基于YOLOV5和AIDLUX实现目标跟踪和人流统计
1.AI 项目开发及 Aidlux 的特点
我们先来梳理一下AI项目开发的整体流程:

由上图可知,在实际项目中,一般先由数据工程师对于数据标注,再由算法工程师进行算法训
练。(比如对于人体框进行标注,由算法工程师训练人体检测模型)因为用到不同的算法设备
上,再由嵌入式工程师进行算法适配,和视频结构化平台的开发。针对不同的图像进行算法处
理,得到结构化的数据信息。(比如在 Nvidia 边缘设备使用,将人体检测模型在设备上适配,
并开发视频结构化平台,对于视频流进行检测处理,得到人体检测框的 Box 信息)再将算法处
理后的数据,对接到系统软件工程师,进行业务平台业务功能的处理。(比如将人体检测的检
测框信息,对接给数据中台上,设置一些业务功能,例如越界识别等)最后对接到客户系统
中,并交给运维工程师进行现场落地部署。(比如将越界人员的信息,对接到客户大屏上,进
行展示)这里的数据处理和算法开发,很多算法岗的同学都会比较了解,因为平时工作中,都
是使用 Python 来进行开发的。而在模型移植、视频结构化部分,目前市面上基本都是采用
C++ 的方式。不过训练营主要采用一种更便捷的方式, Aidlux 平台,即模型移植也采用
Python 的方式。且大家可以基于一台安卓手机,也可以基于一台 AidBox 边缘设备都可以进行
开发,并且无缝衔接。那么为什么 Aidlux 可以进行 Python 版本的 AI 模型开发和移植呢?
1.1 跨平台应用的系统
AIdlux 主打的是基于 ARM 架构的跨生态(
Android/ 鸿蒙 +Linux )一站式 AIOT 应用开发平
台。用比较简单的方式理解,我们平时编写训练模型,测试模型的时候,常用的是
Linux/window 系统。而实际应用到现场的时候,通常会以几种形态: GPU 服务器、嵌入式设
备(比如 Android 手机、人脸识别闸机等)、边缘设备。 GPU 服务器我们好理解,而 Android
嵌入式设备的底层芯片,通常是 ARM 架构。而 Linux 底层也是 ARM 架构,并且 Android 又是
基于 Linux 内核开发的操作系统,两者可以共享 Linux 内核。因此就产生了从底层开发一套应
用系统的方式,在此基础上同时带来原生 Android 和原生 Linux 使用体验。
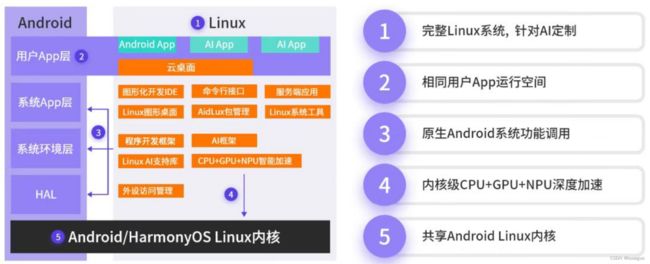
因此基于 ARM 芯片,开发了 Aidlux 平台,可以在安卓手机上直接下载 Aidlux 使用。同时基于
ARM 芯片,比如高通骁龙的 855 芯片和 865 芯片,也开发了 AidBox 边缘设备,提供 7T OPS 和
15TOPS 算力,可以直接在设备上使用。

而使用这些设备平台开发的时候,和在 Linux 上开发都是通用的,即 Linux 上开发的 Python 代
码,可以在安卓手机、边缘设备上转换后使用。而使用这些设备平台开发的时候,和在 Linux
上开发都是通用的,即 Linux 上开发的 Python 代码,可以在安卓手机、边缘设备上转换后使
用。
2.基于YOLOV5和AIDLUX实现目标跟踪和人流统计
假设你已经完成了yolov5模型的训练。并将Yolov 5 +⽬ 标追踪Bytetrack结合,进⾏了2 种算法的串联。⽽有了检测和追踪的结合,我们就可以完成AI项⽬中的很多功能了。⽐如越界识别,判断在某块区域的监测过程中,是否有⼈越过这个区域。这个在很多智能 相机中,⽐如海康、⼤华的相机中,常常会内置这个功能,所以应⽤的场景⾮常多。再⽐如客流统计,通过对⼈流的追踪,判断越过某条统计线段,进出有多少个⼈。
