SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation(NeurIPS 22)
SegNeXt: Rethinking Convolutional Attention Design for Semantic Segmentation
- 摘要
- introduction
- 2 related work
-
- 2.1 semantic segmentation
- 2.2 Multi-scale Networks
- 2.3 Attention Mechanisms
- 3 method
-
- 3.1 Convolutional Encoder
- 3.2 decoder
- 4 Experiments
-
- 4.1 Encoder Performance on ImageNet
- 4.2 Ablation study
参考:
https://mp.weixin.qq.com/s/eALhj_1SNwXPVcXuCs6bkA
论文: https://arxiv.org/abs/2209.08575
代码: code:https://github.com/Visual-Attention-Network/SegNeXt
摘要
我们介绍了SegNeXt,这是一种用于语义分割的简单卷积网络体系结构。由于在编码空间信息时自我注意的效率,最近基于Transformer的模型已主导语义分割领域。在本文中,我们证明了卷积注意比Transformer中的自注意机制更有效地编码上下文信息。本文对已有成功分割方案进行了重审视并发现了几个有助于性能提升的关键成分,进而促使我们设计了一种新型的卷积注意力架构方案SegNeXt。在没有任何花哨的成分下,我们的SegNeXt显着改善了以前在流行基准测试 (包括ADE20K,Cityscapes,COCO-Stuff,Pascal VOC,Pascal Context和iSAID) 上最先进的方法的性能。值得注意的是,SegNeXt的性能优于EfficientNet-L2 w/ NAS-FPN,并且仅使用其1/10参数在Pascal VOC 2012测试一下排行榜上实现90.6% mIoU。与ad20k数据集上具有相同或更少计算的最新方法相比,SegNeXt平均实现了约2.0% mIoU改进。代码可用。
introduction
作为计算机视觉中最基础的研究课题之一,旨在为每个像素分配语义类别的语义分割在过去十年中引起了极大的关注。从以FCN [53] 和DeepLab系列 [4,6,8] 为代表的早期基于CNN的模型,到以SETR [96] 和SegFormer [80] 为代表的最近基于transformer的方法,语义分割模型在网络架构方面经历了重大的革命。
作者首先展现了表1比较了几个主流的语义分割神经网络:

通过重新审视以前成功的语义分割作品,我们总结了不同模型所具有的几个关键属性,如table1所示。基于以上观察,我们认为成功的语义分割模型应具有以下特征 :(一) 强大的骨干网作为编码器。与以前基于CNN的模型相比,基于变压器的模型的性能提升主要来自更强的骨干网。(二) 多尺度信息交互。与主要识别单个对象的图像分类任务不同,语义分割是一个密集的预测任务,因此需要处理单个图像中大小不同的对象。(三) 空间关注。空间注意允许模型通过对语义区域内的区域进行优先级排序来执行分割。(四) 计算复杂度低。在处理来自遥感和城市场景的高分辨率图像时,这尤其重要。
总结:
由图可见成功的语义分割主要会关注于strong encoder:强骨干作为编码器;Multi-scale interactions:多尺度交互;spatial attention:空间注意力;computational complexity:计算复杂度(自然是越低越好)
考虑到上述分析,在本文中,我们重新考虑了卷积注意力的设计,并提出了一种有效的语义分割编码器-解码器体系结构。与以前使用解码器中的卷积作为特征细化器的基于Transformer的模型不同,我们的方法反转了transformer-卷积编码器-解码器体系结构。具体来说,对于编码器中的每个块,我们翻新了传统卷积块的设计,并利用多尺度卷积特征通过简单的元素乘式乘法来引起空间关注 [24]。我们发现,在空间信息编码中,这种建立空间注意力的简单方法比标准卷积和自我注意力都更有效。对于解码器,我们从不同阶段收集多级特征,并使用Hamburger [21] 进一步提取全局上下文。在这种设置下,我们的方法可以从局部到全局获得多尺度上下文,在空间和通道维度上实现适应性,并从低级到高级聚合信息。
原文:
For decoder, we collect multi-level features from different stages and use Hamburger [21] to further extract global context. Under this setting, our method can obtain multi-scale context from local to global, achieve adaptability in spatial and channel dimensions, and aggregate information from low to high levels.
