【浙江大学机器学习胡浩基】04 人工神经网络
目录
第一节 神经元的数学模型
MP模型
第二节 感知器算法
感知器算法
1.一个事实
2.感知器算法收敛定理
3.感知器算法收敛定理的证明
第三节 感知器算法的意义
1.感知器算法首先提出了一套机器学习算法的框架
2.训练数据的复杂度应该和预测函数的复杂度相匹配
3.感知器算法的优势
第四节 第一次寒冬
图像在计算机中的存储
1.灰度图
2.彩色图
3.二值图
4.连通图的分类问题
第五节 多层神经网络
1.多层神经网络结构(以两层为例)
2.阶跃函数
第六节 梯度下降算法
1.设计网络结构的两个准则
2. 梯度下降法
第七节 后向传播算法(上)
后向传播算法
第八节 后向传播算法(下)
现总结一般情况下的后向传播算法流程
第九节 后向传播算法的应用
1.对非线性函数的改进
对非线性函数的改进:使用SIGMOID函数。其在0处可求导,且导函数形式简洁
对非线性函数的改进:使用双曲正切函数
对目标函数的改进:使用基于SOFTMAX和交叉熵的目标函数
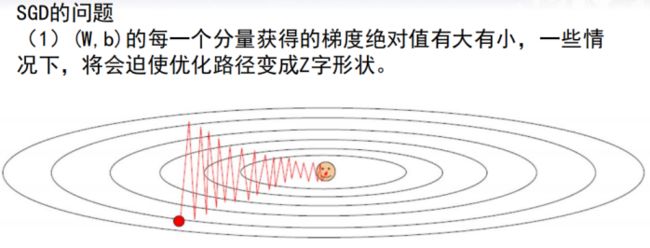
2.对梯度下降法的改进:随机梯度下降法(SGD)
第十节 兵王问题
第十一节 参数设置
1.激活函数
2.6个训练神经网络的建议
3.训练神经网络的各种经验
目标函数的选择
训练数据的归一化
ω和b的初始化
Batch Normalization
参数更新策略
-
第一节 神经元的数学模型

MP模型

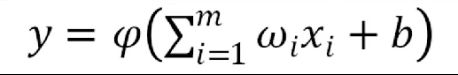
用向量形式表达
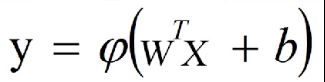
实际上,这是对某个复杂函数的一阶泰勒近似
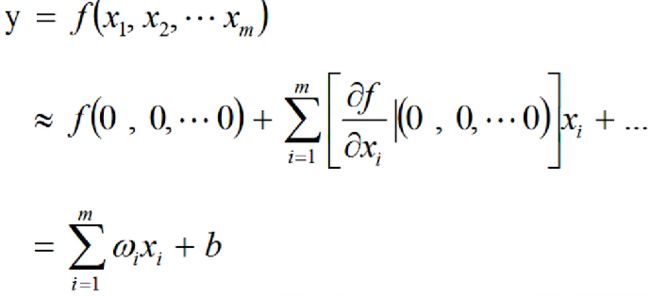
-
第二节 感知器算法
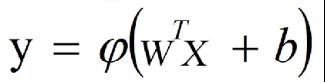
如何求出权重ω和偏置b?
假设输入为(Xi,yi),i=1~N
其中Xi为训练数据,yi为对应标签
我们需要找出合适的权重ω和偏置b,使得以下式子成立

若以上式子成立,则称此训练数据获得了平衡。否则,称未获得平衡
显然,此任务和支持向量机的任务是完全一致的。训练数据可以获得平衡等价于数据集线性可分。但是,感知器算法寻找ω和b的方法不同于支持向量机
感知器算法


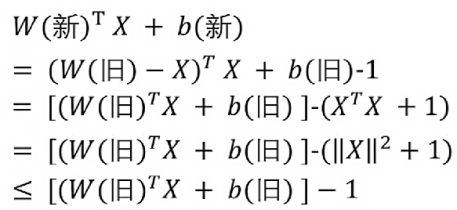
第二种情况同理
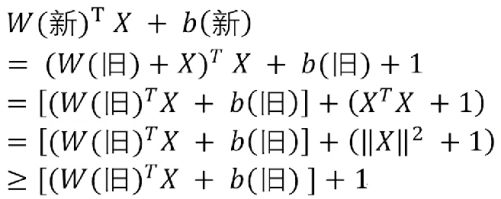
通过不断迭代,使得X越来越接近平衡状态
一个事实
只要训练数据线性可分,循环一定可以最终停止,并达到平衡状态
下面证明此事实
定义增广向量:对于某个Xi。定义其增广向量如下

原任务为

通过使用增广向量得到原任务的简化表达

下图是基于增广向量的感知器算法
基于增广向量的感知器算法和原算法是等价的
感知器算法收敛定理

(注:以上条件完全等价于训练数据集线性可分)
使用上述增广向量的感知器算法,一定可以
(注:此时找到的ω不一定是ωopt)
现证明感知器算法收敛定理
感知器算法收敛定理的证明
由于

