- 智慧水库信息化系统建设产品需求文档V2.0
小赖同学啊
testTechnologyPrecious物联网
智慧水库信息化系统建设产品需求文档1.引言1.1文档目的本文档旨在明确智慧水库信息化系统的建设需求,为系统设计、开发和实施提供全面依据,确保系统功能满足水库管理业务需求,提升水库管理的智能化水平和决策效率。1.2背景介绍传统水库管理面临数据采集不及时、分析手段有限、决策依赖经验等问题,难以应对复杂多变的水文情势和日益增长的管理需求。随着物联网、大数据、人工智能等技术的发展,智慧水库建设成为必然趋势
- 9.20其二
道左无人
做一家服务公司,为下面的公司提供一些事务性的管理、财务管理、风险管理的服务,粘住一个大圈子的HR,通过下面的公司做掉项目,为HR提供一个稳定的资源变现的渠道;做一家科技公司,提供线上的平台运营,大数据采集,以及基于这个基础上的卖货、信贷等服务做一家连锁企业,每一家门店都是独立的企业,提供招聘、引流以及终端服务所以外部通过众筹绑定大批量的HR,就会有稳定的订单,通过服务公司提供服务,通过终端门店保证
- 只靠可视化大屏,做不了数字化,数据总监总结3点,你做到了几个
大数据的那些事
企业数字化是很多企业热衷的话题。本文的数字化指各行业头的头部企业的端到端数字化解决方案,常见部署于华为专有云、阿里私有云、亚马逊云,项目金额一般百万起步,上不封顶。很多企业投人、投钱数字化,都希望有个酷炫的数据大脑,政府、合作伙伴来参观时,用酷炫的数据大脑让来宾们啧啧称赞。热闹散去后,企业内部的各部门,天天围着数据挖宝,大数据快告诉我,下个月能卖多少,哪几个渠道卖得不好,哪条生产线有问题,哪些货压
- hive底层原理 sql执行过程_Hive原理总结(完整版)
目录课程大纲(HIVE增强)31.Hive基本概念41.1Hive简介41.1.1什么是Hive41.1.2为什么使用Hive41.1.3Hive的特点41.2Hive架构51.2.1架构图51.2.2基本组成51.2.3各组件的基本功能51.3Hive与Hadoop的关系61.4Hive与传统数据库对比61.5Hive的数据存储62.Hive基本操作72.1DDL操作72.1.1创建表72.1.
- hive的sql优化思路-明白底层运行逻辑
ycllycll
hivesqlhadoop
一、首先要明白底层map、shuffle、reduce的顺序之中服务器hdfs数据文件在内存与存储之中是怎么演变的,因为hive的性能瓶颈基本在内存,具体参考以下他人优秀文章:1.HiveSQL底层执行过程详细剖析2.HiveJOIN性能调优二是要明白hive对应的sql它底层的mapreduce的过程中sql字段的执行顺序,来理解map的key、value会填充什么值,才能深刻理解怎么一步一步的
- 你多久没有认真读一本书了
我是巴卡
我九岁博览群书,二十岁达到顶峰。我现在都是看社会人文类的书,例如《知音》《故事会》……往前推三百年,往后推三百年,总共六百年没有人超过我。——凤姐引用凤姐的话,没有嘲讽的意思。现在的人,包括我自己,除了刷手机,恐怕连杂志都很少读了,更别说认真读一本书了。1、大数据下,人越读越窄,越读越傻前段时间,埃航波音737MAX8出事,就在网上跟着读了几篇报道。随后的一段时间,基本打开APP都是关于波音和73
- 注意力才是我们最值钱的东西
心守平凡_王慧超
4月10日晚,罗永浩携手国民神车哈弗品牌完成了第二场带货直播。此次直播共售出11357张2777元的优惠券,预估销售额15.65亿元,创造了汽车直播带货的新纪录。流量时代真的已经来临了,随着互联网的高速发展,越来越多的网络用户增加,我们不得不承认,我们已经进入了一个网络时代,进入了一个流量大数据时代。我们所有想获得的东西都可以通过网络获取,资料、信息、购物,网络正在改变人们的生活方式,正在成为人们
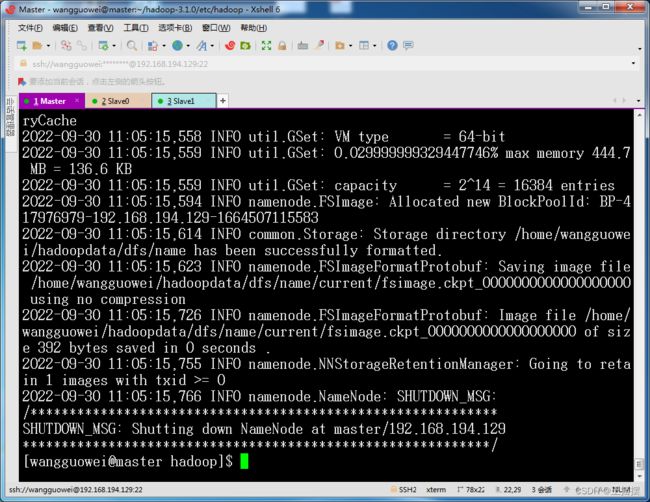
- 六、深度剖析 Hadoop 分布式文件系统(HDFS)的数据存储机制与读写流程
