[机器学习实战] 支持向量机
目录
一、概述
二、算法介绍
三、实现步骤
1、基于最大间隔分隔数据
2、寻找最大间隔
3、SMO高效优化算法
4、利用完整PlattSMO算法加速优化
5、在复杂数据上应用核函数
6、示例:手写识别问题回顾
一、概述
支持向量机是常用的一类分类模型,它通过在两类数据之间寻找一个超平面来分隔不同类的数据。支持向量机最后对应一个二次规划模型(其最优化问题的对偶问题),可以使用通常二次规划求解方法求解,也可以使用Platt在1996年提出的SMO(Sequential Minimal Optimization),它通过一种启发式的误差修正方法求解。
二、算法介绍
支持向量机(support vector machines, SVM)是一种二分类模型,它的基本模型是定义在特征空间上的间隔最大的线性分类器,间隔最大使它有别于感知机;SVM还包括核技巧,这使它成为实质上的非线性分类器。SVM的的学习策略就是间隔最大化,可形式化为一个求解凸二次规划的问题,也等价于正则化的合页损失函数的最小化问题。SVM的的学习算法就是求解凸二次规划的最优化算法。
简单地说,支持向量,就是离分隔超平面最近的那些点,支持向量机的学习就是要对最大化支持向量和分隔面的距离并找到优化求解办法。
支持向量机
优点:泛化错误率低,计算开销不大,结果易解释
缺点:对参数调节和核函数的选择敏感,原始分类器不加修改仅适用于处理二类问题。
适用数据类型:数值型和标称型数据。
三、实现步骤
1、基于最大间隔分隔数据
线性可分:可以很容易就在数据中给出一条直线将两组数据点分开
如果数据不能用一条线进行分类,那就称之为线性不可分数据。
分隔超平面:将数据集分割开来的直线
数据点在二维平面上,分隔超平面就只是一条直线,但数据集是三维时,那么分隔超平面就是一个平面。依此类推,如果数据集是 N ( N ≥ 2 N(N\geq2 N(N≥2)维时,那么就需要一个 N − 1 N-1 N−1维的对象来分隔数据。该对象被称为超平面,也就是分类的决策边界。
理想状态是分布在超平面一侧的所有数据都属于某个类别,而分布在另一侧的所有数据则属于另一个类别。
间隔:离分隔超平面最近的点,到分隔面的距离
间隔应该尽可能地大,这是因为如果我们犯错或者在有限数据上训练分类器的话,大的间隔可以增加分类器的鲁棒性。
支持向量:离分隔超平面最近的那些点
支持向量到分割面的距离应该最大化。
2、寻找最大间隔
如何求解数据集的最佳分隔直线?
以图6-3为例,分隔超平面的形式可以写成![]() ,点A到分隔超平面的法线长度
,点A到分隔超平面的法线长度![]()
最大化间隔的目标就是找出分类器定义中的w和b。为此,我们必须找到具有最小间隔的数据点,而这些数据点也就是前面提到的支持向量。一旦找到具有最小间隔的数据点,我们就需要对该间隔最大化。这就可以写作:
![[机器学习实战] 支持向量机_第1张图片](http://img.e-com-net.com/image/info8/11e29da1a0664cb28f4958c38e45ce78.jpg)
直接求解上述问题相当困难,所以我们将它转换成为另一种更容易求解的形式。通过引人拉格朗日乘子,我们就可以基于约束条件来表述原来的问题。由于这里的约束条件都是基于数据点的,因此我们就可以将超平面写成数据点的形式。于是,优化目标函数最后可以写成:
![[机器学习实战] 支持向量机_第2张图片](http://img.e-com-net.com/image/info8/78773218d3374e138b50221eaebe67bb.jpg)
其约束条件为:
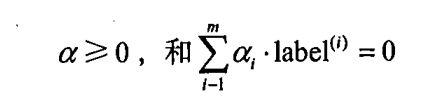
其中常数C 用于控制 “最大化间隔” 和 “保证大部分点的函数间隔小于1.0” 这两个目标的权重。在优化算法的实现代码中,常数C 是一个参数,因此可以通过调节该参数得到不同的结果。一旦求出了所有的 α ,那么分隔超平面就可以通过这些 α 来表达。
SVM的一般流程
(1) 收集数据:可以使用任意方法。
(2) 准备数据:需要数值型数据。
(3) 分析数据:有助于可视化分隔超平面。
(4) 训练算法:SVM的大部分时间都源自训练,该过程主要实现两个参数的调优。
(5) 测试算法:十分简单的计算过程就可以实现。
(6) 使用算法:几乎所有分类问题都可以使用SVM,值得一提的是,SVM本身是一个二类分类器,对多类问题应用SVM需要对代码做一些修改。
3、SMO高效优化算法
简化版SMO算法,省略了确定要优化的最佳alpha对的步骤,而是首先在数据集上遍历每一个alpha, 然后在剩下的alpha集合中随机选择另一个alpha, 从而构建alpha对。这里有一点相当重要,就是我们要同时改变两个alphao之所以这样做是因为我们有一个约束条件:
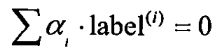
由于改变一个alpha可能会导致该约束条件失效,因此我们总是同时改变两个alpha。
SMO算法中的辅助函数
def loadDataSet(fileName):
dataMat = []; labelMat = []
fr = open(fileName)
for line in fr.readlines():
lineArr = line.strip().split('\t')
dataMat.append([float(lineArr[0]), float(lineArr[1])])
labelMat.append(float(lineArr[2]))
return dataMat,labelMat
def selectJrand(i,m):
j=i #we want to select any J not equal to i
