kubernetes
目录
一、容器云发展及主要内容
1、云平台计算,交付标准(iaas-----openstack)
2、平台即服务(PAAS)
3.软件及服务(SAAS)
特点
二、内容
三、kubernetes集群架构与组件
基本组件
(1)Pod(最小的资源单位)
(2)初始化容器(initcontainers)
(3)业务容器(Maincontainer)
(4)服务发现(Service同一组Pod的访问策略)
(5)存储
(6)调度器(Scheduler)
(7)label
(8)Namespaces
(9)Annotations
(10)集群安全
(11)HELM(K8S 中包的管理工具)
四、K8S架构
1.master组件
(1)kube-apiserver
(2)kube-controller-manager(控制器管理中心-定义资源类型)
2.node组件
3.用户访问流程
五、kubernetes
1.准备环境
(1)将桥接的 IPv4 流量传递到 iptables 的链
(2)docker安装
2.所有节点配置K8S源
(1)安装 kubelet、kubeadm、kubectl 组件
(2)master节点制作
(3)创建K8S组件的家目录 提权(必做)
(4)复制、记录申请加入集群命令
3.重新生成token
4.上传 kube-flannel.yaml 或者直接下载(直接下载需要改动参数)
(1)直接上传
(2)使用在线源下载
(3)调整参数
(4)给node节点打上“node”的标签
5.验证
一、容器云发展及主要内容
1、云平台计算,交付标准(iaas-----openstack)
国内:阿里云—华为云(振兴杯)百度云(私有云) 微软云 其他云
国外:AWS
2、平台即服务(PAAS)
例如:新浪云(号称免运维)
用户下单→下单到sina运维,进行坏境构建,平台级的运维
迭代:产生出来很多运维工具,例如ansible(幂等性)、saltstack、jenkins,这些运维工具可以自动化创建一些环境。
但是,不同环境的要求不一样,需要考虑、解决各种环境匹配、兼容问题
diocker统一了运行环境、发布方式、封装方式
同时,docker→自动构建运行环境封装体→docker成为这一代PAAS的运行环境标准
容器集群化管理
资源管理器/资源管理框架(管理工具):
①早期是mesos (Apache基金会)早期只作为资源管理平台,开源、分布式的管理框架,后来被推特看上,做为基础管理平台,大规模盛行。
②2019年推特宣布不用mesos、而全部使用kubernetca。
③mesos 官方公布,可以在平台上管理k8: (borge)
但是k8:与底层虚拟化相性很简单,未必需要多一步使用mesos
④docker Sw&Lm : docker 父公司的产品,也是一种docker 集群化管理的解决方案
优势:轻量
但是相对于K8s而言,实现的功能还是比较少,例如k8s的
滚动更新、回滚,可以实现,但是很复杂,除此之外大规模集群的使用和管理还是很强大的
⑤kubernetes稳定、适合生产、全面,成为了主要的解决方案→谷歌
kubernetes的名字来自希腊语,意思是“舵手”或“领航员”, K8s是将8个字母"ubernete"替换为“8"的缩写。
mesos + zk + marathon→资源管理的架构(目前使用mesos产品的主流搭配)
3.软件及服务(SAAS)
直接使用成品(直接访问服务端)
Kubernetes Google 10年容器化基础架构→borg架构(内部资源管理器)
随着docker 流行,Borg 派出几个内部工程师,使用go语言以Borg系统设计思路
设计了一款新的资源管理系统→kubernetes ,并且开源贡献给了容器基金会→当前的标准
特点
①轻量级
一些解释性语言:例如Python/JavaScript / Perl /Shell,效率较低,占用内存资源较多。
使用go语言→编译型语言,语言级别支持进程管理,不需要人为控制,所以以go开发的资源消耗占用资源小。
[List-watch] + informer 二级缓存
②开源
③自我修复(控制器控制pod,保证pod可以维持所期望的副本数量3)
scale 副本集
在节点故障时“重新启动”失败的容器,替换和重新部署,保证预期的副本数量;杀死健康检查失败的容器,并且在未准备好之前不会处理客户端请求,确保线上服务不中断。
对异常状态的容器进行重建(先创建、再删除),目的是保证业务线不中断。
节点上的pod无限重启→故障项
④弹性伸缩(自动)
手动弹性伸缩(针对于pod),当I/0读/写、磁盘、内存的压力(单个pod) > 80%,修改replicasets :
3→4