深度剖析Hadoop分布式文件系统(HDFS)的数据存储机制与读写流程在当今大数据领域当中,Hadoop分布式文件系统(HDFS)作为极为关键的核心组件之一,为海量规模的数据的存储以及处理构筑起了坚实无比的根基。本文将会对HDFS的数据存储机制以及读写流程展开全面且深入的探究,通过将原理与实际的实例紧密结合的方式,助力广大读者更加全面地理解HDFS的工作原理以及其具体的应用场景。一、HDFS概述H
- 养老院管理系统基于SpringBoot的养老院管理系统系统设计与实现(源码+论文+部署讲解等)
博主介绍:✌全网粉丝60W+,csdn特邀作者、Java领域优质创作者、csdn/掘金/哔哩哔哩/知乎/道客/小红书等平台优质作者,计算机毕设实战导师,目前专注于大学生项目实战开发,讲解,毕业答疑辅导,欢迎高校老师/同行前辈交流合作✌技术栈范围:SpringBoot、Vue、SSM、Jsp、HLMT、Nodejs、Python、爬虫、数据可视化、小程序、安卓app、大数据、物联网、机器学习、单片机
- 大数据处理技术:分布式文件系统HDFS
茜茜西西CeCe
hdfshadoop大数据HDFS-JAVA接口文件头歌Java
目录1实验名称:2实验目的3实验内容4实验原理5实验过程或源代码5.1HDFS的基本操作5.2HDFS-JAVA接口之读取文件5.3HDFS-JAVA接口之上传文件5.4HDFS-JAVA接口之删除文件6实验结果6.1HDFS的基本操作6.2HDFS-JAVA接口之读取文件6.3HDFS-JAVA接口之上传文件6.4HDFS-JAVA接口之删除文件1实验名称:分布式文件系统HDFS2实验目的1.理
- Linux教程(4)----[hive数据仓库工具]
.房东的猫
Linux教程(完善中~~)linux
Hive基本概念Hive简介什么是HiveHive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能。为什么使用Hive直接使用hadoop所面临的问题人员学习成本太高
- 基于用户画像的商品推荐系统
Dush32
机器学习人工智能python推荐算法
随着人工智能和大数据技术的进步,产品推荐系统成为了现代广告与电商平台中不可或缺的部分。通过深度挖掘用户的行为数据,能够为广告主提供精准的用户画像,从而更高效地推荐相关产品,提升购买转化率。本项目基于科大讯飞AI营销云大赛的赛题,目的是利用用户画像进行产品推荐,预测用户是否会购买相应商品。我们使用了机器学习的二分类模型,通过分析用户的性别、年龄、常驻地、机型等信息,来判断用户的付费行为。项目目标:本
- InfluxDB 数据模型:桶、测量、标签与字段详解(一)
计算机毕设定制辅导-无忧
#InfluxDBdb
一、引言**在大数据和物联网蓬勃发展的当下,时间序列数据的处理需求呈爆发式增长。InfluxDB作为一款高性能的开源时序数据库,凭借其卓越的特性,在时序数据库领域占据了重要地位,被广泛应用于各种场景。InfluxDB专为时间序列数据设计,拥有高效的存储和查询性能。它采用独特的存储引擎,能够快速写入大量带有时间戳的数据,并支持灵活的查询操作。其核心设计针对时间序列数据的特点进行了优化,包括时间索引、
- Kafka 集群架构与高可用方案设计(一)
计算机毕设定制辅导-无忧
#Kafkakafka架构分布式
Kafka集群架构与高可用方案设计的重要性在大数据和分布式系统的广阔领域中,Kafka已然成为了一个中流砥柱般的存在。它最初由LinkedIn开发,后捐赠给Apache软件基金会并成为顶级项目,凭借其卓越的高吞吐量、可扩展性以及持久性,被广泛应用于日志收集、实时数据处理、流计算、数据集成等诸多关键领域。在日志收集场景下,以大型互联网公司为例,每天都会产生海量的日志数据,如用户的访问记录、系统操作日
- 大数据集成方案对比:Kafka vs Flume vs Sqoop
AI天才研究院
计算AI大模型应用入门实战与进阶AgenticAI实战大数据kafkaflumeai
大数据集成方案对比:KafkavsFlumevsSqoop关键词:大数据集成、Kafka、Flume、Sqoop、流处理、批量迁移、日志收集摘要:在大数据生态中,数据集成是连接数据源与数据处理平台的关键环节。本文深度对比Kafka、Flume、Sqoop三大主流集成工具,从核心架构、技术原理、适用场景到实战案例展开系统性分析。通过数学模型量化性能差异,结合实际项目经验总结选型策略,帮助开发者根据业