while (j==i):
j = int(random.uniform(0,m))
return j
def clipAlpha(aj,H,L):
if aj > H:
aj = H
if L > aj:
aj = L
return aj第一个函数是loadDatSet()函数,该函数打开文件并对其进行逐行解析,从而得到每行的类标签和整个数据矩阵。
下一个函数selectJrand()有两个参数值,其中i是第一个alpha的下标,m是所有alpha的数目。只要函数值不等于输人值i,函数就会进行随机选择。
最后一个辅助函数就是clipA1pha(),它是用于调整大于H或小于L的alpha值。
尽管上述3个辅助函数本身做的事情不多,但在分类器中却很有用处。
简化版SMO算法
def smoSimple(dataMatIn, classLabels, C, toler, maxIter):
dataMatrix = mat(dataMatIn); labelMat = mat(classLabels).transpose()
b = 0; m,n = shape(dataMatrix)
alphas = mat(zeros((m,1)))
iter = 0
while (iter < maxIter):
alphaPairsChanged = 0
for i in range(m):
fXi = float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[i,:].T)) + b
Ei = fXi - float(labelMat[i])#if checks if an example violates KKT conditions
if ((labelMat[i]*Ei < -toler) and (alphas[i] < C)) or ((labelMat[i]*Ei > toler) and (alphas[i] > 0)):
j = selectJrand(i,m)
fXj = float(multiply(alphas,labelMat).T*(dataMatrix*dataMatrix[j,:].T)) + b
Ej = fXj - float(labelMat[j])
alphaIold = alphas[i].copy(); alphaJold = alphas[j].copy();
if (labelMat[i] != labelMat[j]):
L = max(0, alphas[j] - alphas[i])
H = min(C, C + alphas[j] - alphas[i])
else:
L = max(0, alphas[j] + alphas[i] - C)
H = min(C, alphas[j] + alphas[i])
if L==H: print "L==H"; continue
eta = 2.0 * dataMatrix[i,:]*dataMatrix[j,:].T - dataMatrix[i,:]*dataMatrix[i,:].T - dataMatrix[j,:]*dataMatrix[j,:].T
if eta >= 0: print "eta>=0"; continue
alphas[j] -= labelMat[j]*(Ei - Ej)/eta
alphas[j] = clipAlpha(alphas[j],H,L)
if (abs(alphas[j] - alphaJold) < 0.00001): print "j not moving enough"; continue
alphas[i] += labelMat[j]*labelMat[i]*(alphaJold - alphas[j])#update i by the same amount as j
#the update is in the oppostie direction
b1 = b - Ei- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[i,:].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[i,:]*dataMatrix[j,:].T
b2 = b - Ej- labelMat[i]*(alphas[i]-alphaIold)*dataMatrix[i,:]*dataMatrix[j,:].T - labelMat[j]*(alphas[j]-alphaJold)*dataMatrix[j,:]*dataMatrix[j,:].T
if (0 < alphas[i]) and (C > alphas[i]): b = b1
elif (0 < alphas[j]) and (C > alphas[j]): b = b2
else: b = (b1 + b2)/2.0
alphaPairsChanged += 1
print "iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged)
if (alphaPairsChanged == 0): iter += 1
else: iter = 0
print "iteration number: %d" % iter
return b,alphas4、利用完整PlattSMO算法加速优化
在简化版和完整版这两个版本中,实现alpha的更改和代数运算的优化环节一模一样。在优化过
程中,唯一的不同就是选择alpha的方式。完整版的Platt SMO算法应用了一些能够提速的启发方
法。
完整版Platt SMO的支持函数
class optStruct:
def __init__(self,dataMatIn, classLabels, C, toler, kTup): # Initialize the structure with the parameters
self.X = dataMatIn
self.labelMat = classLabels
self.C = C
self.tol = toler
self.m = shape(dataMatIn)[0]
self.alphas = mat(zeros((self.m,1)))
self.b = 0
self.eCache = mat(zeros((self.m,2))) #first column is valid flag
self.K = mat(zeros((self.m,self.m)))
for i in range(self.m):
self.K[:,i] = kernelTrans(self.X, self.X[i,:], kTup)
def calcEkK(oS, k):
fXk = float(multiply(oS.alphas,oS.labelMat).T*(oS.X*oS.X[k,:].T)) + oS.b
Ek = fXk - float(oS.labelMat[k])
return Ek
def selectJ(i, oS, Ei): #this is the second choice -heurstic, and calcs Ej
maxK = -1; maxDeltaE = 0; Ej = 0
oS.eCache[i] = [1,Ei] #set valid #choose the alpha that gives the maximum delta E
validEcacheList = nonzero(oS.eCache[:,0].A)[0]
if (len(validEcacheList)) > 1:
for k in validEcacheList: #loop through valid Ecache values and find the one that maximizes delta E
if k == i: continue #don't calc for i, waste of time
Ek = calcEk(oS, k)
deltaE = abs(Ei - Ek)
if (deltaE > maxDeltaE):
maxK = k; maxDeltaE = deltaE; Ej = Ek
return maxK, Ej
else: #in this case (first time around) we don't have any valid eCache values
j = selectJrand(i, oS.m)
Ej = calcEk(oS, j)
return j, Ej
def updateEk(oS, k):#after any alpha has changed update the new value in the cache
Ek = calcEk(oS, k)
oS.eCache[k] = [1,Ek]完整Platt SM0算法中的优化例程
def innerLK(i, oS):
Ei = calcEk(oS, i)
if ((oS.labelMat[i]*Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or ((oS.labelMat[i]*Ei > oS.tol) and (oS.alphas[i] > 0)):
j,Ej = selectJ(i, oS, Ei) #this has been changed from selectJrand
alphaIold = oS.alphas[i].copy(); alphaJold = oS.alphas[j].copy();
if (oS.labelMat[i] != oS.labelMat[j]):
L = max(0, oS.alphas[j] - oS.alphas[i])
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
else:
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
if L==H: print "L==H"; return 0
eta = 2.0 * oS.X[i,:]*oS.X[j,:].T - oS.X[i,:]*oS.X[i,:].T - oS.X[j,:]*oS.X[j,:].T
if eta >= 0: print "eta>=0"; return 0
oS.alphas[j] -= oS.labelMat[j]*(Ei - Ej)/eta
oS.alphas[j] = clipAlpha(oS.alphas[j],H,L)
updateEk(oS, j) #added this for the Ecache
if (abs(oS.alphas[j] - alphaJold) < 0.00001): print "j not moving enough"; return 0
oS.alphas[i] += oS.labelMat[j]*oS.labelMat[i]*(alphaJold - oS.alphas[j])#update i by the same amount as j
updateEk(oS, i) #added this for the Ecache #the update is in the oppostie direction