更新一下nginx. Yml
自动: Yml →阈值cpu使用率> 80%→触发扩容pod (CPU使用上限,docker-cgroup k8s → 1.limit、2.configmap-配置文件)
使用命令、UI或者基于CPU使用情况自动快速扩容和缩容应用程序实例,保证应用业务高峰并发时的高可用性;业务低峰时回收资源,以最小成本运行服务。
弹性→人为只要指定规则,满足条件时,就会自动触发 扩容或缩容的操作
伸缩→扩容和缩容(节点 应用类型nginx)
⑤ 自动部署和回滚
打好容器的镜像
一条指令就可以自动部署
K8S采用滚动更新策略更新应用,一次更新一个Pod,而不是同时删除所有Pod,如果更新过程中出现问题,将回滚更改,确保升级不会影响业务。
⑥ 服务发现(类比于docker中的-p )和负载均衡
⑦ 机密(加密配置)和(普通)配置管理(secret→安全/认证加密性的数据 configmap→例如配置文件)
管理机密数据和应用程序配置,而不需要把敏感数据暴露在镜像里,提高敏感数据安全性。并可以将一些常用的配置存储在K8S中,方便应用程序使用。
⑧ 存储编排(静态、动态)
静态:volume (docker run -itd -v /tmp:/tmp tomcat:latest /bin/bash )→挂载在本地
动态:挂载外部存储系统,无论是来自本地存储,公有云(如AWS),还是网络存储(如NFS、GlusterFS、Ceph)都作为集群资源的一部分使用,极大提高存储使用灵活性。
⑨ 批处理
提供一次性任务(job),定时任务(crontab);满足批量数据处理和分析的场景
目的:
K8S 目标是为了让部署容器化应用、管理容器集群资源更加简单高效
二、内容
资源清单(yml):资源 掌握资源清单的语法(yml) 编写 Pod(yml) 掌握 Pod 的生命周期
Pod 控制器:掌握各种控制器的特点以及使用定义方式
服务发现:掌握 SVC(service) 原理及其构建方式(service 的yml)
存储:掌握多种存储类型(静态、动态)的特点 并且能够在不同环境中选择合适的存储方案(有自己
的理解-有状态服务/无状态的服务)
调度器(Scheduler):掌握调度器原理(预选和优选) 能够根据要求把Pod 定义到想要的节点运行(selector)
安全:集群的认证 鉴权 访问控制 原理及其流程
三、kubernetes集群架构与组件
基本组件
(1)Pod(最小的资源单位)
一个pod 会封装多个容器组成一个子节点的运行环境 (最小单元,容器的种类3+)
最小部署单元
一组容器的集合(基础容器 + 初始化容器+ 业务容器(主应用容器+挂斗/副容器)
PS:基础容器
维护整个Pod网络和存储空间
node节点中操作
启动一个实例时,k8s会自动启动一个init容器,然后启动基础容器最后启动主容器
(2)初始化容器(initcontainers)
Init容器必须在应用程序容器启动之前运行完成,而应用程序容器是并行运行的,所以Init容器能够提供了一种简单的阻塞或延迟应用容器的启动的方法。
Init容器与普通的容器非常像,除了以下两点
① Init容器总是运行到成功完成为止
② 每个Init容器都必须在下一个Init容器启动之前成功完成
如果 Pod 的Init容器失败,k8s 会不断地重启该Pod(为了让init容器可以启动完成),直到 Init容器成功为止。然而,如果 Pod对应的重启策略(restartPolicy)为Never,不会重新启动。
(3)业务容器(Maincontainer)
1)往往是并行启动,但是也有例外情况→看控制器类型(参照物Pod)
2)业务容器并行启动→Pod内部的多个业务容器
一个Pod中的容器共享网络命名空间(基础容器提供的pause)
概念:Pod是短暂的 (叙述的是其生命周期)
① 副本集
② 自动修复
③ 弹性伸缩
④ 探针
⑤ 回滚
⑥ service的服务发现和kube-proxy的负载均衡
以上共同保障Pod的可用性和健康性→保障业务正常运行
Pod 控制器
| ReplicaSet(RS子控制器) | 确保期望的Pod副本数量,直接控制pod的控制器类型 |
| Deployment | 无状态应用控制器(部署) 并行启动 |
| StatefulSet | 有状态应用部署,特性之一是 启动与关闭pod,都是有先后启动/关闭顺序的 依次启动与关闭 |
| DaemonSet | 确保所有Node运行相同服务/应用的一个Pod |
| Job | 一次性任务 |
| Cronjob | 定时任务 |
| ingress | 管理的是L7层的网络模式(HTTP/HTTPS流量) |
| PV PVC | 动态存储 |