- 【Hadoop】onekey_install脚本
菜萝卜子
Linuxhadoop大数据分布式
hosts[root@kafka01hadoop-script]#cat/etc/hosts127.0.0.1localhostlocalhost.localdomainlocalhost4localhost4.localdomain4::1localhostlocalhost.localdomainlocalhost6localhost6.localdomain6192.168.100.150k
- 飞算科技:以创新科技引领数字化变革,旗下飞算 JavaAI 成开发利器
飞算JavaAI开发助手
科技
作为国家级高新技术企业,飞算科技专注于自主创新,在数字科技领域持续深耕,用前沿技术为各行业客户赋能,助力其实现数字化转型升级的飞跃。飞算科技凭借深厚的技术积累,将互联网科技、大数据、人工智能等技术与实际应用紧密融合。公司组建了一支由行业资深专家和技术精英构成的团队,他们在相关领域积累了多年实践经验,深刻理解不同行业客户在数字化进程中面临的痛点与挑战。基于这些洞察,飞算科技推出了一系列具有创新性和实
- Java 大视界 -- Java 大数据机器学习模型在金融市场情绪分析与投资策略制定中的应用
青云交
大数据新视界Java大视界java大数据机器学习情绪分析智能投资多源数据
Java大视界--Java大数据机器学习模型在金融市场情绪分析与投资策略制定中的应用)引言:正文:一、金融情绪数据的立体化采集与治理1.1多模态数据采集架构1.2数据治理与特征工程二、Java机器学习模型的工程化实践2.1情感分析模型的深度优化2.2强化学习驱动的动态投资策略三、顶级机构实战:Java系统的金融炼金术四、技术前沿:Java与金融科技的未来融合4.1量子机器学习集成4.2联邦学习在合
- Java 大视界 -- Java 大数据在影视内容推荐与用户兴趣挖掘中的深度实践(183)
青云交
大数据新视界Java大视界Java+Python双剑合璧:AI大数据实战通关秘籍大数据影视内容推荐用户兴趣挖掘协同过滤基于内容推荐数据可视化个性化推荐系统
亲爱的朋友们,热烈欢迎来到青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而我的博客正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也期待你毫无保留地分享独特见解,愿我们于此携手成长,共赴新程!全网(微信公众号/CSDN/抖音/华为/支付宝/微博):青云交一、欢迎加入【福利社群】点击快速加入1:青云交技术圈福利社群(NEW)点击快速加入2:2025CS
- Java 大视界 -- 基于 Java 的大数据分布式文件系统在科研数据存储与共享中的应用优化(187)
青云交
大数据新视界Java大视界Java+Python双剑合璧:AI大数据实战通关秘籍大数据大数据分布式文件系统科研数据存储科研数据共享应用优化HDFS数据分区
亲爱的朋友们,热烈欢迎来到青云交的博客!能与诸位在此相逢,我倍感荣幸。在这飞速更迭的时代,我们都渴望一方心灵净土,而我的博客正是这样温暖的所在。这里为你呈上趣味与实用兼具的知识,也期待你毫无保留地分享独特见解,愿我们于此携手成长,共赴新程!全网(微信公众号/CSDN/抖音/华为/支付宝/微博):青云交一、欢迎加入【福利社群】点击快速加入1:青云交技术圈福利社群(NEW)点击快速加入2:CSDN博客
- Python医疗大数据实战:基于Scrapy-Redis的医院评价数据分布式爬虫设计与实现
Python爬虫项目
python开发语言爬虫seleniumscrapy
摘要本文将详细介绍如何使用Python构建一个高效的医院评价数据爬虫系统。我们将从爬虫基础讲起,逐步深入到分布式爬虫架构设计,使用Scrapy框架结合Redis实现分布式爬取,并采用最新的反反爬技术确保数据采集的稳定性。文章包含完整的代码实现、性能优化方案以及数据处理方法,帮助读者掌握医疗大数据采集的核心技术。关键词:Python爬虫、Scrapy-Redis、分布式爬虫、医疗大数据、反反爬技术1
