两阶段目标检测重要论文总结
文章目录
- Selective Search方法
-
- 1、论文简介
- 2、算法原理
- EdgeBoxes方法
-
- 1、论文简介
- 2、算法原理
- 一、R-CNN
-
- 1、论文简介
- 2、结构设计
- 3、论文总结及改进点
- 二、SPPNet-解决R-CNN速度慢的问题
-
- 1、论文简介
- 2、结构设计
- 3、论文总结及改进点
- 4、SPPnet代码(Pytorch)
- 三、Fast R-CNN
-
- 1、论文简介
- 2、结构设计
-
- ROI池化层
- multi-task损失
- 截断SVD方法
- 3、论文总结及改进点
- 4、ROI池化层代码(Pytorch)
- 5、selective search方法提取region proposal代码
- 6、输出分类概率及Bbox回归网络代码
- 四、Faster R-CNN
-
- 1、论文简介
- 2、结构设计
-
- RPN模块
- Anchor
- anchor金字塔
- 3、RPN和Fast RCNN共享特征的细节
- 4、论文总结及改进点
- 五、RFCN
-
- 1、论文简介
- 2、结构设计
-
- backbone
- ROI区域的分类
- ROI区域的回归
- 3、论文总结
- 六、Light-Head RCNN
-
- 1、论文简介
- 2、结构设计
-
- RCNN检测子网
- RoI warping
- light-head RCNN结构分解
- 3、论文总结
- 七、FPN
-
- 1、论文简介
-
- 特征金字塔的发展历程
- 自上而下结构和跳跃式连接结构
- 2、结构设计
-
- 自下而上路径(具高分辨率低语义)
- 自上而下路径(具低分辨率高语义)和横向连接
- FPN用在RPN
- FPN用在Fast RCNN
- 3、论文总结
- 4、FPN代码(pytorch)
- 八、Mask R-CNN
-
- 1、论文简介
- 2、结构设计
-
- Mask R-CNN
- Mask表示
- RoIAlign
- 网络结构
- 3、论文总结
- 引用
Selective Search方法
1、论文简介
论文名称:Selective Search for Object Recognition
论文地址:Selective Search
论文代码:Selective Search代码
2、算法原理
# Selective Search算法流程
Algorithm1:Selective Search
Input:(color)image
Output:Set of object location hypotheses L
1、生成初始化区域集R
2、初始化相似集合S为空集
3、foreach (ri,rj) do #计算区域内每个相邻区域的相似度
计算s(ri,rj)
把s(ri,rj)合并到S里面
4、while S不等于空集的时候 do #对S集合中相似度最高的区域进行合并为一个区域
取出S集合中相似度最高的s(ri,ji)
对ri,ji进行合并成为rt
把rt加入到S中
删除S集合中与ri有关的子集
删除S集合中与rj有关的子集
计算新集合与所有集和的相似度
5、跳转到步骤4,直到S为空
# 生成初始化区域集R的方法
Algorithm2:区域分割算法
Input:有n个节点和m条边的图G
Output:一系列区域集R
1、 将边按照权重值以非递减方式排序
2、 最初的分割记为S(0),即每一个节点属于一个区域
3、 按照以下的方式由S(q-1)构造S(q):记第q条边连接的两个节点为vi和vj,如果在S(q-1)中vi和vj是分别属于两个区域并且第q条边的权重小于两个区域的区域内间距,则合并两个区域。否则令S(q) = S(q-1)。
4、 从q=1到q=m,重复步骤2
5、 返回S(m)即为所求分割区域集合
1、区域内间距求法:
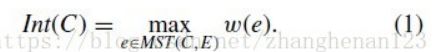
MST为区域对应最小生成树,即区域内间距为区域对应最小生成树中权值最大的边对应的权值。
2、区域间间距的求法:
![]()
即在所有分别属于两个区域且有边链接的点对中,寻找权值最小的那对边的权值即为区域间间距(若两个区域内的点没有边相连,则定义间距为正无穷大)
3、判断两个集合是否可以合并的方法
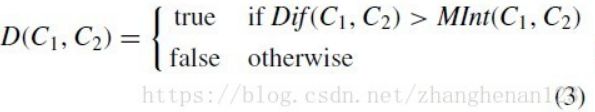
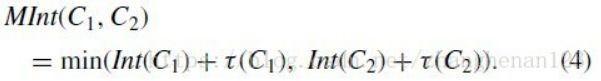
如上公式三求取两个区域是否可以合并的结果为true表示不可合并(也即是区域间间距远大于区域内间距),fasle表示可以合并 。
4、图的最小生成树
见博客https://blog.csdn.net/qq_35644234/article/details/59106779讲解
5、区域相似度的计算
①颜色相似度:对各个通道计算颜色直方图,然后取各个对应bins的直方图最小值。这样做的话两个区域合并后的直方图也很好计算,直接通过直方图大小加权区域大小然后除以总区域大小就好了。将色彩空间转为HSV,每个通道下以bins=25计算直方图,这样每个区域的颜色直方图有25*3=75个区间。
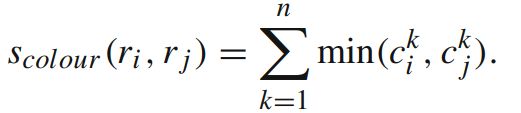
②纹理相似度:计算方式和颜色距离几乎一样,我们计算每个区域的快速sift特征,其中方向个数为8,3个通道,每个通道bins为10,对于每幅图像得到240维的纹理直方图。
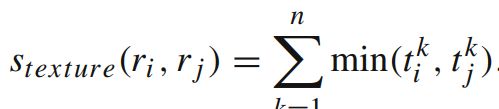
③尺寸相似度:优先合并小区域,如果仅仅是通过颜色和纹理特征合并的话,很容易使得合并后的区域不断吞并周围的区域,后果就是多尺度只应用在了那个局部,而不是全局的多尺度。因此我们给小的区域更多的权重,这样保证在图像每个位置都是多尺度的在合并。
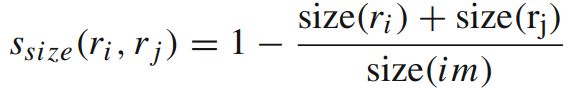
④区域合适相似度:不仅要考虑每个区域特征的吻合程度,区域的吻合度也是重要的,吻合度的意思是合并后的区域要尽量规范,不能合并后出现断崖的区域,这样明显不符合常识,体现出来就是区域的外接矩形的重合面积要大。因此区域的合适相似度定义为:
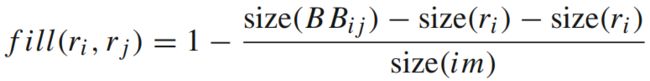
⑤综合各种相似度,通过多种策略去得到region proposal,最简单的方法当然是加权:
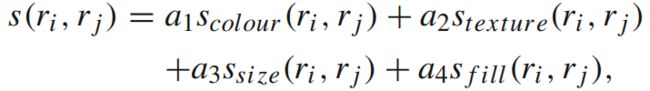
⑥参数初始化多样性,我们基于图的图像分割得到初始区域,而这个初始区域对于最终的影响是很大的,因此我们通过多种参数初始化图像分割,也算是扩充了多样性。
6、给区域打分
通过上述的步骤我们能够得到很多很多的区域,但是显然不是每个区域作为目标的可能性都是相同的,因此我们需要衡量这个可能性,这样就可以根据我们的需要筛选region proposal个数。
本文做法是给予最先合并的图片块较大的权重,比如最后一块完整图像权重为1,倒数第二次合并的区域权重为2以此类推。但是当我们策略很多,多样性很多的时候这个权重就会有太多的重合了,因为不好排序。本文做法是给他们乘以一个随机数,然后对于相同的区域多次出现的就做权重叠加,毕竟多个方法都说你是目标,也是有理由的。这样就得到了所有区域的目标分数,也就可以根据自己的需要选择需要多少个区域了。
EdgeBoxes方法
1、论文简介
论文名称:Edge Boxes: Locating Object Proposals from Edges
论文链接:EdgeBoxes
论文源码:EdgeBoxes实现
selective search与edgeboxes的调包实现
2、算法原理
①对于一张image,计算每一个pixel的edge response,在论文中使用Structured Edge Detector来判断物体的边界。然后使用NMS去整理edge,得到最后较为稳定的object edges。
②计算edge groups 和 affinity:直观的来说,笔直的边界具有较高的affinity,而曲率较高的边界的affinity较低。给定一个bbox,根据bbox内部含有的edge的affinity的最大值来判断bbox的boundary。给定一个edges group的几个,计算两两相邻groups之间的affinity。如果两个groups之间均值夹角接近于groups的方向,则说明这两个edge groups有着较高的affinity。

③计算bounding box的score:从上面得到了edges groups集合S和他们的affinity,可以计算每一个candidate bounding box的object proposal score。首先计算在group Si 中的所有edges p的mp值的和,为mi,在group Si中计算si是否完全包含在b中的连续值wb(xi) ,介于[0,1]。
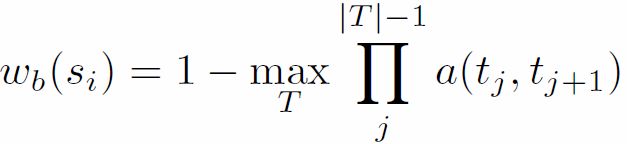
使用一种高效的算法,去计算每一个Sb。上面的公式可以求出edges group Si 与bounding box中含有最高的affinity的一些path。在上面的公式计算下,很多的pairwise都是0。下面可以计算score:
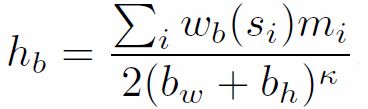
其中 b w b_w bw和 b n b_n bn代表box的width 和height。k值为1.5,作用是对大windows会有更多的edges进行偏置调节。同时发现box中央的edges会比靠近box边界的edges的作用更小。所以在这里对位于box中央的bin做一个调整处理。定义box的center的指标是:bin的width和height是整个box的一半,即 b w 2 \frac{b_w}{2} 2bw, b n 2 \frac{b_n}{2} 2bn。

