多模态深度学习综述总结 与 目标检测多模态融合领域论文推荐
文章目录
- 一、多模态学习定义及应用
- 二、模态表示
-
- 2.1 单模态表示
-
- 2.1.1 语句模态表示
- 2.1.2 视觉模态表示
- 2.1.3 声音模态表示(略)
- 2.2 多模态表示
-
- 2.2.1 模态共作用语义表示(联合表示)
- 2.2.2 模态约束语义表示
- 三、模态传译
-
- 3.1 无界传译
- 3.2 有界传译
- 四、模态融合
-
- 4.1 模型无关融合
- 4.2 模型相关融合
-
- 4.2.1 多核学习方法
- 4.2.2 图像模型方法
- 4.2.3 神经网络方法神经网络方法
- 4.3 总结对比
- 五、模态对齐
-
- 5.1 注意力对齐
- 5.2 语义对齐
- 5.3 总结与对比
- 六、总结
- 七、针对目标检测的多模态融合论文推荐
- 参考文献:
一、多模态学习定义及应用
模态定位为某种类型的信息,如声音、图像、文字等。人们生活在一个多模态相互交融的环境中,生活中的各项决策都考虑了至少两种方面的信息。对单模态信息的学习上,每种模态的异构性决定了其存在不同的学习模型。虽然单模态学习在如今已经取得了显著的进步,在图像单模态的目标检测,文字识别领域等实现了较高的准确率,但是在一些其他领域:例如视频检索、图像语义理解等方面,单模态难以进行处理。
在早期1984年Petajan提出第一个联合视频和声音的多模态视听语音识别系统,实现了性能的大幅度飞跃。christel 等人综合语音识别、图像理解、机器翻译等机器学习的成果,使计算机能够自动地整合视频中的声音、图片和语句等 各模态的信息,并生成一个包含数字视频、声音和语句的可检索数据库,这都是多模态机器学习在前些年来的成果。近些年来,由于神经网络在各个领域的突破,深度学习的加入给多模态学习注入了巨大的活力。
作者总结了当下多模态深度学习所面对的几大关键技术即挑战:
- 模态表示:对于声音、图像等模态的特征表示;
- 模态传译:实现模态之间的转换:例如视频检索将所查询的文字找到对应视频的片段;
- 模态对齐:辨别多个模态元素之间的关系:图像标注中图像中的各区域与语句中各单词的对齐;
- 模态融合:融合多个模态的信息进行预测的过程;

二、模态表示
模态表示是进行多模态任务或者单模态任务的初始处理步骤,其将原始的模态信息进行线性映射或者其他映射将其转化为单个模态的高级表示,不同模态的信息其映射模型也不一:对图像的CNN与面向文字等序列信息的RNN等。这个转化过程存在着一些模态特征的提纯,就像机器学习中的特征工程一样,对于源模态的处理方法一定程度上决定了后面模型的学习上限。因此模态表示对于模式的学习具有非常重要的意义~
2.1 单模态表示
2.1.1 语句模态表示
- 单词one-hot表示与单词的embedding表示
如NLP中对于单词向量的处理一样,one-hot表示对单词进行简单的向量化计算,其只是对于单词的一种标量化标识,无法反映出单词本身的语义信息,并且维数较高。对于低维空间中的表示,使相似语义的单词特征距离缩小,对于每个单词理解为其本身由上下文的单词确定这一合理假设。 - 单词序列的词袋模型表示与单词序列的低维空间表示
对于词袋模型,序列中的单词向量长度与词典单词数相同,单个单词向量的编码值中为1的元素位置与单词在词典中的位置相同,也就是每个单词编码反映了词典中的顺序。没有考虑单词的语义信息。单词序列低维空间表示也就是对单词序列进行语义表示,表示方法从早期的单词语义加权和到后面利用前向神经网络生成段落的段落向量,或者通过encoder-decoder结构(如下图所示),在encoder部分为卷积神经网络,将语句进行卷积与全连接生成句子的一维表示向量。具体的方法还有很多,包括利用RNN的多对一结构生成序列的表示向量等。
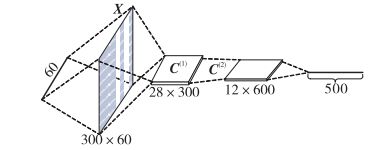
单词模态的独热表示和单词序列模态的袋子表示从统计的观点出发,产生了单词模态和单词序列模态的向量表示,单词模态的低维空间表示和单词序列模态的低维空间表示从语义的角度出发,产生了单词模态和单词序列模态的向量表示。由统计观点获得的对应模态的向量表示忽略了语句模态中固有的单词前后顺序信息,加剧了数据稀疏,且未能提取语句的语义信息。与其相对应的语义观点则很好地解决了上述问题,对单词模态的独热表示 和单词序列模态的袋子表示进行深度的语义提取,产生了低维度的、包含了对应的单词和单词序列语义信息的向量表示。
2.1.2 视觉模态表示
对于视觉模态,存在图片模态这一静态模态与视频模态这一动态模态,图片模态是视频模态的基础。
对于视觉模态表示,我们如今的卷积神经网络能够以极高的准确率对图像进行分类、检测、分割等,已经取得了较高的水平,在卷积神经网络的过程中,将输入的一张图片转化为最终所需的向量,就是一种视觉模态的表示,不过这种表示我们根据下游任务的不同来制定向量的格式。但是传统的卷积神经网络都是利用卷积、池化等操作,具有平移不变性这个偏置假设,在池化的过程中,丢失了图像中的方向等有效的语义信息,胶囊网络解决了这个问题,由动态路由算法代替池化层,减少了有效信息的损失。
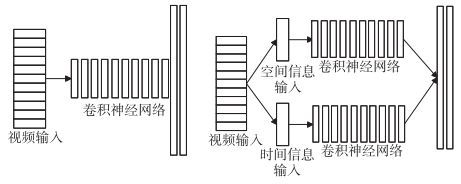
视频模态:视频为在时间维度上的图像序列,它自然地拥有空间属性和时间属性。空间属性是指图像序列中每个图像包含的信息,时间属性是指图像序列中相邻图像的 相互作用信息。因此,在视频模态中,存在两种模态的信息:一类是空间、一类是时间属性信息。对这两种模态的学习分为单通道 卷积神经网络、双通道卷积神经网络,如上图所示。
对单通道卷积的模型,使用3D卷积核或者在**输入融入两种模态(预融合)**都可以。对双通道,要分别计算,例如对于空间输入,即当前的某帧图片,对于时间信息输入,输入连续多个帧的光流位移场来表示其时间属性。另一种方法,使用混合网络,连续输入多帧图像,用CNN对图像进行编码,将逐帧输出的图片输入到LSTM(解码器)中。
显然,由于RNN与CNN的归纳偏置不一样,对于每种模态使用适宜的模型进行表示较好。
2.1.3 声音模态表示(略)
声音模态的表示主要包含声音模拟信号转换为声音数字信号并完成特征向量的提取和提取特征向量的高阶表示两个过程。
2.2 多模态表示
多模态表示基于单模态表示,是包含多个模态数据信息的表示,将多个模态表示在共用的语义空间中,这个空间中含有多个模态的源模态信息转化后的新空间(共用语义空间)下的向量,这个新空间下的向量可以是已经融合成单一的新模态,也可以是与源模态等数量的转化后但是多个模态之间的关系从前面的不相关性到后面的相关性,经历了一个映射。
多模态表示分为两种表示方法,最简单的方法就是进行多模态向量的串联。
那么如何评价一个多模态的表示优劣性,也就是共用语义空间的优劣性呢??
多模态表示的时间空间相干性、聚类性,平滑性等参数可以量化评价。
2.2.1 模态共作用语义表示(联合表示)
模态的共同作用语义,即指融合各单模态的特征表示,以获得包含各模态语义信息的多模态表示。常规流程为:各模态对应的模型进行学习,学习到多模态数据中的各模态数据的模态表示(形成统一的格式),然后在网络结构上继续构建深层神经网络,其输入为各模态的表示,用构建的神经网络融合各模态的语义信息获得模态共作用语义表示。**信息在产生多模态表示的过程中已经完成了融合。**为产生共作用语义表示构建的神经网络包括前向神经网络和递归神经网络。
前向神经网络 :最典型的网络结构为编码器—解码器结构,其中编码器用于压缩和融合各输入模态的表示产生共作用语义表示,解码器根据产生的共作用语义 表示产生学习任务的预测结果:首先对各输入构建解噪自编码器并完成训练,取出完成训练的解噪自编码器中的编码器作为获取各模态表示的神经网络;然后构建深层的编码器—解码器结构的前向网络,通过端到端的训练,使深层的编码器—解码器前向网络能在编码器输出层产生共作用语义表示,在解码器输出层重构各原始输入数据。
编者在这里想到,在我的观点中,如今的BERT、MAE也是通过类似的办法,他们的编码器都用来对源模态建立语义表示,然后在解码器进行重构,解码器的重构性能其实就说明了编码器对源模态的语义表示的优劣性,说明其保留了大量的原始模态信息。
递归神经网络 :也就是类似于RNN的结构,递归神经网络作为上层网络产生共作用语义表示常用在预测结果受时间影响的学习任务中,如视听语音识别任务、视听情感分析。
2.2.2 模态约束语义表示

如上图所示,模态约束语义表示与协调表示的定义则不相同,是指用一个模态的单模态表示结果去约束其他模态的表示,以使其他模态的表示能够包含该模态的语义信息,即用约束进行模态信息的添加。这种方法并不融合各模态的信息并将输入的信息并用于完成预测等机器学习任务,而是将输入模态的表示映射到目标模态的语义空间中,使得在目标模态表示空间中,该映射结果与语义相同的目标模态的相似性大于语义不同的目标模态。
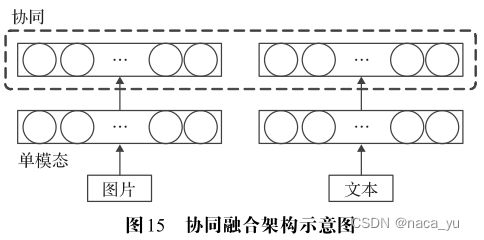
举例说明:有人用LSTM学习语句的表示,把图像的投影空间从名词空间拓展到了语句空间,在完成训练后使得图像在语义空间中的投影和标注语句的表示相似性最大。也就是说,将多个模态投影到新的某个目标模态,并且使这种模态空间中的各个模态之间在同一个物体上拥有相似的描述,其原理如上图所示。
三、模态传译
模态传译是指将模态中包含的信息传译存储在另一个模态中,实现信息在不同模态间的流通,且模态传译的研究主要集中在图片和语句、语句和声音、语言和语言等两个模态之间。即,在目标模态中找到与自己的模态中对应的元素表示,类似于跨媒体检索中的根据文字查找对应的图像帧。其分为有界传译、无界传译。模态传译中间更多的是代表着模态的转换任务,例如翻译、图像标注等任务。
3.1 无界传译
将源模态中的一个元素传译为目标模态集合中的某个元素或多个元素,目标元素没有前后序列关系。例如在多模态深度学习实现跨媒体检索的主要方式是分别学习查询模态元素和目标模态元素的表示,然后用神经网络或者相似性评价函数学习两个模态元素的 相似性,根据相似性结果完成检索。跨媒体混合神经网络(CMDN),将每个模态的表示由模态内和模态间信息合并 生成,用前向神经网络对其相似性进行评估,实现模态检索。
3.2 有界传译
开放性传译是指传译结果为目标模态集合中的有前后顺序关系的多个元素组成的序列。这种具有前后顺序的序列就是语句,代表性的任务就是机器翻译,将我们的一种语言模态转换到另一种不定长的语言模态中。
在图像语句标注任务中,有人采用了编码器—解码器结构,用 googleNet 作为编码器生成图像的固定长度向量表示,使用 LSTM作为解码器将向量解码为语句,整个编码器—解码器将图片转换为描述图片内容的语句。
四、模态融合
多模态融合是指综合来自两个或多个模态的信息以进行预测的过程。关于多模态的融合方法,大致可分为模型无关的融合方法和基于模型的融合方法两大类。其中,模型无关 的方法较简单但实用性低,融合过程容易产生损失;基于模型的融合方法较复杂但准确率高、实用性强,也是目前运用的主流方法。
4.1 模型无关融合
为什么成为无关融合?因为在模型融合的时候不用考虑模型本身的结构,是一种宏观的融合方式,针对融合的阶段而不是针对其他方面。

- 前融合:对多个模态生成模态共作用语义表示(前面提到的),常用的方式有对各模态表示进行相同位置元素的相乘或相加、构建编码器—解码 器结构和用 LSTM神经网络进行信息整合,这种方法适合模态之间差别较小,易于融合的信息,但是由于信源来自于不同的系统,所带的噪声也会影响其他的模态,导致其融合的容错性较差等缺点。
- 后期融合:也称为决策层融合,指的是在每种模态都做出决策(分类或回归)之后才进行的融合,,整合各模型预测结果的常用方式为 平均、投票 、基于信道噪声和信号方差的加权和模型选择(Adaboost和神经网络),但是其融合过程中忽视了多个模态之间的低水平的相互作用,并且融合起来难度较高,而且多个模型的学习带来的参数量过大,会导致学习困难。
- 混合融合:虽然结合了两者的优点,但是混合融合需要具体问题具体分析,单独设计结构。
4.2 模型相关融合
基于模型的融合方法较模型无关的方法应用范围更广且效果更好,现在的研究更倾向于此类方法。常用 方法包括多核学习方法、图像模型方法、神经网络方法等。
4.2.1 多核学习方法
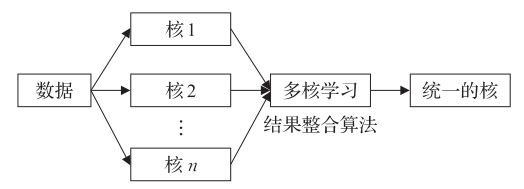
类似于支持向量机方法,利用一个核对数据进行拟合,同样,利用不同的核对不同的输入模态进行拟合,最后结果整合算法对多个核的输出数据进行学习形成统一的核,也就是组合到一个统一的表示空间中,融合过程如上图所示。
由于核方法存在最优解,会学习到最优值,但是核方法的核需要针对每种输入模态人工选择,会导致复杂的人工操作。
4.2.2 图像模型方法
主要通过对图像进行分割、拼接、预测的操作将浅层或深度图形 进行融合,从而得到最终的融合结果。可以看作通过卷积,对不同的图像块在高层或底层特征进行融合。优缺点如下图所示。

4.2.3 神经网络方法神经网络方法
现代常使用长短期记忆网络(LSTM)和循环神经网络(RNN)来融合多模态信息。将神经网络方法应用于多模态融 合中具有较强的学习能力、较好的可扩展性。缺陷是随 模态数量的增加,深度学习可解释性变差,并需要依赖 大量的训练数据。
4.3 总结对比

五、模态对齐
多模态对齐是指辨别来自两个或两个以上的不同模态元素之间的关系。可以说是模态传译中的一个子问题:在图像标注(无界传译任务)中,我们需要在给出的一个图像和对应的标注语句中,辨别图像各区域对应的语句中的单词并进行对齐。根据对齐的方法,将模态对齐分为:注意力对齐和语义对齐。
5.1 注意力对齐
注意力对齐,对于机器翻译、图像标注、语音识别等模态传译的任务上应用较多,因为模态传译的过程中存在模态元素之间的转换,转换结果的对齐要通过对齐算法,尤其是注意力对齐算法。分为软注意力,硬注意力。
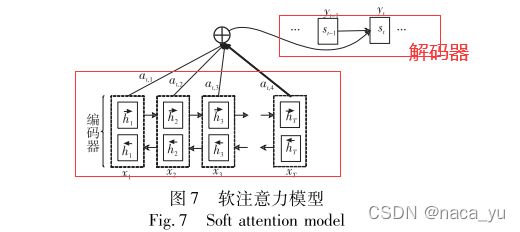
以机器翻译为例,如上图所示,这是软注意力模型,这种注意力利用解码器——即双向RNN提取单词的上下文语义特征表示,后通过解码器——即RNN将上次预测的单词与注意力加权下的单词特征表示输入预测这次单词(最大后验概率)完成对齐。输入语句中的每个单词都以对应的概率对时刻 i 的 输出单词进行对齐。为什么使用这种方式呢?
![]()
上式为注意力强弱参数,si-1(上一个单词的隐变量)作为第 i 个输入的注意力来源。
![]()
上式中,aij为输入表示的 i 时刻的输出单词对应输出模态的对应输入序列的每个单词的相关性权重,Tx为输入源模态的语句的单词数量。由此,每个单词的输入主要来源于两项:一是上一个单词计算的隐向量,二是本单词所代表的上下文向量(即本单词对所有输入单词的注意力向量),所以此时单词的预测,不仅考虑到上个单词,也考虑到本输出的单词最可能对齐的原始输入向量,通过最大后验概率,完成了注意力的对齐。
5.2 语义对齐
,语义对齐最主要的实现方式就是处理带有标签的数据集并产生语义对齐数据集,用深度学习模型去学习语义对齐数据集中的语义对齐信息。
5.3 总结与对比
注意力对齐动态地使用概率对齐实现模态对齐,进而输出预测结果;语义对齐则通过学习数据集中标签与数据之间的对齐信息构建静态的语义对齐数据集,并通过构建模型学习语义对齐信息获得能够产生包含语义对齐信息输出的模型。
两种对齐方式相比,在结构上,注意力对齐模型结构简单,形式灵活;在预测结果上,注意力对齐能更好地考虑到模态元素之间 的长期依赖关系,但是语义对齐能够产生语义对齐数据集,有着直观的评测结果。在实际使用中,注意力对齐由于其优势和较好的性能表现,更频繁地出现在了各学习任务中。
六、总结
决策的本质上:多模态在未来发展的潜力不言而喻,无论是参考自然界动物对于环境的感知或者决策,都充斥着多模态输入信息的融合。可靠性上:由于单模态信息具有较大的噪声,单模态信息采集受限于本身的传感器性能等原因,限制了单模态信息学习器的性能,多模态信息的互补可以有效解决以上问题。应用上:跨模态的任务从一般的机器翻译、图像标注到机器人交互,都会涉及到多模态任务。
对于以上涉及到的多模态关键技术:我认为:首先,多模态的表示是首要任务,模态的表示是否含有大量噪声、是否带有关键信息,决定了后面融合决策的上限,这是任务的基础。在表示的过程中,我们涉及到了模态融合,而根据融合后的任务,如果是类似于机器翻译、图像标注这种模态传译任务,中间就会涉及到模态对齐技术。而如果我们仅仅利用融合后的多模态共作用语义表示进行目标检测等下游任务,就不会涉及到模态对齐或者模态传译的技术。
以上就是个人近期整理并进行总结的一些想法,有一些段落搬运自论文,并已于下文指出,写此文章的目的是为了与大家交流并记录自己想法,如果错误,非常感谢您的指出!
七、针对目标检测的多模态融合论文推荐
对于目标检测,纯图像检测已经能够达到很好的精度,但是对于小目标或者重叠目标等任务,受限于传感器本身的缺点,性能没有较大提升。但是多传感器的融合,能够利用多种模态的信息,结合不同传感器的优势,极大提高检测性能,例如激光雷达与相机的融合在自动驾驶领域的应用。
由于道路的复杂性等因素,多模态目标检测的主要应用领域为行人与车辆检测,因此论文也主要与这两个领域相关,且主要是毫米波雷达与相机融合检测。
论文推荐:
- CenterFusion
- RVNet
- CameraRadarFusionNet (CRF-Net)
- MDETR:https://arxiv.org/abs/2104.12763
- EPNet:https://arxiv.org/pdf/1911.10150.pdf
- PointPainting: Sequential Fusion for 3D Object Detection:https://arxiv.org/pdf/2007.08856.pdf
参考文献:
- 刘建伟,丁熙浩,罗雄麟:多模态深度学习综述
- 任泽裕,王振超,柯尊旺:多模态数据融合综述
- wikipidia:multimode fusion
- Jiquan Ngiam…: Multimodal Deep Learning
- Tadas…:Multimodal Machine Learning: A Survey and Taxonomy