所以
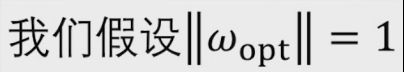
定义ω(k)为第k次改变后的权重向量值,存在以下两种情况
第一种
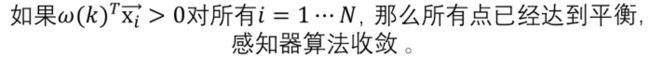
第二种
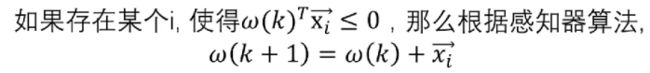
将等式两边同时减去aωopt
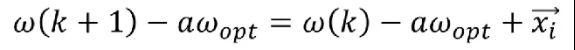
将等式两边取模并平方,右边展开得到
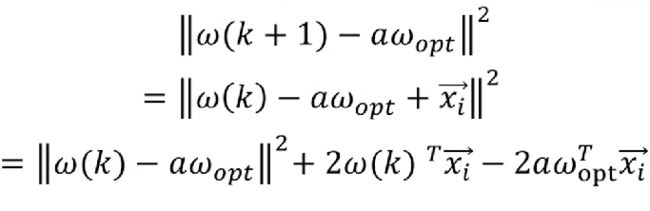
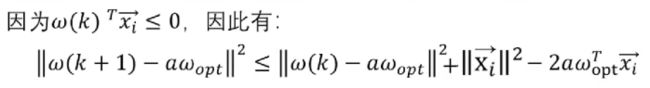 又由于
又由于
 于是,我们得到
于是,我们得到
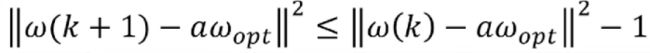
这意味着w每更新一次,它离aωopt的距离至少减少1个单位
假设W的初值为w(0)
记k等于

则最多经过k次迭代后
W的值收敛至aωopt。证明完毕。下面是完整证明过程


-
第三节 感知器算法的意义
感知器算法首先提出了一套机器学习算法的框架

其中
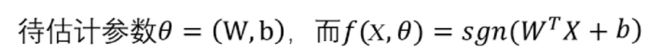
假设X的维度是m,则θ的维度是m+1
训练数据的复杂度应该和预测函数的复杂度相匹配
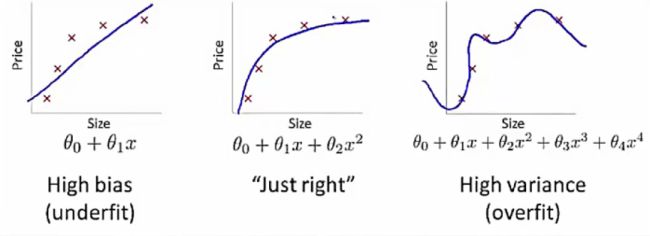
图一:模型欠拟合,指训练数据的复杂度比预测函数的复杂度更高的情况
图三:模型过拟合,指预测函数的复杂度比训练数据的复杂度更高的情况
感知器算法的优势
相比于支持向量机算法,感知器算法消耗的内存和计算资源非常少
-
第四节 第一次寒冬
-
图像在计算机中的存储
-
灰度图


此图像在计算机中为一个512*512的矩阵
像素值是0~255的整数,其中0代表纯黑色,255代表纯白色
彩色图

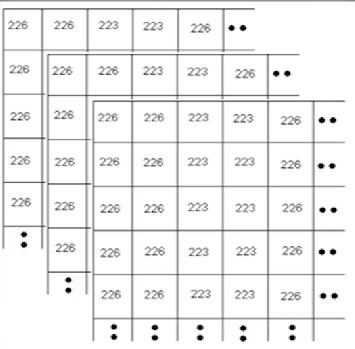
此图像在计算机中为三个512*512的矩阵
分别代表红色(R)、绿色(G)、蓝色(B)
二值图
每个像素要么是白色,要么是黑色
0代表白色 1代表黑色
假设原图的长为M宽为N
将图片的像素矩阵按列逐一排列
得到一个维度为MN的列向量X
y为标签
y=+1表示X是连通图
Y=-1表示X是非连通图
连通图的分类问题
下面证明识别连通图问题是非线性可分的
用反证法。假设这个问题是线性可分的,那么一定存在(W,b)使得

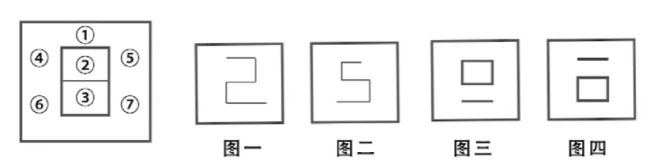
以上五张图中,最左侧的图片是对各边的编号情况
标注为图一图二的是连通图,图三图四是非连通图
由于图一是连通图,它所对应的y=+1
即(1)+(2)+(3)+(5)+(6)+b>0
其中(1)代表编号为①的边上的像素值分别乘以W相应分量然后再求和的结果,其他同理,得到以下四个式子
图一:(1)+(2)+(3)+(5)+(6)+b>0 ①
图二:(1)+(2)+(3)+(4)+(7)+b>0 ②
图三:(1)+(2)+(3)+(4)+(5)+b<0 ③
图四:(1)+(2)+(3)+(6)+(7)+b<0 ④
①+②得到
2*[(1)+(2)+(3)+b]+(4)+(5)+(6)+(7)>0
③+④得到
2*[(1)+(2)+(3)+b]+(4)+(5)+(6)+(7)<0
矛盾!因此连通图非线性可分
1969-1980年,人工神经网络的第一次寒冬
-
第五节 多层神经网络
-
多层神经网络结构(以两层为例)
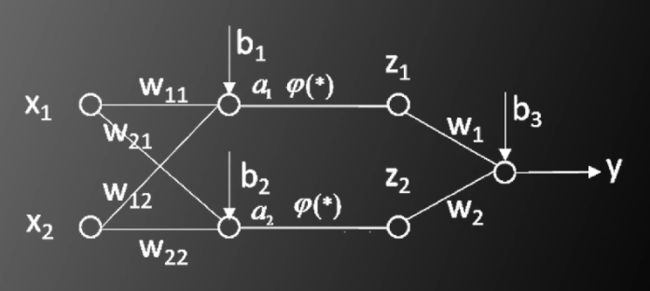
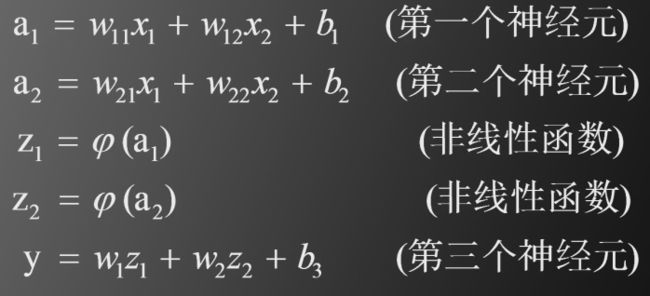
即
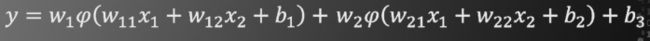
待求参数一共有9个