ingress包含:nginx、Haproxy、traffic、istio、kong
(4)服务发现(Service同一组Pod的访问策略)
一组:通过相同标签的标签选择器关联在一起
1)通过service这个统一入口/定义的访问策略对外暴露服务的方式
K8S内部的Pod 通讯是以一组私有地址进行通讯的,所以默认情况下无法直接为客户端(服务、用户)提供访问
PS:以上解释的其实就是K8S→扁平化网络的默认通讯方式(二层局域网)
可以通过Service服务发现,把我们内部的pod资源暴露给客户端访问/发布出来(以暴露一个ip:端口的方式),让客户端可以通过这个IP:端口的形式访问到K8S内部的多个pod(通常意义上是一个应用的副本集)
Service 作为一组Pod 的统一访问出入口(定义一组Pod的访问策略),以RR分流算法进行负载均衡,把Pod中的应用服务暴露出来给客户端访问service →暴露方式是L4四层的
访问的方式是通过kube-proxy 匹配iptables功能进行转发的(四层)
k8s官方默认提供了四层的代理/负载均衡方式,而我们可以借助于官方后续支持的ingress-nginx 提供七层转发/负载均衡。
2)service
创建service需要ServiceController,EndpointController,kube-proxy,三大模块同时协作
serviceController 是控制service 来创建对应的Pod关联的规则的
endpointController 是定义后端pod的具体位置,也就是endpoint(upstream +consul的自动发现和更新)
kube-proxy 是用来定义具体的后端转发和分流规则的
以上组成了一个service所必要的功能
① ServiceController
当一个service对象状态发生变化的时候,Informer都会通知ServiceController,创建对应的服务
② EndpointController
主体:service pod
主体:endpoint对象
endpointcontroller 是:nginx的upstream(service endpoint) + consul中的发现、更新
EndpointController会同时订阅Service和Pod的增删事件。其功能如下
负责生成和维护所有endpoint对象的控制器
负责监听service和对应pod的变化
监听到service被删除,则删除和该service同名的endpoint对象
监听到新的service被创建,则根据新建service信息(YAML)获取相关pod列表,然后创建对应endpoint对象
监听到service被更新,则根据更新后的service信息获取相关pod列表,然后更新对应endpoint对象
监听到pod事件,则更新对应的service的endpoint对象,将podIp记录到endpoint中
③ kube-proxy
kube-proxy 负责service实现,实现了k8s内部service和外部node port到service的访问。
kube-proxy采用iptables的方式配置负载均衡,基于iptables的kube-proxy的主要职责包括两大块: 一块是侦听service更新事件,并更新service相关的iptables规则,一块是侦听endpoint更新事件,更新endpoint相关的iptables规则(如 KUBE-SVC-链中的规则),然后将包请求转入endpoint对应的Pod。
(5)存储
服务分类:
① 无状态服务:LVS (加入集群后,无特殊性需求--存储)
服务不依赖自身的状态,实例的状态数据可以维护在内存中。
任何一个请求都可以被任意一个实例处理。
不存储状态数据,实例可以水平拓展,通过负载均衡将请求分发到各个节点。
在一个封闭的系统中,只存在一个数据闭环。
通常存在于单体架构的集群中。
② 有状态服务:例如数据库(有特殊状态需求,例如:需要持久化、需要特定的数据支持)
服务本身依赖或者存在局部的状态数据,这些数据需要自身持久化或者可以通过其他节点恢复。
一个请求只能被某个节点(或者同等状态下的节点)处理。
存储状态数据,实例的拓展需要整个系统参与状态的迁移。
在一个封闭的系统中,存在多个数据闭环,需要考虑这些闭环的数据一致性问题。
通常存在于分布式架构中。
无状态服务:就是没有特殊状态的服务,各个请求对于服务器来说统一无差别处理,请求自身携带了所有服务端所需要的所有参数(服务端自身不存储跟请求相关的任何数据,不包括数据库存储信息
有状态服务:与之相反,有状态服务在服务端保留之前请求的信息,用以处理当前请求,比如session等
