个组
- 把 n 组的结果 combine 起来
# 在 Volume 栏取 5 个最大值。
def top( df, n=5, column='Volume' ):
return df.sort_values(by=column)[-n:]
top( data )
| Date | Symbol | Open | High | Low | Close | Volume | |
|---|---|---|---|---|---|---|---|
| 17 | 2021-01-21 | AAPL | 133.80 | 139.67 | 133.59 | 136.87 | 120530000 |
| 38 | 2021-01-27 | AAPL | 143.43 | 144.30 | 140.41 | 142.06 | 140840000 |
| 43 | 2021-01-28 | AAPL | 139.52 | 141.99 | 136.70 | 137.09 | 142620000 |
| 28 | 2021-01-25 | AAPL | 143.07 | 145.09 | 136.54 | 142.92 | 157610000 |
| 48 | 2021-01-29 | AAPL | 135.83 | 136.74 | 130.21 | 131.96 | 177520000 |
Apply 函数
在 split-apply-combine 过程中,apply 是核心。Python 本身有高阶函数 apply() 来实现它,既然是高阶函数,参数可以是另外的函数了,比如刚定义好的 top()。
将 top() 函数 apply 到按 Symbol 分的每个组上,按每个 Symbol 打印出来了 Volume 栏下的 5 个最大值。
data.groupby('Symbol').apply(top)
| Date | Symbol | Open | High | Low | Close | Volume | ||
|---|---|---|---|---|---|---|---|---|
| Symbol | ||||||||
| AAPL | 17 | 2021-01-21 | AAPL | 133.80 | 139.67 | 133.59 | 136.87 | 120530000 |
| 38 | 2021-01-27 | AAPL | 143.43 | 144.30 | 140.41 | 142.06 | 140840000 | |
| 43 | 2021-01-28 | AAPL | 139.52 | 141.99 | 136.70 | 137.09 | 142620000 | |
| 28 | 2021-01-25 | AAPL | 143.07 | 145.09 | 136.54 | 142.92 | 157610000 | |
| 48 | 2021-01-29 | AAPL | 135.83 | 136.74 | 130.21 | 131.96 | 177520000 | |
| BABA | 4 | 2021-01-15 | BABA | 246.25 | 246.99 | 242.15 | 243.46 | 21560000 |
| 9 | 2021-01-19 | BABA | 249.62 | 252.88 | 247.00 | 251.65 | 23680000 | |
| 65 | 2021-02-03 | BABA | 264.79 | 268.14 | 261.33 | 263.43 | 29180000 | |
| 60 | 2021-02-02 | BABA | 264.45 | 264.45 | 254.20 | 254.50 | 30530000 | |
