【翻译】Transformers in Computer Vision
https://www.axelera.ai/vision-transformers-in-computer-vision/
https://www.edge-ai-vision.com/2022/05/transformers-in-computer-vision/
摘要
十多年来,卷积神经网络 (CNN) 在计算机视觉应用中一直占据主导地位。如今,它们的表现已经超越并被具有更高学习能力的 Vision Transformers (ViT) 取代。最快的 ViT 本质上是 CNN/Transformer 混合体,结合了两全其美:(A) 受 CNN 启发的分层和金字塔特征图,其中嵌入维度增加,空间维度减少,整个网络与局部感受野相结合以减少模型复杂性,而 (B) 受 Transformer 启发的 self-attention 增加了建模能力并导致更高的准确性。尽管 ViT 在特定情况下的表现优于 CNN,但它们的主导地位尚未得到证实。我们说明并得出结论,SotA CNN 在 ImageNet 验证中仍然与 ViT 相当或更好,特别是当 (1) 从头开始训练而没有蒸馏,(2) 在较低准确度 <80% 的情况下,以及 (3)针对边缘设备优化的降低网络复杂性。
Convolutional Neural Networks
近十年来,自从 AlexNet[1] 在 ImageNet[2] 图像分类挑战中取得突破性表现之后,卷积神经网络 (CNN) 一直是计算机视觉中占主导地位的神经网络架构。从这个基线架构开始,CNN 已经演变为具有残差连接的瓶颈架构的变体,例如 ResNet[3]、RegNet[4],或者使用分组卷积和倒置瓶颈为移动上下文优化的更轻量级的网络,例如 Mobilenet[5] 或高效网络[6]。通常,此类网络通过在 ImageNet 数据集上的小图像上进行训练来进行基准测试和比较。经过预训练后,它们可用于图像分类之外的应用,例如对象检测、全景视觉、语义分割或其他专门任务。这可以通过将它们用作端到端特定于应用程序的神经网络中的主干,并将生成的网络微调到适当的数据集和应用程序来完成。
图 1-1 和图 1-4 (a) 给出了一个典型的 ResNet 风格的 CNN。通常,此类网络具有以下几个特征:
- 他们交错或堆叠 1×1 和 k×k 卷积,以平衡卷积成本和构建大的感受野,
- 通过使用批量标准化和残差连接来稳定训练。
- 特征图是通过逐渐减小空间维度(W,H)来分层构建的,最终将它们缩小 32 倍。
- 通过将层的嵌入维度从第一层的 10 个通道增加到最后一层的 1000 个,特征图是金字塔形的

在这些更广泛的骨干网络家族中,研究人员开发了一组称为神经架构搜索 (Neural Architecture Search, NAS) [7] 的技术,以优化这些网络的精确参数化。Hardware-Aware NAS方法通过有效搜索其架构参数(例如层数、每层内的通道数、内核大小、激活函数等)来自动优化网络的延迟,同时最大限度地提高准确性。到目前为止,由于高昂的培训成本,这些方法未能为计算机视觉发明全新的架构。 他们主要在 ResNet/MobileNet 混合系列中生成网络,仅比他们手工设计的基线提高了 10-20% [8]。
Transformers in Computer Vision
用于计算机视觉的神经网络的一个更激进的演变是使用Vision Transformers (ViT)[9] 作为 CNN 主干的替代品。 受自然语言处理 (NLP) [10] 中 Transformer 模型惊人性能的启发,研究已转向在计算机视觉中应用相同的原理。 值得注意的例子包括 XCiT[11]、PiT[12]、DeiT[13] 和 SWIN-Transformers[14]。 在这里,类似于 NLP 处理,图像本质上被视为图像块序列(sequences of image patches),通过将特征图建模为标记向量,每个标记表示特定图像块的嵌入。
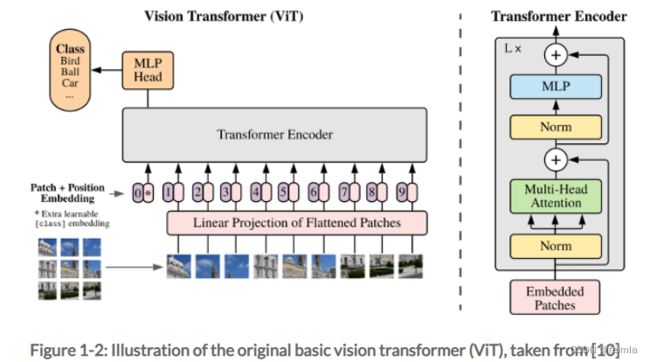
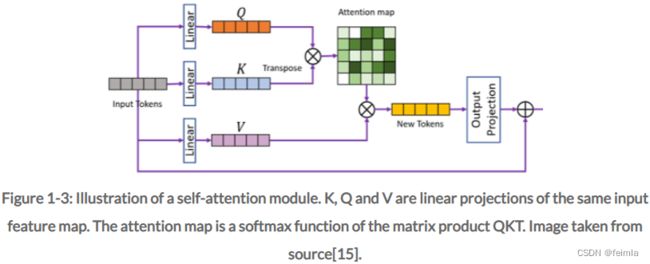