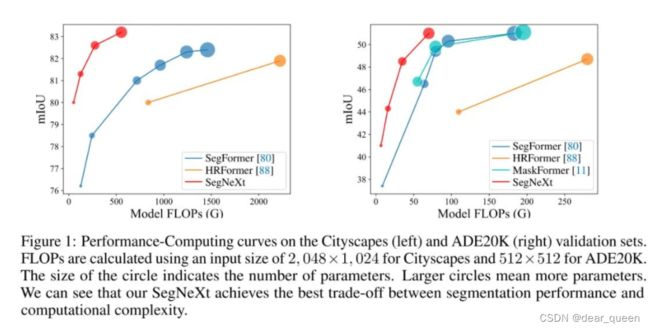
我们的网络称为SegNeXt,除解码器部分外,主要由卷积运算组成,其中包含Hamberger [21] (Ham),用于全局信息提取。这使得我们的SegNeXt比以前严重依赖Transformer的分割方法效率高得多。如图1所示,SegNeXt的性能明显优于最近的基于Transformer的方法。特别是,在处理来自Cityscapes数据集的高分辨率城市场景时,我们的SegNeXt-S仅使用约1/6 (124.6g对717.1G) 的计算成本和1/2参数 (13.9M对27.6M) 就优于SegFormer-B2 (81.3% 对81.0%)
总结一下Introduction
通常情况下,我们是使用Transformer作为骨干网络,因为通常认为Transformer具备更强的特征提取能力,同时通常以Transformer作为全局特征提取,以CNN作为局部辅助,采用Transformer-Convolution Encoder-Decoder架构。
本文中是将该架构翻转,在encoder中是采用卷积结构,同时引入了多尺度卷积注意力。在decoder阶段主要包含Hamberger模块(替代self- transformer),用于全局特征提取。
因此,SegNeXt能够从局部到全局提取多尺度上下文信息,能在空域与通道维度达成自适应性,能从底层到高层进行信息聚合。上图给出了Cityscape与ADE20K数据集上所提方案与标杆方案的计算量与性能对比。
本文贡献:
我们的贡献可以总结如下:
• 我们确定了一个好的语义分割模型应该拥有的特征,并提出了一种新颖的量身定制的网络体系结构,称为SegNeXt,通过多尺度卷积特征引起空间关注。
• 我们证明,具有简易的卷积的编码器仍然可以比vision transformer更好地执行,尤其是在处理对象细节时,同时它需要更少的计算成本。
• 我们的方法在各种细分基准 (包括ADE20K、Cityscapes、COCO-Stuff、Pascal VOC、Pascal上下文和iSAID) 上大幅提高了最先进的语义分割方法的性能。
2 related work
2.1 semantic segmentation
语义分割是计算机视觉的一项基本任务。自FCN [53] 提出以来,卷积神经网络 (CNNs) [1、64、86、94、19、87、71、20、45] 取得了巨大的成功,成为一种流行的语义分割体系结构。最近,基于Transformer的方法 [96、80、88、65、63、44、11、10] 显示出巨大的潜力,并且优于基于CNN的方法。
在深度学习时代,分割模型的体系结构可以大致分为两个部分: 编码器和解码器。对于编码器,研究人员通常采用流行的分类网络 (例如,ResNet [27],ResNeXt [81] 和DenseNet [32]),而不是量身定制的体系结构。但是,语义分割是一种密集预测任务,它不同于图像分类。分类的改进可能不会出现在具有挑战性的分割任务中 [28]。于是,一些量身定制的编码器出现了,包括Res2Net [20] 、HRNet [71] 、SETR [96] 、SegFormer [80] 、HRFormer [88] 、MPViT [38] 、DPT [63] 等。对于解码器,它经常用于与编码器配合以获得更好的效果。针对不同目标有不同类型的解码器,包括实现多尺度感受野 [94、7、78] 、收集多尺度语义 [64、80、8] 、扩大感受野 [5、4、62] 、加强边缘特征 [95、2、16、42、90],并捕获全全局信息 [19、34、89、40、23、26、91]。