- flink-sql读写hive-1.13
第一片心意
flinkflinksqlhive
1.版本说明本文档内容基于flink-1.13.x,其他版本的整理,请查看本人博客的flink专栏其他文章。1.1.概述ApacheHive已经成为了数据仓库生态系统中的核心。它不仅仅是一个用于大数据分析和ETL场景的SQL引擎,同样也是一个数据管理平台,可用于发现,定义,和演化数据。Flink与Hive的集成包含两个层面。一是利用了Hive的MetaStore作为持久化的Catalog,用户可通
- 觉察与正念
佳佳的宝瓶子
今天因为交电费的事与妈妈沟通。在沟通的过程中,年届八十的母亲一直给我强调着过去怎么怎么。父母家的电费一直是银行代扣的,这样的模式自从可以通过银行代扣便开始了。可见那时候的父母还是蛮新潮的,能接受新事物的。至从有了智能手机,人类便进入了大数据时代。通过微信或支付宝来交电费方便得多。可惜父亲不在了,老母亲是连手机都坚决不用的人。(因为想要掩饰自己的不能、不敢,所以干脆拒绝!不愿意做任何的改变)。今年,
- Java大视界:Java大数据在智能医疗电子健康档案数据挖掘与健康服务创新>
Loving_enjoy
计算机学科论文创新点人工智能深度学习迁移学习经验分享
>本文通过完整代码示例,揭秘如何用Java大数据技术挖掘电子健康档案价值,实现疾病预测、个性化健康管理等创新服务。###一、智能医疗时代的数据金矿电子健康档案(EHR)作为医疗数字化的核心载体,包含海量患者全生命周期健康数据。据统计,全球医疗数据量正以每年**48%的速度增长**,单个三甲医院年数据量可达**PB级**。这些数据蕴藏着疾病规律、治疗效能的宝贵知识,但传统技术难以有效挖掘。**Jav
- 无人值守人工智能智慧系统数据分析:深度洞察与未来展望
呆码科技
人工智能数据分析数据挖掘
无人值守人工智能智慧系统数据分析:深度洞察与未来展望随着科技的飞速发展,人工智能(AI)技术已逐渐渗透到社会经济的各个领域,其中无人值守人工智能智慧系统作为AI技术应用的前沿阵地,正引领着一场深刻的行业变革。这类系统通过集成高级算法、大数据分析、物联网(IoT)及云计算等先进技术,实现了对复杂环境的自主监控、智能决策与高效管理,极大地提升了运营效率,降低了人力成本,并开启了数据驱动决策的新纪元。本
- 浮漂式水质监测设备:智能守护水环境的未来之眼
柏峰电子
人工智能
浮漂式水质监测设备:智能守护水环境的未来之眼柏峰【BF-FBSZ】随着全球水资源短缺和水污染问题日益严峻,水质监测技术正迎来前所未有的发展机遇。作为这一领域的创新突破,浮漂式水质监测设备凭借其实时性、智能化和网络化优势,正在重塑水资源管理的新格局。本文将深入探讨这一技术的原理、特点、应用场景及未来发展趋势。一、技术原理与系统架构浮漂式水质监测设备是一种集成了现代传感器技术、物联网和大数据分析的智能
- 基于蜣螂算法优化多头注意力机制的卷积神经网络结合双向长短记忆神经网络实现温度预测DBO-CNN-biLSTM-Multihead-Attention附matlab代码
matlab科研助手
神经网络算法cnn
✅作者简介:热爱科研的Matlab仿真开发者,修心和技术同步精进,代码获取、论文复现及科研仿真合作可私信。个人主页:Matlab科研工作室个人信条:格物致知。更多Matlab完整代码及仿真定制内容点击智能优化算法神经网络预测雷达通信无线传感器电力系统信号处理图像处理路径规划元胞自动机无人机物理应用机器学习内容介绍温度预测在气象学、农业、能源等领域具有重要的应用价值。随着大数据和人工智能技术的快速发
- 基于Socket来构建无界数据流并通过Flink框架进行处理
每天五分钟玩转人工智能
Flink技术实战flink大数据Flink分布式无界数据
本文重点随着大数据技术的不断发展,实时数据流处理已成为企业应对海量数据、实现快速决策的关键技术。ApacheFlink是一个开源的流处理框架,它能够对无界数据流进行高效的、精确的处理。本文将介绍如何通过Socket构建无界数据流,并利用Flink框架进行无界流处理。基于Socket构建无界数据无界数据指的是源源不断产生的数据,这些数据通常来自各种实时数据源,如用户行为日志、传感器数据等。Socke
