【知识图谱论文】视觉语境对知识图谱真的有帮助吗?表征学习视角
- 文章题目:Is Visual Context Really Helpful for Knowledge Graph? A Representation Learning Perspective
- 发表期刊:ACM MM
- 等级:CCF A
摘要:
- 由于现实世界中的许多知识具有多模态的特性,视觉模态在知识图谱和多媒体领域引起了广泛的关注。然而,目前还不清楚视觉模态在多大程度上可以提高单模态模型的知识图任务的性能,并且将结构特征和视觉特征同等对待可能会编码过多的图像无关信息。本文通过设计一个关系敏感的多模态嵌入模型(RSME),从知识图表示学习的角度探讨辅助视觉上下文的效用。RSME可以在表征学习过程中自动鼓励或过滤视觉语境的影响。我们还研究了不同视觉特征编码器的效果。实验结果验证了该方法的优越性。在深入分析的基础上,我们得出结论,在适当的情况下,模型能够利用视觉输入生成更好的知识图嵌入,反之亦然。
引言
- 知识图(KGs),如Wikidata[30]、Freebase[3]、DB[2]等,包含了头,关系,尾,已广泛应用于各种任务中,如问答[13]、推荐系统[11]、多媒体推理等[17,27]。除了与一组固定的实体和结构属性的关系外,kg通常还包括丰富的视觉背景,通常是图像(头像照片、缩略图、海报等)。图1演示了 K G s KGs KGs中的实体的图像示例。每个实体都有多个描述该实体的外观和行为的图像。因此,基于近年来多模态表示学习技术[1]的发展,许多从业者认为,视觉模态对于改进传统的基于KG的应用是至关重要和有益的[5,19],而传统的基于KG的应用大多只依赖于KG的结构上下文作为输入。然而,目前还不清楚在多大程度上真正需要对当前KG任务和数据集进行多模态推理。==例如,有人指出,许多单模态自然语言处理模型与多模态对应的[9]相比,在不了解任何视觉内容的情况下也可以很好地执行。==同样地,视觉环境对KG问题真的有帮助吗?显然,如何充分利用视觉信息是多模态KG场景的核心问题之一,它直接影响模型的性能。在本工作中,我们将着重从KG表示学习的角度来回答这个问题。
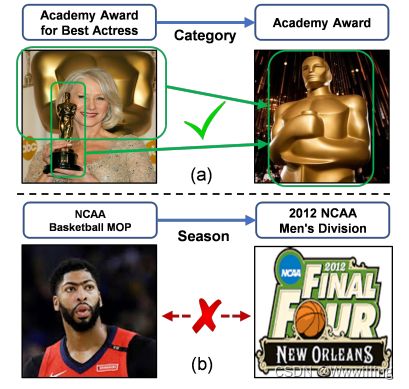
- 图一:多模态知识图实例。关系类别周围的实体图像具有共同的视觉特征。相比之下,《Season》的图像在视觉上几乎没有相似性。
- KG表示学习[31]旨在将实体和关系编码到一个低维的连续向量空间中。学习到的密集向量表示,也就是实体和关系的嵌入,在数学上支持各种机器学习模型来执行KG补全和链接预测,反过来,它们可以用于多模态推理任务。然而,现有的KG表示学习方法大多只考虑KG结构上下文,而忽略了实体的视觉信息。因此,为了获得更好的性能,将KG实体的异构特征投射到一个公共空间中,通过统一嵌入将语义相似的多模态信息融合在一起是一个很有前途的途径。为此,IKRL[34]开始将图像特征集成到基于翻译的KG表示学习模型中,如TransE[4]。==IKRL为每个实体生成两个单独的表示,即一个基于KG结构,另一个基于视觉上下文。==不同的是,Mousselly等[22]和TransAE模型[32]同时对视觉知识和结构知识进行编码。Mousselly等使用了三种不同的方法,即简单拼接、设计[10]和想象[6]来整合多模态信息,TransAE使用了一个自动编码器来融合它们。
