优云软件数据专家最佳实践:数据挖掘与运维分析
优云软件数据专家最佳实践:数据挖掘与运维分析

这份研究报告,作者是优云软件数据专家陈是维,在耗时1年时间制作的一份最佳实践,今天和大家分享下,关于《数据采矿和运维分析》,共同探讨~
数据挖掘(Data Mining)是从大量数据中提取或“挖掘”知识。
广义数据挖掘:数据挖掘是从存放在数据库、数据仓库或其它信息库中的大量数据挖掘有趣知识的过程。
数据挖掘技术侧重:1)概率与数理统计 2)数据库技术 3)人工智能技术 4)机器学习。
1. 数据清理:消除噪音或不一致数据
2. 数据集成:多种数据源可以组合在一起
3. 数据选择:从数据库中提取与分析任务相关的数据
4. 数据变换:数据变换或统一成适合挖掘的形式
5. 数据挖掘:基本步骤,使用智能方法提取数据模式
6. 模式评估:根据某种兴趣度度量,识别提供知识的真正有趣的模式
7. 知识表示:使用可视化和知识表示技术,向用户提供挖掘的知识
数据挖掘的过程图
优秀的数据挖掘软件工具包

OFFICE EXCEL:最为常见的数据分析挖掘工具。
SPSS 的一套工具:包括SPSS电子表格、SPSS SAS、SPSSClementine。
MATLAB:矩阵实验室,也有各种matlab工具箱。

关联规则简介
购物篮分析:啤酒尿布问题,关联规则挖掘首先找出频繁项集,项的集合,如A 和B,满足最小支持度阈值,并满足最小置信度阈值,产生形如A B 的强关联规则。
Apriori算法是一种有效的关联规则挖掘算法,它逐级探查,进行连接和剪枝,找出极大频繁集。性质:频繁项集的所有非空子集都必须是频繁的。
FP(频繁模式)树算法:频繁模式增长是一种不产生候选的挖掘频繁项集方法。它构造一个高度压缩的数据结构FP-树,压缩原来的事务数据库,聚焦于频繁模式片段增长,避免了高代价的候选产生,获得更好的效率。
提升度:相关性度量、兴趣度:并非所有的强关联规则都是有趣的。对于统计相关的项,可以挖掘相关规则。
Apriori算法例子
找出对应强关联规则

关联规则在运维方面的应用

○告警的关联挖掘
挖掘告警的频繁项集,如告警A 告警B,分析告警的连锁性。有利于告警的预测管理及处理和优化。
○用户行为关联分析
基于日志信息的采集分析用户行为的连锁相关性,有利于进行功能的位置的调整优化,提高用户的体验效果。
○server请求关联分析
分析用户行为的连锁相关性,有利于进行功能的位置的调整优化,提高用户的体验效果。
○崩溃和错误的关联分析
挖掘引起崩溃或错误的原因,即在什么样的情形下经常导致崩溃或错误,有利于对崩溃或错误进行处理,提出改进方案。
分类在运维方面的应用
分类——有监督学习
决策树:CLS(最基本)、ID3(信息增益) 、C4.5(信息增益率)、CART(二叉决策树)是决策树归纳的贪心算法。每种算法都使用一种信息论度量,为树中每个非树叶结点选择测试属性。剪枝算法试图通过剪去反映数据中噪音的分枝,提高准确率。
随机森林(分类和回归):是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。
神经网络:是一组连接的输入/输出单元,其中每个连接都与一个权重相关联。多层前馈神经网络由一个输入层,一个或多个隐藏层和一个输出层组成。。
支持向量机(SVM):是一种用于线性和非线性数据的分类算法。它将原数据变换到较高维空间,使用称作支持向量的基本训练元组,从中发现分离数据的超平面。
关联分类:关联挖掘技术在大型数据库中搜索频繁出现的模式,模式可以产生规则,可以分析这些规则,用于分类。
贝叶斯分类:基于贝叶斯定理,其假定类条件独立。朴素贝叶斯分类和贝叶斯信念网络基于后验概率的贝叶斯定理。贝叶斯信念网络允许在变量子集之间定义类条件独立性。
k最近邻分类法:基于距离的分类算法,基于距离的分类算法,惰性学习方法。
决策树例子
1.运维人员是否对告警进行及时处理的决策树(剪枝后)
2.计算各个不同维度对最后决策的影响(信息增益率)从高到低进行分支。
3.C4.5也是数据挖掘十大算法之首(J48 in weka)
分类——有监督学习