| 14 | 2021-01-20 | BABA | 267.50 | 269.00 | 262.70 | 265.49 | 44640000 | |
| FB | 11 | 2021-01-20 | FB | 268.93 | 270.32 | 263.60 | 267.48 | 25200000 |
| 6 | 2021-01-19 | FB | 256.64 | 262.19 | 252.77 | 261.10 | 28030000 | |
| 47 | 2021-01-29 | FB | 265.30 | 266.56 | 254.85 | 258.33 | 30390000 | |
| 37 | 2021-01-27 | FB | 283.10 | 283.18 | 268.15 | 272.14 | 35350000 | |
| 42 | 2021-01-28 | FB | 277.84 | 286.69 | 264.77 | 265.00 | 37760000 | |
| GS | 36 | 2021-01-27 | GS | 276.89 | 277.30 | 271.60 | 273.33 | 3890000 |
| 26 | 2021-01-25 | GS | 289.39 | 289.39 | 277.87 | 283.04 | 4580000 | |
| 10 | 2021-01-20 | GS | 295.82 | 297.45 | 287.48 | 290.47 | 4790000 | |
| 56 | 2021-02-02 | GS | 278.38 | 288.22 | 278.38 | 286.97 | 5200000 | |
| 5 | 2021-01-19 | GS | 304.75 | 306.09 | 293.86 | 294.20 | 6730000 | |
| JD | 44 | 2021-01-28 | JD | 90.15 | 92.16 | 89.59 | 91.41 | 11250000 |
| 59 | 2021-02-02 | JD | 94.88 | 95.99 | 94.22 | 95.42 | 11520000 | |
| 13 | 2021-01-20 | JD | 93.72 | 95.72 | 92.83 | 95.31 | 15500000 | |
| 39 | 2021-01-27 | JD | 93.49 | 94.37 | 89.78 | 90.09 | 16060000 | |
| 29 | 2021-01-25 | JD | 99.44 | 101.68 | 96.29 | 98.38 | 16410000 |
上面在使用 top() 时,对于 n 和 column 我们都只用的默认值 5 和 ‘Volumn’。如果用自己设定的值 n = 1, column = ‘Close’。
data1.groupby(['Symbol','Month']).apply(top, n=1, column='Close')
| Date | Year | Month | Symbol | Close | |||
|---|---|---|---|---|---|---|---|
| Symbol | Month | ||||||
| AAPL | 1 | 33 | 2021-01-26 | 2021 | 1 | AAPL | 143.16 |
| 2 | 68 | 2021-02-04 | 2021 | 2 | AAPL | 137.39 | |
| BABA | 1 | 35 | 2021-01-26 | 2021 | 1 | BABA | 265.92 |
| 2 | 95 | 2021-02-11 | 2021 | 2 | BABA | 268.93 | |
| FB | 1 | 32 | 2021-01-26 | 2021 | 1 | FB | 282.05 |
