一位算法工程师从30+场秋招面试中总结出的超强面经——目标检测篇(含答案)
作者丨灯会
来源丨极市平台
编辑丨极市平台
本文为极市平台原创,转载须经授权并注明来源
作者灯会为21届中部985研究生,七月份将入职某互联网大厂cv算法工程师。在去年灰飞烟灭的算法求职季中,经过几十场不同公司以及不同部门的面试中积累出了CV总复习系列,此为目标检测篇。
Faster-Rcnn网络
1.faster RCNN原理介绍,要详细画出图
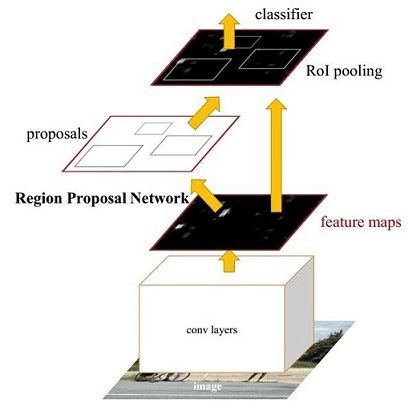
Faster R-CNN是一种两阶段(two-stage)方法,它提出的RPN网络取代了选择性搜索(Selective search)算法后使检测任务可以由神经网络端到端地完成。在结构上,Faster RCNN将特征抽取(feature extraction),候选区域提取(Region proposal提取),边框回归(bounding box regression),分类(classification)都整合在了一个网络中,使得综合性能有较大提高,在检测速度方面尤为明显。
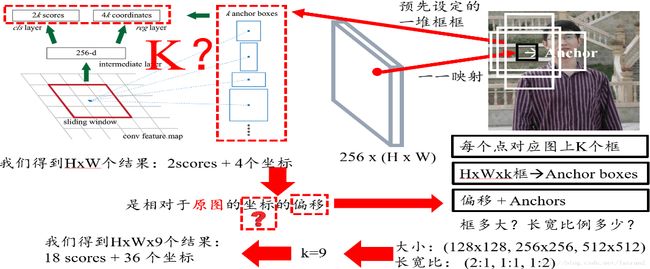
2.RPN(Region Proposal Network)网络的作用、实现细节
RPN网络的作用: RPN专门用来提取候选框,一方面RPN耗时少,另一方面RPN可以很容易结合到Fast RCNN中,成为一个整体。
RPN网络的实现细节:一个特征图(Faster RCNN的公共Feature Map)经过sliding window处理,得到256维特征,对每个特征向量做两次全连接操作,一个得到2个分数,一个得到4个坐标{然后通过两次全连接得到结果2k个分数和4k个坐标[k指的是由锚点产生的K个框(K anchor boxes)]}
2个分数,因为RPN是提候选框,还不用判断类别,所以只要求区分是不是物体就行,那么就有两个分数,前景(物体)的分数,和背景的分数; 4个坐标是指针对原图坐标的偏移,首先一定要记住是原图;
预先设定好共有9种组合,所以k等于9,最后我们的结果是针对这9种组合的,所以有H x W x 9个结果,也就是18个分数和36个坐标。
写一下RPN的损失函数(多任务损失:二分类损失+SmoothL1损失)
训练RPN网络时,对于每个锚点我们定义了一个二分类标签(是该物体或不是)。
以下两种情况我们视锚点为了一个正样本标签时:
1.锚点和锚点们与标注之间的最高重叠矩形区域
2.或者锚点和标注的重叠区域指标(IOU)>0.7
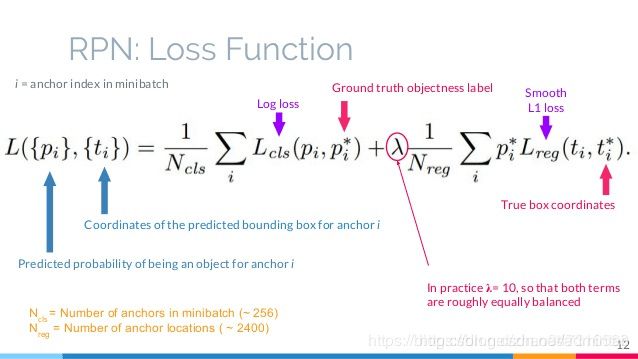
L ( p i , t i ) = 1 N c l s ∑ i L c l s ( p i , p i ∗ ) + λ 1 N r e g ∑ i p i ∗ L r e g ( t i , t i ∗ ) L\left(p_{i}, t_{i}\right)=\frac{1}{N_{c l s}} \sum_{i} L_{c l s}\left(p_{i}, p_{i}^{*}\right)+\lambda \frac{1}{N_{r e g}} \sum_{i} p_{i}^{*} L_{r e g}\left(t_{i}, t_{i}^{*}\right) L(pi,ti)=Ncls1i∑Lcls(pi,pi∗)+λNreg1i∑pi∗Lreg(ti,ti∗)
RPN损失中的回归损失部分输入变量是怎么计算的?(注意回归的不是坐标和宽高,而是由它们计算得到的偏移量)