决策树:CLS(最基本)、ID3(信息增益) 、C4.5(信息增益率)、CART(二叉决策树)是决策树归纳的贪心算法。每种算法都使用一种信息论度量,为树中每个非树叶结点选择测试属性。剪枝算法试图通过剪去反映数据中噪音的分枝,提高准确率。
随机森林(分类和回归):是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。——回归分析中再详细说。
神经网络:是一组连接的输入/输出单元,其中每个连接都与一个权重相关联。多层前馈神经网络由一个输入层,一个或多个隐藏层和一个输出层组成。
支持向量机(SVM):是一种用于线性和非线性数据的分类算法。它将原数据变换到较高维空间,使用称作支持向量的基本训练元组,从中发现分离数据的超平面。
关联分类:关联挖掘技术在大型数据库中搜索频繁出现的模式,模式可以产生规则,可以分析这些规则,用于分类。
贝叶斯分类:基于贝叶斯定理,其假定类条件独立。朴素贝叶斯分类和贝叶斯信念网络基于后验概率的贝叶斯定理。贝叶斯信念网络允许在变量子集之间定义类条件独立性。
k最近邻分类法:基于距离的分类算法,基于距离的分类算法,惰性学习方法。
BP神经网络例子
BP网络:后向传播是一种用于分类的神经网络算法,使用梯度下降方法
分类——有监督学习

决策树:CLS(最基本)、ID3(信息增益) 、C4.5(信息增益率)、CART(二叉决策树)是决策树归纳的贪心算法。每种算法都使用一种信息论度量,为树中每个非树叶结点选择测试属性。剪枝算法试图通过剪去反映数据中噪音的分枝,提高准确率。
随机森林(分类和回归):是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。
神经网络:是一组连接的输入/输出单元,其中每个连接都与一个权重相关联。多层前馈神经网络由一个输入层,一个或多个隐藏层和一个输出层组成。。
支持向量机(SVM):是一种用于线性和非线性数据的分类算法。它将原数据变换到较高维空间,使用称作支持向量的基本训练元组,从中发现分离数据的超平面。
关联分类:关联挖掘技术在大型数据库中搜索频繁出现的模式,模式可以产生规则,可以分析这些规则,用于分类。
贝叶斯分类:基于贝叶斯定理,其假定类条件独立。朴素贝叶斯分类和贝叶斯信念网络基于后验概率的贝叶斯定理。贝叶斯信念网络允许在变量子集之间定义类条件独立性。
k最近邻分类法:基于距离的分类算法,基于距离的分类算法,惰性学习方法。
支持向量机例子
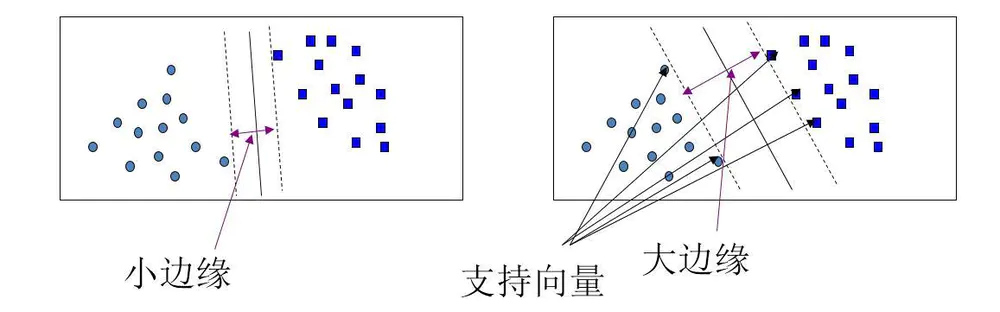
通过搜索
maximum marginal hyperplane
(MMH)来处理问题
分类——有监督学习
决策树:CLS(最基本)、ID3(信息增益) 、C4.5(信息增益率)、CART(二叉决策树)是决策树归纳的贪心算法。每种算法都使用一种信息论度量,为树中每个非树叶结点选择测试属性。剪枝算法试图通过剪去反映数据中噪音的分枝,提高准确率。
随机森林(分类和回归):是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。
神经网络:是一组连接的输入/输出单元,其中每个连接都与一个权重相关联。多层前馈神经网络由一个输入层,一个或多个隐藏层和一个输出层组成。。
支持向量机(SVM):是一种用于线性和非线性数据的分类算法。它将原数据变换到较高维空间,使用称作支持向量的基本训练元组,从中发现分离数据的超平面。
关联分类:关联挖掘技术在大型数据库中搜索频繁出现的模式,模式可以产生规则,可以分析这些规则,用于分类。
贝叶斯分类:基于贝叶斯定理,其假定类条件独立。朴素贝叶斯分类和贝叶斯信念网络基于后验概率的贝叶斯定理。贝叶斯信念网络允许在变量子集之间定义类条件独立性。
k最近邻分类法:基于距离的分类算法,惰性学习方法。
K最近邻分类法例子
5-最近邻分类