图 1-2 给出了基本 ViT 的说明。 ViT 是一系列堆叠的 MLP 和自注意力层,有或没有残差连接。这个 ViT 使用了为 NLP Transformer 开发的多头自注意力机制,见图 1-3。这种自注意力层有两个显着特征。它可以(1)通过根据上下文动态重新加权特定特征的重要性来动态地“引导”其注意力,并且(2)在使用全局自注意力的情况下具有完整的感受野。The latter is the case when self-attention is applied across all possible input tokens. 在这里,代表与特定空间图像块相关的嵌入的所有标记都相互关联,从而提供完整的透视场。全局自注意力在 ViT 中是典型的,但不是必需的。通过将自我注意模块的范围限制在一组较小的标记中,自我注意也可以实现本地化,从而减少特定阶段操作的感受野。
这种 ViT 架构与 CNN 形成鲜明对比。在没有注意机制的普通 CNN 中,(1) 使用预训练的权重对特征进行静态加权,而不是像 ViT 中那样根据上下文动态重新加权;(2) 各个网络层的感受野通常是局部的,并受卷积核大小的限制.
CNN 成功的部分原因在于它们在卷积方法中隐含的强大的架构归纳偏差。具有共享权重的卷积明确编码了特定相同模式在图像中的重复方式。这种归纳偏差确保了在相对较小的数据集上易于训练收敛,但也限制了CNN的建模能力。 Vision Transformers 不会强制执行如此严格的归纳偏差。这使他们更难训练,但也提高了他们的学习能力,见图 1-5。为了在计算机视觉中使用 ViT 获得良好的结果,这些网络通常trained using knowledge distillation with a large CNN-based teacher(例如在 DeiT[16] 中)。这样,CNN 的部分归纳偏差可以更柔和地强制进入训练过程。
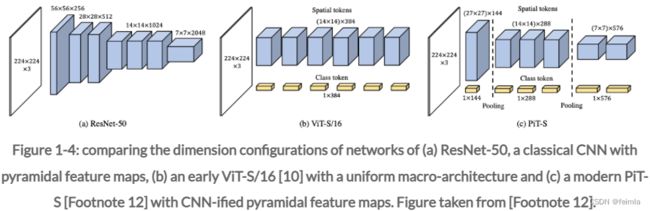
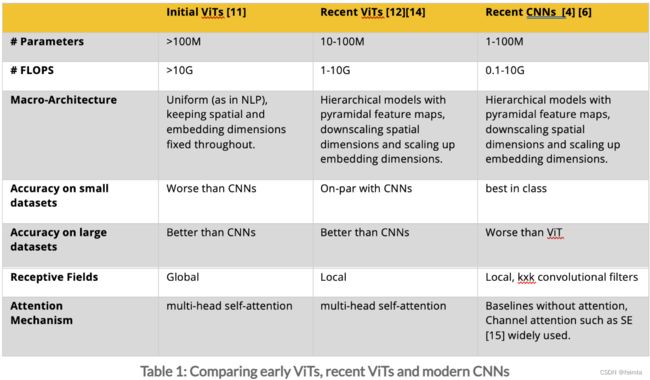
最初,ViT 直接受到 NLP Transformers 的启发:具有统一拓扑和全局自注意力的大规模模型,见图 1-4 (b)。最近的 ViT 具有更接近 CNN 的宏架构(图 1-4 (a)),使用分层金字塔特征图(如 PiT(Footnote 12);见图 1-4 ©)和局部自我-attention(如 Swin-Transformers(Footnote 14)。表 1 中讨论了这种演变的高级概述。)
Comparing CNNs and ViTs for Edge Computing
尽管 ViT 在许多计算机视觉任务中显示出 State-of-the-Art (SotA) 性能,但它们并不一定全面优于 CNN。图 1-5 和图 1-6 对此进行了说明。这些数字比较了 ViT 和 CNN 在 ImageNet 验证精度与模型大小和复杂性方面的性能,用于各种训练方案。区分这些训练方案很重要,因为并非所有训练方法都适用于特定的下游任务。首先,对于某些应用程序,只有相对较小的数据集可用。在这种情况下,CNN 通常表现更好。其次,许多 ViT 依靠蒸馏方法来实现高性能。为此,他们需要一个高度准确的预训练 CNN 作为教师,但这并不总是可用的。
图 1-5 (a) 说明了如果允许所有类型的训练,包括蒸馏方法和使用额外数据(例如 JFT-300[17]),CNN 和 ViT 在模型大小与准确性方面的比较。在这里,ViT 的性能与大型 CNN 相当或更好,在特定范围内优于它们。值得注意的是,XCiT(脚注 11)模型在 +/- 3M-Parameters范围内表现特别出色。然而,当既不允许蒸馏也不允许对额外数据进行训练时,差异就不那么明显了,见图 1-5 (b)。在这两个图中,EfficientNet-B0 和 ResNet-50 都表示为references for context。
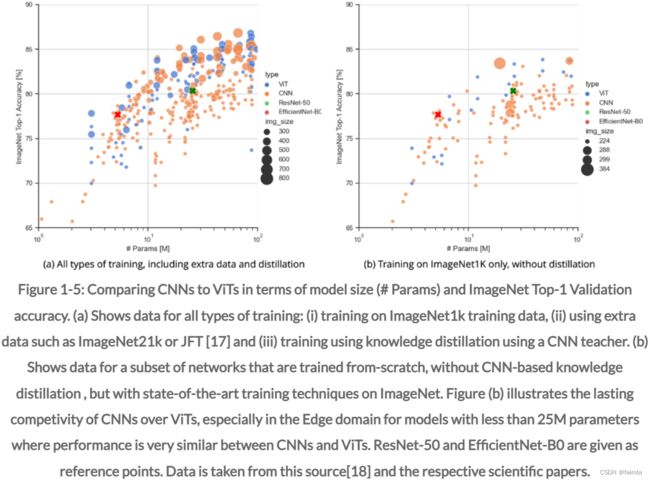
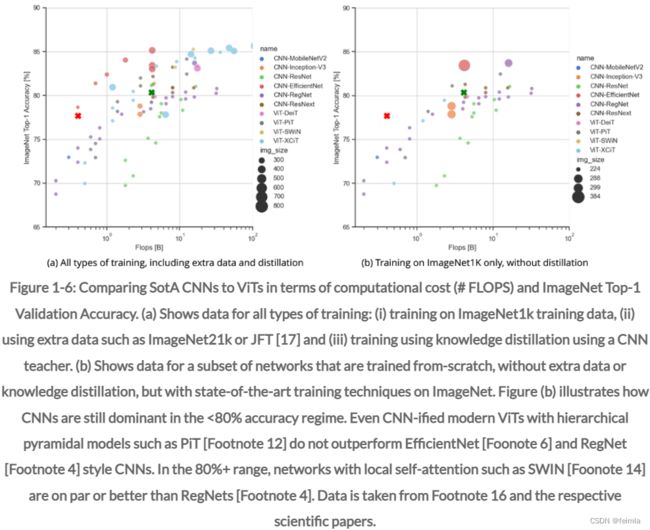