注意该结构中的非线性函数φ是必须的。如果没有非线性函数,将得到
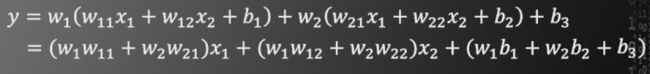
此时仍然是加权求和再加偏置的形式,与单个神经元模型没有本质区别。这也就意味着,多层神经网络的层与层之间如果不加非线性函数φ,将会退化为感知机模型。
那么,加入的非线性函数是什么呢?
阶跃函数
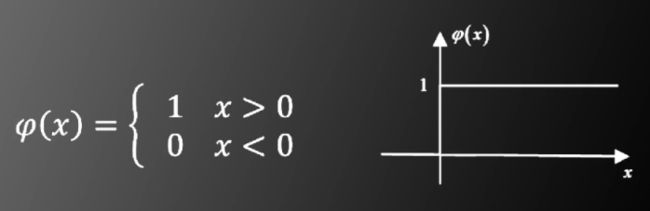
为什么要用阶跃函数作为多层神经网络层与层之间的非线性函数?
实际上,有以下定理:
如果非线性函数采用阶跃函数,那么三层神经网络可以模拟任意的非线性函数
下面证明此定理
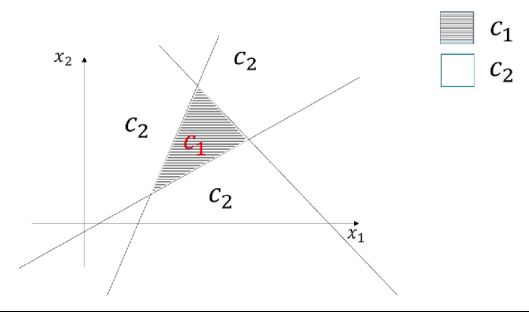
假设一个特征空间为二维的二分类问题,非线性函数将平面划分出一个三角区域
假设三条直线的方程如下图标注
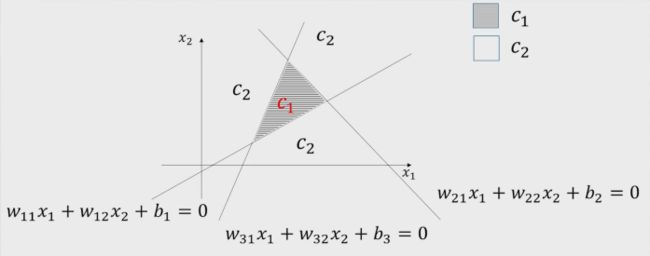
假定对三条直线的任意一条来说,对于平面上的任意一点,如果和C1区域在直线的同侧,则代入方程后的值大于0。这是一定可以做到的,因为w和b同取相反数,表示的直线是不变的。
现在构造一个两层的神经网络来实现在三角形得内输出大于,在三角形外输出小于0
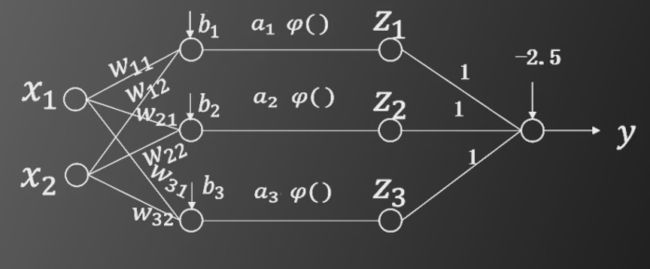
- 如果一点在三角形内部,即C1区域,则第一层的三个神经元输出的a1、a2、a3均大于0,经过阶跃函数后输出的z1、z2、z3均为1。如果一点在三角形外,即C2区域,则a1、a2、a3中至少有一个小于0,经过阶跃函数后输出的z1、z2、z3至少有一个等于0。因此,将第二层神经网络的所有权重设置为1,偏置设置为-2.5,即可满足某点在三角形得内输出大于,在三角形外输出小于0
- 同理,如果C1区域为平面四边形,只需在神经网络的第一层增加一个神经元,第二层的所有权重设置为1,偏置设置为-3.5即可
- 以此类推,对于C1区域为任意的多边形的情况,都可以使用二层神经网络来解决二分类问题
- 当C1区域为平面上的封闭曲线时,可以用多边形对其进行逼近,当边数不断增加,多边形可以以任意精度逼近
现考虑有三角形区域A和三角形区域B,即两个三角形区域的情形
在两个三角形区域中的任意一个时,有两种情况
C1=1,C2=0或者C1=0,C2=1
当不在两个三角形区域当中时
C1=C2=0
此时只需将第三层神经网络的所有权重设置为1,偏置设置为-0.5,即可满足要求
-
第六节 梯度下降算法
-
设计网络结构的两个准则
- 如果问题是简单的,神经网络的结构也可以简单一点。如果问题是复杂的,神经网络的结构也应更复杂。这里的复杂程度指的是神经网络的层数以及每层神经网络的个数
- 如果训练样本很多,可以适当增加神经网络的复杂度。如果训练样本很少,神经网络的复杂度不能设置的过高。
如何解神经网络中待求的参数?
下图是一个两层神经网络的简单例子