- sgg大数据全套技术链接[plus]
原来是大华啊~
资源大数据
写在开头:感谢尚硅谷,尚硅谷万岁,我爱尚硅谷111个技术栈+43个项目,兄弟们,冲!最近小米又又又火了一把,致敬所有造福人民的企业和伟大的企业家,致敬雷军,小米,致敬马云,致敬尚硅谷,致敬所有为人民谋福的英雄人物和企业,再次献上我诚挚的敬意,致敬!尚硅谷大数据全套111个技术1.Java从入门到精通JDK版链接:https://pan.baidu.com/s/1GAc610SYSMmZBuOX4D
- cdh6.3.2的hive使用apache paimon格式只能创建不能写报错的问题
明天,今天,此时
hivepaimon
前言 根据官网paimon安装教程,看上去简单,实则报错阻碍使用的信心。解决方法 原带的jars下的zstd开头的包旧了,重新下载zstd较新的包单独放到每个节点的hive/lib下; 然后将hdfsyarn用户下的mr-framework.tar.gz中的zstdjar包替换成新的版本。 重启就可以了总结 国外软件问题,尽量使用英文搜索,特别是google.。方法来源:http
- apache 安装linux windows
墙头上一根草
apacheinuxwindows
linux安装Apache 有两种方式一种是手动安装通过二进制的文件进行安装,另外一种就是通过yum 安装,此中安装方式,需要物理机联网。以下分别介绍两种的安装方式
通过二进制文件安装Apache需要的软件有apr,apr-util,pcre
1,安装 apr 下载地址:htt
- fill_parent、wrap_content和match_parent的区别
Cb123456
match_parentfill_parent
fill_parent、wrap_content和match_parent的区别:
1)fill_parent
设置一个构件的布局为fill_parent将强制性地使构件扩展,以填充布局单元内尽可能多的空间。这跟Windows控件的dockstyle属性大体一致。设置一个顶部布局或控件为fill_parent将强制性让它布满整个屏幕。
2) wrap_conte
- 网页自适应设计
天子之骄
htmlcss响应式设计页面自适应
网页自适应设计
网页对浏览器窗口的自适应支持变得越来越重要了。自适应响应设计更是异常火爆。再加上移动端的崛起,更是如日中天。以前为了适应不同屏幕分布率和浏览器窗口的扩大和缩小,需要设计几套css样式,用js脚本判断窗口大小,选择加载。结构臃肿,加载负担较大。现笔者经过一定时间的学习,有所心得,故分享于此,加强交流,共同进步。同时希望对大家有所
- [sql server] 分组取最大最小常用sql
一炮送你回车库
SQL Server
--分组取最大最小常用sql--测试环境if OBJECT_ID('tb') is not null drop table tb;gocreate table tb( col1 int, col2 int, Fcount int)insert into tbselect 11,20,1 union allselect 11,22,1 union allselect 1
- ImageIO写图片输出到硬盘
3213213333332132
javaimage
package awt;
import java.awt.Color;
import java.awt.Font;
import java.awt.Graphics;
import java.awt.image.BufferedImage;
import java.io.File;
import java.io.IOException;
import javax.imagei
- 自己的String动态数组
宝剑锋梅花香
java动态数组数组