图 1-6 说明了一组更有限的已知网络的准确性与模型复杂性的相同情况。 图 1-6(a) 和 (b) 显示,对于所有类型的训练,CNN 主要用于较低的准确度和较低复杂度 (<1B FLOPS) 的网络。 这甚至适用于 CNN 化的Vision-Transformers,例如 PiT(脚注 12),它使用带有金字塔特征图的分层架构,以及通过使用局部自注意力来优化复杂性的 SWIN transformers。 如果没有额外的数据或蒸馏,CNN 的性能通常会全面优于 ViT,尤其是对于复杂度较低的网络或准确度低于 80% 的网络。 例如,在相似的复杂度下,RegNet 和 EfficientNet 风格的网络都显着优于 XCiT ViT,见图 1-6 (b)。
除了表 1 中的high-level differences和本节中的performance differences之外,将 ViT 引入边缘设备还有一些其他key different requirements。 与 CNN 相比,ViT 更多地依赖于 3 个 specific operations that must be properly accelerated on-chip。 首先,ViT 依赖于加速的 softmax 算子作为自我注意的一部分,而 CNN 只需要 softmax 作为分类网络的最后一层。 最重要的是,ViT 通常使用平滑非线性激活函数,而 CNN 主要依赖于执行和加速成本更低的整流线性单元 (ReLU)。 最后,ViT 通常需要 LayerNorm,这是一种通过动态计算均值和标准差来稳定训练的层归一化形式。 然而,CNN 通常使用batch-normalization,它只能在训练期间进行计算,并且可以通过将操作折叠到相邻的卷积层中而在推理中基本上被忽略。
结论
Vision Transformers正迅速开始主导计算机视觉中的许多应用。 与 CNN 相比,它们在大型数据集上实现了更高的准确度,因为它们具有更高的建模能力和更低的归纳偏差以及它们的全局感受野。通过减少感受野和使用分层金字塔特征图,现代、改进和更小的 ViT(如 PiT 和 SWIN)本质上正在成为 CNN 化的。 然而,在模型复杂性或大小与准确性方面,CNN 仍然与 ImageNet 上的 SotA ViT 相当或更好,尤其是在没有知识蒸馏或额外数据的情况下进行训练以及针对较低准确度的情况下。
References
[1] Krizhevsky, Alex, Ilya Sutskever, and Geoffrey E. Hinton. “Imagenet classification with deep convolutional neural networks.” Advances in neural information processing systems25 (2012): 1097-1105.
[2][2] Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., & Fei-Fei, L. (2009). Imagenet: A large-scale hierarchical image database. In 2009 IEEE conference on computer vision and pattern recognition (pp. 248–255).
[3] He, Kaiming, et al. “Deep residual learning for image recognition.” Proceedings of the IEEE conference on computer vision and pattern recognition. 2016.
[4] Radosavovic, Ilija, et al. “Designing network design spaces.” Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2020.
[5] Howard, Andrew, et al. “Searching for mobilenetv3.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019.
