MaskFormer 在 MMDtection 中复现全流程解析
熟悉我们的小伙伴肯定知道 MMDetection 已经支持了全景分割算法 MaskFormer 啦!今天我们就以 MaskFormer 为例,和大家一起学习在 MMDetection 复现算法的全流程。我们十分欢迎社区的小伙伴和我们一起往 MMDetection 中添加新的算法,共同打造更加优异的目标检测框架。
目录
全景分割介绍
MaskFormer 介绍
准备工作
确定模型结构
设计并实现模型的基本结构
对齐 forward 结果
对齐 inference 精度
对齐 loss 部分
对齐其余部分
添加单元测试及文档
提交 PR
结语
在开始正式介绍前,我们先一起了解下全景分割和 MaskFormer。
https://github.com/open-mmlab/mmdetectiongithub.com/open-mmlab/mmdetection
全景分割介绍
图像中的像素点可以分成两大类:things 和 stuff。things 是图像中可数的物体,如人,车;stuff 是图像中不可数的像素区域,如路、天空。语义分割简单来说是对图像中每个像素分配一个语义标签,它将 things 也当作 stuff 来看待;实例分割是要将图像中每个实例都分割出来,允许实例之间有重叠。全景分割任务包括语义分割和实例分割,但引入了新的挑战。与语义分割不同,它需要区分单个对象实例;与实例分割不同,实例之间必须是不重叠的。全景分割任务就是对图像中每个像素点分配一个语义标签和一个实例编号。拥有相同 things 标签和实例编号的像素属于同一个物体,对于打上 stuff 标签的区域忽略其实例编号。
下图展示了语义分割、实例分割、全景分割三种任务之间的区别:

全景分割评价指标为 panoptic quality (PQ),计算公式如下所示。
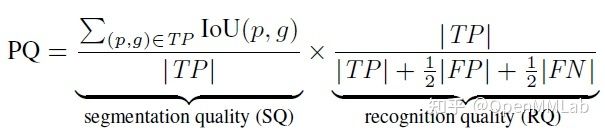
PQ 可是看成是segmentation quality (SQ) 和 recognition quality (RQ) 的乘积。RQ 与 F1 类似,而 SQ 是相匹配区域的 IOU 的平均值。
MaskFormer 介绍
现代的方法通常是将语义分割看作是逐像素点的分类任务,将实例分割看作是在目标检测的基础上加 mask 分类。MaskFormer 论文作者们认为:mask 分类是一个足够通用的方法,可以使用相同的模型、损失函数和训练流程来统一解决语义和实例级别的分割任务。
MaskFormer 是一个 mask 分类模型,它预测一组二进制 mask,每个 mask 与单个全局类别标签(包括 things 和 stuff)相关联。MaskFormer 简化了语义分割以及全景分割任务,并且性能也不错。
MaskFormer 论文链接: https://arxiv.org/abs/2107.06278
MaskFormer 详细解读: MaskFormer: 语义分割是像素分类问题吗? - 知乎
MMDetection 复现代码: https://github.com/open-mmlab/mmdetection/tree/master/configs/maskformer
接下来我们进入今天的正题,介绍一下如何在 MMDetection 中添加 MaskFormer 算法。
准备工作
首先,我们要按照 MaskFormer 的官方代码库中的指引,配置好环境,准备好 COCO 全景分割数据集。其次,使用 model zoo 中发布的模型在验证集上跑一遍,看看精度是否和论文上的一致。最后,准备一个小的验证集,用于快速检查复现后的模型与原版模型是否有差异(单卡跑一遍 COCO 验证集,时间还是比较久的,尤其是全景分割任务)。
确定模型结构
模型结构图可以让我们对模型结构有一个整体的认识,论文中一般都会有,但是模型结构图不一定能完全准确地反映模型的实际结构。
比如,下图中的 image features F 实际上不是直接输入到 transformer decoder,而是先经过 pixel decoder 中的一些卷积层再传入到 transformer decoder。
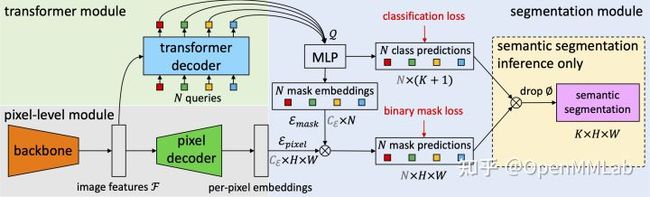
MaskFormer 模型结构图
此外,论文篇幅有限,不会对模型的具体结构参数做详细的说明。因此,在熟读论文并了解模型的整体结构之后,还需要阅读源码,对之前的认知做一个纠正,同时明确模型结构上的小细节。比如,卷积层的卷积大小、步长,后面有没有加 batch normalization 之类的。在完成论文和代码的阅读工作之后,我们可以在模型结构图上,标注出各个模块的具体细节。
设计并实现模型的基本结构
MMDetection 中的目标检测器通常可以分成三部分:backbone、neck(如果有)、head。backbone 部分通常比较明确并且固定,而 neck 和 head 部分有时并不好拆分。
MaskFormer 中 pixel decoder 部分是一个类似于 FPN 的结构,但是感觉不是很通用。因此,这个部分单独做成 plugin,而不是一个 neck。因而,整体上就是把 transformer decoder、pixel decoder 算在 MaskFormerHead 部分。然后考虑到 MaskFormer 和 Mask2Former 结构类似,也可以进行语义分割、实例分割和全景分割,所以就把三种分割后处理拿出来做成一个单独模块 MaskFormerFusionHead。