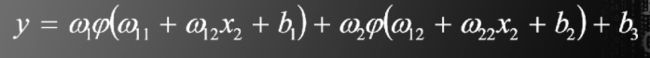
为了使y和标签Y尽可能接近,定义目标函数为
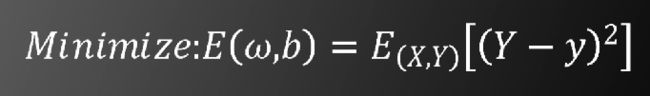
其中E(X,Y)表示遍历训练样本及标签的数学期望
由于y是非凸函数,因此无法像支持向量机算法一样求出唯一的全局最值。我们采用梯度下降法求局部极小值。
梯度下降法
步骤如下

先以一维情况为例。泰勒公式如下
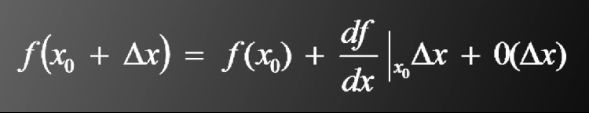
将如下式子带入泰勒公式
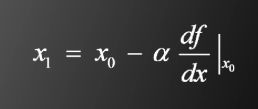
得到
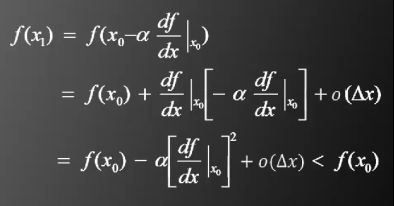
α被称为学习率,这是人工神经网络中最重要的超参数之一
当α设置过大时,得不到局部极值点
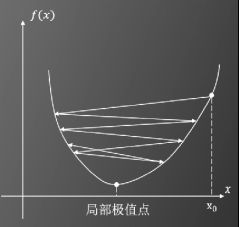
当α设置过小时,收敛速度过慢,而且可能会卡在小的“凹陷”之中
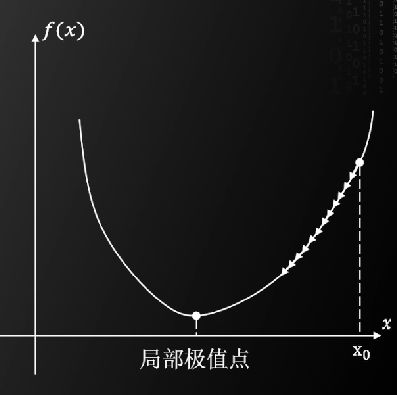
接下来说明二维情况。将二维函数E(ω,b)泰勒展开
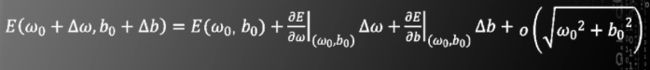
将以下式子带入泰勒公式
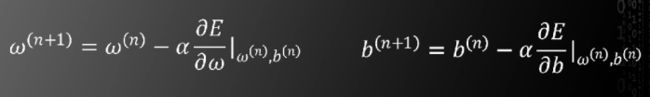 得到
得到
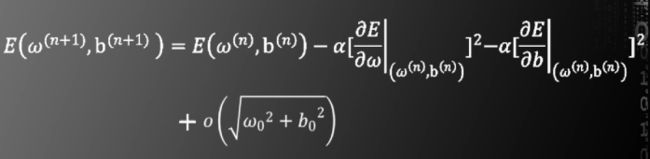 如果两个偏导数不全为零,则
如果两个偏导数不全为零,则
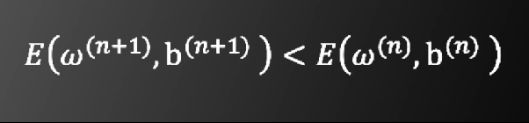
以上是一维和二维的情况。多维的情形同理。
-
第七节 后向传播算法(上)
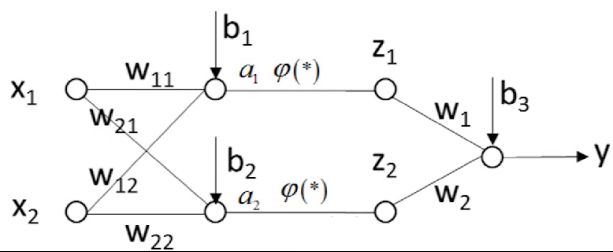
此二层神经网络模型中,待估计的参数有9个
目标函数如下
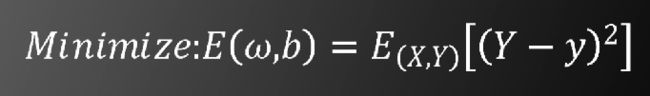
可以设置为