在本文中,我们总结了那些为语义分割设计的成功模型的特征,并提出了一个基于CNN的模型,名为SegNeXt。与我们的论文最相关的工作是 [62],它将k × k卷积分解为一对k × 1和1 × k卷积。尽管这项工作显示了大卷积核在语义分割中的重要性,但它忽略了多尺度感受野的重要性,并且没有考虑如何利用大核提取的这些多尺度特征以注意的形式进行分割。
62论文:Large kernel matters–improve semantic seg-
mentation by global convolutional network
2.2 Multi-scale Networks
设计多尺度网络是计算机视觉的流行方向之一。对于分割模型,多尺度块出现在编码器 [71,20,67] 和解码器 [94,86,6] 部分中。GoogleNet [67] 是与我们的方法最相关的多尺度体系结构之一,该方法使用多分支结构来实现多尺度特征提取。与我们的方法相关的另一项工作是HRNet [71]。在更深的阶段,HRNet还保留了高分辨率特征,这些特征与低分辨率特征聚合在一起,以实现多尺度特征提取。与以前的方法不同,SegNeXt除了在编码器中捕获多尺度特征外,还引入了一种有效的注意机制,并采用了更cheaper,更大的内核卷积。这些使我们的模型能够实现比上述分割方法更高的性能。
2.3 Attention Mechanisms
注意机制是一种自适应选择过程,旨在使网络集中在重要部分。一般来说,它在语义分割上可以分为两类 [25],包括通道注意力和空间注意力。不同类型的注意力发挥着不同的作用。例如,空间关注主要关注重要的空间区域 [17,14,57,51,22]。不同的是,使用通道注意力的目标是使网络有选择地关注那些重要的对象,这在以前的作品中已经被证明是重要的 [30,9,72]。说到最近流行的vision transformer [17、51、82、74、73、50、80、444、49、88],它们通常会忽略通道维度上的适应性。
视觉注意网络 (visual attention network,VAN) [24] 是与SegNeXt最相关的工作,该工作还提出利用大内核注意 (LKA) 机制来构建通道和空间注意。尽管VAN在图像分类方面取得了出色的表现,但它忽略了网络设计过程中多尺度特征聚合的作用,这对于类似分割的任务至关重要。
3 method
在本节中,我们将详细描述拟议的SegNeXt的体系结构。基本上,我们采用了遵循大多数以前工作的编码器-解码器体系结构,该体系结构简单且易于遵循。
3.1 Convolutional Encoder