- 虽然目前的多模态KG表示学习方法带来了一定程度的改进,但他们认为学习到的嵌入应该更好,因为视觉模态直观地有助于内容上的补充或补充。这一假设可能会受到挑战,因为图像也可能引入噪声,并导致视觉环境是否真的提高嵌入质量的不确定性。例如,如图1(a)所示,Academy Award For Best Actress和Academy Award的图像将有助于学习Category的表示。然而,作为对比,在图2(b)中,NCAA MOP和2012 NCAA男子赛区的图像没有任何视觉上的相似和语义上的关联,这将对Season的表征学习产生不利的影响。因此,直接在传统的KG嵌入中添加视觉信息可能会造成负面影响和破坏。此外,上述嵌入方法大多采用卷积神经网络(CNN)的隐嵌入作为视觉信息的初始表示。通过将预训练的VGGNET与其他图像编码器模型(如VGGNET[7])进行比较,我们认为不同视觉特征编码器的效果也值得讨论。
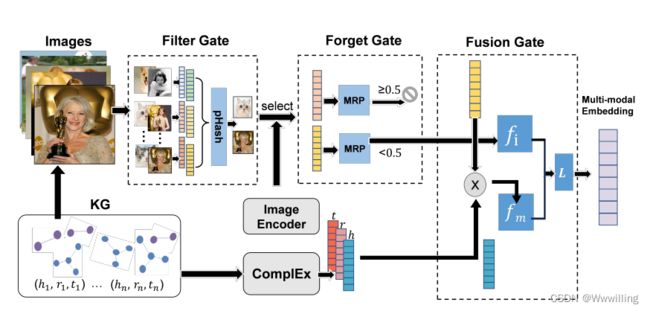
- 基于上述分析,本文重点探讨了视觉语境对KG表示学习的影响,旨在设计一种自动增强有益视觉语境并同时滤除图像噪声的嵌入模型。更具体地说,我们提出了一种新的关系敏感多模态KG嵌入模型,简称RSME,如图2所示。RSME由三个门和一个基本的KG嵌入模型组成。滤波门去除数据集级别的噪声,并且对于每个KG实体,只保留与其他图像具有最高平均相似度的图像。遗忘门利用约简链接预测机制来衡量图像信息在特定关系下的效果,然后遗忘不匹配当前关系环境的实体的视觉信息。最后,融合门融合视觉环境和结构信息,学习KG实体和关系为低维向量。在真实的数据集上,我们进行了链接预测实验,以研究由我们的模型生成的嵌入质量。实验结果表明,RSME方法优于现有方法,达到了最先进的性能。值得注意的是:1)RSME可以选择性地选择实体的图像信息,忽略其他不相关的图像信息;2)提出均值秩比(MRP)来判断图像信息的价值;3)在RSME中使用不同的图像编码器进行测试。我们得出的结论是,视觉语境并不总是有利于表征学习。良好的视觉上下文感知机制和合适的关系环境是必要的。我们在Github上发布了代码和数据集,希望这里提出的工作对未来的多模态KG研究工作有所帮助。
- 综上所述,本工作的贡献如下:
- 据我们所知,本文首次研究了KG问题在何种程度和何种情况下需要视觉语境。我们设计了一个新的模型,即RSME,该模型考虑了关系环境,利用遗忘门中满足的MRP对KG嵌入学习过程中的视觉信息进行选择性过滤。
- 我们探讨了不同视觉特征编码器对多模态KG表示学习的影响,这在经验上是重要的,但之前的嵌入模型忽略了这一点。据我们所知,还没有类似的作品。
- 我们对真实世界的基准数据集进行了全面的实验和灵敏度分析。结果和分析表明,该模型能够自适应地利用视觉信息,并在适当的情况下大大优于目前最先进的模型。
问题描述
-
在本节中,我们将介绍本文中使用的符号,并制定多模态KG表示学习问题。
-
知识图(KG)定义为有向图,可表示为三元组的集合 ( h , r , t ) (h,r,t) (h,r,t),其中 h h h表示头部实体, t t t表示尾部实体,r表示h和 t t t之间的关系。
-
知识图嵌入旨在将实体和关系压缩到一个连续的、低维的向量空间中。给定一个三元(h,r,t),在三元上定义一个损失函数f (h,r,t)来反映h和t之间关系的概率,通过使损失函数最小化,我们最终可以得到KG嵌入。
-
度规空间是一个有序对 ( G , d ) (G, d) (G,d),其中 G G G是一个集合, d d d是 G G G上的一个度规,即函数 d : G × G → R d:G \times G \to R d:G×G→R,使得对于任意 x , y , z ∈ G x,y, z∈G x,y,z∈G,满足以下条件:
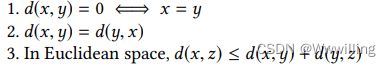
