c缺陷与陷阱
《c陷阱与缺陷》笔记
-- chap.1 --
1. 字符和字符串
'a' //字符,实际上代表一个整数,对应ASCII中的编码值
"a" //字符串,代表一个指向无名数组起始字符的指针,末尾带有结束字符'\0'。因此"abcd"[i]是合理的。
char *ptr = 'c'; //错误,'c'不是一个指针字符,而是一个数值!2. 防御性编程
任何编译器都无法捕捉到所有错误,况且C语言的安全系数较低(较Cpp),因此编程时采取一些防御措施是很好的习惯。
if (c == '\t') //容易发生if (c = '\t')的误写,编译器不会报错。
if ('\t' == c) //防御性高,因为对常量复制('\t' = c)是非法的3. 嵌套注释
c语言标准里是不允许嵌套注释的(matlab可以),两种好玩的判断方法:
// way - 1
int a = /*/*/0*/**/1; //允许嵌套注释的话,a == 1, 否则a == 0*1
// way - 2
string a = /*/**/"*/"/*"/**/; //允许嵌套的话,a == "/*", 否则a == "*/"4. 词法分析的“大嘴原则”
c语言在词法分析上有一个很简单的规则,即每一个符号应该包括尽可能都的字符。
比如:a+++++b会被分解成((a++)++)+b,但a++不能作为左值,因此a+++++b是非法的。
-- chap.2 --
1.* 函数指针
1)可以在声明符中任意使用括号,如float ((f))的含义是((f))是浮点类型,由此可推知f为浮点类型。
2)函数指针的调用。声明一个函数指针float (*p)(),注意我们平常缩写的调用p()只是一个简写,完整的为(*p)()。
3)在已经声明了一个给定类型的变量,那么该类型的类型转换符可这样得到:把声明中的变量和声明尾部的分号去掉,将剩余部分用一个括号“封装”起来。
比如:float a; => (float),很常见的显示float类型转换;稍复杂一点的float (*h)() => (float (*)()),表示一个“指向返回值为浮点类型的函数的指针”的类型转换符;
4)一个再复杂点的函数调用的例子:
(*(void (*)()) 0)(); 分析:注意到内层为“ (void (*)()) ”,是一个“指向返回值为void类型的函数指针”的类型转换符FuncType;外层为“ (* (FuncType) 0)(); ”,即把操作数0强制转换成FuncType,然后进行函数调用(末尾分号)。该函数的 功能:调用首地址为0位置的子例程(实际中能不能调用暂且不管),可以这样理解:“ (* (FuncType) f)() ”中的函数指针f的值代表了函数的地址,显式的将地址值指明为0并进行类型转换后,便起到了函数调用的作用。注意,如果不进行类型转换,这种写法是非法的,因为c语言并不认为0是一个合理的函数指针操作数。也可以用typedef来 重写:
typedef void (*FuncType)();
(* (FuncType) 0)(); 5)案例分析:库函数signal的声明
void (*signal(int, void(*)(int))) (int);typedef void (*FuncType) (int);
FuncType signal(int, FuncType);2.* 运算符优先级

-- chap.3 --
1. 指针与数组
1)c语言中只有一维数组,数组大小必须在编译期作为一个常数确定下来。由于数组元素可以是任意类型,所以可以间接模拟出多维数组。如" int a[2][3] "表示a是一个包含两个元素的数组,每个元素都是一个拥有3个int型元素的数组。
2)数组名是下标为0的元素的指针,除了sizeof(sizeof(a)表示数组a的大小),一切有关数组的操作(哪怕看起来是对下标运算)实际上都是通过指针进行的。也就是说,任何一个数组下标的运算都等同一个对应的指针运算。例如,对于一个数组的元素a[i],由于a+i和i+a表达的意思相同,因此a[i]也可以写成i[a]。
3)使用指针时注意左右类型的匹配,即区别好指向数组的指针与指向整形变量的指针,这也是很多问题来回倒腾的根本之处。
4)分析这样一个例子:
int (*a)[31];2. 不对称边界原则
1)看这样一个例子:
int i, a[10];
for(i = 1; i <= 10; i++)
a[i] = 0;分析:可能会发生死循环。因为栈区通常在虚拟内存中从高逻辑地址向低逻辑地址给变量分配内存,在一些不进行边界保护的系统中,上述代码中的a[10]所处的位置恰巧与i重合,造成了变量i每次都会被置为0,重新开始循环。(在c++里运行时会报错“Stack around the variable 'a' was corrupet”)。
2)在ANSI C标准中允许访问数组出界点元素(即上例中的a[10]),但只能用于赋值和比较,不能引用。(c++里只有取地址是被允许的,不能查看内容)