b1 = oS.b - Ei- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.X[i,:]*oS.X[i,:].T - oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.X[i,:]*oS.X[j,:].T
b2 = oS.b - Ej- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.X[i,:]*oS.X[j,:].T - oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.X[j,:]*oS.X[j,:].T
if (0 < oS.alphas[i]) and (oS.C > oS.alphas[i]): oS.b = b1
elif (0 < oS.alphas[j]) and (oS.C > oS.alphas[j]): oS.b = b2
else: oS.b = (b1 + b2)/2.0
return 1
else: return 0完整版Platt SMO的外循环代码
def smoP(dataMatIn, classLabels, C, toler, maxIter,kTup=('lin', 0)): #full Platt SMO
oS = optStruct(mat(dataMatIn),mat(classLabels).transpose(),C,toler, kTup)
iter = 0
entireSet = True; alphaPairsChanged = 0
while (iter < maxIter) and ((alphaPairsChanged > 0) or (entireSet)):
alphaPairsChanged = 0
if entireSet: #go over all
for i in range(oS.m):
alphaPairsChanged += innerL(i,oS)
print "fullSet, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged)
iter += 1
else:#go over non-bound (railed) alphas
nonBoundIs = nonzero((oS.alphas.A > 0) * (oS.alphas.A < C))[0]
for i in nonBoundIs:
alphaPairsChanged += innerL(i,oS)
print "non-bound, iter: %d i:%d, pairs changed %d" % (iter,i,alphaPairsChanged)
iter += 1
if entireSet: entireSet = False #toggle entire set loop
elif (alphaPairsChanged == 0): entireSet = True
print "iteration number: %d" % iter
return oS.b,oS.alphas5、在复杂数据上应用核函数
核函数的目的主要是为了解决非线性分类问题,通过核技巧将低维的非线性特征转化为高维的线性特征,从而可以通过线性模型来解决非线性的分类问题。
数据点处于一个圆中,人类的大脑能够意识到这一点。然而,对于分类器而言,它只能识别分类器的结果是大于0还是小于0。如果只在x和y轴构成的坐标系中插入直线进行分类的话,我们并不会得到理想的结果。但是或许可以对圆中的数据进行某种形式的转换,从而得到某些新的变量来表示数据。在这种表示情况下,我们就更容易得到大于0或者小于0的测试结果。
这种从某个特征空间到另一个特征空间的映射是通过核函数来实现的。它能把数据从某个很难处理的形式转换成为另一个较容易处理的形式。如果上述特征空间映射的说法听起来很让人迷糊的话,那么可以将它想象成为另外一种距离计算的方法。距离计算的方法有很多种,核函数一样具有多种类型。经过空间转换之后,我们可以在高维空间中解决线性问题,这也就等价于在低维空间中解决非线性问题。
核转换函数
def kernelTrans(X, A, kTup): #calc the kernel or transform data to a higher dimensional space
m,n = shape(X)
K = mat(zeros((m,1)))
if kTup[0]=='lin': K = X * A.T #linear kernel
elif kTup[0]=='rbf':
for j in range(m):
deltaRow = X[j,:] - A
K[j] = deltaRow*deltaRow.T
K = exp(K/(-1*kTup[1]**2)) #divide in NumPy is element-wise not matrix like Matlab
else: raise NameError('Houston We Have a Problem -- \
That Kernel is not recognized')
return K
class optStruct:
def __init__(self,dataMatIn, classLabels, C, toler, kTup): # Initialize the structure with the parameters
self.X = dataMatIn
self.labelMat = classLabels
self.C = C
self.tol = toler
self.m = shape(dataMatIn)[0]
