【文本检测与识别白皮书-3.1】第一节:常用的文本检测与识别方法
点击领取AI产品100元体验金:https://www.textin.com/coupon_redemption/index.html https://www.textin.com/coupon_redemption/index.html
https://www.textin.com/coupon_redemption/index.html

# 3.常用的文本检测与识别方法
## 3.1文本检测方法

随着深度学习的快速发展,图像分类、目标检测、语义分割以及实例分割都取得了突破性的进展,这些方法成为自然场景文本检测的基础。基于深度学习的自然场景文本检测方法在检测精度和泛化性能上远优于传统方法,逐渐成为了主流。图1 列举了文本检测方法近几年来的发展历程。
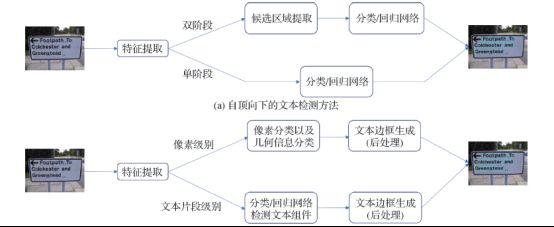
目前,根据检测文本对象的不同可以将基于深度学习的方法划分为基于回归的文本检测方法和基于分割的文本检测方法两大类,不同类别方法的流程如图所示。
### 3.1.1 基于回归的场景文本检测方法
基于回归的自然场景文本检测方法主要是基于以深度学习为基础的目标检测技术或者实例分割技术,它将文本视为一种通用目标然后直接检测出整个文本实例。此类方法通常是直接回归出水平矩形或者多方向的任意形状多边形以解决文本检测的问题。
早期的这类文本检测方法基于传统滑动窗口方法的思想,只是在对滑窗进行文本和非文本分类的时候使用CNN 提取的特征而不是人工设计的特征(Wang 等,2012;Jaderberg 等,2014)。
虽然能提高分类性能,但计算量大以及适用范围窄(大部分只能处理水平方向文本)的问题依旧没有解决。在基于深度学习的目标检测和分割等技术的突破性进展的同时,这些方法也为自然场景文本检测提供了新的思路。
基于深度学习的基于回归的自然场景文本检测方法可分为**两阶段**和**单阶段**的方法。
#### 1)两阶段检测方法。
两阶段的方法主要是借鉴了Faster R-CNN(region CNN),R-FCN(region-based fully convolutional network)以及Mask R-CNN和FCI(fully convolutional instance-aware semantic segmentation)等系列两阶段目标检测和分割算法的思想,针对文本不同于通用目标的表现形进行专门的改进,使之能在文本检测领域取得更好的检测性能。
Jaderberg 等人(2016) 首先借鉴了R-CNN 框架,利用了EdgeBoxes和聚合通道特征(aggregate channel feature, ACF)等候选区域提取算法,得到单词级别的文本候选区域;然后通过随机森林(random forest)对候选区域进行文本和非文本分类以过滤背景区域,得到的文本候选区域最后通过一个CNN 对边界框回归,得到最终的检测结果。
该方法虽然取得了当时不错的性能,但由于各模块是单独优化的,容易造成误差累积,而且EdgeBoxes 和ACF 提取候选区域时都会存在计算量大的问题。
针对这些问题,受Faster R-CNN 的启发,Zhong 等人(2017)提出的DeepText 是第一个把该目标检测算法成功应用到自然场景文本检测的工作。该工作使用了基于感知( inception) 模块(Szegedy 等,2015)的区域生成网络(inception region proposal network,Inception-RPN)来代替传统的候选区域提取算法(EdgeBoxes 等),大大提高了候选区域的提取效率和质量。
然后再通过Fast R-CNN 网络对文本候选区域做更准确的回归和分类,得到最后的检测结果。但是由于Faster R-CNN 只能预测水平矩形框, 因此DeepText 也无法处理多方向以及不规则文本的自然场景文本检测问题。
为了适应文本的不同表现形式,更多的学者基于Faster R-CNN提出了不同的解决方法。
Jiang 等人(2018)提出的R2CNN(rotational region CNN)为了适应文本的长宽比和方向(水平和竖直),首先使用了多尺度的感兴趣区域池化(region of interest pooling,RoI-Pooling)操作,增加了特征尺寸,然后在Fast R-CNN 中额外增加了一个分支预测旋转的矩形以及一个针对倾斜框的非极大值抑制后处理算法以解决多方向文本的检测问题。