而
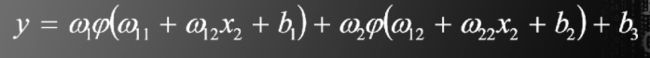
现在需要求出如下9个偏导数
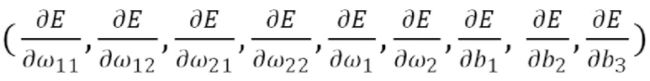
后向传播算法
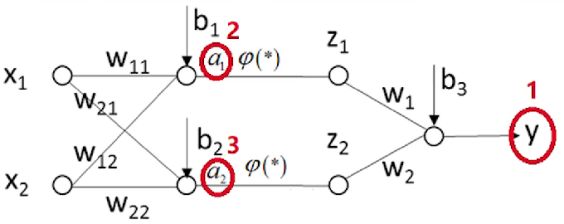

首先求出红色圈中的三个偏导数,即枢纽变量的偏导数
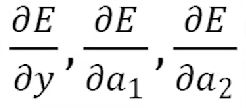
显然
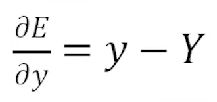
根据链式求导法则,得到
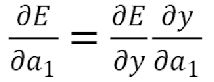
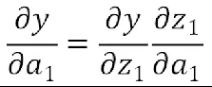
因此

而其中
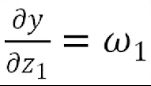
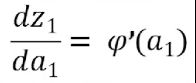
最终整理得到
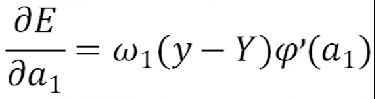
同理
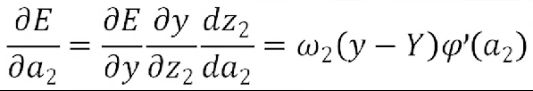
至此,枢纽变量的偏导数已经全部求出。分别为
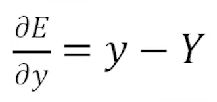
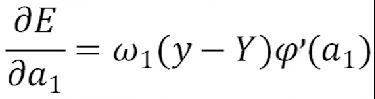
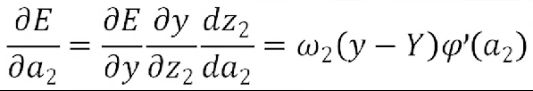
接下来根据上面的三个重要结果,求其它偏导数
由于y=ω1z1+ω2z2+b,则
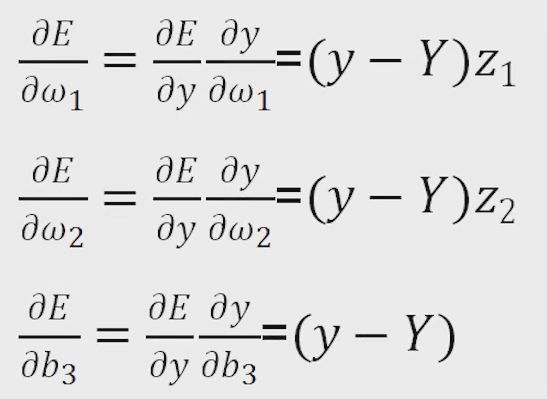
由于

得到
同理,由于
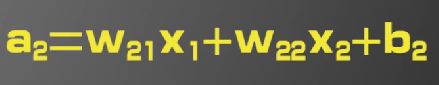
得到
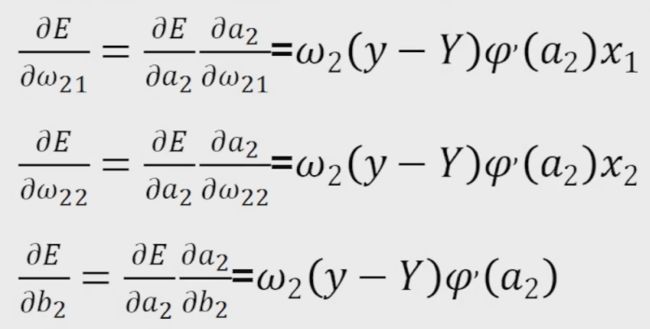
最终得到9个偏导数为
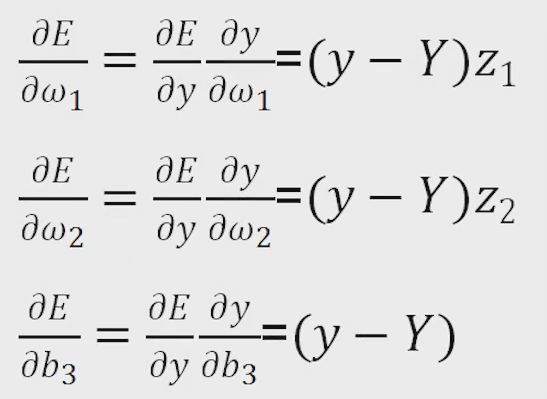
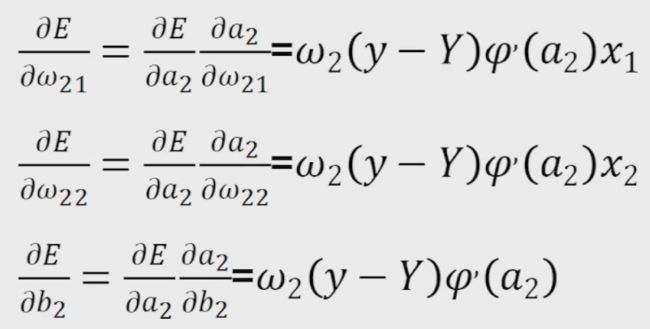
接下来总结人工神经网络后向传播算法的步骤(二层)



