梯度下降算法原理笔记--机器学习
梯度下降算法原理整理笔记–机器学习
最近在看一些梯度下降的知识,看到头蒙,今天来整理一下一些相关知识,以至于后续便于理解。
机器学习中我们常见梯度下降这个名词,但是什么是梯度下降呢?梯度下降又是干嘛的呢?网上一大堆文章最后也没看懂什么,今天刚好想着整理一下,借鉴着别人的一些看法和知识梳理一下自己的思路。
1.什么是梯度下降?
梯度下降可以把梯度和下降分开来说。
首先理解什么是梯度?通俗来说,梯度就是表示某一函数在该点处的方向导数沿着该方向取得较大值,即函数在当前位置的导数。所以我们可以把梯度理解为导数(对于多元函数则可以理解为偏导),所以我们也可以把梯度下降理解为导数下降。所以梯度下降就是表示某一函数在该点处的相反方向,导数沿着该反方向取得较小值时的自变量对应取值。
某一函数就是我们接下来会用到的损失函数(loss/cost function),也叫做误差函数。
同一个损失函数的两个参数设置的不同,会产生不同的拟合曲线,最后的结果(误差)也不相同。
损失函数就是一个自变量为算法的参数,函数值为误差值的函数。所以梯度下降就是找让误差值最小的时候算法取的参数。
梯度下降的两个参数:(斜率,终止条件之变化量)。
算法的终止条件:一迭代次数,二可以是变化量。
2.基本思想
假设我们爬山,如果想最快的上到山顶,那么我们应该从山势最陡的地方上山。也就是山势变化最快的地方上山。
同样,如果从任意一点出发,需要最快搜索到函数最大值,那么我们也应该从函数变化最快的方向搜索。
函数变化最快的方向是什么呢?
函数的梯度。
如果函数为一元函数,梯度就是该函数的导数。
![]()
如果为二元函数,梯度定义为:
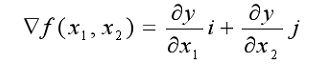
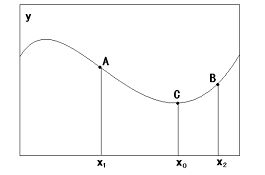
如果需要找的是函数极小点,那么应该从负梯度的方向寻找,该方法称之为梯度下降法。
要搜索极小值C点,在A点必须向x增加方向搜索,此时与A点梯度方向相反;在B点必须向x减小方向搜索,此时与B点梯度方向相反。
总之,搜索极小值,必须向负梯度方向搜索。
3.梯度下降法-步骤
假设函数y=f(x1,x2,…,xn) 只有一个极小点。
初始给定参数为 X0=(x10,x20,…,xn0)。从这个点如何搜索才能找到原函数的极小值点?
方法
1.首先设定一个较小的正数η,ε.
2.求当前位置处的各个偏导数:
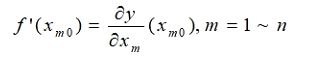
3.修改当前函数的参数值,公式如下:
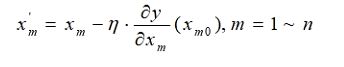
4. 如果参数变化量小于ε,退出;否则返回2。
4.一元线性回归函数推导过程
设线性回归函数: y ^ = w x + b \hat{y}=wx+b y^=wx+b
构造损失函数(loss):
L ( w , b ) = 1 2 n ∑ i = 1 n ( w x i + b − y i ) 2 L(w,b)=\frac{1}{2n}\sum_{i=1}^{n}(wx_{i}+b-y_{i})^{2} L(w,b)=2n1i=1∑n(wxi+b−yi)2
思路:通过梯度下降法不断更新 和 ,当损失函数的值特别小时,就得到 了我们最终的函数模型。
过程:
step1.求导:
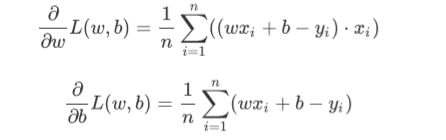
step2.更新 Θ 0 \Theta_{0} Θ0和 Θ 1 \Theta_{1} Θ1:
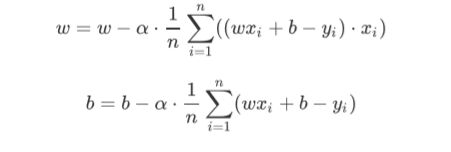
step3.代入损失函数,求损失函数的值,若得到的值小于 ε \varepsilon ε(一般为0.01或 者0.001这样的小数),退出;否则,返回step1。
5.梯度下降存在的问题
∙ \bullet ∙当靠近极小值时收敛速度减慢;
∙ \bullet ∙直线搜索时可能会产生一些问题;
∙ \bullet ∙下降过程可能会出现“之字形”地下降。
6 梯度下降三兄弟(BGD,SGD, MBGD)
6.1 批量梯度下降法(Batch Gradient Descent)
批量梯度下降法每次都使用训练集中的所有样本更新参数。它得到的是一 个全局最优解,但是每迭代一步,都要用到训练集所有的数据,如果m很大,那么迭代速度就会变得很慢。
优点:可以得出全局最优解。
缺点:样本数据集大时,训练速度慢。
6.2 随机梯度下降法(Stochastic Gradient Descent)
随机梯度下降法每次更新都从样本随机选择1组数据,因此随机梯度下降比 批量梯度下降在计算量上会大大减少。
SGD有一个缺点是,其噪音较BGD 要多,使得SGD并不是每次迭代都向着整体最优化方向。而且SGD因为每 次都是使用一个样本进行迭代,因此最终求得的最优解往往不是全局最优 解,而只是局部最优解。但是大的整体的方向是向全局最优解的,最终的 结果往往是在全局最优解附近。
优点:训练速度较快。
缺点:过程杂乱,准确度下降。
6.3小批量梯度下降法(Mini-batch Gradient Descent)
小批量梯度下降法对包含n个样本的数据集进行计算。综合了上述两种方 法,既保证了训练速度快,又保证了准确度。
7.例题
说的再多不如来道实际的例题看的明白,接下来请看题:
例1:任给一个初始出发点,设为x0=-4,利用梯度下降法求函数y=x2/2-2x的极小值。
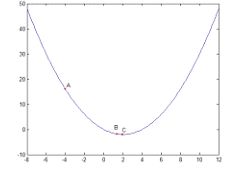


接下来是python代码实现:
``# -*- coding: utf-8 -*-
import numpy as np
import matplotlib.pyplot as plt
def f(x):
return (np.power(x, 2)/2-2*x)
def d_f_1(x):
return x-2
def d_f_2(f, x, delta=1e-4):
return (f(x+delta) - f(x-delta)) / (2 * delta)
#plot the function
xs = np.arange(-8, 12)
plt.plot(xs, f(xs))
plt.show()
learning_rate = 0.9
max_loop = 30
x_init = -4
x = x_init
lr = 0.01
for i in range(max_loop):
# d_f_x = d_f_1(x)
d_f_x = d_f_2(f, x)
x = x - learning_rate * d_f_x
print(x)
print('initial x =', x_init)
print('arg min f(x) of x =', x)
print('f(x) =', f(x))