数组还是好说,学过一两门编程语言的就知道,需要注意的是数组声明时需要把大小给它定下来,比如声明一个字符串类型的数组:String str[]=new String[10]; 但是问题就来了,每次都是大小确定的数组,我需要数组大小不固定随时变化怎么办呢? 动态数组就这样应运而生,龙哥给我们讲的是自己用代码写动态数组,并非用的ArrayList 看看字符
- pinyin4j工具类
darkranger
.net
pinyin4j工具类Java工具类 2010-04-24 00:47:00 阅读69 评论0 字号:大中小
引入pinyin4j-2.5.0.jar包:
pinyin4j是一个功能强悍的汉语拼音工具包,主要是从汉语获取各种格式和需求的拼音,功能强悍,下面看看如何使用pinyin4j。
本人以前用AscII编码提取工具,效果不理想,现在用pinyin4j简单实现了一个。功能还不是很完美,
- StarUML学习笔记----基本概念
aijuans
UML建模
介绍StarUML的基本概念,这些都是有效运用StarUML?所需要的。包括对模型、视图、图、项目、单元、方法、框架、模型块及其差异以及UML轮廓。
模型、视与图(Model, View and Diagram)
&
- Activiti最终总结
avords
Activiti id 工作流
1、流程定义ID:ProcessDefinitionId,当定义一个流程就会产生。
2、流程实例ID:ProcessInstanceId,当开始一个具体的流程时就会产生,也就是不同的流程实例ID可能有相同的流程定义ID。
3、TaskId,每一个userTask都会有一个Id这个是存在于流程实例上的。
4、TaskDefinitionKey和(ActivityImpl activityId
- 从省市区多重级联想到的,react和jquery的差别
bee1314
jqueryUIreact
在我们的前端项目里经常会用到级联的select,比如省市区这样。通常这种级联大多是动态的。比如先加载了省,点击省加载市,点击市加载区。然后数据通常ajax返回。如果没有数据则说明到了叶子节点。 针对这种场景,如果我们使用jquery来实现,要考虑很多的问题,数据部分,以及大量的dom操作。比如这个页面上显示了某个区,这时候我切换省,要把市重新初始化数据,然后区域的部分要从页面
- Eclipse快捷键大全
bijian1013
javaeclipse快捷键
Ctrl+1 快速修复(最经典的快捷键,就不用多说了)Ctrl+D: 删除当前行 Ctrl+Alt+↓ 复制当前行到下一行(复制增加)Ctrl+Alt+↑ 复制当前行到上一行(复制增加)Alt+↓ 当前行和下面一行交互位置(特别实用,可以省去先剪切,再粘贴了)Alt+↑ 当前行和上面一行交互位置(同上)Alt+← 前一个编辑的页面Alt+→ 下一个编辑的页面(当然是针对上面那条来说了)Alt+En
- js 笔记 函数
征客丶
JavaScript
一、函数的使用
1.1、定义函数变量
var vName = funcation(params){
}
1.2、函数的调用
函数变量的调用: vName(params);
函数定义时自发调用:(function(params){})(params);
1.3、函数中变量赋值
var a = 'a';
var ff
- 【Scala四】分析Spark源代码总结的Scala语法二
bit1129
scala
1. Some操作
在下面的代码中,使用了Some操作:if (self.partitioner == Some(partitioner)),那么Some(partitioner)表示什么含义?首先partitioner是方法combineByKey传入的变量,
Some的文档说明:
/** Class `Some[A]` represents existin
- java 匿名内部类
BlueSkator
java匿名内部类
组合优先于继承
Java的匿名类,就是提供了一个快捷方便的手段,令继承关系可以方便地变成组合关系
继承只有一个时候才能用,当你要求子类的实例可以替代父类实例的位置时才可以用继承。
在Java中内部类主要分为成员内部类、局部内部类、匿名内部类、静态内部类。