-
第八节 后向传播算法(下)
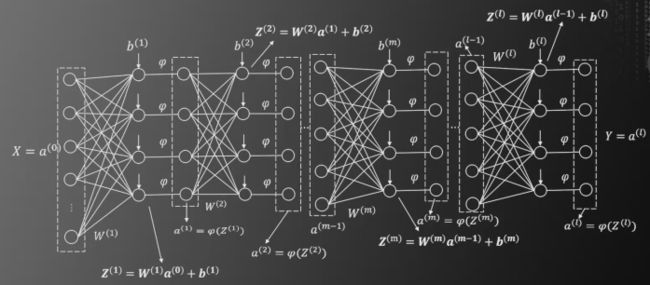
如上图的多层神经网络,结构很复杂。可以用矩阵形式来简化表示
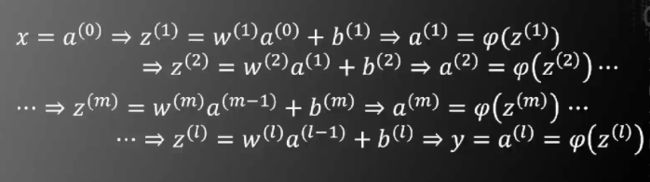


接下来我们要求E对各参数的偏导函数。类似于上一节的求导方式,我们先要求出E对于枢纽变量的偏导。
我们设置枢纽变量为
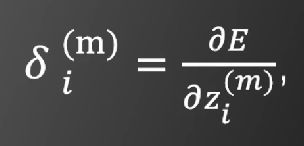
先计算最后一层,即l层
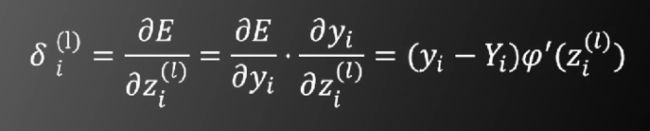
第m+1层的枢纽变量通过以下的方式求出第m层的枢纽变量

其中Sm+1表示第m+1层的神经元个数。计算化简得到第m层的枢纽变量等于如下式子
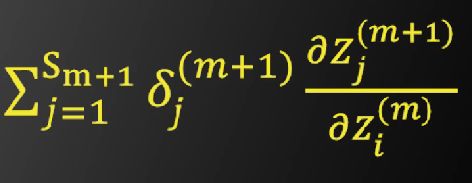
接下来求
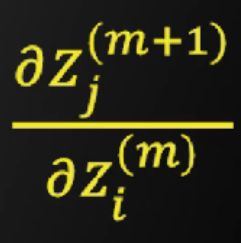
第m层和第m+1层的神经元关系图如下
根据图示,显然可以得到
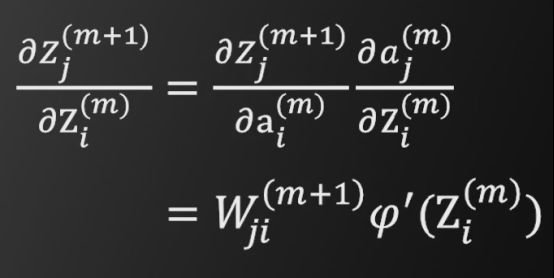
将以上结果带入之前的递推公式,最终可以得到
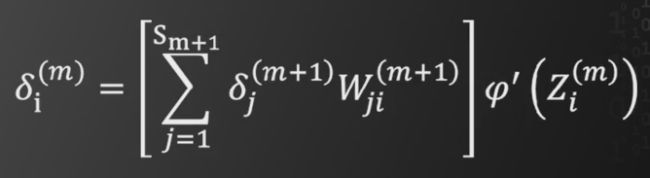
因此,可以由第l层的枢纽变量的偏导,递推至第m层的枢纽变量的偏导
易求出
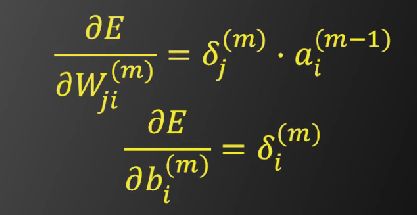
现总结一般情况下的后向传播算法流程



