EMNLP21' | 细粒度情感分析新突破 —— 通过有监督对比学习方法学习隐式情感...
每天给你送来NLP技术干货!
来自:FudanNLP

论文链接:https://aclanthology.org/2021.emnlp-main.22.pdf
论文代码:https://github.com/Tribleave/SCAPT-ABSA
细粒度情感分析中的隐式情感
细粒度情感分析(Aspect-Based Sentiment Analysis, ABSA)又称方面级情感分析任务。其任务范式为:给定用户评论(Review)以及需要分析的方面(Aspect),模型需要输出该方面在评论中的情感倾向。
如下图的例子所示,评论中对于食物(food)的情感倾向是积极的,而对于服务(service)是消极的。

能够发现情感词(opinion term),如上例中对于食物的棒(Great)与对于服务的糟糕(dreadful),能够对细粒度情感的判断起到非常大的作用。
此类具有情感词的细粒度情感,我们称之为“显式情感”(Explicit sentiment)。以往的基于注意力,基于语法树等的细粒度情感分析模型,能够有效地建模方面词与情感词之间的关系。
于是我们自然地提出以下问题:
如果评论中没有情感词信息,是否能够传达清晰的细粒度情感?
如果存在,那么该部分评论占比多少?是否足以影响到方面级情感分析结果?
隐式情感
针对第一个问题,我们在细粒度情感分析数据集 SemEval2014-Restaurant 中找到如下例子:

该评论中没有对于方面词“侍者”(waiter)的主观评价,但是对其行为的客观描述“将水泼在我的手上后走开了”,清楚地表明了对侍者的负面评价。
我们称这类没有明显的情感词,但能够表达明确情感倾向的表述为"隐式情感"(Implicit sentiment)。