-
KG嵌入组表示:KG嵌入过程分为三步。第一步是在头实体 h h h和群 < G , ∗ >

-
其中, ∗ * ∗是组操作, h , r ∈ G h,r∈G h,r∈G。第二步是计算度量空间 < G , ∗ , d >
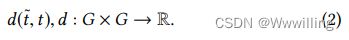
-
第三步是计算损失函数 f ( d ) f (d) f(d)。
-
融合功能,即融合门是结构信息与图像信息融合的机制:

-
多模态KG嵌入群表示可视为KG嵌入引入了一个融合门, Φ Φ Φ。嵌入过程分为3个步骤。第一步是在 Φ ( h s , h i ) Φ(h_s, h_i) Φ(hs,hi)和组 < G , ∗ >

-
其中 h s , h i , r ∈ G h_s, h_i,r∈G hs,hi,r∈G。第二步是计算度量空间 < G , ∗ , d >
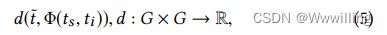
-
其中 t s t_s ts为尾实体的结构嵌入, t i t_i ti为尾实体的图像嵌入。第三步是计算损失函数 f ( d ) f (d) f(d)。
方法
- 本节详细介绍了我们提出的关系敏感的多模态KG嵌入模型(即RSME),该模型可以自动对选择性视觉信息进行编码。如图2所示,RSME由四个部分组成,即一个基本的KG嵌入模型和三个门(即滤波门、遗忘门和融合门)。RSME首先使用一个过滤器门来自动过滤不相关的图像,而不是不加区别地提供所有的视觉上下文。一旦视觉信息被选中,图像将通过遗忘门来增强有益的特征,而MRP评分小的噪声将被忽略。在遗忘门之后,将视觉信息和KG结构信息融合在融合门中,最后通过最小化损失函数实现实体和关系的嵌入。
图像编码器
- 图像编码器的目标是提取KG实体的视觉表示。基于卷积神经网络(CNN)的模型(如VGGNET[26]和AlexNet[14])是以往多模态KG嵌入工作中最常用的编码器[22,32,34]。这就导致在KG嵌入模型中忽略了不同图像编码器的不同效果。因此,为了研究不同图像编码器对KG嵌入的影响,本文采用了三种图像编码器,即遗忘门中的CNN编码器(VGG16[26]或Resnet50[12])、滤波门和遗忘门中的感知哈希算法(pHash)和遗忘门中的视觉转换器[7]。感知哈希算法通常用于生成各种形式的多媒体信息的片段或指纹。与CNN相比,视觉转换器模型需要较少的诱导偏差,更适合于捕获全局视觉信息。
基本嵌入模型
- 表1比较了群表示下多模态学习中KG结构特征编码的三种常用基本嵌入模型。与已有工作不同的是,我们的框架中没有使用翻译模型TransE作为基本模型,而是使用了语义匹配的ComplEx模型。这是因为ComplEx的损失函数为R,利用内积作为度量函数,便于结构模型与视觉信息的统一。在这些模型中,DistMult是最简洁的方法,因此我们在需要规避结构信息干扰的遗忘门中使用它。

过滤门
- 滤波门的设计目的是去除数据集级别的噪声,对于每个KG实体,只保留与其他图像具有最高平均相似度的图像。相比之下,以往的方法在KG嵌入任务中直接利用视觉信息,可能会涉及图像引起的噪声。注意,图像信息的噪声主要来自两个方面,一是数据集的不准确(在这个门中解决),原因是一些实体有不正确的图像,这些图像是从网上自动下载的。另一个噪声是在任务级别,即相关KG实体之间的视觉语义相似性较差(在遗忘门中处理)。