设计后的 MaskFormer 模块层级结构如下图所示:
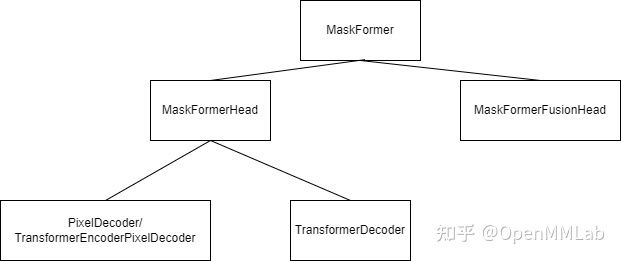
MaskFormer 模块层级结构图
主要模块的功能及代码链接分别如下:
- PixelDecoder:结构类似于 FPN,swin transformer 为 backbone 时用到。
- TransformerEncoderPixelDecoder:resnet 为 backbone 时用到,在 PixelDecoder 基础上多了一个包含 6 个 tansformer encoder block 的 TransformerEncoder。
- TransformerDecoder:包含 6 个 transformer decoder block 的 TransformerDecoder。
- MaskFormerHead:包含 PixelDecoder、TransformerDecoder。
- MaskFormerFusionHead:全景分割、实例分割、语义分割后处理。
- MaskFormer:detector。
对齐 forward 结果
在完成 MaskFormerHead 中的 forward 部分(模型训练和推断中的公共部分)之后,需要核对一下模型结构是不是和原版模型结构一致。具体分为三个步骤:
1.分别打印复现后的模型权重的名字,以及原版模型权重的名字,然后核对权重文件中的权重数量是不是一致,权重的名字是否能对应起来。下面代码展示了部分权重的名字,这里只贴了 resnet50 中的 stem 部分,以及 TransformerEncoderPixelDecoder 中的第一个 transformer block 中部分权重的名字。权重的名字不同,这个是因为模块内部各网络层实例取名不同以及各层之间的嵌套关系不同。
# MMDetection 中的 resnet50 中的 stem 权重的名字
backbone.conv1.weight
backbone.bn1.weight
backbone.bn1.bias
backbone.bn1.running_mean
backbone.bn1.running_var
# Detectron2 中的 resnet50 中的 stem 权重的名字
backbone.stem.conv1.weight
backbone.stem.conv1.norm.weight
backbone.stem.conv1.norm.bias
backbone.stem.conv1.norm.running_mean
backbone.stem.conv1.norm.running_var
# MMDetection 中的 TransformerEncoderPixelDecoder 中的第一个 transformer block 的部分权重的名字
panoptic_head.pixel_decoder.encoder.layers.1.attentions.0.attn.in_proj_weight
panoptic_head.pixel_decoder.encoder.layers.1.attentions.0.attn.in_proj_bias
panoptic_head.pixel_decoder.encoder.layers.1.attentions.0.attn.out_proj.weight
panoptic_head.pixel_decoder.encoder.layers.1.attentions.0.attn.out_proj.bias
# Detectron2 中的 TransformerEncoderPixelDecoder 中的第一个 transformer block 的部分权重的名字
sem_seg_head.pixel_decoder.transformer.encoder.layers.1.self_attn.in_proj_weight
sem_seg_head.pixel_decoder.transformer.encoder.layers.1.self_attn.in_proj_bias
sem_seg_head.pixel_decoder.transformer.encoder.layers.1.self_attn.out_proj.weight
sem_seg_head.pixel_decoder.transformer.encoder.layers.1.self_attn.out_proj.bias 2.将官方发布的模型权重的名字改为我们自己实现的模型权重的名字,并将修改之后的权重保存下来。可以总结一下两个模型权重的名字之间的对应关系,然后写一个脚本来实现转换(MMDetection 中有一个替换模型权重名字的脚本,可以参考)。
3.两个版本的模型各自加载相应权重,给定相同输入,检查输出结果是否一致,代码如下:
# 对齐 forward
import sys
sys.path.append("/data/open-mmlab/MaskFormer")
import torch
import pickle as pkl
from mmdet.models.builder import build_detector