Ma 等人(2018)同样也指出应该用旋转矩形替代水平矩形来进行文本检测。作者提出了旋转候选区域生成网络(rotated region proposal network,RRPN),结合旋转矩形的锚点框(anchor)来生成倾斜的文本候选区域。然后设计了旋转感兴趣区域池化(rotated region of interest pooling,RROI Pooling)算法为每个倾斜的候选区域从卷积特征图中提取固定尺度的特征以进一步地进行文本和非文本分类。
考虑到将Faster R-CNN 用于文本检测时,矩形锚点框与文本的形状相差过大,会导致区域生成网络(region proposal network,RPN)在生成文本候选区域时效率不高,鲁棒性也不强,Zhong 等人(2019)因此借鉴了DenseBox(Huang 等,2015) 的思想,提出了不需要锚点框的区域生成网络(anchor-free region proposal network, AF-RPN)。
AF-RPN 通过特征图上的滑动点与原图文本中心区域的映射关系来确定特征上的文本滑动点,对于每个这样的滑动点,AF-RPN 都会预测其对应的文本边界框位置,从而可以不需要复杂的锚点框计算,直接生成高质量的文本候选区域。
上述方法都是主要针对水平和多方向四边形文本而不能检测任意形状(如曲线) 的文本。
因此,Liu 等人(2019b) 用14 个点描述不规则文本,在R-FCN 的基础上改进了文本边界框回归模块去预测这14 个顶点的位置坐标,并通过循环神经网络(recurrent neural network, RNN)对候选区域提取的特征进行上下文信息的增强以提高文本检测精度。
考虑到之前的方法对于不同形状的文本需要不同数量的点来描述,Wang 等人(2019h) 提出使用RNN去自适应预测不同形状文本实例所需要的多边形顶点数目,并将这个模块结合到Faster R-CNN 中,提高了整个模型的灵活性。
Liu 等人(2019d)提出了条件空间膨胀(conditional spatial expansion, CSE)模块,将不规则文本检测构造成区域膨胀问题,依靠CNN 提取的区域特征和已融合区域的上下文信息进行进一步区域融合得到完整的检测结果。
Wang等人(2020d)同样是基于Faster R-CNN 设计了自适应区域生成网络(Adaptive-RPN)生成更加准确的文本候选区域,然后增加了一个额外的分支去进行候选区域的文本轮廓检测以抑制误检情况,极大提高了检测精度,同时也能适应任意形状的文本检测。
以上文本检测方法主要是基于主流的两阶段目标检测器Faster R-CNN。由于文本方向和形状的复杂性,它通常需要设计回归更多的顶点去描述那些多方向以及不规则的文本,这可能会带来误差累积以及额外的计算量。而Mask R-CNN 和FCIS 在实例分割领域取得了很大的进步,通过边框或边界点回归预测和像素分类相结合的思路也可以对任意形状的文本进行更方便地描述。
Dai 等人(2018)便是借鉴这样的思想,预测了文本候选区域的文本实例像素级掩码后, 通过基于掩码的非最大值抑制(mask non maximum suppression, Mask-NMS)得到更准确的任意形状文本检测框。
Yang 等人(2018)也是类似的做法,基于FCIS 的框架通过Inception-Text模块和可变形ROI 池化模块去处理多方向的文本。
Xie 等人(2019a)同样是为了解决弯曲文本检测的问题,在Mask R-CNN 的基础上增加了一个文本语义模块以及文本区域敏感的重打分机制以抑制误检的问题。
Xiao 等人(2020)考虑到普通卷积对不规则文本的采样效率偏低,在Mask R-CNN 中嵌入了序列变形模块(sequential deformable module,SDM),它能沿着文本方向进行特征采样,此外通过一个Seq2seq 模型对采样过程进行限制,使之能更准确地检测不规则文本。
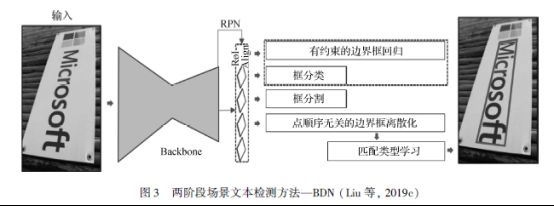
Liu 等人(2019c)则是为了解决数据标注顺序歧义性的问题,提出了包围盒分解网络(box discretization network, BDN),将四边形标注框的点顺序分解成由顺序无关点组成的关键边,并通过匹配类型学习从学习到的关键边中重建四边形检测框。如图3 所示,整个网络也是基于Mask R-CNN 进行搭建,这样可以更好地处理任意方向的文本,不过对于不规则文本,BDN 并不能进行很好地检测。