self.alphas = mat(zeros((self.m,1)))
self.b = 0
self.eCache = mat(zeros((self.m,2))) #first column is valid flag
self.K = mat(zeros((self.m,self.m)))
for i in range(self.m):
self.K[:,i] = kernelTrans(self.X, self.X[i,:], kTup)核函数适用的innerL函数()和calcEK()函数
def innerL(i, oS):
Ei = calcEk(oS, i)
if ((oS.labelMat[i]*Ei < -oS.tol) and (oS.alphas[i] < oS.C)) or ((oS.labelMat[i]*Ei > oS.tol) and (oS.alphas[i] > 0)):
j,Ej = selectJ(i, oS, Ei) #this has been changed from selectJrand
alphaIold = oS.alphas[i].copy(); alphaJold = oS.alphas[j].copy();
if (oS.labelMat[i] != oS.labelMat[j]):
L = max(0, oS.alphas[j] - oS.alphas[i])
H = min(oS.C, oS.C + oS.alphas[j] - oS.alphas[i])
else:
L = max(0, oS.alphas[j] + oS.alphas[i] - oS.C)
H = min(oS.C, oS.alphas[j] + oS.alphas[i])
if L==H: print "L==H"; return 0
eta = 2.0 * oS.K[i,j] - oS.K[i,i] - oS.K[j,j] #changed for kernel
if eta >= 0: print "eta>=0"; return 0
oS.alphas[j] -= oS.labelMat[j]*(Ei - Ej)/eta
oS.alphas[j] = clipAlpha(oS.alphas[j],H,L)
updateEk(oS, j) #added this for the Ecache
if (abs(oS.alphas[j] - alphaJold) < 0.00001): print "j not moving enough"; return 0
oS.alphas[i] += oS.labelMat[j]*oS.labelMat[i]*(alphaJold - oS.alphas[j])#update i by the same amount as j
updateEk(oS, i) #added this for the Ecache #the update is in the oppostie direction
b1 = oS.b - Ei- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.K[i,i] - oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.K[i,j]
b2 = oS.b - Ej- oS.labelMat[i]*(oS.alphas[i]-alphaIold)*oS.K[i,j]- oS.labelMat[j]*(oS.alphas[j]-alphaJold)*oS.K[j,j]
if (0 < oS.alphas[i]) and (oS.C > oS.alphas[i]): oS.b = b1
elif (0 < oS.alphas[j]) and (oS.C > oS.alphas[j]): oS.b = b2
else: oS.b = (b1 + b2)/2.0
return 1
else: return 0
def calcEk(oS, k):
fXk = float(multiply(oS.alphas,oS.labelMat).T*oS.K[:,k] + oS.b)
Ek = fXk - float(oS.labelMat[k])
return Ek在测试中使用核函数
def testRbf(k1=1.3):
dataArr,labelArr = loadDataSet('testSetRBF.txt')
b,alphas = smoP(dataArr, labelArr, 200, 0.0001, 10000, ('rbf', k1)) #C=200 important
datMat=mat(dataArr); labelMat = mat(labelArr).transpose()
svInd=nonzero(alphas.A>0)[0]
sVs=datMat[svInd] #get matrix of only support vectors
labelSV = labelMat[svInd];
print "there are %d Support Vectors" % shape(sVs)[0]
m,n = shape(datMat)
errorCount = 0
for i in range(m):
kernelEval = kernelTrans(sVs,datMat[i,:],('rbf', k1))
predict=kernelEval.T * multiply(labelSV,alphas[svInd]) + b
if sign(predict)!=sign(labelArr[i]): errorCount += 1