有状态:需要持久化,多次请求之间需要共享一些信息
无状态:一次性,不需要持久化的特殊状态,每次请求都是一条新的数据
有状态服务:指的是有独立状态的应用,例如mysql redis (数据库)
无状态服务:指的是没有独立状态的应用,例如nginx的部分功能
(6)调度器(Scheduler)
K8S会自动完成把一个新的pod 调度到对应的节点(预选/优选算法)
需要将pod创建的过程(比如创建到的节点位置)进行管理,
指定节点位置创建Pod(指定调度)
将不同的Pod创建在一个节点上(亲和)
将不同的Pod 创建在不同的节点上(反亲和)
根据需要,对pod进行节点组装等
(7)label
创建一个POD
1、编写pod yml文件(nginx资源怎么跑,用什么环境变量,需不需要资源限制,要调度到哪个节点) label:nginx
2、把pod 暴露出去,Service→通过yml文件定义 label:nginx
通过同一个label标签,进行关联,组合在一起
(8)Namespaces
命名空间,将对象逻辑上隔离
资源名称空间:网络、user、pid 、default
kube-system
kube-node-release
kube-public
(9)Annotations
注释(描述性信息,开发的配置文件模块,或者yml模板文件中会进行英文注释)
(10)集群安全
认证、鉴权、访问控制、原理及流程RBAC(鉴权方式)/CA(证书、密钥认证形式)
从搭建集群,就需要用到加密,CA认证
管理和控制,必须先通过认证/授权,才能进行管理
跑的一些应用,nginx、squid →需要一些访问控制策略
RBAC 认证 授权模块
(11)HELM(K8S 中包的管理工具)
类似linux里面yum
helm 安装 magodb
helm 模板、自定义
chart release
四、K8S架构
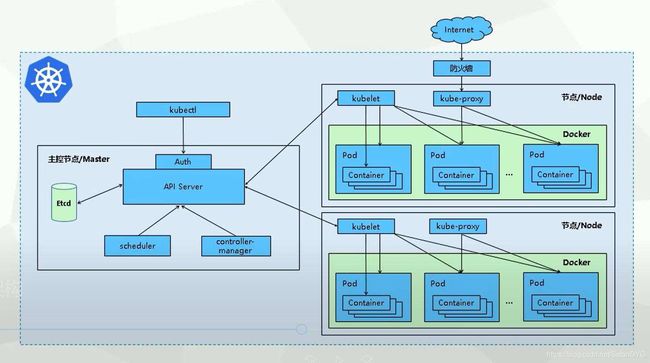
K8S 是一个典型的C/S架构,由master端和node端组成
1.master组件
(1)kube-apiserver
Kubernetes API,集群的统一入口,各组件协调者,以RESTful API提供接口 服务,所有对象资源的增删改查和监听操作都交给APIServer处理后再提交给 Etcd存储。
(2)kube-controller-manager(控制器管理中心-定义资源类型)
处理集群中常规后台任务,一个资源对应一个控制器,而ControllerManager 就是负责管理这些控制器的。
③ kube-scheduler 根据调度算法(预选/优选的策略)为新创建的Pod选择一个Node节点,可以任意部署,可以部署在同一个节点上,也可以部署在不同的节点上。
④ etcd
分布式键值存储系统(特性:服务自动发现)。用于保存集群状态数据,比如Pod、Service等对象信息
⑤ AUTH :认证模块
K8S 内部支持使用RBAC认证的方式进行认证
2.node组件
① kubelet
kubelet是Master在Node节点上的Agent,管理本机运行容器的生命周期,比如创 建容器、Pod挂载数据卷、下载secret、获取容器和节点状态等工作。kubelet将每个Pod转换成一组容器。
kubelet →先和docker 引擎进行交互→docker容器 (一组容器跑在Pod中)
② kube-proxy(四层) →对于七层的负载,k8s官方提供了一种解决方案→ingress-nginx
在Node节点上实现Pod网络代理,维护网络规则、pod之间通信和四层负载均衡工作。
默认会写入规则至iptables ,目前支持IPVS、同时还支持namespaces
③ docker或rocket
容器引擎,运行容器。
3.用户访问流程
用户需创建 nginx资源(网站/调度)kubectl →auth →api-server
基于yaml 文件的 kubectl create run / apply -f nginx.yaml(pod 一些属性,pod )
1)请求发送至master 首先需要经过apiserver(资源控制请求的唯一入口)
2)apiserver 接收到请求后首先会先记载在Etcd中
3)Etcd的数据库根据controllers manager(控制器) 查看创建的资源状态(有无状态化)
4) 通过controllers 触发 scheduler (调度器)
5) scheduler 通过验证算法() 验证架构中的nodes节点,筛选出最适合创建该资源,接着分配给这个节点进行创建
6)node节点中的kubelet 负责执行master给与的资源请求,根据不同指令,执行不同操作