[6] Tan, Mingxing, and Quoc Le. “Efficientnet: Rethinking model scaling for convolutional neural networks.” International Conference on Machine Learning. PMLR, 2019.
[7] He, Xin, Kaiyong Zhao, and Xiaowen Chu. “AutoML: A Survey of the State-of-the-Art.” Knowledge-Based Systems 212 (2021): 106622.
[8] Moons, Bert, et al. “Distilling optimal neural networks: Rapid search in diverse spaces.” Proceedings of the IEEE/CVF International Conference on Computer Vision. 2021
[9] Dosovitskiy, Alexey, et al. “An image is worth 16×16 words: Transformers for image recognition at scale.” arXiv preprint arXiv:2010.11929 (2020).
[10] Devlin, Jacob, et al. “Bert: Pre-training of deep bidirectional transformers for language understanding.” arXiv preprint arXiv:1810.04805 (2018).
[11] El-Nouby, Alaaeldin, et al. “XCiT: Cross-Covariance Image Transformers.” arXiv preprint arXiv:2106.09681 (2021).
[12] Heo, Byeongho, et al. “Rethinking spatial dimensions of vision transformers.” arXiv preprint arXiv:2103.16302 (2021).
[13] Touvron, Hugo, et al. “Training data-efficient image transformers & distillation through attention.” International Conference on Machine Learning. PMLR, 2021.
[14] Liu, Ze, et al. “Swin transformer: Hierarchical vision transformer using shifted windows.” arXiv preprint arXiv:2103.14030 (2021).
[15] Li, Yawei, et al. “Spatio-Temporal Gated Transformers for Efficient Video Processing.”, NeurIPS ML4AD Workshop, 2021
[16] Touvron, Hugo, et al. “Training data-efficient image transformers & distillation through attention.” International Conference on Machine Learning. PMLR, 2021.
[17] Sun, Chen, et al. “Revisiting unreasonable effectiveness of data in deep learning era.” Proceedings of the IEEE international conference on computer vision. 2017.
[18] Ross Wightman, “Pytorch Image Models”, https://github.com/rwightman/pytorch-image-models, seen on January 10, 2022