from mmcv.utils.config import Config
from mask_former import add_mask_former_config
from detectron2.config import get_cfg
from detectron2.modeling import build_model
img = torch.rand((1, 3, 256, 256)).cuda()
img_metas = [{
"img_shape": (250, 250, 3),
"pad_shape": (256, 256, 3),
}]
#################################! MMDetection model
# 配置文件中只需要完成 model 部分的配置即可
mmdet_cfg_path = "./configs/maskformer/maskformer_r50_mstrain_16x1_75e_coco.py"
mmdet_cfg = Config.fromfile(mmdet_cfg_path)
# 构建模型并加载权重
checkpoint_path = "./checkpoints/maskformer/mmdet/maskformer_r50_converted_from_release_version.pth"
checkpoint = torch.load(checkpoint_path)["state_dict"]
mmdet_detector = build_detector(mmdet_cfg.model)
mmdet_detector.load_state_dict(checkpoint)
mmdet_detector = mmdet_detector.cuda()
mmdet_detector.eval()
with torch.no_grad():
mmdet_out = mmdet_detector.forward_dummy(img, img_metas)
#################################! Detectron2 model
# 加载配置文件
det2_cfg_path = "/data/open-mmlab/MaskFormer/configs/coco-panoptic/maskformer_r50.yaml"
det2_cfg = get_cfg()
add_mask_former_config(det2_cfg)
det2_cfg.merge_from_file(det2_cfg_path)
det2_cfg.freeze()
# 构建模型并加载权重
det2_checkpoint_path = "./checkpoints/maskformer/det2/model_final_6f60dc.pkl"
with open(det2_checkpoint_path, "rb") as f:
det2_weight = pkl.load(f)["model"]
# MaskFormer 官方 repo 中提供的权重是 np.array,需要转为为 tensor
det2_weight = {
k: torch.from_numpy(v).cuda()
for k, v in det2_weight.items()
}
det2_detector = build_model(det2_cfg)
det2_detector.load_state_dict(det2_weight)
det2_detector = det2_detector.cuda()
det2_detector.eval()
with torch.no_grad():
features = det2_detector.backbone(img)
det2_out = det2_detector.sem_seg_head(features)
print("pred_logits")
print("mmdet: ", mmdet_out[0][-1].sum())
print("det2: ", det2_out["pred_logits"].sum())
print("pred_masks")
print("mmdet: ", mmdet_out[1][-1].sum())
print("det2: ", det2_out["pred_masks"].sum()) 下图为上面代码运行的结果,两个版本的 forward 结果是一致的。

forward 结果
对齐 inference 精度
在进行 inference 之前,需要完成以下两个步骤:
1.完成整个 simple_test (推断)代码,即从 forward 的返回结果到最终的预测结果的过程,涉及到的代码为以下三部分:
- MaskFormer 的 simple_test
- MaskFormerHead 的 simple_test
- MaskFormerFusionHead
2.确定 inference 阶段的配置(test_cfg)和数据处理流程(val_pipeline)。inference 阶段的配置只需要添加到配置文件中的 test_cfg 部分,而 inference 阶段数据处理流程就是常规的 COCO 检测配置文件中的 val_pipeline,如下:
# test_cfg 及 test_pipeline 的设置
test_cfg=dict(
panoptic_on=True,
# For now, the dataset does not support
# evaluating semantic segmentation metric.
semantic_on=False,
instance_on=False,
# max_per_image is for instance segmentation.
max_per_image=100,
object_mask_thr=0.8,
iou_thr=0.8,
# In MaskFormer's panoptic postprocessing,
# it will not filter masks whose score is smaller than 0.5 .
filter_low_score=False)
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
test_pipeline = [
dict(type='LoadImageFromFile'),
dict(
type='MultiScaleFlipAug',
img_scale=(1333, 800),
flip=False,
transforms=[
dict(type='Resize', keep_ratio=True),
dict(type='RandomFlip'),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=1),
dict(type='ImageToTensor', keys=['img']),
dict(type='Collect', keys=['img']),
])
]
完成上面两步之后,就可以进行 inference,下表是 maskformer_r50 的 inference 结果,复现模型加载转化后的权重的 inference 结果为 46.526,与官方的结果基本一致(需要注意 MMDetection 中默认使用 opencv 来读取和处理图片,Detectron2 使用 pillow 来读取和处理图片,opencv 和 pillow 在读取和处理图片的结果是有差异的,对 inference 结果影响很小,但是对 loss 的影响比较大)。
| 实际测试精度(PQ) | 论文精度(PQ) | 复现模型加载转化后的权重(PQ) | |
| maskformer_r50 | 46.537 | 46.5 | 46.526 |
下图为官方发布的模型权重推理结果的可视化效果图:

对齐 loss 部分
在对齐好 inference 精度之后,可以确保模型的结构已经正确了。接下来要处理三件事:
- ground truth 的预处理。由于 COCOPanopticDataset 返回的是和 things 相关的 gt_labels 和 gt_masks, 以及和 stuff 相关的 gt_semantic_seg,需要转化为不区分 things 和 stuff 的 labels 和 masks。
- match_cost (DiceCost,FocalLossCost)、assigner 以及 loss 代码。由于 MaskFormer 中参与匹配的既有 label 也有 mask,而当时针对于 mask 的 match_cost 和 assigner 在 MMDetection 中还未实现,因此,这部分可以参考 MMDetection 有关 bbox 的 match_cost 和 assigner 来实现。
- 对齐 loss。这里可以伪造输入,然后分别转化为 Detectron2 的数据格式和 MMdetection 的数据格式,然后对比最后的 loss 是否一致。这里还需要排除随机数据变换的影响,比如 RandomFlip, Resize。因此,配置文件中 train_pipeline 可以按下面的代码进行设置,然后 MaskFormer 官方代码中相应的随机数据变换也需要注释掉。
# train_pipeline 的设置
img_norm_cfg = dict(
mean=[123.675, 116.28, 103.53], std=[58.395, 57.12, 57.375], to_rgb=True)
train_pipeline = [
dict(type='LoadImageFromFile', to_float32=True), # 加载图片的 backend 应该设置成 pillow
dict(
type='LoadPanopticAnnotations',
with_bbox=True,
with_mask=True,
with_seg=True),
# dict(type="Resize", img_scale=(1333, 800), keep_ratio=True),
# dict(type='RandomFlip', flip_ratio=0.),
dict(type='Normalize', **img_norm_cfg),
dict(type='Pad', size_divisor=1),
dict(type='DefaultFormatBundle', img_to_float=True),
dict(
type='Collect',
meta_keys=('filename', 'ori_filename', 'ori_shape',
'img_shape', 'pad_shape', 'scale_factor',
'img_norm_cfg'),
keys=['img', 'gt_bboxes', 'gt_labels', 'gt_masks', 'gt_semantic_seg']),
] 下面这段代码是我们分别加载原版的 MaskFormer 和我们实现的 MaskFormer,用官方发布的MaskFormer_r50 版本权重初始化模型,给定相同的输入(000000000009.jpg),对比 loss。
# 对齐 loss
import sys