我们采用金字塔结构为我们的编码器遵循大多数以前的工作 [80,5,19]。对于编码器中的构建块,我们采用了与ViT [17,80] 相似的结构,但不同的是,我们不使用自我注意机制,而是设计了一种新颖的多尺度卷积注意 (MSCA) 模块。如图2 (a) 所示,MSCA包含三个部分: 用于聚合局部信息的深度卷积,用于捕获多尺度上下文的多分支深度条带卷积,以及用于建模不同通道之间关系的1 × 1卷积。1 × 1卷积的输出直接用作attention weights,以重新加权MSCA的输入。
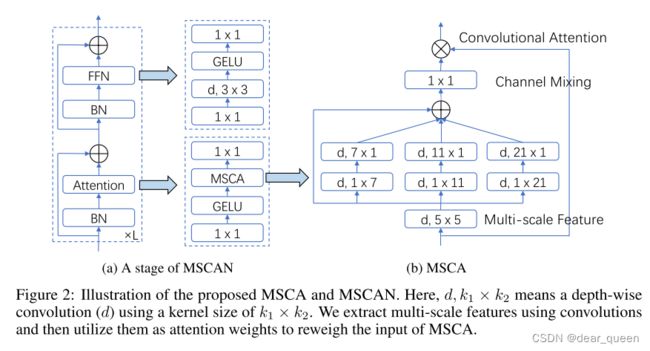
总结
首先该结构与transformer的结构一致(a)中最左边的图,与之不同的是架构attention做了替换,采用MSCA模块。MSCA主要包含三个部分:
(1)depth-wise卷积:用于聚合局部信息;
(2)多分支dw卷积:用于捕获多尺度上下文信息;
(3)1×1卷积:用于通道维度进行相关性建模
,该模块是采用多分支结构。
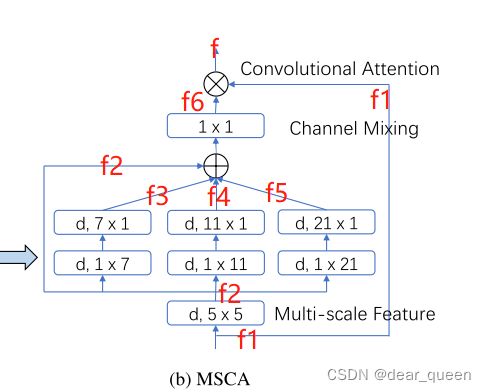
首先输入特征图f1,f1进行一个深度卷积操作,卷积核为5×5,此时特征图记作f2,f2又分为4个分支,分别:(1)不操作f2,;(2、3、4)采用1×k,k×1的形式,进行大卷积(类似论文62提到的),所得特征图分别记作f3、f4、f5。将f2、f3、f4、f5进行add操作得到特征图为f6,随后f6与f1做点乘得到特征图f。
关于MSCA的实现code参考如下。
class AttentionModule(BaseModule):
def __init__(self, dim):
super().__init__()
self.conv0 = nn.Conv2d(dim, dim, 5, padding=2, groups=dim)
self.conv0_1 = nn.Conv2d(dim, dim, (1, 7), padding=(0, 3), groups=dim)
self.conv0_2 = nn.Conv2d(dim, dim, (7, 1), padding=(3, 0), groups=dim)
self.conv1_1 = nn.Conv2d(dim, dim, (1, 11), padding=(0, 5), groups=dim)
self.conv1_2 = nn.Conv2d(dim, dim, (11, 1), padding=(5, 0), groups=dim)
self.conv2_1 = nn.Conv2d(dim, dim, (1, 21), padding=(0, 10), groups=dim)
self.conv2_2 = nn.Conv2d(dim, dim, (21, 1), padding=(10, 0), groups=dim)
self.conv3 = nn.Conv2d(dim, dim, 1)
def forward(self, x):
u = x.clone()
attn = self.conv0(x)
attn_0 = self.conv0_1(attn)
attn_0 = self.conv0_2(attn_0)
attn_1 = self.conv1_1(attn)
attn_1 = self.conv1_2(attn_1)