7)对外提供服务则由kube-proxy开设对应的规则(代理)
8)container 容器开始运行(runtime 生命周期开始计算)
9)外界用户进行访问时,需要经过kube-proxy →service 访问到container (四层)
10)如果container 因故障而被销毁了,master节点的controllers 会再次通过scheduler 资源调度通过kubelet再次创建容器,恢复基本条件限制(控制器,维护pod状态、保证期望值-副本数量)
pod →ip 进行更改→service 定义统一入口(固定被访问的ip:端口)
项目对外访问流程
对外访问流程
七层(ingress-nginx/load balance)→ 四层 (kube-proxy→service)→访问策略入口(定义一组pod)
五、kubernetes
1.准备环境
swapoff -a 临时
sed -ri 's/.*swap.*/#&/' /etc/fstab 永久
free -g #验证,swap 必须为 0
vim /etc/hosts
192.168.22.228 master
192.168.22.168 node01
192.168.22.206 node02 ![]()

(1)将桥接的 IPv4 流量传递到 iptables 的链
cat > /etc/sysctl.d/k8s.conf << EOF
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
EOF
sysctl --system
(2)docker安装
1)安装依赖包
yum install -y yum-utils device-mapper-persistent-data lvm22)设置阿里云镜像源
cd /etc/yum.repos.d/
yum-config-manager --add-repo https://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo3)安装docker-ce 社区版
yum install -y docker-ce4)关闭防火墙
systemctl stop firewalld
systemctl disable firewalld
setenforce 0
vim /etc/selinux/config
SELINUX=disabled
systemctl start docker
systemctl enable docker
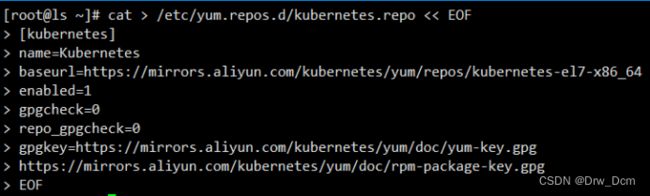
2.所有节点配置K8S源
cat > /etc/yum.repos.d/kubernetes.repo << EOF
[kubernetes]
name=Kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg
https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
(1)安装 kubelet、kubeadm、kubectl 组件
yum list|grep kube
yum install -y kubelet-1.21.3 kubeadm-1.21.3 kubectl-1.21.3
systemctl enable kubelet
systemctl start kubelet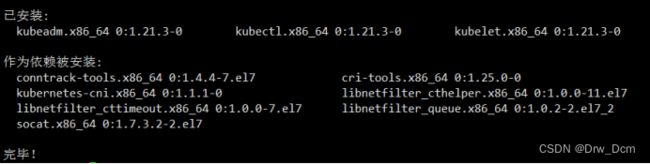

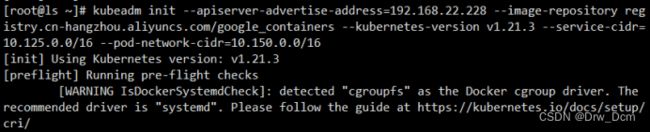
(2)master节点制作
kubeadm init \
--apiserver-advertise-address=192.168.22.228 \
--image-repository registry.cn-hangzhou.aliyuncs.com/google_containers \
--kubernetes-version v1.21.3 \
--service-cidr=10.125.0.0/16 \
--pod-network-cidr=10.150.0.0/16
如有问题:
kubeadm init --apiserver-advertise-address=192.168.22.228 --image-repository registry.cn-hangzhou.aliyuncs.com/google_containers --kubernetes-version v1.21.3 --service-cidr=10.125.0.0/16 --pod-network-cidr=10.150.0.0/16