- 大多数实体在不同的场景中有多个来自不同方面的图像。因此,找出哪些图像更能代表其对应的实体,并过滤掉不相关的图像是非常必要的,但也是具有挑战性的。为了解决这一问题,基于错误图像在所有图像中所占比例较大的经验分析,提出了一种滤波门。这少数不正确的图片与其他图片的相似度很低。具体来说,给定一个实体 e e e,它包含多个KG的图像,这些图像可以表示为 I = { i m g 1 , i m g 2 , . . . , i m g n } I=\{img_1,img_2,...,img_n\} I={img1,img2,...,imgn}。滤波门选择与给定实体的其他图像相似度最高的图像进行进一步的表示学习,记为 i m g e img_e imge:
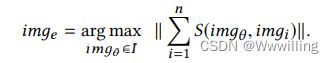
- 其中, S S S表示度量两幅图像视觉相似性的函数。为了简单和高效,pHash[25]被用于滤门。
遗忘门
- 遗忘门可以根据不同的关系情况,增强实体的有益视觉信息,同时消除视觉相似性较差的噪声。如图3所示,遗忘门主要包括两个关键部分,即结构信息省略和平均rank占比。
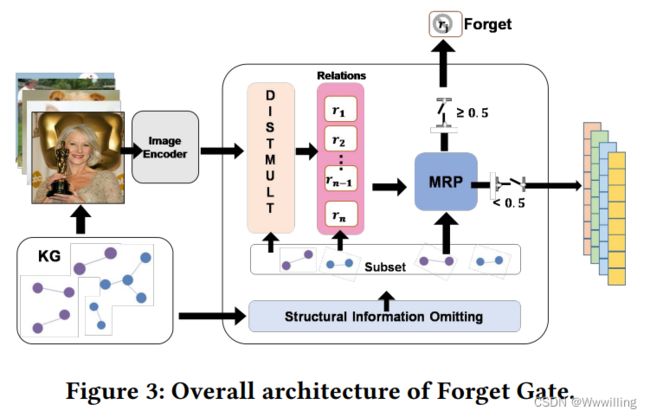
- 通过对数据集的初步实证分析,我们发现KG中的图像大致可以分为两类,即=视觉可检查图像和深度语义图像。可视觉检查的图像是指在颜色、线条组成或其他视觉信息上具有一定程度视觉相似性的KG三元组中两个对应实体的图像对,如图1(a)中的图像。深度语义图像是指只有人类的经验和知识才能识别其视觉相关性的图像,如图1(b)中的图像。因此,在本研究中,视觉可检图像中的视觉信息相对容易被我们的遗忘门捕获,而深度语义图像相对难于被模型检测。
- 通过进一步的分析,我们发现图像的类型与关系高度相关。这意味着一些关系往往由视觉上可检查的图像围绕,如hyponym→or→part_of,而其他关系往往具有更深的语义图像,如关系judge。因此,遗忘门决定了视觉信息被增强的关系环境。
- 结构信息省略:为了确定视觉上下文对KG嵌入学习的有效性,我们需要保证遗忘门不受结构信息的干扰,即只保持视觉信息的独立性。因此,遗忘门鉴别器的第一步是省略KG结构信息。
- 值得注意的是,现有的嵌入工作大多只考虑实体的视觉信息,而关系仍然仅通过结构信息进行编码。但是,给定一个头实体和一个尾实体,在真实的kg中,它们之间可能存在多重关系,在这种多重关系的情况下,由于头实体和尾实体不是一一对应的,因此不能直接省略它们之间的关系。因此,为了简化,我们按照常规设置,从原始数据集中提取子集,即WN18-IMGS和FB15K-IMG-S,它们只包含一对一对应的KG三元组。
- MRP:对于每个给定的关系 r r r,我们设计了一个度量平均秩比( M R P MRP MRP)来确定视觉信息的价值。如果 r r r的 M R P MRP MRP大于阈值,则关系 r r r的图像信息将被遗忘。否则,图像信息将被保留。具体来说, r r r的 M R P MRP MRP分数可以通过简化链接预测过程计算出来。为了方便起见,我们使用相对简单的DistMult模型(参见表1)作为KG嵌入模型。由于省略了结构信息,我们设置了融合函数 Φ ( h s , h i ) = h i Φ(h_s, h_i) = h_i Φ(hs,hi)=hi和 Φ ( t s , t i ) = t i Φ(t_s,t_i) = t_i Φ(ts,ti)=ti和群操作 h i ∗ r = h i h_i * r = h_i hi∗r=hi,其中 h i h_i hi和 t i t_i ti是由图像编码器编码的视觉嵌入。然后直接在非结构化数据集上进行测试,无需训练。最后,我们分别计算每个给定关系 r r r的 M R P MRP MRP,其中 M R P MRP MRP可以通过平均秩计算:
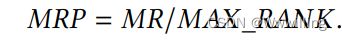
- 通常,我们使用0.5作为阈值。因为 M R P = 0.5 MRP = 0.5 MRP=0.5相当于从所有可选实体中随机选择一个尾部实体。如果给定关系的 M R P MRP MRP大于等于0.5,我们认为视觉信息对链接预测有负面影响,则将其忽略。否则,该关系的视觉信息将被传递到融合门。
融合门
- 本文设计了两种聚变机制。第一种是串联,第二种是关系敏感的线性组合。拼接是最常用的特征融合方法,它将结构嵌入和图像嵌入的投影直接联系起来,如下所示:
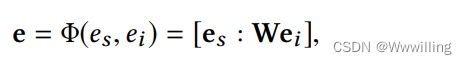
- 其中 Φ Φ Φ为融合门, W W W为投影矩阵, e e e为最终实体嵌入。类似地,关系敏感线性组合可定义为:
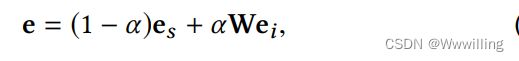
- 其中 W W W为投影矩阵, α α α为视效信息的比值,该比值与对应的KG三元组的关系类型有关,如下:

- MRP越小,视觉信息的重要性越高。这意味着我们赋予视觉信息(如 α α α)的权重增加了。
Loss函数
- 我们使用融合门将结构信息和视觉信息结合在一起。受到ComplEx嵌入模型的启发,所提出的嵌入RSME模型的整体损失由合并能量函数和图像能量函数两部分组成。下标 m m m表示合并信息,下标 s s s表示结构信息,下标 i i i分别表示图像信息。
- KG三元 ( h , r , t ) (h,r,t) (h,r,t)的合并能函数可表示为:
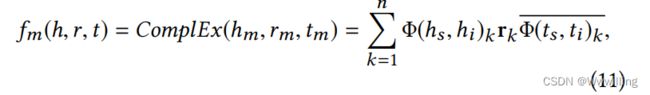
- 其中 Φ Φ Φ为融合门, r \textbf{r} r为关系 r r r的结构嵌入。我们希望头尾实体视觉信息也能一致。因此,我们将视觉能量函数定义为:
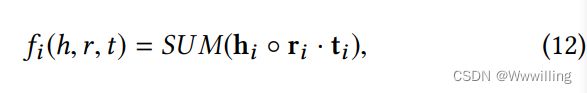
- 其中 h i , r i , t i h_i, r_i,t_i hi,ri,ti是实体和关系的可视化嵌入,◦是组操作,即Hadamard产品。然而,在KG中没有给定关系的图像。为了解决这个问题,我们简单地使用一个单位向量1作为关系的嵌入。在此基础上,我们可以定义整体能量函数如下:

- 其中 β β β是超参数。最后,整体损失为:
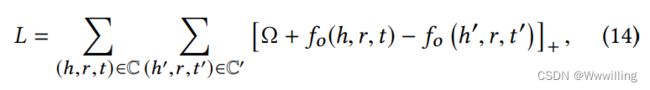
- 其中 C C C是训练三元组的集合。 C ′ C' C′为C的负采样集, Ω Ω Ω为松弛变量。 C ′ C' C′是通过随机替换头、尾实体或关系来构造的。
实验
- 在本节中,我们将评估所提出的RSME模型在真实基准数据集上的性能,以及对相关参数和设置的敏感性分析,以理解视觉上下文在多模态KG嵌入中的影响。
数据集
- 本文在两个公开的多媒体检索数据集上进行了实验,这两个数据集广泛用于多模态KG嵌入模型的性能评价。
- WN18- img: WN18[4]是一个著名的KG,最初是从WordNet[21]中提取出来的。WN18- img是WN18[4]的扩展数据集,为每个实体准备10个图像。
- FB15K- img: FB15K[4]是一个广泛应用于KG嵌入链路预测任务的数据集。FB15K- img是FB15K的扩展数据集,为每个实体准备20张图像。我们使用MMKG[20]提供的脚本重建FB15KIMG。
- WN18-IMG- s: WN18-IMG- s是WN18-IMG的一个子集,它只包含具有一对一对应实体的三元组。