| 2 | 87 | 2021-02-10 | 2021 | 2 | FB | 271.87 | |
| GS | 1 | 0 | 2021-01-15 | 2021 | 1 | GS | 301.01 |
| 2 | 96 | 2021-02-12 | 2021 | 2 | GS | 306.32 | |
| JD | 1 | 29 | 2021-01-25 | 2021 | 1 | JD | 98.38 |
| 2 | 99 | 2021-02-12 | 2021 | 2 | JD | 99.31 |
按每个 Symbol 和 Month 打印出来了 Close 栏下的最大值。
7 总结
Pandas 里面的数据结构是多维数据表,细化为一维的 Series,二维的 DataFrame,三维的 Panel。
多维数据表 = 多维数组 + 描述
其中
- Series = 1darray + index
- DataFrame = 2darray + index + columns
- Panel = 3darray + index + columns + item
pd 多维数据表和 np 多维数组之间的类比关系如下图所示。
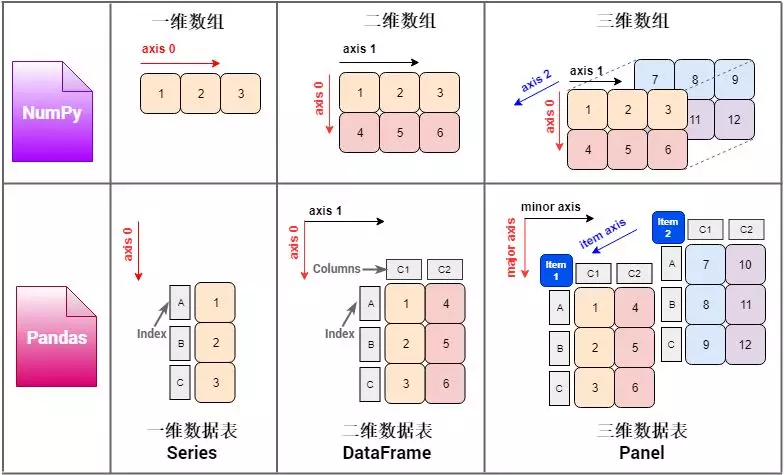
【创建数据表】创建 Series, DataFrame用下面语句
- pd.Series(x, index=idx)
- pd.DataFrame(x, index=idx, columns=col)
【索引和切片数据表】在索引或切片 DataFrame,有很多种方法。最好记的而不易出错的是用基于位置的 at 和 loc,和基于标签的 iat 和 iloc,具体来说,索引用 at 和 iat,切片用 loc 和 iloc。带 i 的基于位置,不带 i 的基于标签。
用 MultiIndex 可以创建多层索引的对象,获取 DataFrame df 的信息可用
- df.loc[1st].loc[2nd]
- df.loc[1st].iloc[2nd]
- df.iloc[1st].loc[2nd]
- df.iloc[1st].iloc[2nd]
要调换 level 可用
- df.index.swaplevel(0,1)
- df.columns.swaplevel(0,1)
要设置和重设 index 可用
- df.set_index( columns )
- df.reset_index
【合并数据表】用 merge 函数按数据表的共有列进行左/右/内/外合并。
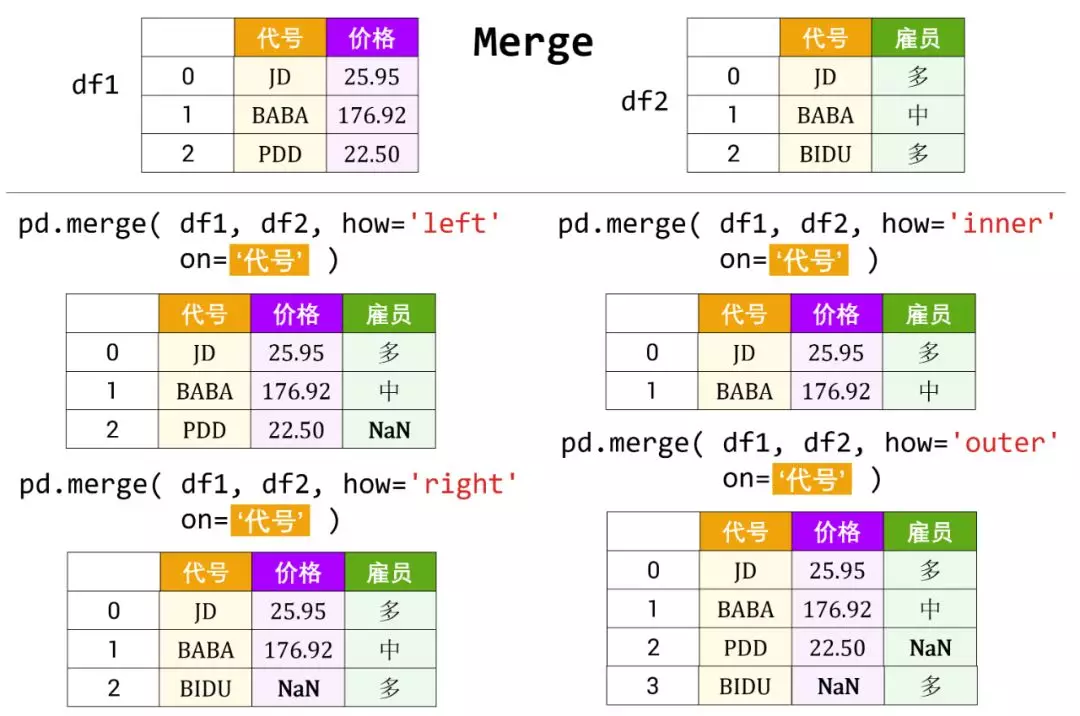
【连接数据表】用 concat 函数对 Series 和 DataFrame 沿着不同轴连接。
【重塑数据表】用 stack 函数将「列索引」变成「行索引」,用 unstack 函数将「行索引」变成「列索引」。它们只是改变数据表的布局和展示方式而已。
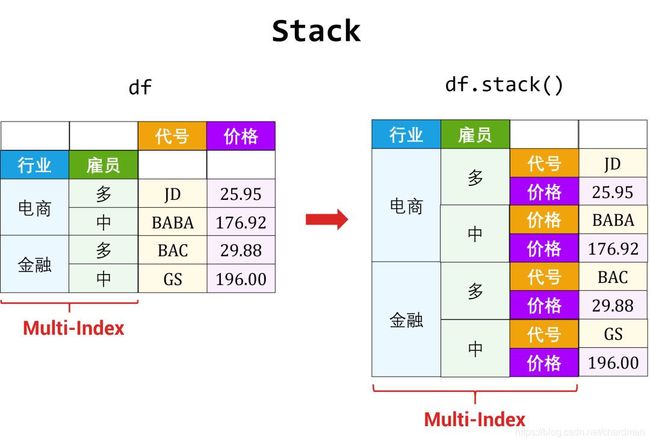
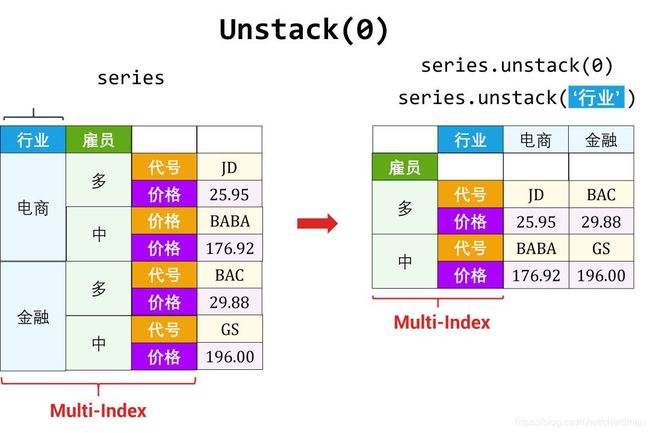

【透视数据表】用 pivot 函数将「一张长表」变成「多张宽表」,用 melt 函数将「多张宽表」变成「一张长表」。它们只是改变数据表的布局和展示方式而已。
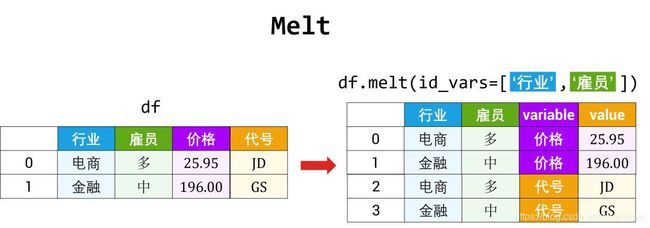
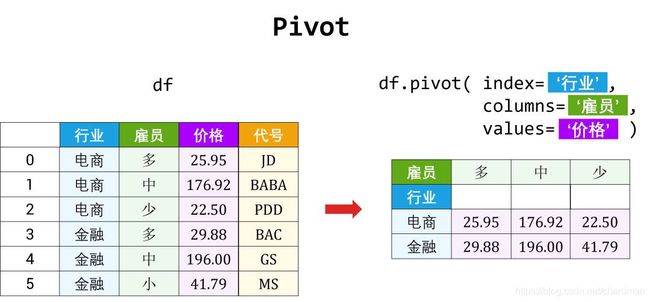
【分组数据表】用 groupBy 函数按不同「列索引」下的值分组。一个「列索引」或多个「列索引」就可以。
【整合数据表】用 agg 函数对每个组做整合而计算统计量。
【split-apply-combine】使用 apply 函数能够提高数据分析的效率。