场景 1 :⼤型商超客流统计
当然,⼈流统计也可以通过区域统计。
场景2 :区域客流统计
再⽐如⻋辆违停检测,统计停靠在某个区域的⻋辆,停留的时间,判断是否违规停放,还只是临时停 放。
当然有的同学也会发现,上⾯使⽤的⽬标检测和⽬标追踪算法功能原理上是⼀样的,只是检测的⽬标和 设置的业务功能不相同。⽐如越界识别、客流统计,检测的⽬标,主要是⼈体。⻋辆违停统计,检测的 ⽬标主要是⻋辆。两种功能,检测的⽬标不同,设置的业务逻辑也不同。
⽽本次训练营,主要针对越界识别的功能,进⾏讲解和实现,并且在最后的作业,会实现⼀个⼈流统计
1 越界监测区域绘制
###人流计数识别功能实现 ###
# 1.绘制统计人流线
lines = [[186,249],[1235,366]]
cv2.line(res_img,(186,249),(1235,366),(255,255,0),3) 2 越界识别功能实现
2 . 1 ⼈体检测监测点调整
# 2.计算得到人体下方中心点的位置(人体检测监测点调整)
pt = [tlwh[0]+1/2*tlwh[2],tlwh[1]+tlwh[3]] 2 . 2 ⼈体状态追踪判断
# 3. 人体和违规区域的判断(人体状态追踪判断)
track_info = is_passing_line(pt, lines)
if tid not in track_id_status.keys():
track_id_status.update( {tid:[track_info]})
else:
if track_info != track_id_status[tid][-1]:
track_id_status[tid].append(track_info) 2 . 3 双向 越界⾏为判断
# 4. 判断是否有track_id穿越统计线段
# 当某个track_id的状态,上一帧是-1,但是这一帧是1时,说明穿过线段了
if track_id_status[tid][-1] == 1 and len(track_id_status[tid]) >1:
# 判断上一个状态是否是-1,是否的话说明穿过线段,为了防止继续判别,随机的赋了一个3的值
if track_id_status[tid][-2] == -1:
track_id_status[tid].append(3)
count_person +=1
elif track_id_status[tid][-1] == -1 and len(track_id_status[tid]) >1:
# 判断上一个状态是否是1,是否的话说明穿过线段,为了防止继续判别,随机的赋了一个3的值
if track_id_status[tid][-2] == 1:
track_id_status[tid].append(3)
count_person_r +=1 3 越界识别&系统告警
3 . 1 新建喵提醒账号
当有了告警信息和告警图⽚后,⼀般在实际应⽤的项⽬业务系统中,会出现⼀个告警弹窗。⽐如某个位 置出现告警信息,安排⼯作⼈员前去查看。当然我们训练营没有业务系统,为了更加贴近实际,在本训 练营中,则采⽤⼀种简单的⽅式,当然也⽐较实⽤,即通过微信“喵提醒”的⽅式。在后⾯⼤作业,⼈流 统计分析中,也会使⽤到。
3 . 1 新建喵提醒账号
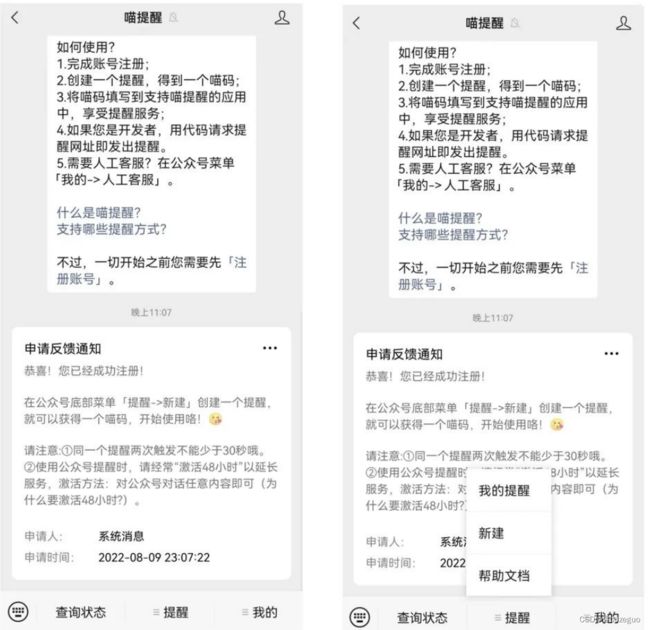
( 1 )注册并创建喵提醒账号
关注“喵提醒”的公众账号,点击回复消息中最后的“注册账号”,填写⼿机号码进⾏注册,注册后跳到后 台⻚⾯可以看到,今天还能收到提醒100 条信息,基础上够⽤的。

( 2 )注册完成后,回到公众号⻚⾯,点击菜单栏的“提醒”,并选择“新建”。