3)问题1:将长度无规律的输入数据送到缓冲区(能够容纳N个字符),每当这块内存被填满时,就将缓冲区中的内容写出。
#define N 1024
static char buffer[N];
static char *bufptr = buffer;
void bufwrite(char *p, int n)
{
while(n > 0)
{
int k, rem;
if(bufptr = &buffer[N])
flushbuffer();
rem = N - (bufptr - buffer);
k = rem > n? n:rem;
memcpy(bufptr, p, k);
n -= k;
p += k;
}
}
//c语言中的memcpy()函数通常使用汇编来写的(为了加快速度)
void memcpy(char *dest, char *source, int k)
{
while(--k>=0)
*dest++ = *source++;
}采用了先赋值后自增的方式,利用“不对称边界原则”进行判断,每次操作结束后,bufptr指针都指向当前元素的下一个内存地址,这样实现起来的代码简练不易出错。
4)问题2:存在一个程序,该程序按一定顺序生成一些整数,并将这些整数按列输出,填充完一页后可以翻页。要求从左到右打印每个输出行,一行被打印后就不能被撤销或更改,print函数可以缓冲(不缓冲也做不了)。
//缓冲区大小最小要这么大,
//否则永远不能按照要求把最后一列的元素与其对应行元素整合
#define BUFSIZE (NROWS*(NCOLS-1))
static int buffer[BUFSIZE];
static int *bufptr = buffer;
//按要求打印每个元素
void print(int n)
{
if(bufptr == &buffer[BUFSIZE])
{
static int row = 0;
int *p;
for(p = buffer + row; p < bufptr; p += NROWS)
printnum(*p); //打印当前row位置p的数值
printnum(n); //打印当前row最后一列的数值
printline(); //打印换行符
if(++row == NROWS)
{
bufptr = buffer;
row = 0;
printpage(); //打印分页符
}
}
else
*bufptr++ = n;
}
//处理尾部文件,将最后的的未满BUFSIZE的内容全部打出
//只遍历出现的列数
void flush()
{
int row;
int k = bufptr - buffer;
k = k > NROWS? NROWS:k;
if(k > 0)
{
for(row = 0; row < k; row++)
{
int *p;
for(p = buffer + row; p < bufptr; p += NROWS)
printnum(*p);
printline();
}
printpage();
}
}3. 操作符求值顺序
只有四个操作符存在求值顺序的问题:"&&"、"||"、"?:"和","。具体不再详记。
4. 整数溢出
只有在两个操作符都为有符号数时才有可能发生“溢出”,其他情况会发生隐式转换(一方有符号,另一方无符号时)。
假设a和b都是非负整型常量,检测a+b是否溢出的方法:
if(a + b < 0) //naive, 有的机器寄存器存在四种状态:正、负、零、溢出,此时if判断失败
if((unsigned)a + (unsigned)b > INT_MAX) //good
if(a > INT_MAX - b) //good
-- chap.4 --
1.scanf("%d",&c)出错防不胜防
#include
int main()
{
freopen("Example.in","r",stdin);
int i;
char c;
for( i = 0; i < 5; ++i)
{
scanf("%d",&c);
printf("%d ",i);
}
return 0;
} 为什么呢?问题的关键在于,这里c被声明为char类型,而不是int类型。当程序要求scanf 读入一个整数,应该传递给它一个指向整数的指针。而程序中scanf 函数得到的却是一个指向字符的指针,scanf 函数并不能分辨这种情况,它只能将这个指向字符的指针作为指向整数的指针而接受,并且在指针指向的位置存储一个整数。因为整数所占的存储空间要大于字符所占的存储空间,所以字符c附近的内存将被覆盖。
字符c附近的内存中存储是由编译器决定的,本例中它存放的是整数i的低端部分。因此,每次读入一个数值到c时,都会将i的低端部分覆盖为0,循环将一直进行。当达到文件的结束位置后,scanf 函数不再试图读入新的数值到c。这使,i 才可以正常地递增,最后循环结束。
2. 外部类型的检查
这样对吗?
