关于SparkSQL那些事(二)----sparksql基础语法(下)
在上一篇博客中,重点介绍了如何通过sparksql来执行查询操作,虽然可以实现对创建的DateFrame进行操作,但是语法和普通的关系型数据库的SQL操作存在差异。不容易记住,所以这一篇博客中,介绍如何通过普通SQL来操作。
通过SQL语句来调用
创建表
df.registerTempTable("tabName");---->创建的是临时表
df.saveAsTable("tabName");---------->创建的是永久表
永久表和持久表的区别就在于:临时表在会话结束时,会被删除;而持久表会在会话结束后被保存下来。
查询操作
我们首先创建一个DateFrame,进行演示。
>import org.apache.spark.sql.SQLContext
>val ssc=new SQLContext(sc);
>val df=sc.makeRDD(List((1,"a","bj"),(2,"b","sh"),(3,"c","gz"),(4,"d","bj"),(5,"e","gz"))).toDF("id","name","addr");
>df.registerTempTable("stu");----->注册临时表
1)查询

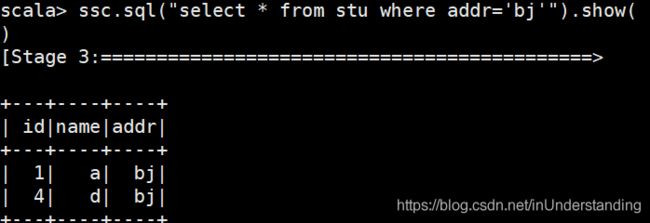
2)带条件查询
3)排序查询
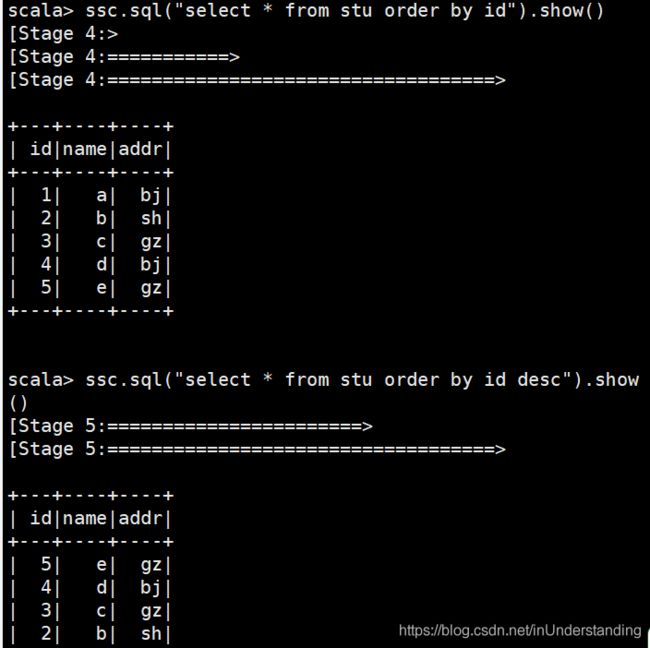
注意:这里和SQL类似,默认的情况下是升序排序。
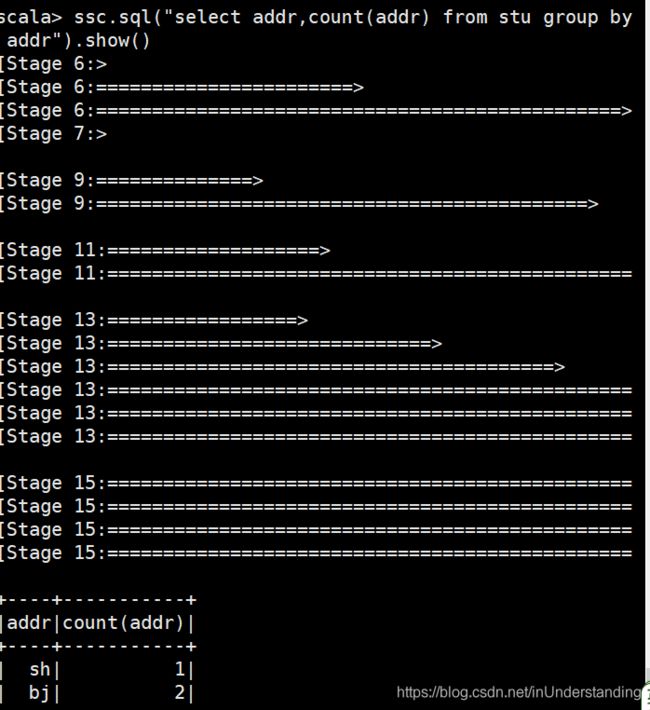
4)分组查询
5)连接查询
这里我们创建新的DataFrame来进行操作。
>import org.apache.spark.sql.SQLContext
>val ssc=new SQLContext(sc);
>val dept=sc.parallelize(List((100,"财务部"),(200,"研发部"))).toDF("deptid","deptname")
>val emp=sc.parallelize(List((1,100,"张财务"),(2,100,"李会计"),(3,300,"王艳发"))).toDF("id","did","name")
>dept.registerTempTable("deptTab");
>emp.registerTempTable("empTab");
>sc.sql("select deptname,name from deptTab inner join empTab on deptTab.deptid=empTab.did").show()

这里演示的是内连接,左外连接和右外连接可自行调试。
6)执行运算
>import org.apache.spark.sql.SQLContext
>val ssc=new SQLContext(sc);
>val df = sc.makeRDD(List(1,2,3,4,5)).toDF("num");
>df.registerTempTable("tabx")
>ssc.sql("select num*10 from tabx").show()
7)分页查询
>import org.apache.spark.sql.SQLContext
>val ssc=new SQLContext(sc);
>val df = sc.makeRDD(List(1,2,3,4,5)).toDF("num");
>df.registerTempTable("tabx")
>ssc.sql("select * from tabx limit 3").show();
8)查看表
>ssc.sql("show tables").show
9) 类似hive方式的操作
>val hiveContext = new org.apache.spark.sql.hive.HiveContext(sc)
>hiveContext.sql("create table if not exists zzz (key int, value string) row format delimited fields terminated by '|'")
>hiveContext.sql("load data local inpath 'file:///home/software/hdata.txt' into table zzz")
>hiveContext.sql("select key,value from zzz").show
10)Scala实现sparkSql操作
val conf=new SparkConf().setMaster("spark://IP地址:7077").setAppName("操作名称");
val sc=new SparkContext(conf);
val sqlContext=new SQLContext(sc)
val rdd=sc.makeRDD(List((1,"zhang"),(2,"li"),(3,"wang")))
import sqlContext.implicits._
val df=rdd.toDF("id","name")
df.registerTempTable("tabx")
val df2=sqlContext.sql("select * from tabx order by name");
val rdd2=df2.toJavaRDD;---->schemaRDD转换成JavaRDD
rdd2.saveAsTextFile("file:///home/software/result")----->将结果输出到linux的本地目录