④查找策略:使用sliding window search 在一个image上进行位置,尺度和纵横比上的查找bbox,在含有一个object的区域,可能会产生更多的bounding boxes和更密集地聚集。利用IoU去筛选,提炼最终合并bounding box。然后最后是对得到的bounding boxes进行NMS,得到最终的sorted boxes。
一、R-CNN
1、论文简介
论文名称:《Rich feature hierarchies for accurate object detection and semantic segmentation》
论文链接:R-CNN
摘要:在过去几年中,在标准PASCAL VOC数据集上目标检测性能保持稳定。性能最好的方法是复杂的集成系统,通常将多个低级图像特征与高级上下文相结合。在本文中,我们提出了一种简单且可扩展的检测算法,与之前在VOC 2012上获得的53.3%的平均精度相比,平均精度(mAP)提高了30%以上。我们的方法结合了两个关键观点:(1)一个可以将高容量CNN应用于自下而上的region proposal,以便定位和分割对象;(2)当有label的训练数据稀缺时,这时就用到了监督预训练作为辅助任务,然后进行特定区域的微调,就可以显著提高性能。由于我们将区域提议与CNN相结合,我们将此方法称为R-CNN:具有CNN特征的区域。我们还将R-CNN与OverFeat进行了比较,OverFeat是最近提出的一种基于类似CNN结构的滑动窗口检测器。我们发现,在200类别的ILSVRC2013检测数据集上,R-CNN的表现远优于OverFeat。
关注的两个问题:①用深度网络定位目标②用小量的标注数据训练一个高容量模型。
解决CNN定位问题:使用区域识别范式操作。具体操作为:测试时在输入图片上产生2000个类别独立的region proposal,用CNN从每个proposal上提取固定长度的向量,然后用特定类别的线性SVM对每个region进行分类。用仿射图像变形去计算来自每个region proposal的固定大小CNN输入。
解决标注数据缺失问题:在大型辅助数据集ImageNet上进行监督预训练,在小数据集VOC上进行迁移学习微调操作。(传统方法为先进行无监督预训练再进行有监督微调操作)
2、结构设计
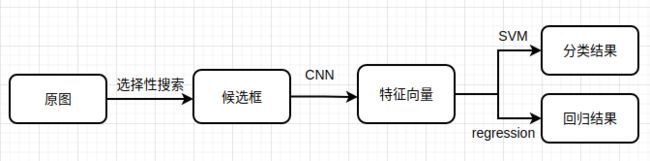
R-CNN结构图:

R-CNN包括三个模块:RP生成模块,特征提取模块,分类模块。
①RP生成模块:生成类别独立的region proposal模块,使用选择性搜索方法。
选择性搜索方法:首先通过类似聚类方法在图像中找到初始的分割区域(颜色、纹理、大小、形状、相似度比较相似的区域),然后对这些区域进行加权合并产生不同层次的2000个候选框。
②特征提取模块:用大型CNN(AlexNet)从每个region提取固定长度的特征向量的模块。
候选框缩放原则:使用非等比例缩放(不保留长宽比)且连带邻近像素的方法(dilate proposal),连带的像素作者使用P=16,多出来的像素全部填为此图的像素平均值,喂到CNN之前每个像素都要做去均值操作。下图最右边的两张图表示本文使用的缩放原则。

③分类模块:使用特定类别的线性SVM分类器。
为什么用SVM分类而不用softmax?
答:微调时正负样本的选择策略是与GT的IOU最大且IOU大于0.5的候选框为正样本(与GT有偏离,精确定位性能差),其余候选框为负样本;而训练各类别SVM分类器时GT框为正样本(精确定位性能好),与GT的IOU小于0.3的候选框为该类负样本(用到难例挖掘),忽略与GT的IOU大于0.3的候选框。
选择sotfmax之后正负样本的选择策略要跟着微调时的策略来,因此造成性能没有SVM分类那么好。
整个过程描述:将输入图像用选择性搜索方法生成2000个候选框,将每个候选框都强制缩放为227×227大小的RGB图像,然后将每一张RGB图像逐一输入同一个CNN中提取出一个4096维度的特征向量,最后用线性SVM对这个向量进行分类,在分类的同时还进行了BBox的回归操作。
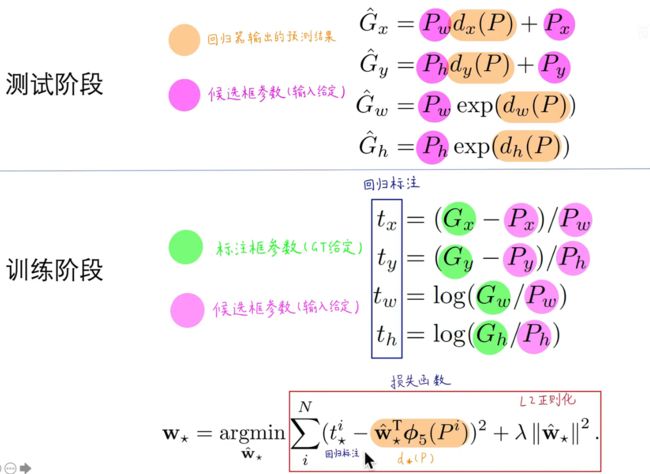
在这里BBox回归是什么?
答:对候选框进行精调,得到偏移量,然后对候选框施加这个偏移量得到最终的预测框。总的来说就是BBox回归使得微调后的窗口与GT更接近了。
BBox回归怎么做?
上图测试阶段黄色的为预测的偏移量,将偏移量都放到等式左边,然后在训练阶段由给定的GT框和输入框就可以算出要拟合的比例因子(要预测的偏移量)了。让神经网络去拟合这个比例因子,即现在要让黄色的 W ∗ T ϕ 5 ( P i ) W_*^T \phi_5(P^i) W∗Tϕ5(Pi)去拟合 t ∗ i t_*^i t∗i, W ∗ T ϕ 5 ( P i ) W_*^T \phi_5(P^i) W∗Tϕ5(Pi)代表在第五个池化层的特征上乘以一个线性回归的权重矩阵, ( t ∗ i − W ∗ T ϕ 5 ( P i ) ) 2 (t_*^i-W_*^T \phi_5(P^i))^2 (t∗i−W∗Tϕ5(Pi))2可以看出这是一个典型的回归问题,为了防止权重过大在后面加上L2正则化。
3、论文总结及改进点
总结:该设计是一个由上而下产业链的设计,不是端到端的设计,这使得流程中只要有一个地方出差错整体性能将会跟着下降。而且这种设计很耗时,主要耗费都在2000张RGB图像逐一输入到CNN中得到特征向量的计算上。
R-CNN缺点:①训练是个多阶段的流水线过程(首先在目标proposal上对卷积网络进行微调,然后让SVM适应卷积网络输出的特征,最后需要学习BBox回归)
②训练非常耗费时间和空间
③检测速度非常慢(测试阶段)
改进点:①提取候选框:EdgeBoxes、RPN网络
②共享卷积运算:SPPNet、Fast R-CNN
③兼容任意尺寸图像:SPP、ROI Pooling
④预设长宽比:Anchor
⑤网络结构:端到端
⑥融合各层特征:FPN
二、SPPNet-解决R-CNN速度慢的问题
1、论文简介
论文名称:《Spatial Pyramid Pooling in Deep Convolutional Networks for Visual Recognition》
论文地址:SPPNet
论文源码:SPPNet实现
摘要:现有CNN需要一个固定大小的输入图像。这一要求是“人为的”,可能会降低任意大小/比例的图像或子图像的识别精度。在这项工作中,我们为网络配备了另一种**池化策略“空间金字塔池化”**以消除上述要求。这种新的网络结构称为SPP网络,它可以生成固定长度的表示,而不管图像大小/比例如何。金字塔池化对于目标变形也鲁棒。有了这些优势,SPP网络总体上改进了所有基于CNN的图像分类方法。在ImageNet 2012数据集上,我们证明了SPP net提高了各种CNN架构的准确性,尽管它们的设计不同。在Pascal VOC 2007和Caltech101数据集上,SPP net使用单个完整图像表示,无需微调,即可获得最先进的分类结果。
SPP网络的功能在目标检测中也很重要。使用SPP网络,我们只从整个图像中计算一次特征映射,然后在任意区域(子图像)中汇集特征,生成用于训练检测器的固定长度表示。该方法避免了重复计算卷积特征。在处理测试图像时,我们的方法比R-CNN方法快24-102倍,同时在Pascal VOC 2007上实现了更好或类似的精度。
在2014年ImageNet大规模视觉识别挑战赛(ILSVRC)中,我们的方法在所有38个团队中的目标检测和图像分类排名分别为#2和#3。
问题:CNN需要固定大小的输入图像(卷积层其实不需要固定尺寸的输入图也能产生任意尺寸大小的特征图,但是FC层则需要固定大小的输入)。
方案:提出空间金字塔池化层,在卷积层最后一层加SPP层,该层可以池化特征产生固定大小的输出。
SPP优点:①不论输入图像大小可产生固定带小的输出;
②使用多级空间池化核,多级池化对目标变形具有鲁棒性;
③由于输入尺寸较灵活,SPP可以池化在不同尺度上提取到的特征。
对R-CNN的改进点:
①让卷积层在整张输入图像中只运行一次(而不是像R-CNN中在整张图像中提取到2000多个候选框再强制扭曲为227×227大小的2000张图像最后逐图像输入CNN中让CNN运行2000多次),然后让SPPnet在特征图上提取特征。
②用到EdgeBoxes的快速提案法,整张图的处理速度更快了。

