深度学习求解微分方程系列一:PINN求解框架
下面我将介绍内嵌物理知识神经网络(PINN)求解微分方程。首先介绍PINN基本方法,并基于Pytorch框架实现求解一维Poisson方程。
1.PINN简介
神经网络作为一种强大的信息处理工具在计算机视觉、生物医学、 油气工程领域得到广泛应用, 引发多领域技术变革.。深度学习网络具有非常强的学习能力, 不仅能发现物理规律, 还能求解偏微分方程.。近年来,基于深度学习的偏微分方程求解已是研究新热点。内嵌物理知识神经网络(PINN)是一种科学机器在传统数值领域的应用方法,能够用于解决与偏微分方程 (PDE) 相关的各种问题,包括方程求解、参数反演、模型发现、控制与优化等。
2.PINN方法
PINN的主要思想如图1,先构建一个输出结果为 u ^ \hat{u} u^的神经网络,将其作为PDE解的代理模型,将PDE信息作为约束,编码到神经网络损失函数中进行训练。

损失函数主要包括4部分:偏微分结构损失(PDE loss),边值条件损失(BC loss)、初值条件损失(IC loss)以及真实数据条件损失(Data loss)。特别的,考虑下面这个的PDE问题,其中PDE的解 u ( x ) u(x) u(x)在 Ω ⊂ R d \Omega \subset \mathbb{R}^{d} Ω⊂Rd定义,其中 x = ( x 1 , … , x d ) \mathbf{x}=\left(x_{1}, \ldots, x_{d}\right) x=(x1,…,xd):
f ( x ; ∂ u ∂ x 1 , … , ∂ u ∂ x d ; ∂ 2 u ∂ x 1 ∂ x 1 , … , ∂ 2 u ∂ x 1 ∂ x d ) = 0 , x ∈ Ω f\left(\mathbf{x} ; \frac{\partial u}{\partial x_{1}}, \ldots, \frac{\partial u}{\partial x_{d}} ; \frac{\partial^{2} u}{\partial x_{1} \partial x_{1}}, \ldots, \frac{\partial^{2} u}{\partial x_{1} \partial x_{d}} \right)=0, \quad \mathbf{x} \in \Omega f(x;∂x1∂u,…,∂xd∂u;∂x1∂x1∂2u,…,∂x1∂xd∂2u)=0,x∈Ω
同时,满足下面的边界
B ( u , x ) = 0 on ∂ Ω \mathcal{B}(u, \mathbf{x})=0 \quad \text { on } \quad \partial \Omega B(u,x)=0 on ∂Ω
为了衡量神经网络 u ^ \hat{u} u^和约束之间的差异,考虑损失函数定义:
L ( θ ) = w f L P D E ( θ ; T f ) + w i L I C ( θ ; T i ) + w b L B C ( θ , ; T b ) + w d L D a t a ( θ , ; T d a t a ) \mathcal{L}\left(\boldsymbol{\theta}\right)=w_{f} \mathcal{L}_{PDE}\left(\boldsymbol{\theta}; \mathcal{T}_{f}\right)+w_{i} \mathcal{L}_{IC}\left(\boldsymbol{\theta} ; \mathcal{T}_{i}\right)+w_{b} \mathcal{L}_{BC}\left(\boldsymbol{\theta},; \mathcal{T}_{b}\right)+w_{d} \mathcal{L}_{Data}\left(\boldsymbol{\theta},; \mathcal{T}_{data}\right) L(θ)=wfLPDE(θ;Tf)+wiLIC(θ;Ti)+wbLBC(θ,;Tb)+wdLData(θ,;Tdata)
式中:
L P D E ( θ ; T f ) = 1 ∣ T f ∣ ∑ x ∈ T f ∥ f ( x ; ∂ u ^ ∂ x 1 , … , ∂ u ^ ∂ x d ; ∂ 2 u ^ ∂ x 1 ∂ x 1 , … , ∂ 2 u ^ ∂ x 1 ∂ x d ) ∥ 2 2 L I C ( θ ; T i ) = 1 ∣ T i ∣ ∑ x ∈ T i ∥ u ^ ( x ) − u ( x ) ∥ 2 2 L B C ( θ ; T b ) = 1 ∣ T b ∣ ∑ x ∈ T b ∥ B ( u ^ , x ) ∥ 2 2 L D a t a ( θ ; T d a t a ) = 1 ∣ T d a t a ∣ ∑ x ∈ T d a t a ∥ u ^ ( x ) − u ( x ) ∥ 2 2 \begin{aligned} \mathcal{L}_{PDE}\left(\boldsymbol{\theta} ; \mathcal{T}_{f}\right) &=\frac{1}{\left|\mathcal{T}_{f}\right|} \sum_{\mathbf{x} \in \mathcal{T}_{f}}\left\|f\left(\mathbf{x} ; \frac{\partial \hat{u}}{\partial x_{1}}, \ldots, \frac{\partial \hat{u}}{\partial x_{d}} ; \frac{\partial^{2} \hat{u}}{\partial x_{1} \partial x_{1}}, \ldots, \frac{\partial^{2} \hat{u}}{\partial x_{1} \partial x_{d}} \right)\right\|_{2}^{2} \\ \mathcal{L}_{IC}\left(\boldsymbol{\theta}; \mathcal{T}_{i}\right) &=\frac{1}{\left|\mathcal{T}_{i}\right|} \sum_{\mathbf{x} \in \mathcal{T}_{i}}\|\hat{u}(\mathbf{x})-u(\mathbf{x})\|_{2}^{2} \\ \mathcal{L}_{BC}\left(\boldsymbol{\theta}; \mathcal{T}_{b}\right) &=\frac{1}{\left|\mathcal{T}_{b}\right|} \sum_{\mathbf{x} \in \mathcal{T}_{b}}\|\mathcal{B}(\hat{u}, \mathbf{x})\|_{2}^{2}\\ \mathcal{L}_{Data}\left(\boldsymbol{\theta}; \mathcal{T}_{data}\right) &=\frac{1}{\left|\mathcal{T}_{data}\right|} \sum_{\mathbf{x} \in \mathcal{T}_{data}}\|\hat{u}(\mathbf{x})-u(\mathbf{x})\|_{2}^{2} \end{aligned} LPDE(θ;Tf)LIC(θ;Ti)LBC(θ;Tb)LData(θ;Tdata)=∣Tf∣1x∈Tf∑∥ ∥f(x;∂x1∂u^,…,∂xd∂u^;∂x1∂x1∂2u^,…,∂x1∂xd∂2u^)∥ ∥22=∣Ti∣1x∈Ti∑∥u^(x)−u(x)∥22=∣Tb∣1x∈Tb∑∥B(u^,x)∥22=∣Tdata∣1x∈Tdata∑∥u^(x)−u(x)∥22
w f w_{f} wf, w i w_{i} wi、 w b w_{b} wb和 w d w_{d} wd是权重。 T f \mathcal{T}_{f} Tf, T i \mathcal{T}_{i} Ti、 T b \mathcal{T}_{b} Tb和 T d a t a \mathcal{T}_{data} Tdata表示来自PDE,初值、边值以及真值的residual points。这里的 T f ⊂ Ω \mathcal{T}_{f} \subset \Omega Tf⊂Ω是一组预定义的点来衡量神经网络输出 u ^ \hat{u} u^与PDE的匹配程度。
3.求解问题定义