sys.path.append("/data/open-mmlab/MaskFormer")
import torch
import pickle as pkl
from mmdet.datasets import build_dataset
from mmdet.models.builder import build_detector
from mmcv.utils.config import Config
from mask_former import DETRPanopticDatasetMapper, add_mask_former_config
from detectron2.config import get_cfg
from detectron2.modeling import build_model
from detectron2.data import build_detection_train_loader
#################################! MMDetection dataset
# 配置文件中训练数据处理流程中只加载数据不做变换(去掉 flip, resize)
mmdet_cfg_path = "./configs/maskformer/maskformer_r50_mstrain_16x1_75e_coco.py"
mmdet_cfg = Config.fromfile(mmdet_cfg_path)
mmdet_ds = build_dataset(mmdet_cfg.data.train)
# 加载 000000000009.jpg 及其标注
input_data = mmdet_ds[97623]
input_img = input_data["img"].data.unsqueeze(0).cuda()
img_metas = [input_data["img_metas"].data, ]
gt_bboxes = [input_data["gt_bboxes"].data.cuda(), ]
gt_labels = [input_data["gt_labels"].data.cuda(), ]
gt_masks = [input_data["gt_masks"].data, ]
gt_semantic_seg = [input_data["gt_semantic_seg"].data.cuda(), ]
#################################! MMDetection model
# 构建模型并加载权重
mmdet_detector = build_detector(mmdet_cfg.model)
checkpoint_path = "./checkpoints/maskformer/mmdet/maskformer_r50_converted_from_release_version.pth"
checkpoint = torch.load(checkpoint_path)["state_dict"]
mmdet_detector.load_state_dict(checkpoint)
mmdet_detector = mmdet_detector.cuda()
mmdet_detector.eval()
with torch.no_grad():
mmdet_loss = mmdet_detector.forward_train(
input_img,
img_metas,
gt_bboxes,
gt_labels,
gt_masks,
gt_semantic_seg)
#################################! Detectron2 dataset
# 加载配置文件
det2_cfg_path = "/data/open-mmlab/MaskFormer/configs/coco-panoptic/maskformer_r50.yaml"
det2_cfg = get_cfg()
add_mask_former_config(det2_cfg)
det2_cfg.merge_from_file(det2_cfg_path)
det2_cfg.freeze()
# 需要注释掉对随机变换的代码
mapper = DETRPanopticDatasetMapper(det2_cfg, True)
ds = build_detection_train_loader(det2_cfg, mapper=mapper)
# 第一张图片为 000000000009.jpg
det2_input = None
for x in ds:
if det2_input is None:
det2_input = x
break
#################################! Detectron2 model
# 构建模型并加载权重
det2_checkpoint_path = "./checkpoints/maskformer/det2/model_final_6f60dc.pkl"
with open(det2_checkpoint_path, "rb") as f:
det2_weight = pkl.load(f)["model"]
# MaskFormer 官方 repo 中提供的权重是 np.array,需要转为为 tensor
det2_weight = {
k: torch.from_numpy(v).cuda()
for k, v in det2_weight.items()
}
det2_detector = build_model(det2_cfg)
det2_detector.load_state_dict(det2_weight)
det2_detector = det2_detector.cuda()
det2_detector.eval()
# 在 https://github.com/facebookresearch/MaskFormer/blob/da3e60d85fdeedcb31476b5edd7d328826ce56cc/mask_former/mask_former_model.py#L171
# 中将 self.training 替换成 True
with torch.no_grad():