- FB15K-IMG- s: FB15K-IMG- s是FB15K-IMG的一个子集,它只包含有一对一对应实体的三元组。
- FBX%: FBX是FB15K-IMG的一个子集。我们通过随机选择10%的三元组来创建它。和FB40%, FB60%, FB80%一样。
链路预测和训练数据掩蔽
- 链路预测任务的目标是在 ( h , r , t ) (h,r,t) (h,r,t)缺少一个时,在最小化损失函数的基础上完成一个三元组。我们采用以下度量作为评价指标:(1)MR:正确实体的平均秩;(2) Hit@k:有效实体分别排在前1、3、10位的比例。
- 实验设置:我们和其他KG嵌入模型一样进行链路预测实验。在训练过程中,我们首先为测试数据集中的每个三元组生成一个损坏的三元组,方法是随机替换三元组的头部或尾部实体,表示为 ( h ′ , r , t ) (h ',r,t) (h′,r,t)或 ( h , r , t ′ ) (h,r,t ') (h,r,t′)。将式(14)中 L L L的损失函数最小化,得到实体和关系的嵌入。对于测试数据集中的KG三元组,我们将尾部实体分别替换为所有实体,然后按 f o f_o fo升序对每个三元组进行排序,以分析平均秩和Hit@k。较小的平均排名或较大的Hit@k表示结果良好。RSME(No Image)是指仅基于结构信息的表示。RSME(VIT)由结构信息和视觉信息计算,视觉信息由视觉转换器编码。RSME(VIT+Forget)是指对RSME(VIT)应用遗忘门。
- 超参数设置:RSME由Adam优化。我们进行网格搜索以找到合适的超参数。
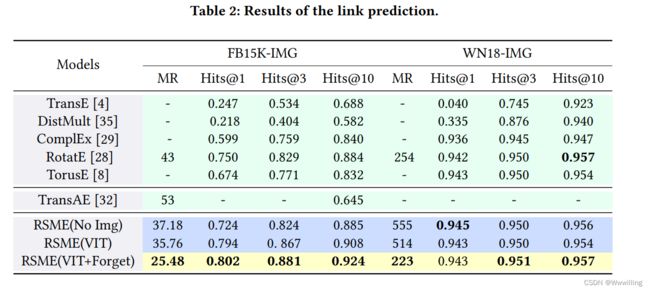
- 结果:表2给出了链路预测的实验结果。可以看出,RSME的性能优于其他所有模型。RSME(VIT)组和RSME(No Img)组之间的差异是显著的,这表明视觉上下文的引入是有帮助的。此外,RSME(VIT)和RSME(VIT+Forget)的比较也表明,遗忘门在大多数情况下确实有进一步的改进。然而,我们发现一些基于结构的嵌入模型也有很好的性能,如RotatE。我们认为这可能是因为数据集已经有非常丰富的结构信息,不需要依赖太多的视觉信息。因此,我们不能直接得出视觉信息在rsmme改善中起关键作用的结论。因为模型还受到超参数、变量初始化和其他因素的影响。为了进一步分析图像信息的影响,我们对部分训练数据进行了掩模, 并利用RSME进行了实验。
- 我们认为目前的数据集FB15K包含了足够的结构信息来进行预测,这干扰了视觉信息的分析。为了突出视觉信息的作用,我们屏蔽了一部分训练数据,并创建数据集,FB1%, FB20%, FB40%, FB60%, FB80%。然后,我们再次进行了链路预测实验。
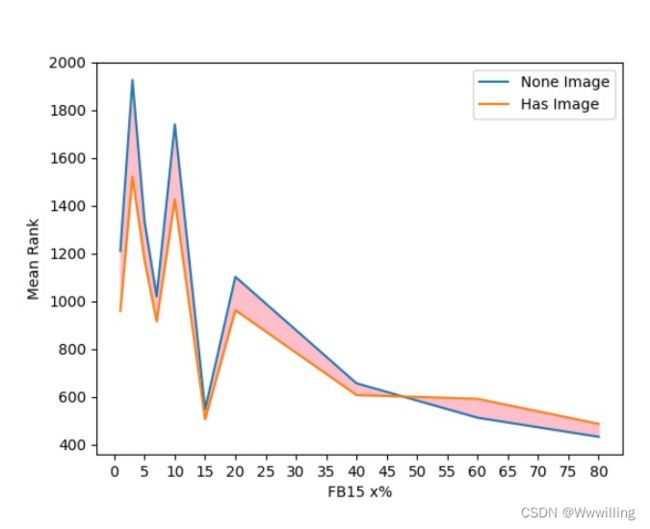
- RSME(No Image) VS RSME(VIT+Forget):为了进一步探索图像信息的作用,我们比较了RSME和RSME(VIT+Forget)在不同尺寸下对FBX%的链接预测实验结果。结果如图4所示。令人惊讶的是,视觉信息的引入并不总是对FBX%有益。我们发现,当结构训练数据集较小时,视觉信息是有帮助的。随着结构数据的增加,图像信息的好处逐渐减少,直至消失。
- RSME(VIT+Forget) VS RSME(VIT+Random):为了验证视觉信息的选择性带来的好处,我们设计了一个随机门。随机门随机选择与遗忘门相同数量的图像,然后将其与结构信息相结合。FBX%的比较结果如图5所示。RSME(VIT+Forget)的整体MR低于RSME(VIT+Random),验证了在与结构信息融合前需要对图像信息进行有针对性的选择。此外,在FB80%上,RSME(VIT+Forget)得到的结果比RSME(VIT+Random)更差。我们认为这是由于结构信息的干扰,如前所述。