attn_2 = self.conv2_1(attn)
attn_2 = self.conv2_2(attn_2)
attn = attn + attn_0 + attn_1 + attn_2
attn = self.conv3(attn)
return attn * u
ps:不了解dw卷积也就是深度卷积的可以看看mobilenet网络结构深度可分离。
数学上,我们的MSCA可以写成:

其中F表示输入特征。Att和Out分别是注意力图和输出。![]()
是逐元素矩阵乘法运算。DW-Conv表示深度卷积,Scalei,i ∈ {0,1,2,3},表示图2(b) 中的第i个分支。Scale0是身份连接。在 [62] 之后,在每个分支中,我们使用两个深度条带卷积来近似具有大核的标准深度卷积。这里,每个分支的内核大小分别设置为7、11和21。我们选择深度带状卷积的原因有两个。一方面,条带卷积是轻量级的。要模仿内核大小为7 × 7的标准2D卷积,我们只需要一对7 × 1和1 × 7卷积。另一方面,在分割场景中有一些条状物体,例如人和电线杆。因此,条带卷积可以是网格卷积的补充,并有助于提取条带状特征 [62,29]。

堆叠一系列构建块即诞生所提的卷积编码器,称为MSCAN。对于MSCAN,我们采用了一种通用的层次结构,该结构包含四个阶段,其空间分辨率H 4 × W 4,H 8 × W 8,H 16 × W 16和H 32 × W 32。(这里跟swin transformer的结构很相似了,如果不记得可以看看https://blog.csdn.net/dear_queen/article/details/126942782?spm=1001.2014.3001.5501在这里总结过)
这里,H和W分别是输入图像的高度和宽度。每个阶段都包含一个下采样块和一堆如上所述的构建块。下采样块具有stride 2和内核大小3 × 3的卷积,然后是批归一化层 [35]。请注意,在MSCAN的每个构建块中,我们使用批归一化而不是层归一化,因为我们发现批归一化对分段性能的效果更好。

提议的SegNeXt不同大小的详细设置。在此表中,“e.r.” 表示前馈网络中的扩展比率。“C” 和 “l” 分别是通道和构建块的数量。“解码器尺寸” 表示解码器中的MLP尺寸。“参数” 是在ad20k数据集上计算的 [98]。由于不同数据集中的类别数量不同,因此参数的数量可能会略有变化。
我们设计了四个大小不同的编码器模型,分别命名为MSCAN-T、MSCAN-S、MSCAN-B和MSCAN-L。相应的整体分割模型分别称为SegNeXt-T,SegNeXt-S,SegNeXt-B,SegNeXt-L。详细的网络设置显示在table2。
3.2 decoder
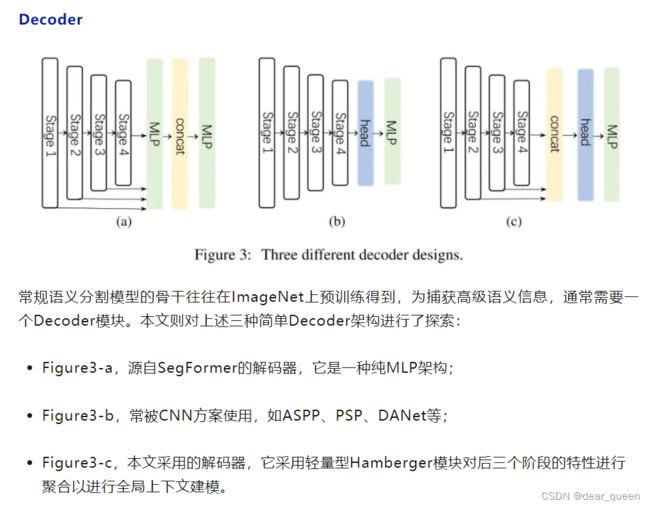
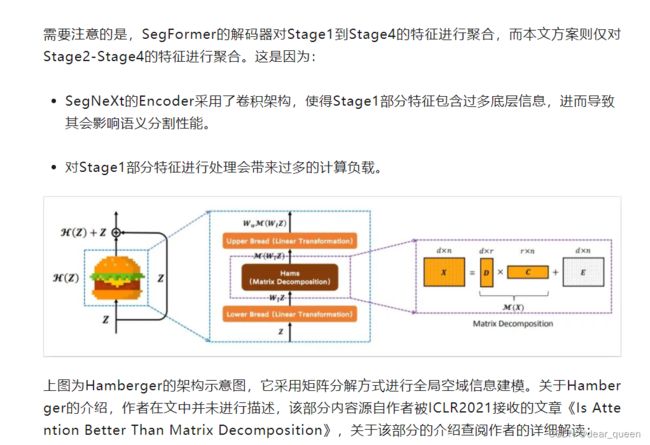