2、结构设计
SPP是一种自适应的max-pooling方法
思路:根据输入特征图的大小和期望输出特征图的大小来确定池化框的size和stride,如假设输入为C×M×M的特征图,期望SPP输出C×N×N的特征图,则SPP的池化框大小为 c e i l ( M N ) ceil(\frac{M}{N}) ceil(NM),其中ceil为向上取整操作;滑动stride为 f l o o r ( M N ) floor(\frac{M}{N}) floor(NM),其中floor为向下取整操作。
-
池化框数量的确定:SPP输出C×N×N的特征图,则bin数量为N×N。如下图最左边的SPP欲输出4×4大小的特征图,则bin数量为16(可以理解为将原来的特征图分为16份,在每一份上做最大池化操作)。
-
维度数确定 :等于最后一层卷积层的卷积核个数。例如下图为256维。
-
L-level SPP:L个输出尺寸不同的SPP形成的金字塔网络。一般将每个SPP的输出进行flatten,然后再concatenate,最后输入到FC或softmax。例如下图为3-level SPP。

上图操作可以可视化为下面的图:

注意:最右边有一个覆盖全图的池化框,这其实是全局池化操作。
全局池化:可以做全局平均池化和全局最大池化
优点:①减少模型尺寸、参数量;②防止过拟合现象
3、论文总结及改进点
总结:此篇论文对R-CNN最大的改进点在于特征提取阶段:将整张待检测的图片输入CNN中,进行一次性特征提取,得到feature maps,然后在feature maps中找到各个候选框的区域,再对各个候选框采用金字塔空间池化,提取出固定长度的特征向量。R-CNN的做法是:将每个候选框逐个输入到CNN中提取出4096维向量。因为SPP-Net只需要对整张图片进行一次特征提取,速度会大大提升。
SPPnet缺点:①训练过程仍是个多阶段的流水线;
②微调算法不能更新SPP层之前的卷积层,因此(固定的卷积层)限制了非常深的网络的准确性。
改进点:①改为单阶段训练;
②使得算法可以更新网络所有层。
4、SPPnet代码(Pytorch)
整个训练和测试流程见这篇博客的部分三:https://blog.csdn.net/weixin_45422462/article/details/108412656
对SPP层的定义:
import math
def spatial_pyramid_pool(self, previous_conv, num_sample, previous_conv_size, out_pool_size):
'''
previous_conv: a tensor vector of previous convolution layer
num_sample: an int number of image in the batch(这里等于1)
previous_conv_size: size of featrue map in previous convolution layer
out_pool_size: expected output size of max pooling layer
returns: a tensor vector with shape [1 x n] is the concentration of multi-level pooling
'''
for i in range(len(out_pool_size)):
h_siz = int(math.ceil(previous_conv_size[0] / out_pool_size[i]))
w_siz = int(math.ceil(previous_conv_size[1] / out_pool_size[i]))
h_str = int(math.floor(previous_conv_size[0] / out_pool_size[i]))
w_str = int(math.floor(previous_conv_size[1] / out_pool_size[i]))
h_pad = (h_siz*out_pool_size[i] - previous_conv_size[0] + 1)/2
w_pad = (w_siz*out_pool_size[i] - previous_conv_size[1] + 1)/2
maxpool = nn.MaxPool2d((h_wid, w_wid), stride=(h_wid, w_wid), padding=(h_pad, w_pad))
x = maxpool(previous_conv)
if(i == 0):
spp = x.view(num_sample,-1)
# print("spp size:",spp.size())
else:
# print("size:",spp.size())
spp = torch.cat((spp,x.view(num_sample,-1)), 1) #concat操作
return spp
带有SPP层的CNN网络:
import torch
import torch.nn as nn
from torch.nn import init
import functools
from torch.autograd import Variable
import numpy as np
import torch.nn.functional as F
from spp_layer import spatial_pyramid_pool
class SPP_NET(nn.Module):
'''
A CNN model which adds spp layer so that we can input multi-size tensor
'''
def __init__(self, opt, input_nc, ndf=64, gpu_ids=[]):
super(SPP_NET, self).__init__()
self.gpu_ids = gpu_ids
self.output_num = [4,2,1]
self.conv1 = nn.Conv2d(input_nc, ndf, 4, 2, 1, bias=False)
self.conv2 = nn.Conv2d(ndf, ndf * 2, 4, 1, 1, bias=False)
self.BN1 = nn.BatchNorm2d(ndf * 2)
self.conv3 = nn.Conv2d(ndf * 2, ndf * 4, 4, 1, 1, bias=False)
self.BN2 = nn.BatchNorm2d(ndf * 4)
self.conv4 = nn.Conv2d(ndf * 4, ndf * 8, 4, 1, 1, bias=False)
self.BN3 = nn.BatchNorm2d(ndf * 8)
self.conv5 = nn.Conv2d(ndf * 8, 64, 4, 1, 0, bias=False)
self.fc1 = nn.Linear(10752,4096)
self.fc2 = nn.Linear(4096,1000)
def forward(self,x):
x = self.conv1(x)
x = self.LReLU1(x)
x = self.conv2(x)
x = F.leaky_relu(self.BN1(x))
x = self.conv3(x)
x = F.leaky_relu(self.BN2(x))
x = self.conv4(x)
x = F.leaky_relu(self.BN3(x))
x = self.conv5(x)
spp = spatial_pyramid_pool(x,1,[int(x.size(2)),int(x.size(3))],self.output_num)
fc1 = self.fc1(spp)
fc2 = self.fc2(fc1)
s = nn.Sigmoid()
output = s(fc2)
return output
三、Fast R-CNN
1、论文简介
论文名称:《fast R-CNN 》
论文链接:Fast R-CNN
源码(fast-RCNN实践):Fast R-CNN实现
摘要:本文提出了一种基于区域卷积网络的快速目标检测方法(Fast R-CNN)。Fast R-CNN基于之前的工作,使用深度卷积网络对目标proposal进行有效分类。与之前的工作相比,Fast R-CNN采用了多项创新技术来提高训练和测试速度,同时也提高了检测精度。Fast R-CNN比R-CNN快9倍,在测试时快213倍,在PASCAL VOC 2012上得到了更高的mAP。与SPPnet相比,Fast R-CNN训练VGG16的速度快3倍,测试速度快10倍也更准确。
问题:解决目标检测定位的复杂性的时候牺牲了速度、准确性和简化度。
解决措施:提出单阶段训练算法,使之可以联合学习对目标proposal分类和优化空间位置这两个动作。最终结果可以训练非常深的检测网络,如VGG。
Fast R-CNN算法的优点:
- ①较R-CNN和SPPnet更高的mAP;
- ②单阶段训练,用多任务损失;
- ③训练可以更新网络所有层;
- ④特征计算不需要耗费磁盘空间存储。
2、结构设计

过程分解:
①输入整张图像经过两个分支,一个分支将图像送入到卷积网络中得到特征图,另一个分支通过selective search方法提取region proposal;两路分支都是整个Fast RCNN的输入;
②将region proposal映射到CNN的最后一层卷积特征图上;
③对于每个region proposal,ROI池化层使每个RoI生成固定尺寸的特征图;
④每个特征向量输入到一系列FC层中,这些层最终分支为两个同级输出层:一个层对K个目标类加上一个“背景”类生成softmax概率估计,另一层为K个对象类中的每一类输出四个实数,即边框回归偏移量。每组4个值代表了K类中的其中一类的精确边框位置的编码。
ROI池化层
ROI池化层:用最大池化将内含感兴趣区域的特征图转换为小的固定尺寸为H×W大小的特征图(H,W是相互独立的)。本文中ROI池化层是个卷积特征图中的矩形窗,每个ROI都由四元组 ( r , c , h , w ) (r,c,h,w) (r,c,h,w)定义,其中 ( r , c ) (r,c) (r,c)代表左顶部, ( h , w ) (h,w) (h,w)代表高和宽。这些坐标都是对应原图像的,而不是输出的特征图的,因此还需要把原图像的坐标系映射到特征图上!
ROI池化层过程:将h×w的region proposal用尺寸为h/H,w/W的子窗分割为H×W大小的网格然后将region proposal映射到最后一个卷积层输出的特征图,最后计算每个网格里的最大值作为该网格的输出。其中池化操作在每个特征图通道中都是独立的。ROI层其实是one-level SPP层的一种特殊情况。
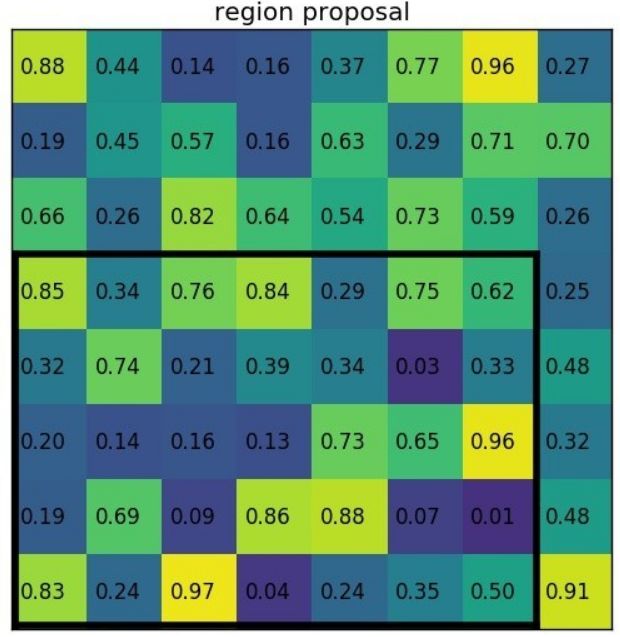
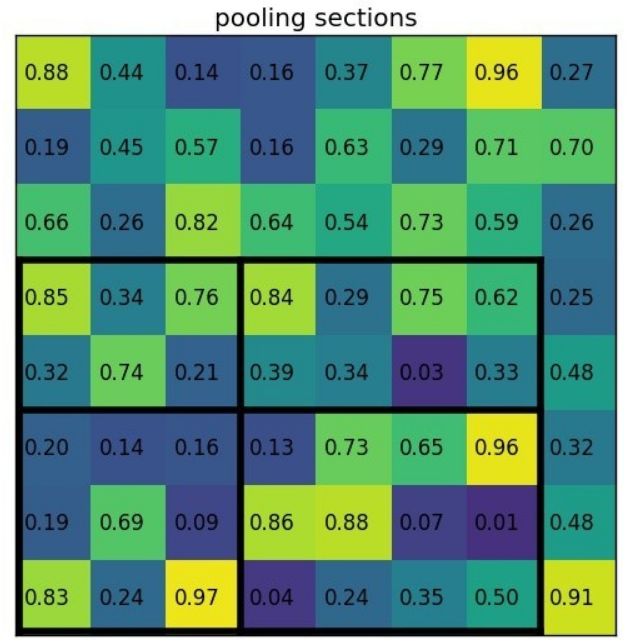
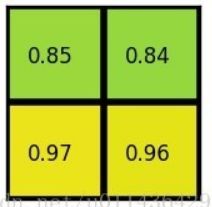
ROI池化过程:
①输入的固定大小的feature map
②region proposal 投影之后位置(左上角,右下角坐标):(0,3),(7,8)
③将其划分成(2×2)个sections(因为输出大小为2*2),我们可以得到:
④对每个section做max pooling,可以得到:

multi-task损失
Softmax Loss(检测分类概率)+Smooth L1 Loss(检测边框回归)对分类概率和边框回归联合训练。
总损失:![]()
分类损失:![]()
回归损失: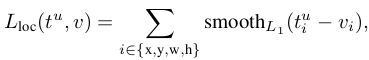
其中Smooth L2 loss: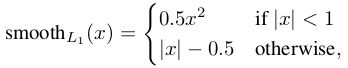
截断SVD方法
整张图的分类上,FC层花费的时间少于卷积层;检测时要处理的ROI数量非常大,前向传播一半时间都用在FC层计算上。**用截断SVD方法压缩可以使得参数量巨大的FC层(也即ROI数量较大)加速更加容易。**被u×v大小的权重矩阵W参数化的FC层近似分解为: ![]()
这里U是由W的前t个左奇异向量组成的u×t矩阵, ∑ t \displaystyle \sum t ∑t是一个包含W顶部的t个奇异值的t×t对角矩阵,V是W的前t个右奇异向量组成的v×t矩阵。SVD方法将参数计算量由uv减少到了t(u+v)。
为了压缩网络,将与W对应的单个FC层替换为两个FC层(FC层之间没有非线性关系)。第一层使用没有偏置的权重矩阵 ∑ t V T \displaystyle \sum t V^T ∑tVT,第二层使用矩阵U(具有与W有关联的初始偏置)。
3、论文总结及改进点
相比RCNN本文不同点为:
- 最后一层卷积层后加入ROI池化层
- 使用softmax分类损失+Smooth L1回归损失的多任务损失函数,将边框回归直接加入到CNN中训练,同时用sotfmax代替SVM。
- 在检测中使用截断SVD方法加速FC层计算
对RCNN的改进点:
- fast RCNN将整张图归一化后送入CNN,在最后一层卷积层输出的特征图上加入region proposal,使得在此之前的CNN运算可以共享。
- fast RCNN在训练时只需要将一张图像送入到CNN,每张图像一次性提取所有特征和region proposal,训练数据在GPU内存里直接进Loss层,减少了重复计算以及硬盘存储需要。
- 使用ROI池化层,不需要再对input进行Corp和wrap操作,避免像素的损失,巧妙解决了尺度缩放的问题。
对RCNN和SPPnet的共同改进点:
- Fine-tuning使用单阶段流水线的方式,联合优化了softmax分类器和边框回归器。
- Fast RCNN训练过程中的SGDmini batch是分层采样的,使得训练过程可以更新网络所有层的权重。这利用了训练中的特征共享。
fast RCNN缺点:
- 仍使用selective search方法得到region proposal,整个检测流程时间大多消耗在这上面(生成region proposal大约2~3s,而特征提取+分类只需要0.32s)。
4、ROI池化层代码(Pytorch)
import torch.nn.functional as F
def ROI_Pooling(feature_map, rois, size):
Pooled_ROI = []
rois_num = len(rois)
for i in range(rois_num):
roi = rois[i]
Right, Left, Top, Bottom = roi # ROI映射到特征图之后的坐标
Cut_Feature_Map = feature_map[:, :, Top:Bottoom, Left:Right]
Fixed_Feature_Map = F.adaptive_max_pool2d(Cut_Feature_Map, size)
Pooled_ROI.append(Fixed_Feature_Map)
return torch.cat(Pooled_ROI)
if __name__ == '__main__':
feature_map = torch.randn(1, 512, 15, 13) # 输入为batch_size=1的数据:torch.Size([1, 512, 15, 13])
rois = [(7, 4, 4, 1), (10, 2, 12, 9), (5, 2, 12, 10)]
size = (7, 7)
print(RoI_Pooling(feature_map, rois, size).size()) # 输出为batch_size=3的数据:torch.Size([3, 512, 7, 7])
5、selective search方法提取region proposal代码
import sys
import cv2
def get_selective_search():
ss = cv2.ximgproc.segmentation.createSelectiveSearchSegmentation()
return ss
def config(ss, img, strategy='q'):
ss.setBaseImage(img)
if strategy == 's':
ss.switchToSingleStrategy()
if strategy == 'f':
ss.switchToSelectiveSearchFast()
if strategy == 'q':
ss.switchToSelectiveSearchQuality()
else:
print(__doc__)
sys.exit(1)
def get_rects(ss):
rects = ss.process()
rects[:, 2] += rects[:, 0]
rects[:, 3] += rects[:, 1] # 使用process方法取候选框
return rects
def selective_search(img):
ss = get_selective_search() # 获取selective search方法
config(ss, img, strategy='q') # 设置selective search方法获取模式
rects = get_rects(ss) # 定义候选框
rectsd = []
for i in rects:
rectsd.append({"rect": i}) # 格式为字典,每个字典为一个rect
if len(rectsd) > 2000:
break
return rectsd
6、输出分类概率及Bbox回归网络代码
import torch.nn as nn
from collections import OrderedDict
class Fully_Conection_Model(nn.Module):
def __init__(self):
super(Fully_Conection_Model, self).__init__()
self.First_Sibling_Layer = nn.Sequential(
OrderedDict([('Dropout_1', nn.Dropout()),
('Linear_1', nn.Linear(512 * 7 * 7, 4096)),
('ReLU_1', nn.ReLU(inplace=True)),
('Dropout_2', nn.Dropout()),
('Linear_2', nn.Linear(4096, 4096)),
('ReLU_2', nn.ReLU(inplace=True)),
('Linear_3', nn.Linear(4096, 21))]))
self.Second_Sibling_Layer = nn.Sequential(
OrderedDict([('Dropout_1', nn.Dropout()),
('Linear_1', nn.Linear(512 * 7 * 7, 4096)),
('ReLU_1', nn.ReLU(inplace=True)),
('Dropout_2', nn.Dropout()),
('Linear_2', nn.Linear(4096, 4096)),
('ReLU_2', nn.ReLU(inplace=True)),
('Linear_3', nn.Linear(4096, 4))]))
def forward(self, Model_INPUT):
Flatten_INPUT = Model_INPUT.view(-1, 512 * 7 * 7)
Classification_Output = self.First_Sibling_Layer(Flatten_INPUT)
Bbox_Regression_Output = self.Second_Sibling_Layer(Flatten_INPUT)
return Classification_Output, Bbox_Regression_Output
device = 'cuda'
Fast_RCNN_Model = Fully_Conection_Model().to(device)
四、Faster R-CNN
1、论文简介
论文名称:《Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks》
论文地址:Faster R-CNN
论文源码1:Faster R-CNN实现1
论文源码2:Faster R-CNN实现2
摘要(部分):最先进的目标检测网络依靠region proposal算法来假设目标位置。SPPnet和Fast R-CNN等技术进步缩短了这些检测网络的运行时间,但是region proposal的计算仍是瓶颈。在解决此瓶颈的工作中,我们引入了一个region proposal网络(RPN),它与检测网络共享全图像的卷积特征,从而可以实现几乎无计算损耗的region proposal。RPN是一个全卷积的网络,可以同时预测目标边界和每个位置的目标分数,可以经过端到端的训练,生成高质量的region proposal,在Fast R-CNN中用于检测。然后进一步将RPN和Fast R-CNN合并成一个单一的网络,通过使用注意力机制来共享它们的卷积特征,使得RPN组成成分告诉统一的网络在哪里寻找目标。
目前生成region proposal的方法:
- selective search(一张图2s)
- EdgeBoxes(一张图0.2s)
本文提出的问题1:怎么更快更高效地产生region proposal?
解决方案:用CNN特征图计算得到region proposal,提出了RPN共享卷积层。(一张图10ms)。
RPN特点:①在最后的卷积特征上额外的卷积层
②可以同时在网格的任意位置做区域边界和目标得分的回归
③全卷积网络的一种
④可以端到端训练
⑤可以生成具有广泛尺度和纵横比的region proposal
目前处理多尺度图像的方法:
-
图金字塔方法(在所有尺度上运作)