在一个文件包含定义: char filename[] = "/etc/passwd";
在另个文件包含声明: extern char * filename;
尽管数组与指针非常相似,但它们毕竟不同。
字符数组filename的内存布局如图:
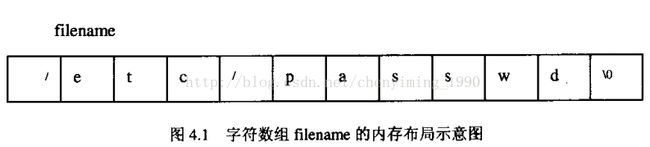
指针字符filename的内存布局如图:

更正本例:
既可以:
char filename[[ = "/etc/passwd'; /* 文件1*/
extern char filename[];/* 文件2*/
也可以:
char * filename = "/etc/passwd';/* 文件1*/
extern char * filename; /* 文件2*/
-- chap.5 --
1.fread和fwrite中间必须加入fseek,因为读写操作都改写了读取的位置,都是然后面移动的,而且读写不是实时进行的,会有缓存区,用fseek可以清空缓存,防止读写错误。
#include
struct tm
{
long c;
int i;
}st;
int main()
{
FILE *fp = fopen("Example.in","r+");
while(fread(&st,sizeof(st),1,fp) == 1)
{
/* st 执行某些操作 */
if(/* rec 必须重新写入 */)
{
fseek(fp,-(long)sizeof(st),1);
fwrite(&st,sizeof(st),1,fp);
}
}
fclose(fp);
return 0;
} #include
struct tm
{
long c;
int i;
}st;
int main()
{
FILE *fp = fopen("Example.in","r+");
while(fread(&st,sizeof(st),1,fp) == 1)
{
/* st 执行某些操作 */
if(/* rec 必须重新写入 */)
{
fseek(fp,-(long)sizeof(st),1);
fwrite(&st,sizeof(st),1,fp);
fseek(fp,0L,1);//增添的
}
}
fclose(fp);
return 0;
} 2.缓冲区输出与内存分配
#include
int main()
{
int c;
char buf[BUFSIZ];
setbuf(stdout,buf);
while((c = getchar()) != EOF)
{
putchar(c);
}
} 3.使用erron检测错误
/* 调用库函数 */
if(返回的错误值)
{
/* 检查 erron */
}4.库函数 signal
-- chap.6 --
/* 略过 */
-- chap.7 --
1.移位运算符
2.除法运算时发生的截断
必定满足 q*b + r == a, 还有就是余数r可能是负数(比如:-3 % 2 = -1 商为1,而不是 余数为 1 商为2,切记)
而且如果 b为负数的话,比如 -3 % -2 == -1,商为1,所以应该保证 a/ b 与 -a / b 的绝对值是相同的原则上考虑余数。
在通过除法得到哈希条目n的情况:
h = n % HASHSIZE; // 如果n有可能为负数的时候,一定要检测结果的正负
if(h < 0) h += HASHSIZE;