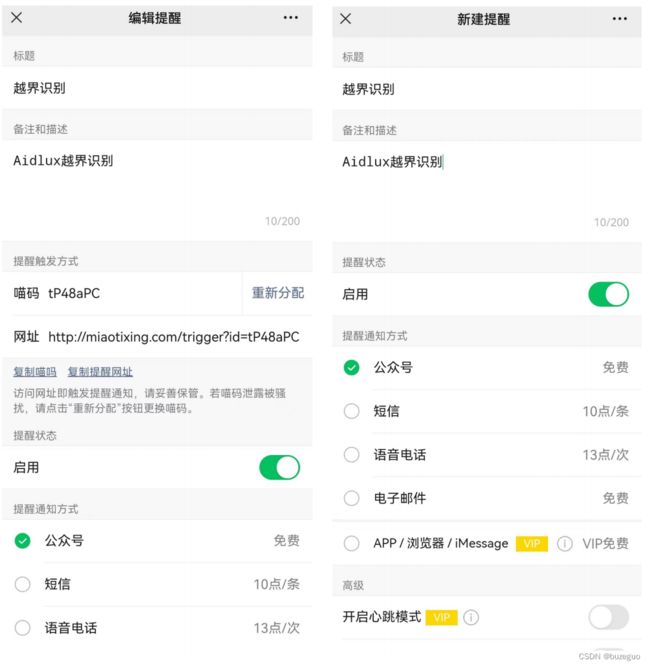
( 3 )填写新建提醒的相关信息,点击最后的“保存”,⻚⾯会⾃动加载,中间的部分会跳出⾃⼰账号专属 对应的“喵码”和“⽹址”,后⾯的代码中主要⽤到喵码的功能。
3 . 2 喵提醒代码测试
import requests
import time
# 填写对应的喵码
id = '******'
# 填写喵提醒中,发送的消息,这里放上前面提到的图片外链
text = "有人越界识别!!"
ts = str(time.time()) # 时间戳
type = 'json' # 返回内容格式
request_url = "http://miaotixing.com/trigger?"
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47'}
result = requests.post(request_url + "id=" + id + "&text=" + text + "&ts=" + ts + "&type=" + type,
headers=headers)
4 . 2 双向 ⼈流统计代码实
# aidlux相关
from cvs import *
import aidlite_gpu
from utils import detect_postprocess, is_passing_line, preprocess_img, draw_detect_res, scale_coords,process_points,is_in_poly#,isInsidePolygon
import cv2
# bytetrack
from track.tracker.byte_tracker import BYTETracker
from track.utils.visualize import plot_tracking
import requests
import time
# 加载模型
model_path = '/home/lesson4_codes/aidlux/yolov5n_best-fp16.tflite'
in_shape = [1 * 640 * 640 * 3 * 4]
out_shape = [1 * 25200 * 6 * 4]
# 载入模型
aidlite = aidlite_gpu.aidlite()
# 载入yolov5检测模型
aidlite.ANNModel(model_path, in_shape, out_shape, 4, 0)
tracker = BYTETracker(frame_rate=30)
track_id_status = {}
cap = cvs.VideoCapture("/home/lesson4_codes/aidlux/video.mp4")
frame_id = 0
count_person = 0
count_person_r = 0
while True:
frame = cap.read()
if frame is None:
###相机采集结束###
print('相机采集结束')
### 统计打印人流数量 ###
#填写对应的喵码
id = '******'#写你自己
# 填写喵提醒中,发送的消息,这里放上前面提到的图片外链
text = "人流统计数量为:" + str(count_person + count_person_r)
ts = str(time.time()) # 时间戳
type = 'json' # 返回内容格式
request_url = "http://miaotixing.com/trigger?"