关系环境的敏感性
- 在本小节中,我们主要讨论KG嵌入方法中何时引入视觉信息是有利的,并主要讨论不同关系对所提模型的敏感性。我们首先观察到,视觉信息并非对所有关系都有益。然后,在链路预测的基础上,对各个关系的结果分别进行分析。
- 实验设置:按照4.2节所述的方法,我们首先比较RSME对WN18-IMG和FB15K-IMG上不同关系的预测结果,然后计算WN18-IMG- s和FB15K-IMG- s数据集上的MRP。选择视觉转换器作为图像编码器。视觉转换器的权重是预先训练的。每个图像的大小统一调整为384x384。每个实体只使用滤波门选择的一个图像参与计算。
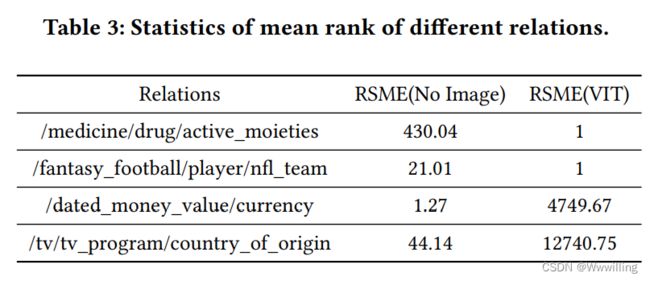
- 结果:表3显示,图像信息并不总是有利于所有关系的嵌入。一些带有图像信息的关系,例如/dated_money_value/currency,其结果比没有图像信息的关系差。这验证了我们的假设,即视觉信息中的噪声可能会对模型产生不利影响。
- 表4给出了WN18-IMG-S中所有10个关系和FB15K-IMG-S中采样的10个关系的结果。WN18-IMG-S的平均MRP为0.104,FB15K-IMG-S的平均MRP为0.386。这一结果在MRP <0.5水平上是显著的,这意味着视觉信息确实可以帮助建立头部和尾部实体之间的正确连接。表4的数据还显示,WN18-IMG-S的MRP报告明显优于FB15K-IMG-S。我们认为这是因为WN18-IMG-S中的许多图像来自ImageNet,在那里视觉转换器是预先训练的。同样的训练数据集对于提高模型的性能显然是有意义的。有趣的是,FB15K-IMG-S的平均MRP为0.386,尽管FB15K-IMG-S中的实体图像不在ImageNet中。这表明视觉变换作为一种图像度量确实具有意想不到的效果。此外,我们注意到FB15K-IMG-S与大于等于0.5的MRP仍有很多关系。说明这些实体的视觉信息并不会带来负面影响。模型应该忘记这类视觉信息。
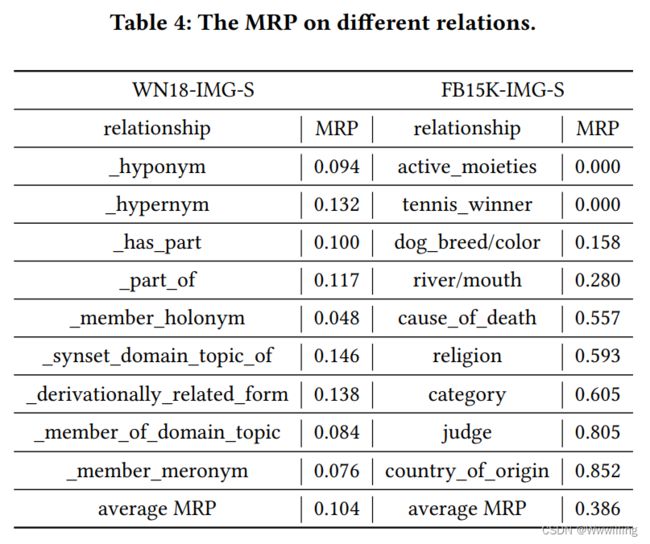
- 由表4我们还发现,不同的关系有不同的MRPs,这说明不同的关系对视觉信息有不同的敏感性。有一些关系可以很好地利用视觉信息,如active_moietie→和river/mouth→。通过分析原因,我们发现active_moietie→是一种反身关系,并且大多数river/mouth→上的实体都具有视觉上可检查的图像。相比之下,judge→等抽象关系的准确性相对较低.
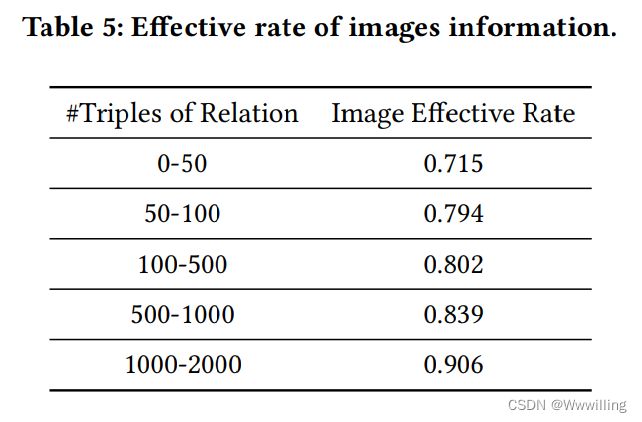
- 此外,我们提出了一个新的度量,即图像有效率,它指的是 M R P < 0.5 MRP < 0.5 MRP<0.5的关系的数量相对于所有关系的数量的比例。我们根据关系中包含的三元组的数量对关系进行分割,然后计算每个片段的图像效率。结果如表5所示。我们发现,随着关系中包含的三元组数量的增加,图像效率也逐渐提高。由此可以得出这样的结论:数据越复杂,视觉信息越有利。
图像编码器的灵敏度
- 在本小节中,我们主要讨论模型中使用的图像编码器的影响。在链路预测实验中,我们分析了RSME在不同类型图像编码器下的性能。相比之下,目前大多数的嵌入模型只使用CNN (VGG16[26]和AlexNet[14])来提取图像的视觉特征,而忽略了对图像编码器在嵌入模型中的作用的分析。