-
多尺度卷积核金字塔(在特征图上运作)

本文提出的问题2:怎么更高效地处理多尺度、多纵横比问题?
解决方案:提出锚框概念(作为多尺度和纵横比的参考)
方案优点:①可认为是回归参考的金字塔,避免了枚举多尺度的图像或卷积核。
②用在单尺度图像中训练和测试表现优益,利于提高速度。
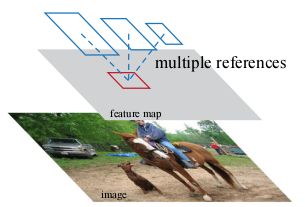
2、结构设计
Faster RCNN包含的模块:①RPN模块 ②检测模块

过程分解:
①输入测试图像
②将整张图片输入CNN进行特征提取
③用RPN生成region proposal,每张图片生成300个RP
④把RP映射到CNN最后一层卷积特征图上
⑤对每个RP,通过ROI池化层使每个RoI生成固定尺寸的特征图
⑥利用Softmax Loss(探测分类概率) 和Smooth L1 Loss(探测边框回归)对分类概率和边框回归(Bounding box regression)联合训练
RPN模块
输入为任意大小的图像,输出为一组矩形region proposal,每个都有目标分数。将此过程封装为FCN(全卷积网络)。目标是使得RPN网络和Fast RCNN的目标检测网络共享计算、共享一组卷积层。
生成RP过程:在最后一层共享卷积层输出的特征图上滑动一个小网络,此网络输入为特征图的n×n空间窗口,每个滑动窗口都映射到低维特征,此低维特征分别喂到两个同级FC层中,一层是Bbox回归层(reg),另一层是box分类层(cls),两个FC层共享所有的空间位置。
RPN模块结构实施:n×n卷积层后跟两个同级的1×1卷积层。

Anchor
在每个滑动窗口位置,同时预测多个region proposal,其中每个位置的最大可能region proposal的数量表示为 k。 因此reg层有 4k 个输出用来编码 k 个框的坐标,cls 层输出 2k 个分数用于估计每个proposal的目标或非目标概率。 将k 个proposal相对于 k 个参考框进行参数化,这些参考框称之为锚点anchor。
**每个anchor位于滑动窗口的中心,并与尺度和纵横比相关。**假设使用三个尺度和三个纵横比,则在每个滑动窗口的位置可以产生k=9个anchor。对于W×H大小的卷积特征图,总共会产生W×H×k个anchor。
特点:平移不变性,对anchor和计算相对于anchor的region proposal的函数来说都有此性质。即平移图像中的目标,proposal也应该平移,与之前相同的函数也能够预测任意位置的proposal。
anchor金字塔
参考多尺度和纵横比的锚框对BBox进行分类和回归,仅仅需要单一尺度的图和特征图,以及单一size的在特征图上滑动的核。多尺度anchor的设计对于cost-free的特征共享来说是一个关键的组成成分。
3、RPN和Fast RCNN共享特征的细节
RPN和Fast RCNN独立训练,用不同的方式修改它们各自的卷积层。有三种共享特征的训练网络方法。
- 交替训练:先训练RPN,再用proposal训练Fast RCNN,然后用 Fast R-CNN 调优的网络来初始化 RPN,这个过程是迭代的。
- 近似联合训练
- 非近似联合训练
本文采取4步交替训练法:通过交替优化来学习共享特征。
第一步:训练RPN网络,用ImageNet预训练模型初始化,对region proposal生成任务用端到端调优的方式;
第二步:将第一步RPN生成的region proposal用在Fast RCNN中训练一个与RPN分离的检测网络,同样用ImageNet预训练模型初始化,在这时两个网络还没有共享卷积层。
第三步:用检测网络初始化RPN训练,固定共享的卷积层,只微调RPN特有的层。这一步两个网络开始共享卷积层。
第四步:固定共享卷积层,微调Fast RCNN特有的层,这一步两个网络共享相同的卷积层并形成一个统一的网络。
4、论文总结及改进点
相对Fast RCNN有两处不同:
- 使用RPN代替原来的selective search方法生成region proposal
- RPN网络和目标检测网络共享卷积层
相对Fast RCNN的优点:region proposal数量下降但质量有所提高且更快速、高效
缺点:
①检测阶段计算冗余。通过costly的RCNN子网(这里RCNN子网指的是:RPN后面的检测子网,ROI后面的检测子网之所以costly就是因为检测之前有两层FC) 单独传递每个ROI,降低了网络速度,尤其当region proposal数量巨大时。

②RoI的分类性能较好,这是因为在第一层FC层之前有一个GAP层(用来减少FC层计算量),但是这样做会不利于RoI的空间定位性能。
五、RFCN
1、论文简介
论文名称:《R-FCN: Object Detection via Region-based Fully Convolutional Networks》
论文链接:RFCN
论文源码:RFCN实现
摘要(部分):提出了基于区域的全卷积网络,以实现准确高效的目标检测。与以前的Fast/Faster RCNN相比,我们的基于区域的检测器是全卷积的,几乎所有计算都在整个图像上共享。为了实现这一目标,我们提出了位置敏感分数图来解决图像分类中的平移不变性和目标检测中的平移变性之间的矛盾。因此,我们的方法可以自然地采用全卷积的图像分类器的backbo- ne(如Resnet)用于目标检测。实现了高mAP的同时每幅图像的测试时间也缩短为170ms,比Faster R-CNN对应模块快2.5-20倍。
全卷积层定义:最后一层是FC层时,目标检测会在微调时移除并用卷积层替代该层
早期问题:目标检测中使用全卷积来构造共享的卷积子网络使得检测精度很低,与网络优越的分类精度不匹配。
解决方案:Faster RCNN中的ROI池化层插入到两组卷积层之间,构建了一个更深的ROI子网,提高了精度。
本文提出的问题1:在上述解决方案中每个ROI计算不共享,速度较慢。
分析问题的根源:图像分类中的平移不变性与目标检测中的平移变性之间有矛盾。
解决方案:将ROI池化层插入到卷积层中,引入了R-FCN。
该方案优点:这种区域特定操作打破了平移不变性,在ROI之后的卷积层通过不同的区域不再具有平移不变性。
本文提出的问题2:可以将全卷积图像分类器有效转换为全卷积目标检测器吗?
回答:可以实现
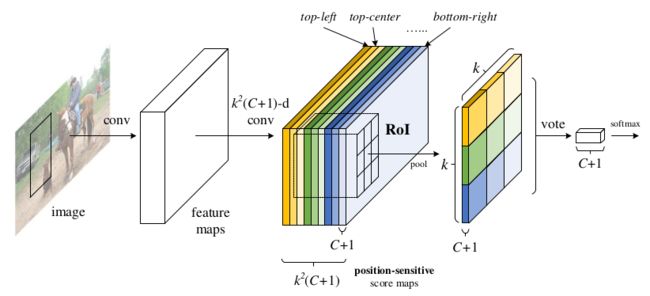
平移变性纳入FCN的具体做法(R-FCN):用一些特定的卷积层构建一组位置敏感分数图作为FCN的输出,每个分数敏感图都根据相对的空间位置对位置信息进行编码。在FCN顶部添加一个对位置敏感的ROI层,该层引导这些分数图信息,后面不跟权重层(卷积\FC)。整个框架是端到端的,所有需要学习参数的层都是卷积层且共享整张图像。本文需要为目标检测编码空间信息。纳入平移变性关键思想如下:
2、结构设计
①共享卷积子网:去掉了最后的 average pooling 层和全连接层,并新增了一个卷积层进行降维,共101个卷积层。
②RPN子网:与Faster RCNN一致
③检测分类子网:1个 Score Maps层 + 1个 ROI Pooling层,与RPN并联。RPN和R-FCN共享特征
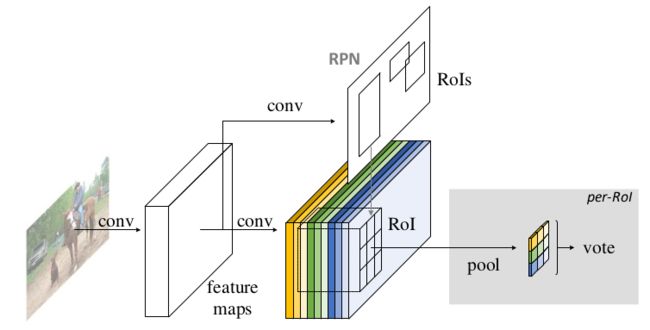
过程:①给定ROIs,R-FCN将ROI进行分类(目标种类+背景类)
②图像经过CNN到达最后一层特征图,最后一层卷积层针对每个类别产生 k 2 k^2 k2个位置敏感图,假设有C个目表类别,因此会有 k 2 ( C + 1 ) k^2(C+1) k2(C+1)通道的输出层。 k 2 k^2 k2个位置敏感图是对应于描述特定位置的(如{top-left, top-center, top-right, …, bottom-right})。其中每个分数图的大小和最后一层特征图大小一致。
③ 设计一个位置敏感的ROI池化层,将Fast RCNN中的ROI划分为k×k个区域。**R-FCN以ROI池化层作为结尾,该层汇总最后一个卷积层的输出,并为每个ROI生成分数,与SPP和Fast RCNN不同的是本文的池化层是选择池化,每个k×k的ROI池化核从k×k个分数图中选出一个最后做聚合响应。(在ROI区域分类中详细解释)**通过端到端学习,该ROI池化层引导最后一个卷积层学习特定的位置敏感分数图。在ROI层之后没有可学习的层,实现了几乎free的区域计算,加快了训练和推理。
backbone
去掉GAP层和FC层的ResNet + 一个1×1的1024维卷积层(降维)+ 一个 k 2 ( C + 1 ) k^2(C+1) k2(C+1)通道的卷积层(产生分数图)
ROI区域的分类
解释过程中步骤③怎么从 k 2 ( C + 1 ) k^2(C+1) k2(C+1)个位置敏感分数图得到k×k大小且通道数为C+1的map。即位置敏感ROI池化操作(PSROIPooling),本文所用池化是平均池化。
假设一个类别下的9个位置敏感分数图如下:

下面为划分为k×k,且k=3情况下的位置对应关系
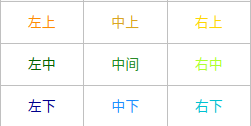
①首先处理类别为1的部分,如下面表格所示:

②从下图所示的图中得到9个特征图,然后对每个特征图按照各自敏感的区域将其框出来(比如在这9个feature map中第一个表示左上位置,那么提取这个feature map的ROI区域,然后将其分成k∗k的网格,提取其表示的左上位置,即第一个网格)
③对抽取出来的ROI池化后的部分再做平均池化,然后按照位置组成一个k×k,即3×3大小的矩阵。
④对这个k×k大小的矩阵做投票(本文为求平均操作)得到一个值。
⑤对类别2至C+1分别进行步骤①至④的操作,从而最终得到一个1×(C+1)大小的向量如下图:
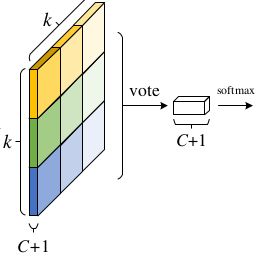
⑥对这个向量进行softmax操作,从而估计当前特征图对应的ROI区域是何类别。
ROI区域的回归
上面提到从基CNN的特征图中得到ROI池化知道softmax的分类,现在是如何微调ROI本身的区域,与ROI区域的分类较相似。
①位置敏感分数图是 k 2 ( C + 1 ) k^2(C+1) k2(C+1)通道的,现在依然从基CNN的特征图中连接出一个与位置敏感分数图并列的 4 k 2 4k^2 4k2通道的图,用来做候选框坐标微调,如下所示:

②像ROI区域分类部分一样做步骤①至④,最后得到一个1×4的向量,这个向量将Bbox参数化为 t = ( t x , t y , t w , t h ) t=(t_x,t_y,t_w,t_h) t=(tx,ty,tw,th)。
③整个步骤执行的是与类无关的bbox回归,但背景类除外。
3、论文总结
本文提出一种平衡目标检测任务平移变性和分类任务平移不变性矛盾的解决方案。本文贡献在于:
①提出用特定卷积层构建一组位置敏感分数图,使用PSROI池化层,使得这种ROI池化层可以引导敏感分数图信息。
②提出PSROIPooling操作。
③实现了真正的计算共享
对Faster RCNN的改进点:①实现了全部子网的计算共享
RFCN缺点:
①用了cost-free的RCNN子网(这里的检测子网之所以cost-free是因为检测没有用到网络运算,直接用平均池化+投票+softmax),但是因为要生成一个巨大的分数图,因此整个网络仍非常耗时。
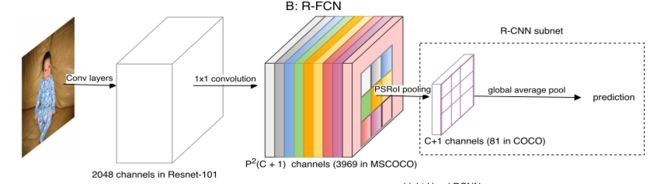
②直接在位置敏感池化操作之后池化预测结果,当没有ROI-wise的计算层时,整体效果还不如Faster RCNN。
六、Light-Head RCNN
1、论文简介
论文名称:Light-Head R-CNN: In Defense of Two-Stage Object Detector
论文链接:Light-Head RCNN
论文源码:Light-Head RCNN实现
摘要:在本文中首先研究了为什么典型的两阶段方法不如YOLO和SSD等单阶段快速检测器快。我们发现Faster RCNN和R-FCN在RoI扭曲之后或之前要执行密集计算。Faster R-CNN涉及RoI识别层的两个FC层,而RFCN生成一个大的分数图。因此由于该体系结构中的重型头部设计,这些网络的速度很慢。即使我们显著减少了基础模型,计算成本也无法相应地大幅降低。
我们提出了一种新的两阶段检测器——Light-Head RCNN,以解决现有方法的不足。在我们的设计中,我们通过使用一个轻薄的特征图和一个计算成本低昂的R-CNN子网(池化层和单个FC层),使网络的头部尽可能轻。我们基于ResNet-101的Light-Head RCNN在保持效率的同时,优于COCO上最先进的目标检测器。更重要的是,我们的LightHead R-CNN只需用一个小型网络(例如Exception)替换backbone,就可以在COCO上以每秒102帧的速度获得30.7 mmAP,在速度和精度上都显著优于yolo、SSD这种单阶段检测器。
本文提出问题:能否让两阶段检测器兼顾准确性和速度?
解决方案:提出light-head设计,特别是应用一个大核的可分离卷积去产生较薄的有着少量通道数的特征图。在ROI池化层后面再跟上一个FC层(用来获取分类和回归的特征表示)。
该方案优点:
①大大减少了ROI子网的计算。
②无论使用大型backbone还是小型都能够在速度和精度上达到满意的效果(这一点Faster R-CNN和R-FCN就做不到,如果backbone替换成小网络那么精度就跟不上)。
③对大型backbone网络具有灵活性。
2、结构设计
本文所指的“头”是指连接到backbone基CNN的结构,具体的“头”有两个部分:RCNN子网和ROI warping。
RCNN检测子网

为RCNN检测子网设计了一种简单、计算量小的FC层,实现了准确率和速度上的均衡。
问题:但是FC层的计算和内存损耗仍依赖于ROI池化操作之后的图的通道数量。
RoI warping
为解决上面检测子网中可能出现的问题,用到RoI warping使得特征图形状固定。提出产生较少通道数的特征图(轻薄特征图)之后跟上一个卷积RoI warping层这样的方法。不仅可以在轻薄特征图上提高精度,也可以减少内存损耗和计算量。
ROI warping原理:与ROI池化不一样,ROI池化过程中需要ROI区域的左上角和右下角的坐标,而ROI warping池化需要的是ROI区域的中心坐标和宽高。
解释:W、H代表输入的ROI区域的宽和高;u、v代表ROI区域在原始图像的坐标;W‘、H‘代表输入ROI区域进行crop和resize操作后输出的ROI区域的宽高;u‘、v‘代表输入ROI区域进行crop和resize操作后输出的ROI区域的坐标,G代表crop和resize操作。具体操作如下,分别对宽,高做插值。
最终将ROI区域从(x-w/2,y-h/2)×(x+w/2,y+h/2)变换为(-W‘/2,-H’/2)×(W‘/2,H’/2)。



light-head RCNN结构分解
基CNN(用作特征提取):设定为‘L’时backbone为ResNet-101,设定为‘S’时backbone为如Xception这样的小网络。
轻薄特征图:在Xception的第五层卷积层上应用大型可分离卷积层,结构如下图。
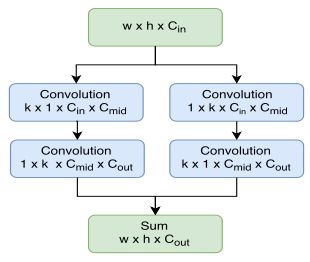
让 k = 1.5 k=1.5 k=1.5,设定为’S’时 C m i d = 64 C_{mid}=64 Cmid=64,设定为’L’时 C m i d = 256 C_{mid}=256 Cmid=256,降低 C o u t C_{out} Cout到10×p×p因此生成的图比RFCN生成的更加轻薄。因为卷积核大因此感受野也更大,这使得ROI warping之前的特征图更加powerful。
RCNN子网:仅用一个通道数为2048的FC层(无dropout),后跟两个同级FC层预测ROI的分类和回归。
RPN网络:使用Xception的第四层卷积层上的特征。RPN预定义了一组锚点,由几个特定的尺寸和纵横比控制。
3、论文总结
本文贡献:
①提出light-head设计(RCNN检测子网+ROI warping)
②使用大核可分离卷积层产生轻薄特征图
③使用RoI warping方法在轻薄特征图上提升精度并减少内存损耗和计算。
对RFCN改进点:
①将heavy head替换为light-head设计,用可分离卷积产生轻薄特征图后大大减少了ROI池化层的计算量。
②backbone的设计更为灵活,改变为小型backbone也能达到较高精度。
Light-Head RCNN缺点:①仍然在网络顶层做预测,没有考虑到尽管CNN网络深层的特征对分类有益但对于目标的定位却无益的问题。
七、FPN
1、论文简介
论文名称:Feature Pyramid Networks for Object Detection
论文链接:FPN
论文源码:FPN实现
摘要:特征金字塔是用于检测不同尺度目标的识别系统的基本组成部分。但最近的深度学习目标检测器避免了金字塔表示,部分原因是金字塔是计算和存储密集型的。在本文利用深度CNN固有的多尺度、金字塔层次结构,用额外成本构建特征金字塔。我们开发了一种具有横向连接的自上而下的体系结构,用于在各种尺度上构建高级语义特征图,这一架构称之为FPN,它作为特征提取器在多个应用中显示了明显的改进。在一个基本的Faster R-CNN系统中使用FPN,在COCO检测基准上可实现SOTA,同时也超过了所有现有的单模型检测器,包括COCO 2016挑战赛获奖者中使用的检测器。此外我们的方法可以在GPU上以6 FPS的速度运行,因此是多尺度目标检测的一个实用而准确的方案。
特征金字塔的发展历程