我们进一步将隐式情感的判断归结于常识知识和领域知识。在上面的两条评论中,相同的动作“泼,倒”(pour)在不同的事件场景中表达出不同的情感,而对这两种情感的判断凭据是常识知识;在下面的两条评论中,针对笔记本电源寿命,十小时和一小时表述了对立的情感倾向,而这种判断来源于笔记本电源寿命的领域知识。
为了强调隐式情感在细粒度情感分析中的复杂性,我们需要指出,上例中水(water)和香槟(chanmpagne)同样是待分析的方面词,它们的情感极性均为中性。
数据集中的隐式情感比例
为了回答第二个问题,我们需要区分数据集里的每个方面级别表述是显式情感还是隐式情感。我们利用了南京大学Fan等[1]标注的TOWE数据,他们将SemEval2014-Restaurant/Laptop中的情感词均标注出。
将该数据与原始的SemEval2014数据集对齐并检查后,能够将原先的数据集分为显式情感部分和隐式情感部分。我们发现在Restaurant中细粒度情感为隐式情感的比例为27.47%,在Laptop中这一比例为30.09%。
| 数据集 | 总数 | 隐式情感比例 % |
|---|---|---|
| Restaurant | 4722 | 28.59 |
| Laptop | 2951 | 30.09 |
通过解答以上两个问题,我们发现隐式情感在细粒度情感分析中占据不可忽视的比例,而以往的方法并没有对隐式情感的学习进行深入研究。在本文中我们提出有监督对比学习预训练来学习细粒度情感分析中的隐式情感,并使用方面感知的微调,在SemEval2014 Restaurant, Laptop和MAMS数据集上得到了领先的结果,并且在隐式情感中相较前人的提升明显。
在本文中我们提出有监督对比学习预训练来学习细粒度情感分析中的隐式情感,并使用方面感知的微调,在SemEval2014 Restaurant, Laptop和MAMS数据集上得到了领先的结果,且在隐式情感的预测准确率上得到了明显的提升。
隐式情感的知识来源
前文我们讨论了判断隐式情感需要知识凭据,而当前细粒度情感分析数据集的数据数量太小,成为学习隐式情感的一大阻碍。如上表所示,该任务中最经常使用的 SemEval2014 数据集均只有数千条。数据集的大小限制了在训练过程中模型学习到的情感知识,我们需要更多的知识用于判断隐式情感。
为了构建包含常识知识和领域知识的语料,我们尝试从 YELP 和 Amazon 两个情感分析数据集筛选适合的数据。不同于细粒度情感分析数据集中的句子级别数据、方面级情感标注,以及积极消极中性三种情感倾向,YELP 和 Amazon 中的评论为篇章级数据、整体情感标注,以及一星到五星的五种情感倾向。
我们提出以下抽取步骤,从 YELP 和 Amazon 中构造出大规模且有噪声的句子级别数据,且具有方面级别情感标注的数据集:
保留 YELP 和 Amazon 中对应领域的数据,即保留餐厅和笔记本领域的评论;
保留其中一星和五星的评论,该步骤是消除篇章级标注的噪声;
将篇章级的评论分割成多个句子,且仅保留包含方面词的句子,这里的方面词集合指 SemEval 中曾经作为的方面的词组;
将原先一星评论中的句子标记为消极情感的例子,将原先五星评论中的句子标记为积极情感的例子。该数据集中没有中性情感数据。
抽取的得到的数据集具有百万级别的数据,且与原先的数据有相同的领域。经过人工检查,能够确认在该数据集中同时包含隐式和显式的情感,可以进一步的被用于隐式情感的学习。
| 数据集 | #积极 | #消极 | 总数 |
|---|---|---|---|
| YELP | 1.17M | 0.39M | 1.56M |
| Amazon | 0.38M | 0.13M | 0.51M |
有监督对比学习预训练
我们通过有监督对比学习预训练与方面感知的微调学习细粒度情感分析中的隐式情感。预训练所使用的基础模型为 Transformer Encoder。有监督对比学习预训练(Supervised ContrAstive Pre-Training, SCAPT)分为三个部分:
有监督对比学习 (Supervised Contrastive Learning)
评论重建 (Review Reconstruction)
方面词预测 (Masked Aspect Prediction)
有监督对比学习预训练使用上节所抽取的大规模外部数据集,旨在使隐式情感和显式情感拥有相同的模型情感表示。
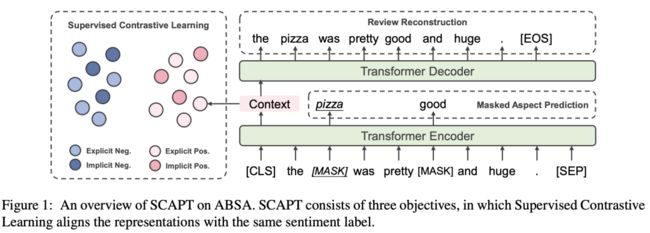
有监督对比学习
有监督对比学习最初用于计算机视觉中的分类任务,由无监督的对比学习发展而来。在预训练中,该目标使得具有相同标签的方面级情感具有相似的情感表示,由此模型能够将无论为显式还是隐式的情感表示,根据其情感倾向性投射到对应的向量空间中。
在有监督对比学习中,给定一个 Batch 中的评论与其标签 , 我们首先得到其情感表示 ,其中 为句子在 [CLS] 位置的表示。之后得到对比学习 Loss 为:
此处我们使用 作为相似度度量, 表示在同一 batch 中与当前评论具有相同标签的评论数量。
评论重建
评论重建的灵感来源于去噪自编码器(denoise auto-encoder)。其目标为通过句子表示 和一个 Transformer Decoder 将评论文本以自回归的方式重建出来。引入评论重建目标的目的是防止单一的有监督对比学习目标使句子表示退化,让其包含句子原先的整体信息。
评论重建的 Loss 为:
方面词预测
在预训练中,我们希望模型注意到方面词的信息,并且建模方面词为之后的方面感知的微调做准备。类似于在众多预训练模型中应用的完型填空任务,方面词预测任务要求模型根据方面词位置表示预测得到原先的方面词。
如果将 [MASK] 位置的表示记为 ,则方面词预测的 Loss 为:
在有监督对比学习预训练(SCAPT)中,三个目标同时作用:
方面感知的微调
在方面感知的微调(Aspect-aware fine-tuning)中,句子的情感表示和方面表示融合在一起用于判断细粒度的情感倾向。具体而言,将所有属于该方面词的词表示进行聚合,得到方面词表示 :
进一步地,将句子的情感表示和方面表示连接后输入分类器,得到细粒度的情感倾向:

使用方面感知的微调具有以下好处:
对于隐式情感,该方式能够充分利用预训练得到的情感表示中的知识,并根据对应的方面获得情感倾向;
对于显式情感,来自方面词的表示能够包含句子的树信息,有效建模方面词和情感词之间的关系(该结论可见于复旦大学Dai等[2]);
方面词级别的平行处理。过去的基线模型往往将方面词作为一部分输入,因此一个句子中的多个方面需要多次通过模型。而该微调可以同时处理句子中的多个方面。
实验与分析
基于有监督对比学习预训练和方面感知的微调,我们实现两种主模型:
TransEncAsp+SCAPT:在300维6层6个注意力头的随机初始化 Transformer Encoder上进行预训练和微调的模型
BERTAsp+SCAPT: 基于BERT-base-uncased的模型架构和参数作为基础进行预训练和微调的模型
基于方面感知的微调,我们也实现了一种新的基线模型 BERTAsp,即在预训练模型上直接使用方面感知的微调。
主要结果
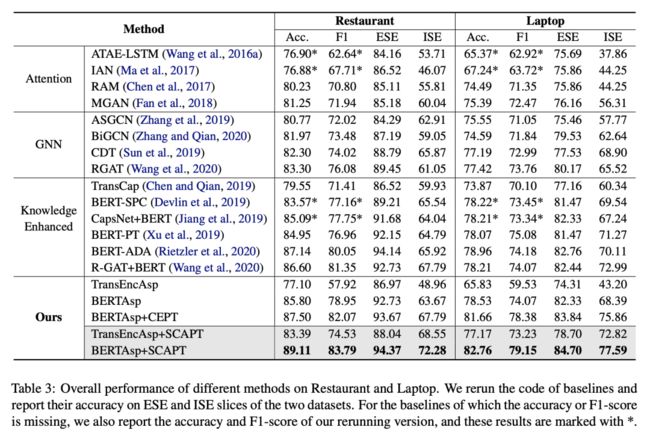
我们将提出的模型与基线模型在 SemEval2014 Restaurant 和 Laptop 上进行了实验,并测试了在显式情感和隐式情感部分的准确率。结果表明:
BERTAsp+SCAPT在两个数据集上均达到了领先的结果;
使用有监督对比学习预训练的模型在隐式情感上具有更好的表现;
BERTAsp超过传统的基于BERT的基线模型,证明了方面感知的微调方法的有效性。
多方面词上的结果

我们在多句子多方面词数据集MAMS(Jiang等[3])上验证模型在复杂的细粒度情感分析场景下的表现。实验结果表明,即使在有监督对比学习预训练中,我们抽取的是句子级别的情感表示,但其能够在方面感知的微调的作用下,有效地应对多句子、多方面的复杂场景。
可视化分析
在 Restaurant 数据集上,使用 T-SNE 将 BERTAsp 和 BERTAsp+SCAPT 中的分类前的表示进行可视化,展示出使用有监督对比学习预训练的模型能够更好地将相同标签的显式情感与隐式情感表示聚合在一起,并且拉远不同情感标签的情感表示。

鲁棒性分析

细粒度情感分析中的鲁棒性分析,最初由复旦大学Xing等[4]提出,并在复旦大学Wang等[5]的 TextFlint 中进一步扩充。我们在鲁棒性测试集上测试了我们的模型。相比于其他基线模型较大的准确率下降,经过有监督对比学习预训练的模型在面对添加方面无关词、添加无用信息等的鲁棒性测试下保持了较高稳定性和健壮性。
总结
在本文中,我们提出一种有监督对比学习预训练(SCAPT)用于学习细粒度情感分析中的隐式情感。
我们发现在隐式情感尚未引起学者的足够重视,而处理隐式情感需要更多的知识。
我们构建了大规模的有标注语料,并使用有监督对比学习预训练(SCAPT)学习隐式情感中的情感知识。
实验证明该方法在细粒度情感分析任务具有领先的表现,并且能够有效地处理数据集中的隐式情感。
我们希望未来通过知识增强的方法,更具体更有效地建模并理解细粒度情感分析中的隐式情感。
引用
[1]. Zhifang Fan, Zhen Wu, Xin-Yu Dai, Shujian Huang, and Jiajun Chen. Target-oriented opinion words extraction with target-fused neural sequence labeling. NACCL2019.
[2]. Junqi Dai, Hang Yan, Tianxiang Sun, Pengfei Liu, and Xipeng Qiu. Does syntax matter? a strong baseline for aspect-based sentiment analysis with RoBERTa. NACCL2021.
[3]. Qingnan Jiang, Lei Chen, Ruifeng Xu, Xiang Ao, and Min Yang. A challenge dataset and effective models for aspect-based sentiment analysis. EMNLP2019.
[4]. Xiaoyu Xing, Zhijing Jin, Di Jin, Bingning Wang, Qi Zhang, and Xuanjing Huang. Tasty burgers, soggy fries: Probing aspect robustness in aspect- based sentiment analysis. EMNLP2020.
[5]. Xiao Wang, Qin Liu, Tao Gui, Qi Zhang, et al. Textflint: Unified multilingual robustness evaluation toolkit for natural language processing. ACL2021.
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!