mindspore情感分析时RNN网络搭建出错
在参考https://gitee.com/mindspore/docs/blob/r1.1/tutorials/training/source_zh_cn/advanced_use/nlp_sentimentnet.md#%E4%BD%BF%E7%94%A8sentimentnet%E5%AE%9E%E7%8E%B0%E6%83%85%E6%84%9F%E5%88%86%E7%B1%BB进行情感分类实战训练时,想要把lstm网络改为rnn网络
【操作步骤&问题现象】
在查看mindsprore文档后发现nn.RNN和nn.LSTM的区别在于LSTM比RNN多一个参数c,把代码中的所有c删除后训练时出现函数参数个数不匹配的原因,但本人水平有限,没有找到具体哪里导致的这个原因。
【截图信息】
修改后代码如下:
# 定义需要单层LSTM小算子堆叠的设备类型。
STACK_LSTM_DEVICE = ["CPU"]
# 短期内存(h)和长期内存(c)初始化为0
# 定义lstm_default_state函数来初始化网络参数及网络状态。
def lstm_default_state(batch_size, hidden_size, num_layers, bidirectional):
"""初始化默认输入."""
num_directions = 2 if bidirectional else 1
h = Tensor(np.zeros((num_layers * num_directions, batch_size, hidden_size)).astype(np.float32))
#c = Tensor(np.zeros((num_layers * num_directions, batch_size, hidden_size)).astype(np.float32))
return h
def stack_lstm_default_state(batch_size, hidden_size, num_layers, bidirectional):
"""init default input."""
num_directions = 2 if bidirectional else 1
h_list = []
for _ in range(num_layers):
h_list.append(Tensor(np.zeros((num_directions, batch_size, hidden_size)).astype(np.float32)))
#c_list.append(Tensor(np.zeros((num_directions, batch_size, hidden_size)).astype(np.float32)))
h= tuple(h_list)
return h# 针对不同的场景,自定义单层LSTM小算子堆叠,来实现多层LSTM大算子功能。
class StackRNN(nn.Cell):
"""
Stack multi-layers LSTM together.
"""
def __init__(self,
input_size,
hidden_size,
num_layers=3,
has_bias=True,
batch_first=False,
dropout=0.0,
bidirectional=True):
super(StackRNN, self).__init__()
self.num_layers = num_layers
self.batch_first = batch_first
self.transpose = ops.Transpose()
# direction number
num_directions = 2 if bidirectional else 1
# input_size list
input_size_list = [input_size]
for i in range(num_layers - 1):
input_size_list.append(hidden_size * num_directions)
# layers
layers = []
for i in range(num_layers):
layers.append(nn.RNNCell(input_size=input_size_list[i],
hidden_size=hidden_size,
has_bias=has_bias,
))
# weights
weights = []
for i in range(num_layers):
# weight size
weight_size = (input_size_list[i] + hidden_size) * num_directions * hidden_size * 4
if has_bias:
bias_size = num_directions * hidden_size * 4
weight_size = weight_size + bias_size
# numpy weight
stdv = 1 / math.sqrt(hidden_size)
w_np = np.random.uniform(-stdv, stdv, (weight_size, 1, 1)).astype(np.float32)
# lstm weight
weights.append(Parameter(initializer(Tensor(w_np), w_np.shape), name="weight" + str(i)))
#
self.lstms = layers
self.weight = ParameterTuple(tuple(weights))
print(1)
def construct(self, x, hx):
"""construct"""
print(2)
if self.batch_first:
x = self.transpose(x, (1, 0, 2))
# stack lstm
h= hx
hn= None
for i in range(self.num_layers):
x, hn, _, _ = self.lstms[i](x, h[i], self.weight[i])
if self.batch_first:
x = self.transpose(x, (1, 0,2))
return x, (hn)其他部分未作修改
【日志信息】(可选,上传日志内容或者附件)
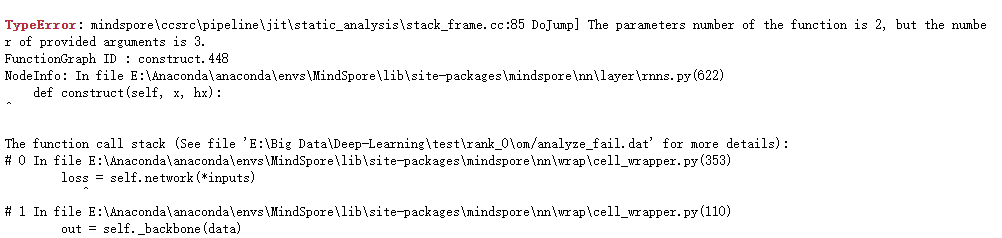
从报错信息来看是因为你的函数要求参数是两个但实际提供了三个,那么应该是你有地方删除c变量时没有删除干净,若是寻找比较难你可以开启pynative模式,https://www.mindspore.cn/tutorials/zh-CN/r1.7/advanced/pynative_graph/pynative.html?highlight=pynative, 参考该文档寻找哪一块没有配置好。