将所有训练元组储存在模式空间中,一直等到经验元组出现才进行分类。
分类在运维方面的应用
由于是有监督,必须已经有一些决策数据后才可以训练分类的模型

聚类分析在运维方面的应用
聚类——无监督学习
样本没有标记,根据距离把样本聚为k类
聚类分析是一个活跃的研究领域。
数据类型:数据矩阵:p个变量n个对象
相异度矩阵:相异度(距离)定义需满足
1) d(i,j)>=0;
2) d(i,i)=0;
3) d(i,j)=d(j,i);
4) d(i,j)<=d(i,k)+d(k,j).
最常见的距离是欧式距离和曼哈顿距离
常用的距离还有:相似矩阵转换的距离
聚类的方法

聚类分析许多聚类算法已经被开发出来,具体可以分为划分方法,层次方法,基于密度的方法,基于网格的方法。
划分方法首先得到初始的k 个划分的集合,这里的参数k是要构建的划分的数目;然后它采用迭代重定位技术,试图通过将对象从一个簇移到另一个来改进划分的质量。有代表性的划分方法包括k-means聚类、EM(期望最大化)算法。
层次方法创建给定数据对象集合的一个层次性的分解。根据层次分解的形成过程,这类方法可以被分为自底向上的,或自顶向下的。有代表性的层次方法包括系统聚类法、模糊聚类方法。
K-means聚类
K-means聚类算法是距离平方和最小聚类法
[1] 假设要聚成K 个类。由人为决定K 个类中心。
[2] 在第i 次叠代中,计算每个样本点到K个类中心的距离,并将它归 入最近的类。
[3] 计算新类的类中心为每一类的重心,并重新计算每个样本点到K 个类中心的距离,重新分类。
[4] 直到类中心的变化很小或已到最大迭代为止。
聚类的方法
聚类分析许多聚类算法已经被开发出来,具体可以分为划分方法,层次方法,基于密度的方法,基于网格的方法。
划分方法首先得到初始的k 个划分的集合,这里的参数k是要构建的划分的数目;然后它采用迭代重定位技术,试图通过将对象从一个簇移到另一个来改进划分的质量。有代表性的划分方法包括k-means聚类、EM(期望最大化)算法。
层次方法创建给定数据对象集合的一个层次性的分解。根据层次分解的形成过程,这类方法可以被分为自底向上的,或自顶向下的。有代表性的层次方法包括系统聚类法、模糊聚类方法。
系统聚类法
系统聚类法即谱系聚类法或分层聚类法。
谱系图



聚类在运维方面的应用
离群点检测在运维方面的应用
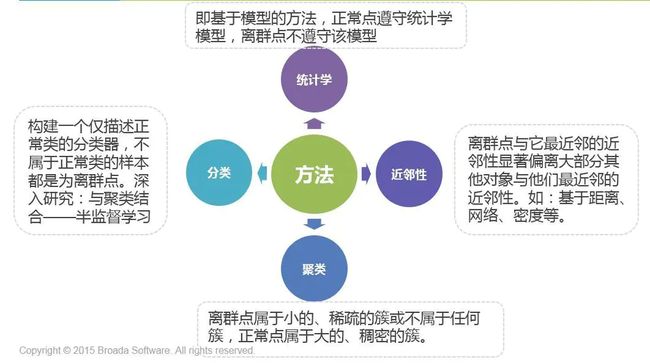
离群点检测
离群点(outlier)分析也叫异常检测。
离群点是一个数据对象,它显著不同于其他数据对象。
离群点类型
离群点检测的方法