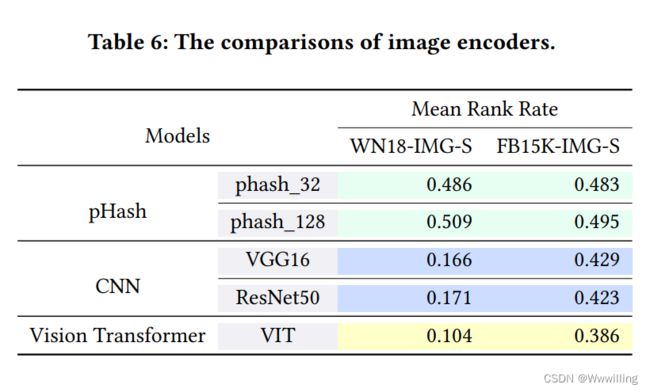
- 结果:结果如表6所示。我们发现,无论是WN18-IMG-S还是FB15K-IMG-S,即使将感知哈希算法的长度增加到128,也无法捕捉到图像的特征。这表明传统的基于汉明距离的度量不适合作为多模态KG嵌入的图像编码器。对于基于CNN的模型,我们发现Resnet50在两个数据集上的表现都优于VGG16,这表明一个好的CNN可以提取更好的视觉特征。令人惊讶的是,我们发现视觉转换器明显优于所有其他图像编码器。这是由于视觉转换器具有更好的全局感知能力。图像编码器之间巨大的性能差距表明,多模态KG嵌入模型的性能不仅取决于模型本身,而且对使用的图像编码器也很敏感。
相关工作
单峰KG嵌入模型
- 基于翻译的KG嵌入模型以其简单和高效而闻名。TransE[4]是第一个基于翻译的模型,其引擎函数满足 ∥ h + r − t ∥ ≈ 0 ∥h + r−t∥≈0 ∥h+r−t∥≈0。尽管TransE简单且高效,但它在处理1到n、n到1和n到n关系时存在缺陷。TransH[33]和TransR[18]通过允许实体具有基于关系的嵌入来克服这一缺陷。TransH将实体投影到关系 r r r的超平面上。TransR通过基于关系的矩阵将实体投影到特征空间上。TransD[15]通过将投影矩阵分解为单位矩阵加上两个向量的乘积来简化TransR,从而减少了参数的数量。TranSparse[16]通过稀疏矩阵简化TransR。TorusE[8]定义紧李群上的平移。SOTA方法RotatE[28]提出了一个将平移作为复空间旋转的旋转模型。RESCAL[24]是第一个双线性模型。RESCAL表示KG为一个三向张量。这三种方式分别是实体和关系。通过将Mr限制为对角矩阵,DistMult[35]简化了RESCAL。然而,DistMult算法不能处理非对称关系,HolE[23]通过使用循环相关操作,将RESCAL的表达能力与DistMult的效率和简单性相结合。ComplEx[29]将HolE赋给复空间,以更好地模拟非对称关系。然而,基于翻译的模型和双线性模型都只关注三元组之间的结构信息,而忽略了多模态KGs中丰富的视觉环境。
多模态KG嵌入模型
- 为了在KG嵌入中编码图像特征,IKRL[34]基于TransE[4]分别学习视觉信息和结构信息。在此基础上,Mousselly等[22]和TransAE模型[32]联合学习视觉特征和结构特征,形成统一的知识嵌入。Mousselly等人使用了三种不同的方法,即简单拼接、设计[10]和想象[6]来整合多模式信息,TransAE则使用了一个自动编码器来融合它们。虽然现有的多模态KG表示学习方法表现出了良好的性能,但他们认为,由于视觉模态直观地提供了丰富的内容信息,因此学习到的嵌入有望取得更好的效果。尽管它们在一定程度上取得了成功,但在多大程度上KG嵌入需要真正的视觉上下文并不总是很清楚。图像也可能引入噪声,并导致视觉环境是否真的提高嵌入质量的不确定性。
结论
- 在这项工作中,我们试图探讨丰富的视觉上下文在KG表示学习中的效用。我们发现KG中的图像资源确实有助于提高学习到的KG嵌入的质量。我们还认为,视觉信息并不总是有用的。为了验证我们的假设,我们提出了一种关系敏感的多模态嵌入模型,即RSME,在表示学习过程中自动鼓励或过滤附加视觉上下文的影响。我们对我们的方法与最先进的方法进行了广泛的链接预测实验,以表明在适当的情况下利用视觉输入生成更好的KG嵌入是可能的。我们还探讨了在模型中使用的不同视觉特征编码器的效果。实验结果验证了视觉特征编码器设置的重要性。希望本文的研究成果对今后的多模态KG研究工作有所帮助。