Liu 等人(2019a)则是考虑到若将文本检测视为实例分割问题,采用的分割标注是直接根据文本框得到,这会使得部分背景像素被划分为正样本,从而增加训练的噪声,导致训练不稳定。于是舍弃Mask R-CNN 中简单的(0,1)二值预测方案,根据文本中心点到边界的距离为像素分配[0,1]中的值作为弱标签进行训练,减少了文本边界错误标注像素带来的训练噪声,从而提高文本的检测性能。
#### 2)单阶段检测方法。
除了上述RCNN 系列的两阶段检测器,很多单阶段的目标检测器如YOLO(you only look once) 系列(Redmon 等,2016; Redmon和Farhadi,2017) 和SSD(single shot multibox detector)(Liu 等,2016a)也被学者们应用于自然场景文本检测。Gupta 等人(2016)基于YOLO 模型,对不同尺度的图像使用全卷积网络(Long 等,2015)定位文本的位置。基于SSD 的方法则有以下的一些工作。
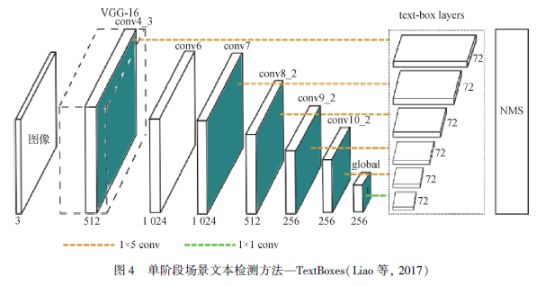
如图4 所示,Liao 等人(2017)提出了Text-Boxes,该算法针对自然场景文本的特性,设置了适应性的锚点(Anchor),考虑到文本长宽比与通用目标差别过大便采用了长条形的卷积核,它能对水平文本取得不错的检测性能。这些学者进一步提出TextBoxes ++ (Liao 等人,2018a),增加了角度预测以适应多方向文本的检测。He 等人(2017b)加入了文本注意力机制,通过强化文本部分的特征加强其分类和边界框回归,同时他们设计了一个多级特征融合模块以适应文本的尺度变化。
Liu 和Jin (2017)也是基于相同的框架提出了深度匹配先验网络(deep matching prior network, DMPNet),首次使用四边形锚点框来替换原来的矩形锚点框,实现了多方向文本检测。Liao 等人(2018b)针对多方向文本这一问题,使用了方向响应网络(oriented response network,ORN)取代融合SSD中不同尺度特征的侧边连接。ORN 可以提取旋转的文本特征以适应不同方向的文本实例,然后在每个侧边连接提取特征后进行分类和边界框回归。
除了基于SSD 和YOLO 这类需要锚点框的单阶段方法之外,还有很多是借助文本的一些几何属性进行建模并利用全卷积神经网络的单阶段文本检测方法。
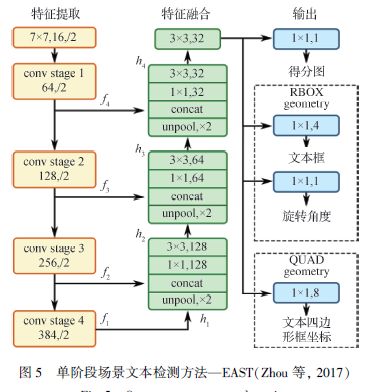
Zhou 等人(2017)借鉴了DenseBox(Huang等,2015)的架构和U-Net(Ronneberger 等,2015)的特性提出了EAST(efficient and accurate scene text detector)算法,结构如图所示。
它先在每个像素位置预测是否有文本,如果有则直接预测该像素点对应文本实例的得分图和边界坐标。He 等人(2017c)提出的DDR(deep direct regression)算法思想和EAST 相似,不过DDR 是直接学习4 个边界点对于有文本像素点作为文本实例中心点的偏移量,而EAST 是回归点到边框的上下左右距离。
类似的方法还有Xue 等人(2018)提出的Border,不过它除了进行文本和非文本分类以及边框回归的同时,还增加了对4 条文本框边界的学习和预测。
Wang 等人(2018b) 提出了一个实例变换网络( instance transformation network, ITN)去学习自然场景文本的几何属性表达,以适应任意四边形文本行的检测。
针对不规则文本的检测,Long 等人(2018)提出的TextSnake 是首个单阶段解决此类问题的工作。
它先利用一个全卷积神经网络预测文本区域、文本的中心线以及几何属性(角度、半径等),然后通过这些属性重建整个文本实例。
Zhang 等人(2019a)提出的LOMO(look more than once)是在EAST 算法思想的基础上额外增加了一个迭代优化模块和形状表征模块,分别加强对长文本以及对不规则文本的检测。
而Wang 等人(2019a) 提出的SAST(singleshot arbitrarily-shaped text detector) 同样也是EAST的演进版本,他们也借鉴了TextSnake 的思想,在直接回归边界框的同时加入了对文本一些几何特征的预测(文本中心线区域、文本边界偏置和文本中心点偏置等),使之能适用于不规则的文本检测。
考虑到文本多尺度的问题,Xue 等人(2019)提出了多尺度形状回归网络(multi-scale regression,MSR) 去检测不同尺度的任意形状文本。MSR 分别预测文本中心区域、中心区域的点到最近边界的横向和纵向距离,最后通过后处理得到文本边框。