离群点检测在运维方面的应用
统计分析在运维方面的应用

统计分析方法

▲主成分分析:是将多个指标化为少数指标的一种统计方法。(降维)
应用:(1)解释,在心理学与社会学中的应用(2)综合评价,如衡量企业的指标有很多,各种指标对不同企业来说,差异很大,通过主成分分析,用很少的综合指标进行评价。(3)分类:用两个主成分,在图上可以分类。聚在一起的属于同一类,离得很远,说明差别很大。
步骤:1)标准化数据矩阵,2)计算相关系数阵R,3)计算特征根排序,4)确定主成分,5)计算单位特征向量,6)写出主成分。
▲因子分析:主成分分析的推广。
目的:(理论)是研究原始变量的内部关系,简化原变量的协方差结构,分析变量中存在的复杂关系;(应用)是寻找众多变量的公共因子,即探讨多个能直接测量且有相关性的指标是如何受少数几个不能直接测量的相对独立的因子支配的。
基本思想:根据相关性的大小把变量分组,使得同组内的变量间相关性(共性)较高,而不同组的变量相关性较低。
步骤:1)标准化数据矩阵,2)计算相关系数阵R(协方差),3)求R特征根及特征向量,4)计算得到因子载荷A,5)因子旋转(方差极大旋转)、6)计算因子得分
■两者区别:主成分分析所着重的在于如何转换原来变量使之成为一些综合性的新指标。与主成分分析不同的是因子分析重视的是如何解释变量之间的共同变异问题。
▲典型相关分析:研究两组随机变量之间的相关关系
应用:(1)解释相互之间关系:如:y表示体重,x表示身高,年龄。身高,年龄对体重是否有影响?(2)预测与控制在1的基础上,利用x变量预测或控制y变量。如在西方,股票市场情况不太好,则银行降息,促进股市繁荣;若股票升得太厉害,银行就会上调利息。一般地,控制应建立在很好的预测基础上。(3)寻找结构联系:通过线性函数解释内部结构机理。
▲判别分析:当得到一个新样品(或个体)的关于指标X的观测值时,要判断该样品属于哪一个类型,即为判别分析。
1.距离判别:通过定义样品指标X的观测值x(p维)到各总体的距离,以其大小判定样品属于哪个总体。
2.Bayes判别 :对给定的样品x,计算两总体的概率密度函数在x处的值。
3.Fisher判别:基本思想是投影,即把K类的m维数据投影(变换)到某个方向,使得变换后的数据,同类别的点“尽可能聚在一起”,不同类的点“尽可能分离”,以达到分类的目的。
回归分析
回归分析(预测):研究相关性关系的最基本、应用最广泛的方法。就是在掌握大量观察数据基础上,利用数理统计方法建立因变量与自变量之间的回归关系函数式。
1) 线性回归分析,方法:最小二乘法。
2) 非线性回归分析:抛物线模型、双曲线模型、幂函数模型、指数函数模型、对数函数模型、逻辑曲线模型,多项式模型等。方法:非线性模型线性化,最小二乘法。
3) 二项逻辑回归分析:因变量Y=0,1,可以用于分类决策。
4)基于随机森林模型的回归:真实情况自变量既可能包含因子(factor),也可能包含数值的连续性变量,又要考虑自变量对因变量的重要性程度,还可以对将来的情况进行预测。
随机森林回归在运维方面的例子
新增设备数影响因素及预测:时间、周几、新版本发布、广告宣传、前一天的活跃设备数、当天的活跃设备数等等。
可以通过两个指标判断自变量对因变量的重要程度:
1)%IncMSE:均方误差递减意义下的重要性,若此指标值越大则说明此自变量对因变量的影响程度越大,若为0则说明此自变量对因变量没有任何关系,若为负值则说明此自变量对因变量的变化可能有起到误导的作用。
2)IncNodePurity:精确度递减意义下的重要性。计算方法是残差的平方和(非负),若此指标值越大则说明此自变量对因变量的影响程度越大,若为0则说明此自变量对因变量没有任何关系。

新增设备数与其他因素影响的数据集范例
new_date week new_ver advertising yestoday_act today_act new_device
636147 星期日 0 0 884 459 79
636148 星期一 0 0 459 701 45
636149 星期二 0 2.8 701 185 13
636150 星期三 0 3.6 185 112 12
636151 星期四 6 3.2 112 827 87
636152 星期五 8 2.8 827 892 32
636153 星期六 9 2 892 716 89
636154 星期日 8 0.8 716 204 98
636155 星期一 7 0 204 157 39
636156 星期二 5 0 157 484 72
636157 星期三 3 0 484 595 42
636158 星期四 1 0 595 592 70
636159 星期五 0 0 592 93 42
636160 星期六 2 0 93 451 89
636161 星期日 5 0 451 582 54
636162 星期一 4 0 582 140 97
636163 星期二 3 0 140 741 61
636164 星期三 1 0 741 809 30
636165 星期四 0 0 809 440 91
636166 星期五 0 0 440 108 65
636167 星期六 0 0 108 304 75
统计分析在运维方面的应用