内部类不是很好理解,但说白了其实也就是一个类中还包含着另外一个类如同一个人是由大脑、肢体、器官等身体结果组成,而内部类相
- 盗版win装在MAC有害发热,苹果的东西不值得买,win应该不用
ljy325
游戏applewindowsXPOS
Mac mini 型号: MC270CH-A RMB:5,688
Apple 对windows的产品支持不好,有以下问题:
1.装完了xp,发现机身很热虽然没有运行任何程序!貌似显卡跑游戏发热一样,按照那样的发热量,那部机子损耗很大,使用寿命受到严重的影响!
2.反观安装了Mac os的展示机,发热量很小,运行了1天温度也没有那么高
&nbs
- 读《研磨设计模式》-代码笔记-生成器模式-Builder
bylijinnan
java设计模式
声明: 本文只为方便我个人查阅和理解,详细的分析以及源代码请移步 原作者的博客http://chjavach.iteye.com/
/**
* 生成器模式的意图在于将一个复杂的构建与其表示相分离,使得同样的构建过程可以创建不同的表示(GoF)
* 个人理解:
* 构建一个复杂的对象,对于创建者(Builder)来说,一是要有数据来源(rawData),二是要返回构
- JIRA与SVN插件安装
chenyu19891124
SVNjira
JIRA安装好后提交代码并要显示在JIRA上,这得需要用SVN的插件才能看见开发人员提交的代码。
1.下载svn与jira插件安装包,解压后在安装包(atlassian-jira-subversion-plugin-0.10.1)
2.解压出来的包里下的lib文件夹下的jar拷贝到(C:\Program Files\Atlassian\JIRA 4.3.4\atlassian-jira\WEB
- 常用数学思想方法
comsci
工作
对于搞工程和技术的朋友来讲,在工作中常常遇到一些实际问题,而采用常规的思维方式无法很好的解决这些问题,那么这个时候我们就需要用数学语言和数学工具,而使用数学工具的前提却是用数学思想的方法来描述问题。。下面转帖几种常用的数学思想方法,仅供学习和参考
函数思想
把某一数学问题用函数表示出来,并且利用函数探究这个问题的一般规律。这是最基本、最常用的数学方法
- pl/sql集合类型
daizj
oracle集合typepl/sql
--集合类型
/*
单行单列的数据,使用标量变量
单行多列数据,使用记录
单列多行数据,使用集合(。。。)
*集合:类似于数组也就是。pl/sql集合类型包括索引表(pl/sql table)、嵌套表(Nested Table)、变长数组(VARRAY)等
*/
/*
--集合方法
&n
- [Ofbiz]ofbiz初用
dinguangx
电商ofbiz
从github下载最新的ofbiz(截止2015-7-13),从源码进行ofbiz的试用
1. 加载测试库
ofbiz内置derby,通过下面的命令初始化测试库
./ant load-demo (与load-seed有一些区别)
2. 启动内置tomcat
./ant start
或
./startofbiz.sh
或
java -jar ofbiz.jar
&
- 结构体中最后一个元素是长度为0的数组
dcj3sjt126com
cgcc
在Linux源代码中,有很多的结构体最后都定义了一个元素个数为0个的数组,如/usr/include/linux/if_pppox.h中有这样一个结构体: struct pppoe_tag { __u16 tag_type; __u16 tag_len; &n
- Linux cp 实现强行覆盖
dcj3sjt126com
linux
发现在Fedora 10 /ubutun 里面用cp -fr src dest,即使加了-f也是不能强行覆盖的,这时怎么回事的呢?一两个文件还好说,就输几个yes吧,但是要是n多文件怎么办,那还不输死人呢?下面提供三种解决办法。 方法一
我们输入alias命令,看看系统给cp起了一个什么别名。
[root@localhost ~]# aliasalias cp=’cp -i’a
- Memcached(一)、HelloWorld
frank1234
memcached