-
第九节 后向传播算法的应用
对非线性函数的改进
阶跃函数存在的问题:X=0处无法求导,但是在上一节中得到的递推公式中,需要对非线性函数进行求导
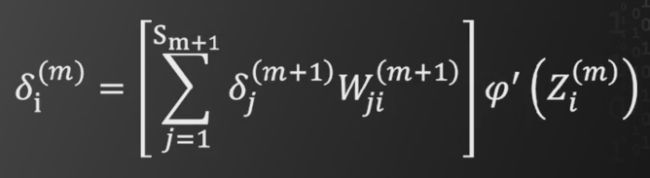
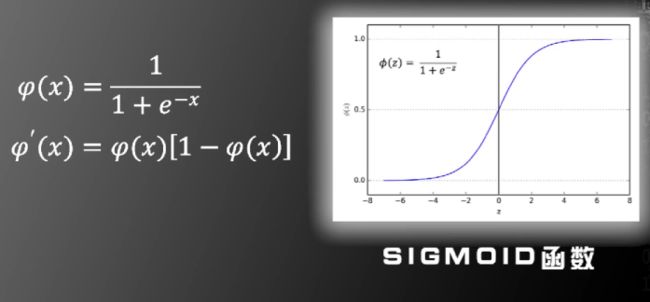
对非线性函数的改进:使用SIGMOID函数。其在0处可求导,且导函数形式简洁
对非线性函数的改进:使用双曲正切函数
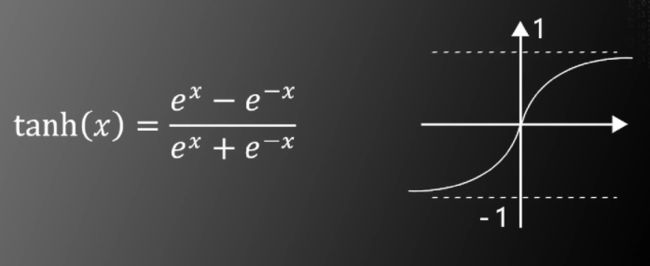 其导数的形式也很简洁,如下
其导数的形式也很简洁,如下
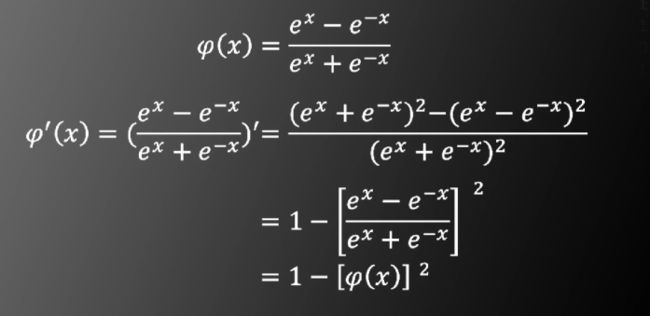
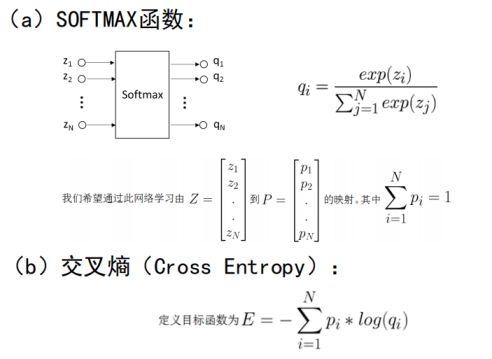
对目标函数的改进:使用基于SOFTMAX和交叉熵的目标函数
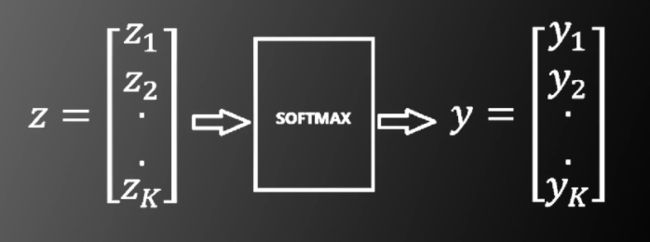
其中向量z为多层神经网络最后一层的输出
其中SOFTMAX的函数形式为
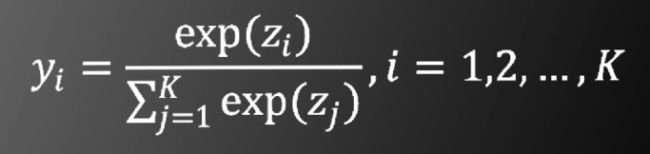
显然
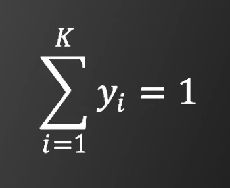
基于交叉熵的目标函数为
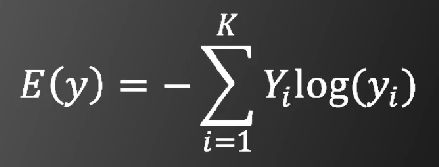
交叉熵反应的是两个概率分布Y与y的相似程度
有以下两个事实

利用此目标函数并使用后向传播算法时
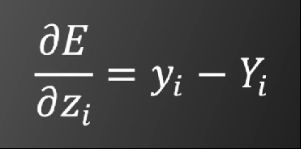
对梯度下降法的改进:随机梯度下降法(SGD)
一般梯度下降法存在的问题
- 如果对于每个训练样本都要更新一次参数,训练速度将会非常慢
- 如果某个训练数据存在较大误差,则此误差将会传导至每一个参数中去
随机梯度下降法的要点