在分割模型 [80,96,5] 中,编码器主要在ImageNet数据集上进行预训练。为了捕获高级语义,通常需要解码器,并将其应用于编码器。在这项工作中,我们研究了三个简单的解码器结构,如图3所示。在SegFormer [80] 中采用的第一个是纯粹的基于MLP的结构。第二种主要采用基于CNN的模型。在这种结构中,编码器的输出直接用作沉重的解码器头的输入,例如ASPP [5],PSP [94] 和DANet [19]。最后一个是我们SegNeXt中采用的结构。我们汇总了最后三个阶段的特征,并使用轻量级Hamburger [21] 来进一步建模全局环境。结合我们强大的卷积编码器,我们发现使用轻量级解码器可以提高性能计算效率。

与SegFormer的解码器汇总从stage1到stage4的功能不同,我们的解码器仅接收来自最后三个阶段的功能,这是毫无价值的。这是因为我们的SegNeXt基于卷积。第1阶段的功能包含过多的低级信息,从而损害了性能。此外,阶段1的操作带来了沉重的计算开销。在我们的实验部分中,我们将证明我们的卷积SegNeXt的性能要比最近的基于transformer的最先进的SegFormer [80] 和HRFormer [88] 好得多。
4 Experiments
数据集。我们在七个流行的数据集上评估我们的方法,包括ImageNet-1K [15],ADE20K [98],Cityscapes [13],Pascal VOC [18],Pascal Context [58],COCO-Stuff [3] 和iSAID [76]。ImageNet [15] 是最著名的图像分类数据集,其中包含1,000类别。与大多数分割方法类似,我们使用它来预先训练我们的mcan编码器。ADE20K [98] 是一个具有挑战性的数据集,其中包含150语义类。它由训练,验证和测试一下集中的20,210/2,000/3,352图像组成。Cityscapes [13] 主要关注cityscapes,包含5000个19个类别的高分辨率图像。有2,975/500/1,525图像分别用于训练,验证和测试。Pascal VOC [18] 涉及20个前景类和一个背景类。增强后,它分别具有10、582/1、449/1、456个图像用于训练,验证和测试。Pascal Context [58] 包含59个前景类和一个背景类。训练集和验证集分别包含4,996和5,104图像。COCO-Stuff [3] 也是一个具有挑战性的基准,它包含172个语义类别和总共164k个图像。iSAID [76] 是一个大规模的航空图像分割基准,它包括15个前景类和一个背景类。其训练、验证和测试一下集分别涉及1,411/458/937图像。
实施细节。我们使用Jittor [31] 和Pytorch [61] 进行实验。我们的实现分别基于timm (Apache-2.0) [77] 和mmsegmentation (Apache-2.0) [12] 库进行分类和分割。我们分割模型的所有编码器都是在ImageNet-1K数据集上预先训练的 [15]。我们分别采用Top-1准确性和平均交集 (mIoU) 作为分类和分割的评估指标。所有模型都在具有8个RTX 3090 gpu的节点上训练。