det2_loss = det2_detector(det2_input)
print(mmdet_loss)
print(det2_loss)
如下图所示,前四行为我们实现的 MaskFormer 所产生的 loss,后四行为 Detectron2 版本的 MaskFormer 所产生的 loss。给定相同的输入(000000000009.jpg),我们在 MMDetection 中实现的模型所产生的 loss 和原版的 Detectron2 中实现的模型所产生的 loss 是相同的(这里 loss_ce 和 loss_cls 是对应的)。

mmdet_loss 和 det2_loss
对齐 loss 涉及到的模块的功能及代码链接分别如下:
- preprocess_panoptic_gt:Ground truth 的预测预处理。
- DiceCost,FocalLossCost:用于mask 之间匹配的 dice cost、focal loss cost。
- MaskHungarianAssigner:用于 mask 的匈牙利分配器。
- MaskPseudoSampler:用于 mask 的伪采样器。
- MaskSamplingResult:用于 mask 的采样结果。
对齐其余部分
除了对齐上面的 foward 结果、 inference 精度、loss 等主要部分,还需要对齐:模型各层参数初始化方式、训练时的数据处理流程(与 detr 的训练数据处理流程相同)、训练配置(learning rate, warmup, weight decay, norm decay)等。这些部分相对简单并且 MMDetection 都已经有相应的实现,只需要设置好相关参数配置即可。下面是优化器及学习率策略的相关配置:
# 优化器
optimizer = dict(
type='AdamW',
lr=0.0001,
weight_decay=0.0001,
eps=1e-8,
betas=(0.9, 0.999),
paramwise_cfg=dict(
custom_keys={
# 调整 backbone 的学习率为整体学习率的十分之一
'backbone': dict(lr_mult=0.1, decay_mult=1.0),
# 关闭 query_embed 的 weight decay
'query_embed': dict(lr_mult=1.0, decay_mult=0.0)
},
# 关闭模型中的所有 norm 层的 weight decay
norm_decay_mult=0.0))
# 梯度裁剪
optimizer_config = dict(grad_clip=dict(max_norm=0.01, norm_type=2))
# 学习率策略,训练 75 个 epoch,在第 50 个 epoch 结束后,学习率减少为原来的十分之一
lr_config = dict(
policy='step',
gamma=0.1,
by_epoch=True,
step=[50],
warmup='linear',
warmup_by_epoch=False,
warmup_ratio=1.0, # 不添加warmup
warmup_iters=10)
runner = dict(type='EpochBasedRunner', max_epochs=75) 添加单元测试及文档
单元测试尽可能在完成一个模块之后就添加进去,因为在 PR 合入之前,代码可能要多次改动,这个过程中很可能产生 bug,单元测试可以帮助我们检查出一部分 bug。另外,各个模块需要完善的文档来说明其作用、输入和输出。这么做一方面可以帮助用户快速上手我们写的模块,另一方面也可以检查所写模块是否是自己所想要的。
提交 PR
提交一个大 PR(代码数量大,涉及的文件很多)是不合适的,容易引入 bug,而且不利于 review。因此,在上述步骤完成得差不多时,可以考虑拆分 PR,逐个提交 PR(PR 提交方式见【干货贴】手把手教你给 OpenMMLab 提 PR )到 MMDetection。以 MaskFormer 为例,整个大 PR 可以拆分为 10 个小 PR (每个 PR 都要包含相应模块的单元测试):
- preprocess_panoptic_gt
- DiceCost
- FocalLossCost
- MaskHungarianAssigner
- MaskPseudoSampler
- MaskSamplingResult
- PixelDecoder, TransformerEncoderPixelDecoder
- MaskFormerHead
- MaskFormerFusionHead
- MaskFormer
PR 提交后,会进行 license、lint、unit test 检查以及 docs 的生成。如果有哪一项检查没有通过,可以点进相应的 item 看一下问题出在哪里。


经过多轮 review 确保代码基本没有问题之后,我们会帮助训练模型。如果模型训练结果和论文结果一致,那我们就会把 PR 合入到 dev 分支。在每个月发布新版本之前,我们会对 dev 分支进行测试,如果通过测试,dev 分支将被合并到 master 分支,然后打上 tag ,发布新版本。
结语
本文以 MaskFormer 算法为例,和大家一起学习了在 MMDetection 复现算法的全流程,同时还分享了在 MMDetection 提交 PR 的一些经验,希望大家能有所收获。我们非常欢迎大家提交 PR 给 MMDetection 添加新的算法,共同打造更加优异的目标检测框架。
了解 PR 合入 MMDetection 的过程可参考:
- MaskFormer
- MaskFormer Refactor
- Mask2Former
参考文献
- https://arxiv.org/pdf/2107.06278
- https://arxiv.org/pdf/1801.00868