数据挖掘其他方法在运维方面的应用
数据挖掘其他方法
▲遗传算法
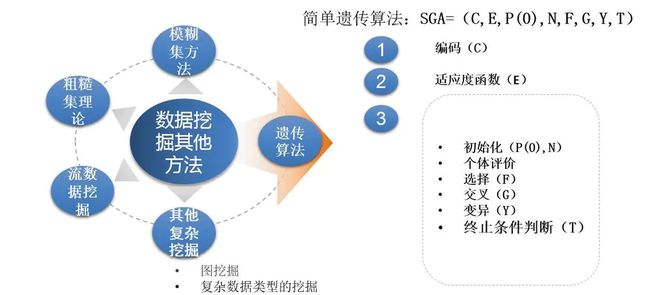
:是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。
一、编码,不能直接处理问题空间的参数,必须把它们转换成遗传空间的由基因按一定结构组成的染色体或个体。这一转换操作就叫做编码,也可以称作(问题的)表示。(C)
二、适应度函数:进化论中的适应度,是表示某一个体对环境的适应能力,也表示该个体繁殖后代的能力。遗传算法的适应度函数也叫评价函数,是用来判断群体中的个体的优劣程度的指标,它是根据所求问题的目标函数来进行评估的。(E)
条件:1.单值、连续、非负、最大化;2.合理、一致性;3.计算量小;4.通用性强。
三、基本运算过程如下:简单遗传算法:SGA=(C,E,P(0),N,F,G,Y,T)
1.初始化:设置进化代数计数器t=0,设置最大进化代数T,随机生成N个个体作为初始群体P(0)。(P(0),N)
2.个体评价:计算群体P(t)中各个个体的适应度。
3.选择运算(F):将选择算子作用于群体。目的是把优化的个体直接遗传到下一代或通过配对交叉产生新的个体再遗传到下一代。选择操作是建立在群体中个体的适应度评估基础上的
4.交叉运算(G);将交叉算子作用于群体。所谓交叉是指把两个父代个体的部分结构加以替换重组而生成新个体的操作。遗传算法中起核心作用的就是交叉算子。
4.变异运算(Y):将变异算子作用于群体。即是对群体中的个体串的某些基因座上的基因值作变动。
■群体P(t)经过选择、交叉、变异运算之后得到下一代群体P(t+1)。
5.终止条件判断(T):若t=T,则以进化过程中所得到的具有最大适应度个体作为最优解输出,终止计算。
▲粗糙集理论:已成为人工智能领域中一个较新的学术热点, 在机器学习,知识获取,决策分析,过程控制等许多领域得到了广泛的应用.
▲模糊集方法:就是指具有某个模糊概念所描述的属性的对象的全体。由于概念本身不是清晰的、界限分明的,因而对象对集合的隶属关系也不是明确的、非此即彼的。设A是集合X到[0,1]的一个映射,A:X→[0,1],x→A(x) 则称A是X上的模糊集,A(x)称为模糊集A的隶属函数,或称A(x)为x对模糊集A的隶属度。
▲流数据挖掘:一组顺序、大量、快速、连续到达的数据序列,一般情况下,数据流可被视为一个随时间延续而无限增长的动态数据集合。
▲图挖掘:用于挖掘大型图数据集的频繁图模式,进行特征化、区分、分类和聚类分析。应用于化学信息学,生物信息学,计算机视觉,视频索引,文本检索,Web分析等。
▲复杂数据类型的挖掘,包括对象数据,空间数据,多媒体数据,时序数据,文本数据和Web 数据。空间数据挖掘是指从大数据量的地理空间数据库中发现有意义的模式;多媒体数据挖掘是指从多媒体数据库中发现有意义的模式;文本数据是指从文本数据中抽取有价值的信息和知识的计算机处理技术,文本数据挖掘是从文本中进行数据挖掘;Web 挖掘是指从大量的Web文档集合中发现蕴涵的、未知的、有潜在应用价值的、非平凡的模式,它所处理的对象包括静态网页、Web数据库、Web结构、用户使用记录等信息。
在运维方面的应用
作者:陈是维,现任职优云软件(秉承devops的理念,从监控、到应用体验,到自动化持续交付,全栈运维解决方案服务商:
https://www.uyun.cn)
原文:https://www.jianshu.com/p/bb9426583dc3