对于ImageNet预训练,我们的数据增强方法和训练设置与DeiT相同 [70]。对于分割实验,我们采用了一些常见的数据增强,包括随机水平翻转,随机缩放 (从0.5到2) 和随机裁剪。Cityscapes数据集的批处理大小设置为8,所有其他数据集的批处理大小设置为16。AdamW [54] 用于训练我们的模型。我们将初始学习率设置为0.00006,并采用多学习率衰减策略。我们为ad20k、cityscape和iSAID数据集训练模型160K次迭代,为COCO-Stuff、Pascal VOC和Pascal上下文数据集训练80K次迭代。测试一下过程中,我们同时使用单尺度 (SS) 和多尺度 (MS) 翻转测试一下策略进行公平比较。更多细节可以在我们的补充材料中找到。
4.1 Encoder Performance on ImageNet
ImageNet预训练是训练分割模型的常用策略 [94,6,80,88,5]。在这里,我们将MSCAN的性能与最近流行的基于CNN和基于transformer的分类模型进行了比较。如选项卡所示。3,我们的mcan取得了比最近的最先进的基于CNN的方法ConvNeXt更好的结果 [52],并且优于流行的基于变压器的方法,如Swin变压器 [51] 和MiT,SegFormer [80] 的编码器。
4.2 Ablation study
MSCA设计中的消融。我们在ImageNet和ADE20K数据集上对MSCA设计进行了消融研究。K × K分支包含深度1 × K卷积和K × 1深度卷积。1 × 1 conv表示通道混合操作。注意力是指元素乘积,它使网络获得自适应能力。结果显示在选项卡中。6.我们可以发现每个部分都有助于最终的表现。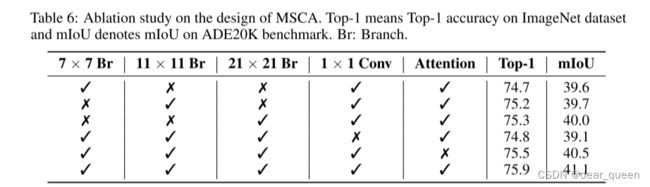
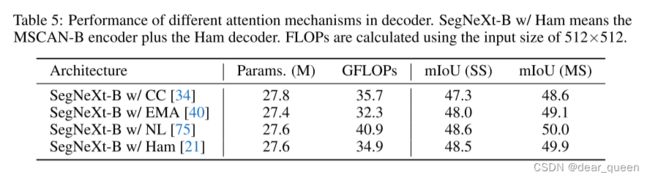
解码器的全局上下文。解码器在从分割模型的多尺度特征集成全局上下文中起着重要作用。在这里,我们研究了不同的全局上下文模块对解码器的影响。如大多数以前的作品 [75,19] 所示,基于注意力的解码器比金字塔结构 [94,5] 为cnn实现更好的性能,因此我们仅显示使用基于注意力的解码器的结果。具体来说,我们展示了4种不同类型的基于注意力的解码器的结果,包括具有O(n2) 复杂度的非局部 (NL) 注意 [75] 和具有O(n) 复杂度的CCNet [34],EMANet [40] 和HamNet [21]。如选项卡所示。5、Ham实现了复杂度和性能之间的最佳权衡。因此,我们在解码器中使用Hamburger [21]。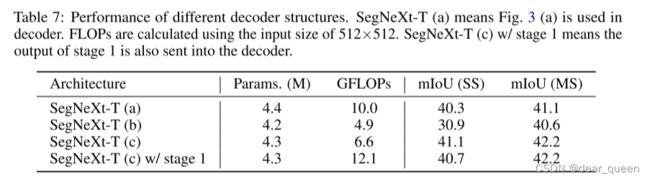
解码器结构。与图像分类不同,分割模型需要高分辨率输出。我们对用于分割的三种不同的解码器设计进行了烧蚀,所有这些都在图3中示出。相应的结果在Tab中列出。7.我们可以看到SegNeXt © 达到了最佳性能,并且计算成本也很低。
我们的MSCA的重要性。在这里,我们进行实验来证明MSCA对于分割的重要性。作为比较,我们遵循VAN [24],并将MSCA中的多个分支替换为具有大内核的单个卷积。如选项卡所示。8和Tab。3,我们可以观察到,尽管两个编码器的性能在ImageNet分类中接近,但SegNeXt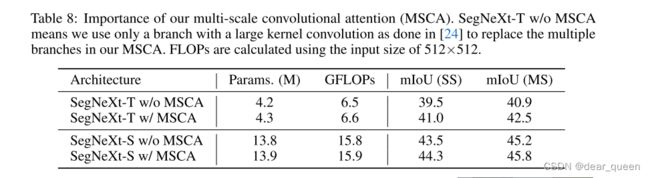
后续实验可以看原文。
下面主要看下decoder部分:
后续将继续读下这篇论文,更深入理解