(3)创建K8S组件的家目录 提权(必做)
mkdir -p $HOME/.kube
sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config
sudo chown $(id -u):$(id -g) $HOME/.kube/config
镜像批量导出,方便以后使用docker save `docker images | grep -v TAG | awk '{print $1":"$2}'`
-o name.tar.gz
(4)复制、记录申请加入集群命令
kubeadm join 192.168.22.228:6443 --token q4z0vx.jy5op60uxko19sou \
--discovery-token-ca-cert-hash sha256:8a84bd4d56404732591af2f6a200ed01d1256107a42114ed3c138368df9f28f8
3.重新生成token
若token 过期或丢失,需要先申请新的token 令牌
kubeadm token create列出token
kubeadm token list | awk -F" " '{print $1}' |tail -n 1然后获取CA公钥的的hash值
openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^ .* //'
替换join中token及sha256
kubeadm join 192.168.226.128:6443 --token zwl2z0.arz2wvtrk8yptkyz \
--discovery-token-ca-cert-hash sha256:e211bc7af55310303fbc7126a1bc7289f16b046f8798008b68ee01051361cf024.上传 kube-flannel.yaml 或者直接下载(直接下载需要改动参数)
(1)直接上传
kubectl apply -f kube-flannel.yml

(2)使用在线源下载
kubectl delete -f \
https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
kubectl apply -f \
https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
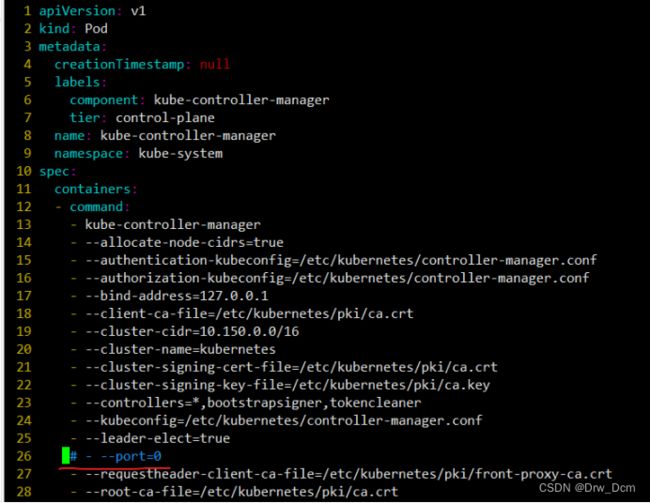
或者使用镜像包导入的方式完成flannel的部署(3)调整参数
cd /etc/kubernetes/mainfests/
vim kube-controller-manager.yaml
26行 --port=0 ”#“注释掉
vim kube-scheduler.yaml
#19行参数注释 - --port=0
如果不调整,使用kubect1 get cs的时候,会看到2个unhealthy
使用watch -n 1 kubectl get pods -A 等待pod ”running“
kubectl label node node01 node-role.kubernetes.io/node=node
kubectl label node node02 node-role.kubernetes.io/node=node

![]()

![]()

kubectl get nodes
(4)给node节点打上“node”的标签
kubectl label node node01 node-role.kubernetes.io/node=node
kubectl label node node02 node-role.kubernetes.io/node=node
kubectl get nodes
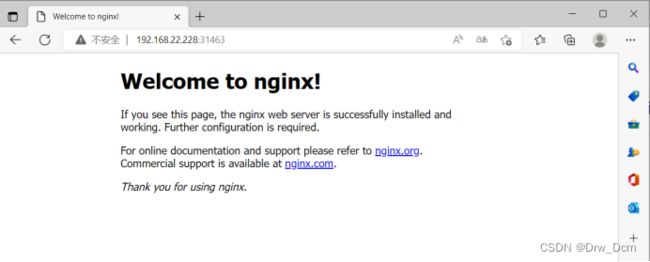
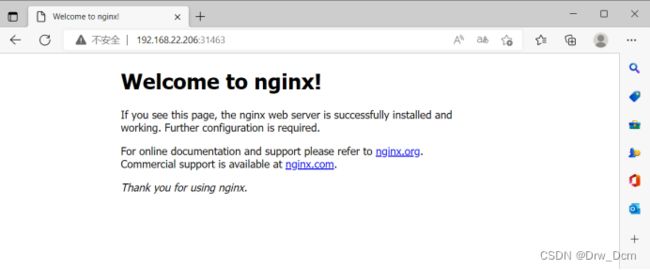
5.验证
部署服务
kubectl create deployment nginx --image=nginx
暴露端口
kubectl expose deployment nginx --port=80 --type=NodePort
kubectl get pods
kubectl get svc(service)
删除pod与svc
kubectl delete deploy/nginx
kubectl delete svc/nginx