smooth L 1 ( x ) = { 0.5 x 2 if ∣ x ∣ < 1 ∣ x ∣ − 0.5 otherwise \operatorname{smooth}_{L_{1}}(x)=\left\{\begin{array}{ll} 0.5 x^{2} & \text { if }|x|<1 \\ |x|-0.5 & \text { otherwise } \end{array}\right. smoothL1(x)={0.5x2∣x∣−0.5 if ∣x∣<1 otherwise
ti 和 ti* 分别为网络的预测值和回归的目标
t x = ( x − x a ) / w a , t y = ( y − y a ) / h a , t w = log ( w / w a ) , t h = log ( h / h a ) t x ∗ = ( x ∗ − x a ) / w a , t y ∗ = ( y ∗ − y a ) / h a , t w ∗ = log ( w ∗ / w a ) , t h ∗ = log ( h ∗ / h a ) , \begin{array}{r} t_{x}=\left(x-x_{a}\right) / w_{a}, \quad t_{y}=\left(y-y_{a}\right) / h_{a}, \quad t_{w}=\log \left(w / w_{a}\right), \quad t_{h}=\log \left(h / h_{a}\right) \\ t_{x}^{*}=\left(x^{*}-x_{a}\right) / w_{a}, \quad t_{y}^{*}=\left(y^{*}-y_{a}\right) / h_{a}, \quad t_{w}^{*}=\log \left(w^{*} / w_{a}\right), \quad t_{h}^{*}=\log \left(h^{*} / h_{a}\right), \end{array} tx=(x−xa)/wa,ty=(y−ya)/ha,tw=log(w/wa),th=log(h/ha)tx∗=(x∗−xa)/wa,ty∗=(y∗−ya)/ha,tw∗=log(w∗/wa),th∗=log(h∗/ha),
在训练RPN时需要准备好目标t*。它是通过ground-truth box(目标真实box)和anchor box(按一定规则生成的anchor box)计算得出的,代表的是ground-truth box与anchor box之间的转化关系。用这个来训练rpn,那么rpn最终学会输出一个良好的转化关系t。而这个t,是predicted box与anchor box之间的转化关系。通过这个t和anchor box,可以计算出预测框box的真实坐标。
RPN中的anchor box是怎么选取的?
滑窗的中心在原像素空间的映射点称为anchor,以此anchor为中心,生成k(paper中default k=9, 3 scales and 3 aspect ratios/不同尺寸和不同长宽比)个proposals。三个面积尺寸(1282,2562,512^2),然后在每个面积尺寸下,取三种不同的长宽比例(1:1,1:2,2:1)
为什么提出anchor box?
全文链接:CV 面试问题详解宝典–目标检测篇
推荐大家关注极市平台公众号,每天都会更新最新的计算机视觉论文解读、综述盘点、调参攻略、面试经验等干货~