d 2 u d x 2 = − 0.49 ⋅ sin ( 0.7 x ) − 2.25 ⋅ cos ( 1.5 x ) u ( − 10 ) = − sin ( 7 ) + cos ( 15 ) + 1 u ( 10 ) = sin ( 7 ) + cos ( 15 ) − 1 \begin{aligned} \frac{\mathrm{d}^2 u}{\mathrm{~d} x^2} &=-0.49 \cdot \sin (0.7 x)-2.25 \cdot \cos (1.5 x) \\ u(-10) &=-\sin (7)+\cos (15)+1 \\ u(10) &=\sin (7)+\cos (15)-1 \end{aligned} dx2d2uu(−10)u(10)=−0.49⋅sin(0.7x)−2.25⋅cos(1.5x)=−sin(7)+cos(15)+1=sin(7)+cos(15)−1
真实解为
u : = sin ( 0.7 x ) + cos ( 1.5 x ) − 0.1 x u:=\sin (0.7 x)+\cos (1.5 x)-0.1 x u:=sin(0.7x)+cos(1.5x)−0.1x
4.Python求解代码
第一步,首先定义神经网络
# torch version 1.4.0
import torch
import torch.optim
from collections import OrderedDict
import torch.nn as nn
class Net(nn.Module):
def __init__(self, seq_net, name='MLP', activation=torch.tanh):
super().__init__()
self.features = OrderedDict()
for i in range(len(seq_net) - 1):
self.features['{}_{}'.format(name, i)] = nn.Linear(seq_net[i], seq_net[i + 1], bias=True)
self.features = nn.ModuleDict(self.features)
self.active = activation
# initial_bias
for m in self.modules():
if isinstance(m, nn.Linear):
nn.init.constant_(m.bias, 0)
def forward(self, x):
length = len(self.features)
i = 0
for name, layer in self.features.items():
x = layer(x)
if i == length - 1: break
i += 1
x = self.active(x)
return x
第二步,PINN求解框架
from net import Net
import os
import matplotlib.pyplot as plt
import torch
from torch.autograd import grad
def d(f, x):
return grad(f, x, grad_outputs=torch.ones_like(f), create_graph=True, only_inputs=True)[0]
def PDE(u, x):
return d(d(u, x), x) + 0.49 * torch.sin(0.7 * x) + 2.25 * torch.cos(1.5 * x)
def Ground_true(x):
return torch.sin(0.7 * x) + torch.cos(1.5 * x) - 0.1 * x
def train():
lr = 0.001
n_pred = 100
n_f = 200
epochs = 8000
os.environ['CUDA_VISIBLE_DEVICES'] = '0'
device = torch.device('cuda:0') if torch.cuda.is_available() else torch.cuda('cpu')
PINN = Net([1, 50, 50, 50, 1]).to(device)