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.67 Safari/537.36 Edg/87.0.664.47'}
result = requests.post(request_url + "id=" + id + "&text=" + text + "&ts=" + ts + "&type=" + type,headers=headers)
break
frame_id += 1
if frame_id % 3 != 0:
continue
# 预处理
img = preprocess_img(frame, target_shape=(640, 640), div_num=255, means=None, stds=None)
# 数据转换:因为setTensor_Fp32()需要的是float32类型的数据,所以送入的input的数据需为float32,大多数的开发者都会忘记将图像的数据类型转换为float32
aidlite.setInput_Float32(img, 640, 640)
# 模型推理API
aidlite.invoke()
# 读取返回的结果
pred = aidlite.getOutput_Float32(0)
# 数据维度转换
pred = pred.reshape(1, 25200, 6)[0]
# 模型推理后处理
pred = detect_postprocess(pred, frame.shape, [640, 640, 3], conf_thres=0.4, iou_thres=0.45)
# 绘制推理结果
res_img = draw_detect_res(frame, pred)
# 目标追踪相关功能
det = []
# Process predictions
for box in pred[0]: # per image
box[2] += box[0]
box[3] += box[1]
det.append(box)
if len(det):
# Rescale boxes from img_size to im0 size
online_targets = tracker.update(det, [frame.shape[0], frame.shape[1]])
online_tlwhs = []
online_ids = []
online_scores = []
# 取出每个目标的追踪信息
for t in online_targets:
# 目标的检测框信息
tlwh = t.tlwh
# 目标的track_id信息
tid = t.track_id
online_tlwhs.append(tlwh)
online_ids.append(tid)
online_scores.append(t.score)
# 针对目标绘制追踪相关信息
res_img = plot_tracking(res_img, online_tlwhs, online_ids, 0,0)
###人流计数识别功能实现 ###
# 1.绘制统计人流线
lines = [[186,249],[1235,366]]
cv2.line(res_img,(186,249),(1235,366),(255,255,0),3)
# 2.计算得到人体下方中心点的位置(人体检测监测点调整)
pt = [tlwh[0]+1/2*tlwh[2],tlwh[1]+tlwh[3]]
# 3. 人体和违规区域的判断(人体状态追踪判断)
track_info = is_passing_line(pt, lines)
if tid not in track_id_status.keys():
track_id_status.update( {tid:[track_info]})
else:
if track_info != track_id_status[tid][-1]:
track_id_status[tid].append(track_info)
# 4. 判断是否有track_id穿越统计线段
# 当某个track_id的状态,上一帧是-1,但是这一帧是1时,说明穿过线段了
if track_id_status[tid][-1] == 1 and len(track_id_status[tid]) >1:
# 判断上一个状态是否是-1,是否的话说明穿过线段,为了防止继续判别,随机的赋了一个3的值
if track_id_status[tid][-2] == -1:
track_id_status[tid].append(3)
count_person +=1
elif track_id_status[tid][-1] == -1 and len(track_id_status[tid]) >1:
# 判断上一个状态是否是1,是否的话说明穿过线段,为了防止继续判别,随机的赋了一个3的值
if track_id_status[tid][-2] == 1:
track_id_status[tid].append(3)
count_person_r +=1
cv2.putText(res_img,"-1 to 1 person_count:"+ str(count_person),(50,50),cv2.FONT_HERSHEY_SIMPLEX,1,(255,0,255),2)
cv2.putText(res_img,"1 to -1 person_count:"+ str(count_person_r),(50,100),cv2.FONT_HERSHEY_SIMPLEX,1,(255,0,255),2)
cvs.imshow(res_img)效果: