DeepFuse: A Deep Unsupervised Approach for Exposure Fusion with Extreme Exposure Image Pairs 阅读笔记
DeepFuse: A Deep Unsupervised Approach for Exposure Fusion with Extreme Exposure Image Pairs 阅读笔记
- 引言
- 介绍
-
- 主要贡献
- 提出的方法
-
- 总体架构
-
- 网络结构
- 损失函数
- 训练
- 测试
- 小细节
- 待续
- 参考
论文地址:https://arxiv.org/abs/1712.07384
如有侵权请联系我们
引言
文章中提出了一种基于深度学习架构,用于融合多曝光图像的算法
在神经网络的训练过程,一般都是监督学习,这样训练出的神经网络都有很不错的效果。但是由于没有足够的数据集供其使用,所以该篇论文提出了无监督的MEF(多曝光融合)深度学习框架。
介绍
首先引入HDRI的概念,这是一种存储图像的格式,相对于RGB格式来说,HDRI有更大的亮度范围,图像会更好,更清晰。
比较流行的生成HDR图像的方法被称为MEF(多次曝光融合),该方法就是将具有不同曝光的多个LDR图像(例如我们熟知的jpg,png等)融合为一个HDR图像。不同曝光的多个LDR文件也被称为曝光堆栈。
如果曝光堆栈中多个图像之间的曝光偏差最小时,大部分的MEF算法都可以取得不错的效果。但是这就带来了一个问题,曝光偏差小时,就意味着我们需要更大的存储容量以及更长的处理时间,论文中的方法是直接输入一个图像对,曝光偏差可以很大,该论文在这种情况下也可以工作的不错。
主要贡献
一种基于CNN的无监督图像融合算法,用于融合曝光叠加静态图像对。
一个新的基准数据集,可用于比较各种MEF方法
针对各种自然图像的7种最新算法的广泛实验评估和比较研究
提出的方法
总体架构
论文中使用的是使用CNN的图像融合框架。
为什么使用CNN?
因为CNN可以通过损失函数来自动更新网络中的参数,使得输出的结果不断地逼近预测值,运用在图像融合上也是一样,通过我们设定好的损失函数,CNN的输出图像结果就会逐渐趋近我们希望的结果。
主要流程
将输入曝光堆栈转换为YCbCr色通道数据。CNN用于融合输入图像的亮度通道。这是因为亮度通道中存在图像结构细节,亮度通道中的亮度变化比色度通道中的明显。
获得的亮度通道
网络结构
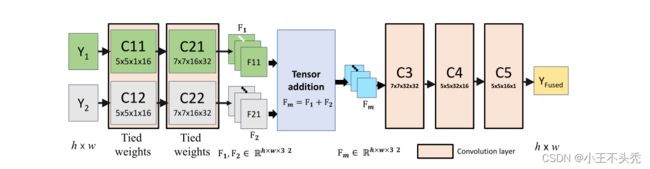
如上所示,特征提取层(C11,C21,C12和C22),融合层(Tensor addition)和重构层(C3,C4,C5)。
输入的Y1和Y2分别为曝光不足和曝光过度的图像。
C11和C12,C21和C22的参数是共享的,这有什么好处呢?
从另一角度来说C11,C21和C12,C22提取的特征是相同的,这就使得提取出的F11和F21可以通过融合层直接融合。这里融合的策略是直接相加。
损失函数
因为MEF没有预期的输出图像,因此像监督学习中使用的各种损失函数,在这里就不适用了,这里使用MEF SSIM作为损失函数,详情可参考以下论文。
K. Ma, K. Zeng, and Z. Wang. Perceptual quality assess-
ment for multi-exposure image fusion. IEEE Transactions
on Image Processing, 24(11):3345–3356, 2015.

如上图,yk代表表示在输入图像p像素位置周围提取的块,这里k属于(1,2),即代表一张高曝光和曝光不足的图像;uyk代表yk的平均值,Ck代表yk这里的对比度,Sk代表结构,Lk代表亮度
知道了以上公式之后我们再往下看
对比度越高,图像越好,因此这里c hat(就是c的预测值)就是两张图像中yk中的最大的c

结构的预测值公式如下
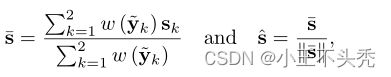
总体的y的预测如下
![]()
由于局部面片中的亮度比较不重要,因此从上述等式中删除亮度分量(文章中提到的,不是很理解)
以上都是为损失函数做铺垫,接下来才到了真正的损失函数
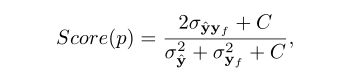
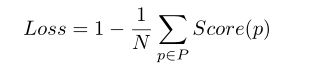
σ2y hat 是y hat的的方差,σy hat yf是是二者之间的协方差,N是图中像素总数
以上就是对论文中的损失函数的介绍了
训练
训练数据
25个公开的曝光堆栈+50个不同场景特征的曝光堆栈,每个场景由两个LDR图像组成。
在这些堆栈中剪裁了30000个大小为64*64的图像用于训练。
训练参数
学习率为10的-4次方,经过100次训练,每次训练所有的数据
测试
遵循标准的交叉验证程序来训练模型,并在不相交的测试集上测试最终模型。
图像的关键细节主要再Y通道上,因此Y通道和Cb/Cr所采用的融合策略是不同的
此外,MEF SSIM损失被公式化以计算2个灰度(Y)图像之间的得分
不知道大家有没有和我一样的疑惑,这里为什么是计算两个灰度图像之间的得分,来看下百度给结果
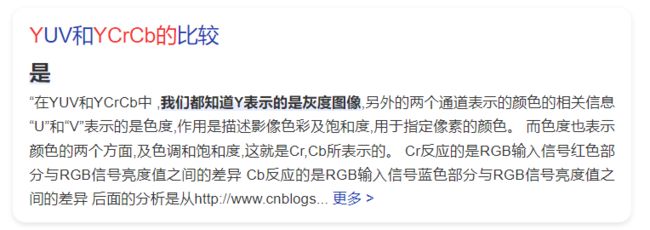
前文中我们已经提到了,论文中的方法主要是融合Y通道,这就很明朗了。
小细节
- 这里和之前阅读的一篇论文中一样,都需要对输入的图像进行配准和对齐,因为在采集过程中,不可避免的会出现摄像机和物体的移动。 另一篇论文
- 这里的相加策略中是单纯的相加,这时候我们想如果在两张图像中,一张图像中的特征是我们希望在融合时占的比重较大,另一张占的较小,这样实现起来也许融合图像的效果会更好,但是这就要我们计算融合时的权重了,而经过论文作者的测试,发现增加C3后的过滤器和层数也可以达到这个效果。(神经网络yyds)
待续
关于实验结果以及总结部分,这里就不赘述了,大家有兴趣可以看一下
文章读的比较糙,因为我的目的主要是想了解这个MEF SSIM损失函数,大家如果有兴趣的话建议好好读一下,非常好的论文
参考
[1] DeepFuse: A Deep Unsupervised Approach for Exposure Fusion with Extreme
Exposure Image Pairs