特征化的图金字塔:每一层都在检测,不同比例的图像单独计算特征,每一层都会产生特征语义,(浅层的网络更关注于细节信息,高层的网络更关注于语义信息),但速度很慢。此为手工设计的阶段。
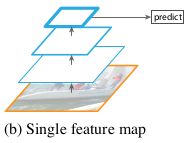
单一特征图:只是适用于单一尺度的图片,显著特点就是速度快!卷积网络可表示高级语义特征,尺度变化的鲁棒性也很强,取代了手工设计特征。
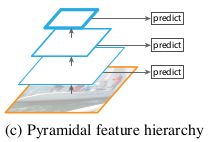
金字塔特征分级:利用卷积神经网络来设计,卷积网络本身就是一个多层的金字塔型,直接利用卷积网络中间层的特征图,这样也就不会有多余的计算消耗,但是这样的设计不适用于目标识别,网络前几层的特征图只包含低级别特征。
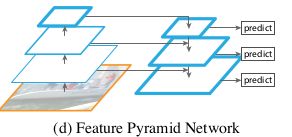
本文所用结构FPN:利用卷积神经网络各层次特征,同时创建在所有尺度上都具有强大语义特征的金字塔。是一种依靠通过自上而下的途径和横向连接的方式将低分辨率、语义强的特征与高分辨率、语义弱的特征相结合的体系结构。
此结构优点:
①将不同层级的语义信息结合起来,因此在所有层级上都具有丰富的语义信息。
②可以由单一图像尺度快速构建得到金字塔结构
③可以在不牺牲性能、速度、内存的情况下构建网络内的特征金字塔,此金字塔可以代替之前的特征化图像金字塔。
自上而下结构和跳跃式连接结构

以前的结构是产生一个高分辨率单一高级特征图,并按照最好的特征层进行预测。
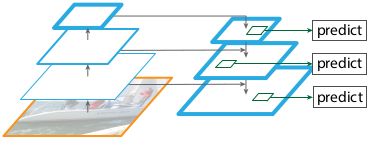
**本文所用结构:**与上面的结构相似,但是是将这种结构当做特征金字塔来使用,目标检测的预测在每层上是单独进行的。
本文所用方法优点:
①仅用FPN+基础Faster RCNN就可以超过任何单模型性能达SOTA
②能够衍生到掩膜region proposal,提高了实例分割的平均recall和速度
③此金字塔结构可以端到端地在所有尺度上训练,并在训练\测试中都能用(在图金字塔这么使用会出现内存问题)。
2、结构设计
目标:利用卷积网络金字塔特征层次(语义信息是从低到高的),用高层次语义信息建立特征金字塔。
方法:将一个单尺度任意尺寸图像作为输入,以全卷积形式输出多层次成比例尺寸的特征图,此过程独立于backbone卷积结构。
结构:使用backbone为ResNet,金字塔结构采用自下而上路径、自上而下路径以及横向连接。
自下而上路径(具高分辨率低语义)
原理:这指的是基础网络的前向传播,为每一个阶段定义一个金字塔级别,FPN利用每一次pooling前(特征图长宽缩小2倍)的特征图构造特征金字塔(通过卷积计算), 因为每个阶段的最深层应该具有最强的特征。
做法:对于ResNets,作者使用了每个阶段的最后一个残差块的特征激活输出。将这些残差模块输出表示为{C2, C3, C4, C5},对应于conv2,conv3,conv4和conv5的输出,并且注意它们相对于输入图像具有{4, 8, 16, 32}像素的步长。不将conv1纳入金字塔因为占用内存太大。
自上而下路径(具低分辨率高语义)和横向连接
原理:相当于将语义更强的高层特征图进行上采样得到高分辨率特征,然后把该特征横向连接到自下而上的路径来增强这些特征。注意:横向连接的两层特征空间尺寸要相同,横向连接的主要作用是结合自下而上(低层)的高分辨率特征以及更精确的定位信息。
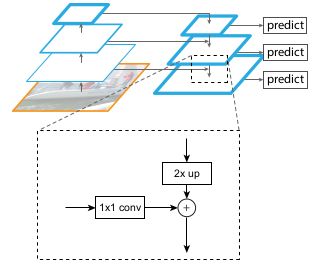
做法:将自下而上路径中最上层的特征图通过1x1的卷积(压缩通道)后,产生的特征图作为自上而下路径的起点,然后逐步上采样,每次使长宽扩大两倍,上采样后的特征图与对应自下而上的特征图(进行一次1x1的卷积以压缩通道使得和后一层的通道数相同)相结合(对应元素相加)。在自上而下路径中的特征图都生成完后,然后我们在每个融合图上进行3×3卷积来生成最后的特征图,这是为了减少上采样的其他影响。最后的特征图为{P2、P3、P4、P5}为FPN的输出,与{C2、C3、C4、C5}相匹配。因金字塔所有层都用的共享分类器\回归器,因此自上而下的路径以及横向连接中产生的所有特征图的通道数固定为256,并且这些额外的卷积层也是256维度的输出且没有非线性的激活函数。
FPN用在RPN
用FPN代替RPN中单一尺度的特征图。特征金字塔的每一层依然用3×3卷积和两个同级1×1卷积,因网络的头是在所有金字塔层级中滑过所有区域,因此在特定的层中不需要用到多尺度anchor。我们设定每一层的anchor都是单一尺度的,分别在{P2、P3、P4、P5、P6}定义了anchor的所占区域为 3 2 2 、 6 4 2 、 12 8 2 、 25 6 2 、 51 2 2 {32^2、64^2、128^2、256^2、512^2} 322、642、1282、2562、5122像素。在每一层应用Faster RCNN中的anchor多纵横比{1:2、1:1、2:1},因此金字塔共有5×3=15种anchor。
优点:网络头的参数在所有金字塔层中都是共享的,共享参数的优异性能表明金字塔的所有层都在共享相同等级的语义信息。此优点可以类比到特征化图金字塔上,即头部分类器可以应用于在任何图像尺度下计算出的特征图上。
FPN与RPN设定上的区别:RPN在每一张特征图上设置不同尺度的anchor,FPN在每一层特征图上只设定单一尺度的anchor。
FPN用在Fast RCNN
需要为金字塔的不同层准备不同尺度的ROI。将宽高分别为w、h(相对于网络的输入图像)的ROI分配给特征金字塔的 P k P_k Pk级,通过以下等式:
![]()
这里224代表ImageNet预训练尺寸, k 0 k_0 k0是 w × h = 22 4 2 w×h=224^2 w×h=2242的ROI区域应该被映射到的目标层级。上面的方程可以这么理解:首先设定 k 0 = 4 k_0=4 k0=4,如果ROI尺寸变小了,那么它应当被映射到一个更高分辨率的层,得到的 k = 3 k=3 k=3(层级降低)。
让预测头(分类器和BBox回归器)放在所有层的所有ROI上,不论哪一层这些头都是共享参数的。ROI池化层简单提取得到7×7特征图后,后跟两个FC层(每个都有ReLU),这种2-FC的MLP头要比标准ResNet的conv5头构建特征金字塔来得更快、更轻量化。
整个FPN用在Faster RCNN+RPN(没错就是Faster,没写错)结构图如下:
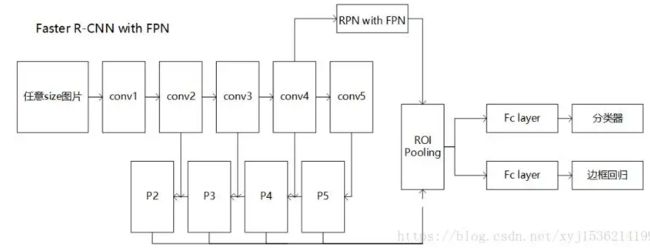
3、论文总结
本文贡献:
①利用之前学者提出的结构,但是是以特征金字塔的形式使用的。提出FPN结构。
②将特征金字塔高层的高语义特征和低层的高分辨率特征相结合,使得每层都有较丰富的语义信息以及较精确的定位信息
③可以由单一尺度图像快速构建金字塔结构,而不牺牲性能、速度、内存。
④FPN结构可以端到端地在所有尺度上训练,并在训练\测试中都能用到。
缺点:
①结合的层仍然比较多,会增加计算量,降低目标检测系统的运行速度。
②利用FPN的思想,改变特征提取部分,特征层变多,ROI pooling也增加了,网络变得较为臃肿。
FPN大致运算结构:

4、FPN代码(pytorch)
import torch
import torch.nn as nn
import torch.nn.functional as F
class SamePad2d(nn.Module):
"""Mimics tensorflow's 'SAME' padding.
"""
def __init__(self, kernel_size, stride):
super(SamePad2d, self).__init__()
self.kernel_size = torch.nn.modules.utils._pair(kernel_size)
self.stride = torch.nn.modules.utils._pair(stride)
def forward(self, input):
in_width = input.size()[2]
in_height = input.size()[3]
out_width = math.ceil(float(in_width) / float(self.stride[0]))
out_height = math.ceil(float(in_height) / float(self.stride[1]))
pad_along_width = ((out_width - 1) * self.stride[0] +
self.kernel_size[0] - in_width)
pad_along_height = ((out_height - 1) * self.stride[1] +
self.kernel_size[1] - in_height)
pad_left = math.floor(pad_along_width / 2)
pad_top = math.floor(pad_along_height / 2)
pad_right = pad_along_width - pad_left
pad_bottom = pad_along_height - pad_top
return F.pad(input, (pad_left, pad_right, pad_top, pad_bottom), 'constant', 0)
def __repr__(self):
return self.__class__.__name__
class FPN(nn.Module):
def __init__(self, C1, C2, C3, C4, C5, out_channels=256):
super().__init__()
self.out_channels = out_channels
self.C1 = C1
self.C2 = C2
self.C3 = C3
self.C4 = C4
self.C5 = C5
self.P6 = nn.MaxPool2d(kernel_size=1, stride=2)
self.C5_conv1 = nn.Conv2d(2048, self.out_channels, kernel_size=1, stride=1)
self.P5_conv3 = nn.Sequential(
SamePad2d(kernel_size=3, stride=1),
nn.Conv2d(self.out_channels, self.out_channels, kernel_size=3, stride=1),
)
self.C4_conv1 = nn.Conv2d(1024, self.out_channels, kernel_size=1, stride=1)
self.P4_conv3 = nn.Sequential(
SamePad2d(kernel_size=3, stride=1),
nn.Conv2d(self.out_channels, self.out_channels, kernel_size=3, stride=1),
)
self.C3_conv1 = nn.Conv2d(512, self.out_channels, kernel_size=1, stride=1)
self.P3_conv3 = nn.Sequential(
SamePad2d(kernel_size=3, stride=1),
nn.Conv2d(self.out_channels, self.out_channels, kernel_size=3, stride=1),
)
self.C2_conv1 = nn.Conv2d(256, self.out_channels, kernel_size=1, stride=1)
self.P2_conv3 = nn.Sequential(
SamePad2d(kernel_size=3, stride=1),
nn.Conv2d(self.out_channels, self.out_channels, kernel_size=3, stride=1),
)
def forward(self, x):
x = self.C1(x)
x = self.C2(x)
c2_out = x
x = self.C3(x)
c3_out = x
x = self.C4(x)
c4_out = x
x = self.C5(x) # c5_outy
m5 = self.C5_conv1(x)
m4 = self.C4_conv1(c4_out) + F.upsample(m5, scale_factor=2)
m3 = self.C3_conv1(c3_out) + F.upsample(m4, scale_factor=2)
m2 = self.C2_conv1(c2_out) + F.upsample(m3, scale_factor=2)
p5_out = self.P5_conv3(m5)
p4_out = self.P4_conv3(m4)
p3_out = self.P3_conv3(m3)
p2_out = self.P2_conv3(m2)
# P6 is used for the 5th anchor scale in RPN. Generated by
# subsampling from P5 with stride of 2.
p6_out = self.P6(p5_out)
return [p2_out, p3_out, p4_out, p5_out, p6_out]
八、Mask R-CNN
1、论文简介
论文名称:Mask R-CNN
论文链接:Mask R-CNN
论文源码:Mask R-CNN实现1
Mask R-CNN实现2
detectron2
注:第三个链接中的detectron2可以实现目标检测中的Faster RCNN, RetinaNet, RPN, Fast RCNN, 实例分割中的Mask RCNN, 人类关键点检测中的Keypoint RCNN, 全景分割中的Panoptic FPN。(安装detectron2建议在linux环境下进行,且按照官方给出的第二中方法安装detectron依赖直接能跑通源码)
摘要:我们提出了一个概念简单、灵活且通用的目标实例分割框架。我们的方法可有效地检测图像中的目标,同时为每个实例生成高质量的分割掩膜,将该方法称为Mask R-CNN,通过添加一个用于预测对象掩码的分支,此分支与用于BBox识别的现有分支并行,扩展了Faster RCNN。Mask R-CNN训练起来很简单,而且在Faster R-CNN的基础上增加了一小部分开销。此外Mask R-CNN很容易推广到其他任务,例如允许我们在相同的框架内估计人体位姿。我们展示了COCO系列挑战三个方面的最佳结果,包括实例分割、BBox目标检测和人物关键点检测。Mask R-CNN在每项任务上都超过了所有现存的模型框架。我们希望这种简单有效的方法可以作为一个坚实的基础,帮助简化实例级识别的未来研究。
本文提出问题1:目标检测有Fast/Faster RCNN,语义分割有FCN,实例分割没有一个灵活、鲁棒且训练推理都较快的框架。
分析:实例分割需要图中所有目标都得到正确检测且每个实例都要得到准确分割。需要结合目标检测和语义分割
本文目标:开发一个对实例分割有利的框架。
提出模型:Mask RCNN,是对Faster RCNN的一个延伸,即在每个RoI区域添加一个预测分割的任务分支,此分支和之前Faster RCNN的分类任务分支和BBox回归任务分支并行。mask分支是一个应用在每个RoI区域的小FCN,以像素到像素的方式对每个region proposal进行预测分割mask,仅添加了少量计算,不影响整个Mask RCNN的速度。

本文提出问题2:Faster RCNN不是为网络输入和输出之间的像素与像素对齐而设计的,那Mask RCNN该如何解决像素与像素间对齐的问题呢?
解决方案:提出RoIAlign层代替Faster RCNN中的RoI池化层。该层无量化且保留了提取的空间位置信息。
RoIAlign层优点:
①使得mask任务准确率变高,能够在严格的定位指标下实现更好的性能。
②依赖于网络的RoI分类分支去预测类别。
2、结构设计
Mask R-CNN
第一阶段:RPN,第二阶段:并行预测分类概率+Bbox回归+每个ROI的mask(并行)
每个ROI的loss计算:L = Lcls + Lbox + Lmask,分类损失为softmax loss,回归损失为smoothl1 loss,Lmask为平均二值交叉熵损失。
Lmask的定义:
每个ROI的mask分支有 K m 2 Km^2 Km2维度的输出,对分辨率为m×m的K个二进制掩膜进行编码,K个类别中的每一个都对应一个编码。为此采用每个像素的sigmoid,并且定义Lmask为平均二值交叉熵损失。对一个与GT类别k有关联的ROI,Lmask仅由第k个mask输出定义(其他mask输出不对Lmask产生影响)。这种对mask的定义使得产生的mask在每个类别与其他类别之间的竞争消失,这与FCN里的类别竞争全然不同。
Mask表示
不同于类别标签和边框回归通过FC层不可避免地折叠为短输出向量,本文提取掩膜的空间结构可以通过卷积提供的像素到像素的对应关系自然地得到处理。
像素到像素的动作需要ROI特征(小特征图)能很好地对齐,以保持每个像素之间的空间对应上,基于此动机,我们提出了RoIAlign层,该层在掩膜预测中起关键作用。
RoIAlign
ROI池化层缺点:考虑到ROI池化层需要进行两次量化取整操作,每进行一次都会有精度的损失。第一次是ROI pooling之前预测的边界框是个float数值,而不是整数,这样就涉及到一次取整的操作,取整后才可以输入ROI Pooling。第二次是ROI Pooling需要对提取的ROI做pooling操作,输出一个7×7大小的feature map,即7×7个bin。这样ROI的长度或者宽度除以7,得到的也是一个float数值,而非整数,这个时候又涉及到一次量化取整的操作。那么无法保证输入像素和输出像素是一一对应,首先他们包含的信息量不同(有的是1对1,有的是1对2),其次他们的坐标无法和输入对应起来。这对分类没什么影响,但是对分割却影响很大。
ROIAlign:为避免ROI边界框或bin引起的量化误差,用双线性插值法计算每个ROI框的bin中的4个随意采样位置的输入特征精确值并聚合起来(使用最大值或平均值)。
ROIAlign层原理:
首先在输入ROIAlign之前的边界框的点还是和ROI池化一样,采用同样的思想得到,同样是一个float数值,但是这个数值对应的位置的像素不需要进行双向性插值得到。ROIAlign操作同样是需要输出一个7×7的feature map,在经过ROIAlign之后,与ROI池化一样,也是得到7×7个float类型的框的位置(x1, y1)、(x2, y2),也就是bin区域。如下图中的红色虚线框。对于每一个bin区域,构造其中间的N个点,N需要预先设置,图中N=4,这样对其平均分成3×3块,bin区域的中间就会生成4个需要的点,这4个红色的点(ai, bi)就是需要的坐标点,同样这4个红色点的坐标也是float类型,上、下、左、右4个整数值位置的像素使用双线性插值得到。最终对每一个bin区域的4个像素求平均,也就是average pooling操作,得到每个bin的输出,最终输出7×7的feature map。

网络结构
使用了不同的backbone:resnet-50,resnet-101,resnext-50,resnext-101;使用了不同的head Architecture:Faster RCNN使用resnet50时,从Block 4导出特征供RPN使用,这种叫做ResNet-50-C4;除了使用上述这些结构外,还使用了FPN,ResNet-FPN。

3、论文总结
本文贡献:
①扩展了Faster RCNN,在分类+回归输出头上加入了一个并行分支mask分支。增加计算量不大,也不影响整体速度。
②提出RoIAlign层,该层对实例分割任务的准确率提升较大。
ROIAlign层缺点:
①ROI区域中的每个bin区域中引入了新的参数,即需要插值的点的数目N。并且这个N是预先设定的,无法根据feature map做自适应调整。
②这N个点的梯度只与其上下左右4个整数位置的像素点有关,而不是整个区域的像素点都有梯度的传递。
引用
[1] R-CNN深度学习目标检测算法
[2] spp-net理解
[3] Fast RCNN理解
[4] faster-rcnn原理及相应概念解释
[5] object detection——rfcn
[6] 目标检测-selective search算法
[7] Selective Search原理及实现
[8] Roi Pooling,Roi Warping pooling,PSROIPooling,Roi Align,PrROI Pooling大总结
[9] FPN论文总结
[10] 【Mask RCNN】论文详解(真的很详细)