一、简介
高性能的架构离不开缓存,分布式缓存中的佼佼者当属memcached,它通过客户端将不同的key hash到不同的memcached服务器中,而获取的时候也到相同的服务器中获取,由于不需要做集群同步,也就省去了集群间同步的开销和延迟,所以它相对于ehcache等缓存来说能更好的支持分布式应用,具有更强的横向伸缩能力。
二、客户端
选择一个memcached客户端,我这里用的是memc
- Search in Rotated Sorted Array II
hcx2013
search
Follow up for "Search in Rotated Sorted Array":What if duplicates are allowed?
Would this affect the run-time complexity? How and why?
Write a function to determine if a given ta
- Spring4新特性——更好的Java泛型操作API
jinnianshilongnian
spring4generic type
Spring4新特性——泛型限定式依赖注入
Spring4新特性——核心容器的其他改进
Spring4新特性——Web开发的增强
Spring4新特性——集成Bean Validation 1.1(JSR-349)到SpringMVC
Spring4新特性——Groovy Bean定义DSL
Spring4新特性——更好的Java泛型操作API
Spring4新
- CentOS安装JDK
liuxingguome
centos
1、行卸载原来的:
[root@localhost opt]# rpm -qa | grep java
tzdata-java-2014g-1.el6.noarch
java-1.7.0-openjdk-1.7.0.65-2.5.1.2.el6_5.x86_64
java-1.6.0-openjdk-1.6.0.0-11.1.13.4.el6.x86_64
[root@localhost
- 二分搜索专题2-在有序二维数组中搜索一个元素
OpenMind
二维数组算法二分搜索
1,设二维数组p的每行每列都按照下标递增的顺序递增。
用数学语言描述如下:p满足
(1),对任意的x1,x2,y,如果x1<x2,则p(x1,y)<p(x2,y);
(2),对任意的x,y1,y2, 如果y1<y2,则p(x,y1)<p(x,y2);
2,问题:
给定满足1的数组p和一个整数k,求是否存在x0,y0使得p(x0,y0)=k?
3,算法分析:
(
- java 随机数 Math与Random
SaraWon
javaMathRandom
今天需要在程序中产生随机数,知道有两种方法可以使用,但是使用Math和Random的区别还不是特别清楚,看到一篇文章是关于的,觉得写的还挺不错的,原文地址是
http://www.oschina.net/question/157182_45274?sort=default&p=1#answers
产生1到10之间的随机数的两种实现方式:
//Math
Math.roun
- oracle创建表空间
tugn
oracle
create temporary tablespace TXSJ_TEMP
tempfile 'E:\Oracle\oradata\TXSJ_TEMP.dbf'
size 32m
autoextend on
next 32m maxsize 2048m
extent m
- 使用Java8实现自己的个性化搜索引擎
yangshangchuan
javasuperword搜索引擎java8全文检索
需要对249本软件著作实现句子级别全文检索,这些著作均为PDF文件,不使用现有的框架如lucene,自己实现的方法如下:
1、从PDF文件中提取文本,这里的重点是如何最大可能地还原文本。提取之后的文本,一个句子一行保存为文本文件。
2、将所有文本文件合并为一个单一的文本文件,这样,每一个句子就有一个唯一行号。
3、对每一行文本进行分词,建立倒排表,倒排表的格式为:词=包含该词的总行数N=行号