按照BATCH遍历所有训练样本一次,我们称为一个EPOCH。在实际训练中,我们根据BATCH多次遍历所有训练样本,即训练不止一个EPOCH。对于每一个EPOCH,我们需要随机打乱所有的训练样本的次序,从而增加BATCH中训练样本的随机性
-
第十节 兵王问题
vec = zeros(6,1);
xapp = [];
yapp = [];
while ~feof(fid)
string = [];
c = fread(fid,1);
flag = flag+1;
while c~=13
string = [string, c];
c=fread(fid,1);
end;
fread(fid,1);
if length(string)>10
vec(1) = string(1) - 96;
vec(2) = string(3) - 48;
vec(3) = string(5) - 96;
vec(4) = string(7) - 48;
vec(5) = string(9) - 96;
vec(6) = string(11) - 48;
xapp = [xapp,vec];
if string(13) == 100
yapp = [yapp,[1,0]'];%独热向量
else
yapp = [yapp,[0,1]'];%独热向量
end;
end;
end;
fclose(fid);[N,M] = size(xapp);
p = randperm(M); %Shuffle the network
ratioTraining = 0.15; %训练数据集所占比例
ratioValidation = 0.05;%验证数据集所占比例
ratioTesting = 0.8;%测试数据集所占比例
xTraining = [];
yTraining = [];
for i=1:floor(ratioTraining*M)
xTraining = [xTraining,xapp(:,p(i))];
yTraining = [yTraining,yapp(:,p(i))];
end;
xTraining = xTraining';
yTraining = yTraining';[U,V] = size(xTraining);
avgX = mean(xTraining);
sigma = std(xTraining);
xTraining = (xTraining - repmat(avgX,U,1))./repmat(sigma,U,1);%归一化:减去均值,除以方差
xValidation = [];
yValidation = [];
for i=floor(ratioTraining*M)+1:floor((ratioTraining+ratioValidation)*M)
xValidation = [xValidation,xapp(:,p(i))];
yValidation = [yValidation,yapp(:,p(i))];
end;
xValidation= xValidation';
yValidation = yValidation';
[U,V] = size(xValidation);
xValidation = (xValidation - repmat(avgX,U,1))./repmat(sigma,U,1);%归一化:减去均值,除以方差
xTesting = [];
yTesting = [];
for i=floor((ratioTraining+ratioValidation)*M)+1:M
xTesting = [xTesting,xapp(:,p(i))];
yTesting = [yTesting,yapp(:,p(i))];
end;
xTesting = xTesting';
yTesting = yTesting';
[U,V] = size(xTesting);
xTesting = (xTesting - repmat(avgX,U,1))./repmat(sigma,U,1);%归一化:减去均值,除以方差%create a neural net
clear nn;
nn = nn_create([6,10,10,10,10,10,10,10,10,10,10,2],'active function','relu','learning rate',0.005, 'batch normalization',1,'optimization method','Adam', 'objective function', 'Cross Entropy');
%创建神经网络。其中[6,10,10,10,10,10,10,10,10,10,10,2]代表输入输出的维度和神经网络每一层的神经元个数。由于输入是6个维度,因此神经网络第一层的神经元个数为6。其中输入是6个维度,输出是两个维度
%relu为神经网络的激活函数
%学习率learning rate=0.005
%目标函数objective function为交叉熵%train
option.batch_size = 100;%每个mini-BATCH中有100个训练样本
option.iteration = 1;
iteration = 0;
maxAccuracy = 0;
totalAccuracy = [];
maxIteration = 10000;%最大的训练轮次为10000轮
while(iteration<=maxIteration)
iteration = iteration +1;
nn = nn_train(nn,option,xTraining,yTraining);
totalCost(iteration) = sum(nn.cost)/length(nn.cost);%平均损失
[wrongs,accuracy] = nn_test(nn,xValidation,yValidation);%验证集上测试识别率
totalAccuracy = [totalAccuracy,accuracy];
if accuracy>maxAccuracy
maxAccuracy = accuracy;
storedNN = nn;
end;
cost = totalCost(iteration);
accuracy
cost
end;
[wrongs,accuracy] = nn_test(storedNN,xTesting,yTesting);%在测试集上测试最后的训练效果
-
第十一节 参数设置
-
激活函数

6个训练神经网络的建议
1.一般情况下,在训练集上的目标函数的平均值会随着训练的深入而不断减小。如果这个指标有增大情况,停下来。
一般有两种情况
①采用的模型不够复杂,以至于不能在训练集上完全拟合
②已经训练得很好了
2.分出一些验证集,训练的本质目标是在验证机上获取最大的识别率
因此在训练一段时间后,必须在验证集上测试识别率,保存使得验证集上识别率最大的模型参数,作为最后的结果。
3.注意调整学习率,如果刚刚训练几步损失函数就增加,一般来说是学习率太高了。如果每次损失函数的值变化很小,说明学习率太低
4.Batch Normalization 比较好用,用了这个后,对学习率、参数更新策略等不敏感。建议如果用Batch Normalization, 更新策略用最简单的SGD即可,我的经验是加上其他反而不好。
5.如果不用Batch Normalization, 我的经验是,合理变换其他参数组合,也可以达到目的。
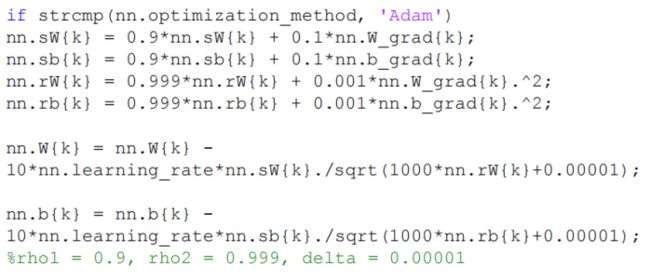
6.由于梯度累积效应,AdaGrad, RMSProp, Adam三种更新策略到了训练的后期会很慢,可以采用提高学习率的策略来补偿这一效应。
训练神经网络的各种经验
-
目标函数的选择
可以加入正则项

如果是分类问题,F(W)可以采用SOFTMAX函数和交叉熵的组合
-
训练数据的归一化
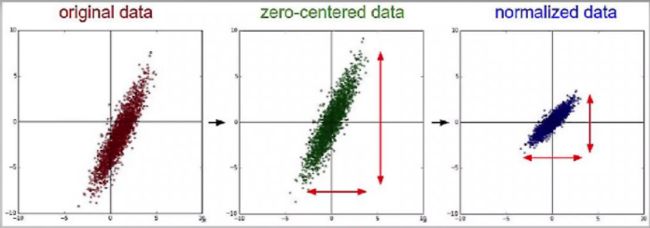
 保证数据的每个维度都落在相对固定的区间
保证数据的每个维度都落在相对固定的区间
-
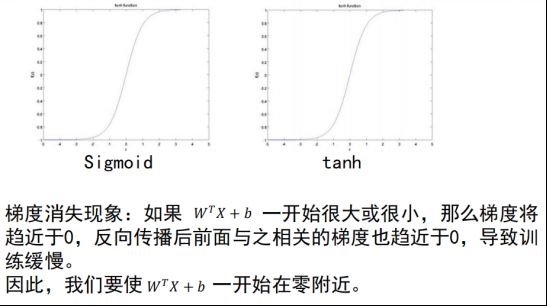
ω和b的初始化
-
Batch Normalization


-
参数更新策略