x_left, x_right = -10, 10
optimizer = torch.optim.Adam(PINN.parameters(), lr)
criterion = torch.nn.MSELoss()
loss_history = []
for epoch in range(epochs):
optimizer.zero_grad()
# inside
x_f = ((x_left + x_right) / 2 + (x_right - x_left) *
(torch.rand(size=(n_f, 1), dtype=torch.float, device=device) - 0.5)
).requires_grad_(True)
u_f = PINN(x_f)
PDE_ = PDE(u_f, x_f)
mse_PDE = criterion(PDE_, torch.zeros_like(PDE_))
# boundary
x_b = torch.tensor([[-10.], [10.]]).requires_grad_(True).to(device)
u_b = PINN(x_b)
true_b = Ground_true(x_b)
mse_BC = criterion(u_b, true_b)
# predict
x_pred = ((x_left + x_right) / 2 + (x_right - x_left) *
(torch.rand(size=(n_pred, 1), dtype=torch.float, device=device) - 0.5)
).requires_grad_(True)
u_f = PINN(x_pred)
true_f = Ground_true(x_pred)
mse_pred = criterion(u_f, true_f)
loss = 1 * mse_PDE + 1 * mse_BC
loss_history.append([mse_PDE.item(), mse_BC, mse_pred])
if epoch % 100 == 0:
print(
'epoch:{:05d}, EoM: {:.08e}, BC: {:.08e}, loss: {:.08e}'.format(
epoch, mse_PDE.item(), mse_BC.item(), loss.item()
)
)
loss.backward()
optimizer.step()
xx = torch.linspace(-10, 10, 10000).reshape((-1, 1)).to(device)
if (epoch + 1) % 300 == 0:
yy = PINN(xx)
zz = Ground_true(xx)
xx = xx.reshape((-1)).data.detach().cpu().numpy()
yy = yy.reshape((-1)).data.detach().cpu().numpy()
zz = zz.reshape((-1)).data.detach().cpu().numpy()
plt.cla()
plt.plot(xx, yy, label='PINN')
plt.plot(xx, zz, label='True', color='r')
plt.legend()
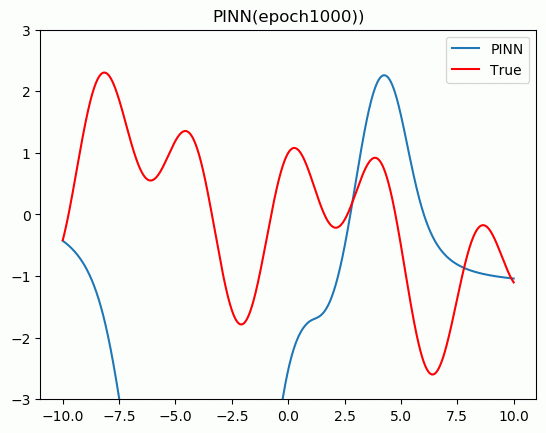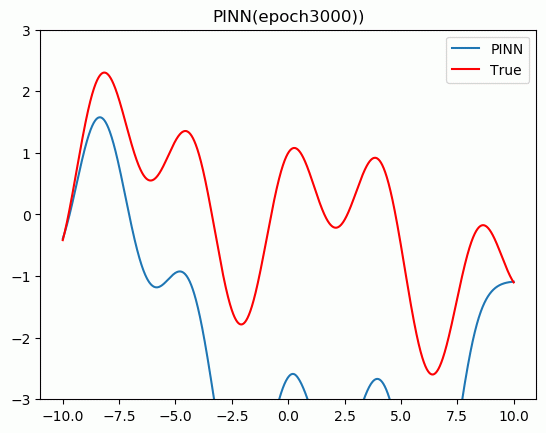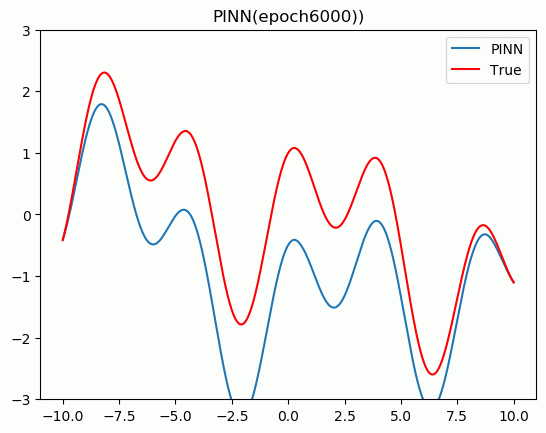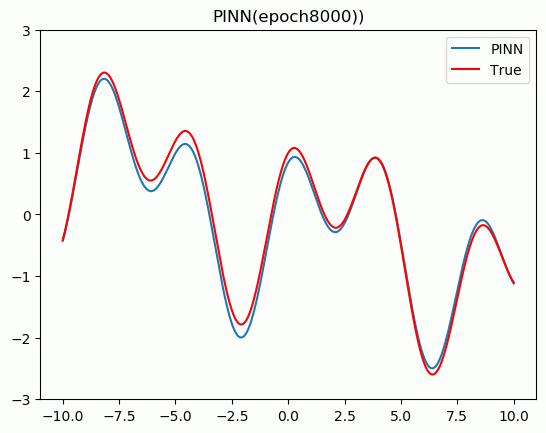
plt.title('PINN(epoch{}))'.format(epoch + 1))
plt.show()
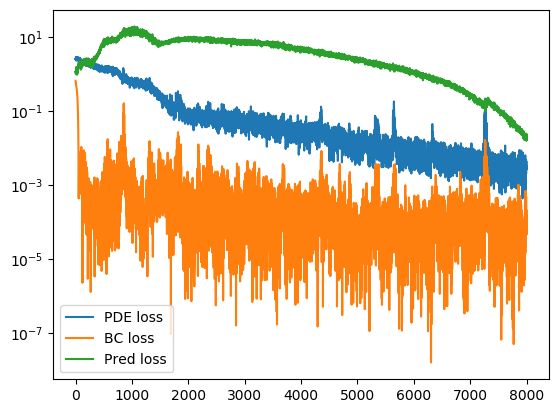
plt.plot(loss_history)
plt.legend(('PDE loss', 'BC loss', 'Pred loss'), loc='best')
plt.show()
if name == ‘main’:
train()
5.结果展示