print "the training error rate is: %f" % (float(errorCount)/m)
dataArr,labelArr = loadDataSet('testSetRBF2.txt')
errorCount = 0
datMat=mat(dataArr); labelMat = mat(labelArr).transpose()
m,n = shape(datMat)
for i in range(m):
kernelEval = kernelTrans(sVs,datMat[i,:],('rbf', k1))
predict=kernelEval.T * multiply(labelSV,alphas[svInd]) + b
if sign(predict)!=sign(labelArr[i]): errorCount += 1
print "the test error rate is: %f" % (float(errorCount)/m) 6、示例:手写识别问题回顾
基于SVM的手写数字识别
def loadImages(dirName):
from os import listdir
hwLabels = []
trainingFileList = listdir(dirName) #load the training set
m = len(trainingFileList)
trainingMat = zeros((m,1024))
for i in range(m):
fileNameStr = trainingFileList[i]
fileStr = fileNameStr.split('.')[0] #take off .txt
classNumStr = int(fileStr.split('_')[0])
if classNumStr == 9: hwLabels.append(-1)
else: hwLabels.append(1)
trainingMat[i,:] = img2vector('%s/%s' % (dirName, fileNameStr))
return trainingMat, hwLabels
def testDigits(kTup=('rbf', 10)):
dataArr,labelArr = loadImages('trainingDigits')
b,alphas = smoP(dataArr, labelArr, 200, 0.0001, 10000, kTup)
datMat=mat(dataArr); labelMat = mat(labelArr).transpose()
svInd=nonzero(alphas.A>0)[0]
sVs=datMat[svInd]
labelSV = labelMat[svInd];
print "there are %d Support Vectors" % shape(sVs)[0]
m,n = shape(datMat)
errorCount = 0
for i in range(m):
kernelEval = kernelTrans(sVs,datMat[i,:],kTup)
predict=kernelEval.T * multiply(labelSV,alphas[svInd]) + b
if sign(predict)!=sign(labelArr[i]): errorCount += 1
print "the training error rate is: %f" % (float(errorCount)/m)
dataArr,labelArr = loadImages('testDigits')
errorCount = 0
datMat=mat(dataArr); labelMat = mat(labelArr).transpose()
m,n = shape(datMat)
for i in range(m):
kernelEval = kernelTrans(sVs,datMat[i,:],kTup)
predict=kernelEval.T * multiply(labelSV,alphas[svInd]) + b
if sign(predict)!=sign(labelArr[i]): errorCount += 1
print "the test error rate is: %f" % (float(errorCount)/m) 函数loadImages ()是作为前面kNN.py中的handwritingClassTest ()的一部分出现的。它已经被重构为自身的一个函数.其中仅有的一个大区别在,在kNN.:py中代码直接应用类别标签,而同支持向量机-起使用时,类别标签为- 1或者+1。因此一旦碰到数字9,则输出类别标签-1,否则输出+1。本质上,支持向量机是-个二类分类器,其分类结果不是+1就是-1。由于这里只做二类分类,因此除了1和9之外的数字都被去掉了。
下一个函数testDigits ()并不是全新的函数,它和testRbf ()的代码几乎一样,唯一的大区别就是它调用了loadImages ()函数来获得类别标签和数据。另一个细小的不同是现在这里的函数元组kTup是输人参数,而在testRbf()中默认的就是使用rbf核函数。如果对于函数testDigits()不增加任何输人参数的话,那么kTup的默认值就是(rbf ,10)。
输入命令 svmMLiA.testDigits(('rbf',120)),得到结果
![[机器学习实战] 支持向量机_第3张图片](http://img.e-com-net.com/image/info8/6b8e1a709b2842e298ef198f5512c4df.jpg)