【文本检测与识别-白皮书-3.1】第四节:算法模型 2
CTPN
CTPN,全称是“Detecting Text in Natural Image with Connectionist Text Proposal Network”(基于连接预选框网络的文本检测)。CTPN直接在卷积特征映射中检测一系列精细比例的文本建议中的文本行。CTPN开发了一个垂直锚定机制,可以联合预测每个固定宽度提案的位置和文本/非文本得分,大大提高了定位精度。序列建议由递归神经网络自然连接,该网络无缝地合并到卷积网络中,形成端到端可训练模型。这使得CTPN能够探索图像的丰富上下文信息,使其能够强大地检测极其模糊的文本。CTPN可以在多尺度和多语言文本上可靠地工作,而不需要进一步的后处理,不同于以前需要多步骤后过滤的自下而上的方法。
CTPN算法原理:
CTPN包括三个关键的工作,使其对文本定位的可靠和准确:detecting text in fine-scale proposals, recurrent connectionist text proposals, and side-refinement。
Detecting text in fine-scale proposals:
与RPN类似,CTPN本质上是一个完全卷积的网络,允许任意大小的输入图像。它通过在卷积特征图中密集滑动一个小窗口来检测文本线,并输出一系列精细尺度(例如,固定的16像素宽度)文本建议,如图1 (b).所示。

CTPN以非常深的16层vggNet(VGG16)为例来描述方法,它很容易适用于其他深度模型。CTPN的体系结构如图1.(a).所示,使用一个小的空间窗口,3×3,来滑动最后一个卷积层的特征图(例如,VGG16的conv5)。conv5特征图的大小由输入图像的大小决定,总步幅和接受域分别固定为16像素和228像素。总步幅和接受域都是由网络体系结构固定的。在卷积层中使用滑动窗口允许它共享卷积计算,这是减少昂贵的基于滑动窗口的方法的计算的关键。
CTPN模型的网络结构如下图所示:

检测处理过程总结如下。给定一个输入图像,有W×H×C conv5特征图(通过使用VGG16模型),其中C是特征图或通道的数量,W×H是空间排列。当探测器在conv5中密集地滑动一个3×3的窗口时,每个滑动窗口都采用3×3×C的卷积特征来产生预测。对于每个预测,水平位置(x坐标)和锚定位置都是固定的,这可以通过将conv5中的空间窗口位置映射到输入图像上来预先计算。检测器输出每个窗口位置上的k个锚点的文本/非文本分数和预测的y坐标(v)。检测到的文本建议是由文本/非文本得分为>0.7(具有非最大抑制)的锚点生成的。通过设计的垂直锚定和精细尺度检测策略,检测器能够通过使用单尺度图像处理大尺度和长宽比的文本线。这进一步减少了它的计算量,同时也预测了文本行的准确定位。与RPN或Faster R-CNN系统相比,CTPN的精细尺度检测提供了更详细的监督信息,自然会导致更准确的检测。
Recurrent Connectionist Text Proposals:
为了提高定位精度,CTPN将一条文本线分割成一系列精细尺度的文本建议,并分别进行预测。显然,独立考虑每一个孤立的建议并不是不可靠的。这可能会导致对与文本模式具有相似的结构的非文本对象进行大量的错误检测,如窗口、砖块、叶子等。。也可以丢弃一些包含弱文本信息的歧义模式。图3(top)给出了几个例子。文本具有很强的顺序特征,其中顺序上下文信息对做出可靠的决策至关重要。这已经被最近的工作证实,其中一个循环神经网络(RNN)被应用于编码这个上下文信息,用于文本识别。研究结果表明,序列上下文信息极大地简化了裁剪词图像的识别任务。RNN为经常使用它的隐藏层来编码这些信息提供了一个自然的选择。为此,CTPN建议在conv5上设计一个RNN层。

Side-refinement:
CTPN可以准确、可靠地检测到精细尺度的文本建议。通过连接文本/非文本得分为> 0.7的连续文本建议,文本行构造很简单。文本行的构造如下。首先,当(i) Bj是距离Bi最近的水平距离,(ii)该距离小于50像素,(iii)其垂直重叠时,CTPN将Bi(Bj)定义为> 0.7。其次,将两个建议分为一对,如果Bj−> Bi和Bi−> Bj。然后,通过顺序连接具有相同提议的成对来构造一条文本线。精细尺度检测和RNN连接能够预测垂直方向上的准确定位。在水平方向上,图像被划分为一个等于16像素宽度的建议序列。当水平两侧的文本提案没有被地面真实文本线区域完全覆盖,或者一些边提案被丢弃(例如,文本得分较低)时,这可能会导致不准确的本地化,如图4所示

这种不准确性在一般的对象检测中可能不是关键的,但在文本检测中也不应被忽视,特别是对于那些小规模的文本行或单词。为了解决这个问题,CTPN提出了一种侧细化方法,该方法可以准确估计每个锚/方案在左右水平侧的位置(称为侧锚或侧建议)的偏移量。与y坐标预测相似,计算相对偏移量为:

其中,xside是距离当前锚点最近的水平侧(例如,左侧或右侧)的预测x坐标。
![]() 是x轴上的真实(GT)边坐标,它是根据GT边界框和锚点位置预先计算出来的。是x轴上锚的中心。瓦是锚的宽度,它是固定的,w a= 16。当CTPN将检测到的一系列检测到的精细文本建议连接到一个文本行时,侧建议被定义为开始和结束建议。CTPN只使用边建议的偏移量来细化最终的文本行边界框。图4给出了几个通过侧细化改进的检测例子。侧边细化进一步提高了定位精度,导致SWT和多语言数据集的性能提高了约2%。请注意,CTPN的模型同时预测了侧边细化的偏移量,如图1所示。它不是从一个额外的后处理步骤中计算出来的。
是x轴上的真实(GT)边坐标,它是根据GT边界框和锚点位置预先计算出来的。是x轴上锚的中心。瓦是锚的宽度,它是固定的,w a= 16。当CTPN将检测到的一系列检测到的精细文本建议连接到一个文本行时,侧建议被定义为开始和结束建议。CTPN只使用边建议的偏移量来细化最终的文本行边界框。图4给出了几个通过侧细化改进的检测例子。侧边细化进一步提高了定位精度,导致SWT和多语言数据集的性能提高了约2%。请注意,CTPN的模型同时预测了侧边细化的偏移量,如图1所示。它不是从一个额外的后处理步骤中计算出来的。
实验结果:
CPTN选用ICDAR2011、ICDAR 2013、ICDAR 2015、SWT和多语言数据集作为实验的数据集,得到了如下的实验结果。
实验首先讨论了针对RPN和Faster R-CNN系统的精细检测策略。如表1(左)所示,单个RPN很难执行精确的文本定位,因为它会产生大量错误检测(精度低)。通过使用Fast R-CNN检测模型重新规划RPN方案,Faster R-CNN系统大大提高了定位精度,F-measure值为0.75。一个观察结果是,Faster R-CNN也会增加对原始RPN的回忆。这可能得益于Fast R-CNN的联合边界框回归机制,该机制提高了预测边界框的准确性。RPN提案可能粗略地本地化了文本行或单词的主要部分,但根据ICDAR 2013标准,这些提案不够准确。显然,拟议的精细文本提议网络(FTPN)在精确度和召回率方面显著提高了更快的R-CNN,这表明FTPN通过预测一系列精细文本提议而不是整个文本行,更加准确和可靠。
实验讨论了循环连接对CTPN的影响。如图3所示,上下文信息非常有助于减少错误检测,例如类文本异常值。这对于恢复高度模糊的文本(例如,非常小的文本)非常重要,这是CTPN的主要优势之一,如图6所示。这些吸引人的特性带来了显著的性能提升。如表1(左)所示,通过循环连接,CTPN将FTPN从F-measure值0.80大幅提高到0.88。
运行时间。通过使用单个GPU,CTPN(用于整个检测处理)的实现时间约为每幅图像0:14s,短边为600。没有RNN连接的CTPN大约需要0.13s/image GPU时间。因此,所提出的网络内递归机制略微增加了模型计算量,并获得了可观的性能增益。


图5显示了CTPN在几个挑战性图像上的检测结果。可以发现,CTPN在这些具有挑战性的情况下非常有效,其中一些情况对于以前的许多方法来说都很困难。它能够高效地处理多尺度和多语言(如中文和韩文)。

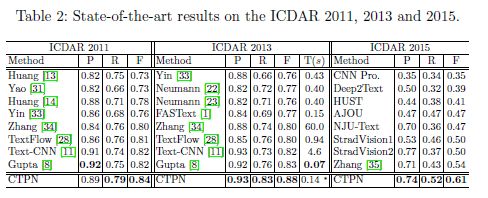
实验对五个基准进行了全面评估。在不同的数据集中,图像分辨率有很大的不同。实验将SWT和ICDAR 2015的图像短边设置为2000,其他三个设置为600。实验将CTPN和最近公布的几种方法进行了比较。如表1和表2所示, CTPN在所有五个数据集上都达到了最佳性能。在SWT上,CTPN在召回率和F-measure上都有显著的改进,在精确度上略有提高。CTPN的检测器在多语言上对TextFlow表现良好,这表明CTPN的方法可以很好地推广到各种语言。在2013年ICDAR上,通过将F-measure从0.80提高到0.88,它的表现明显优于最近的TextFlow和FastText。精度和召回率都有相当大的提高,分别提高了5%和7%以上。此外,实验还将CTPN与首次提交后发布的几种方法进行了进一步比较。它在F-measure和召回方面不断取得实质性的改进。这可能是因为CTPN具有很强的检测极具挑战性的文本的能力,例如,非常小的文本,其中一些文本甚至对人类来说是不受欢迎的。如图6所示,CTPN检测器可以正确检测到那些具有挑战性的,但其中一些甚至被GT标记遗漏,这可能会降低CTPN的评估精度。
实验进一步研究了各种方法的运行时间,如表2所示。FASText达到0:15s/图像CPU时间。通过获得0:14s/图像,CTPN的方法略快于它,但需要GPU时间。虽然直接比较它们并不公平,但随着近年来深度学习方法在目标检测方面的巨大成功,GPU计算已成为主流。无论运行时间如何,CTPN方法都大大优于FastText,F-measure提高了11%。CTPN可以通过使用较小的图像比例来减少时间。与Gupta等人使用GPU的0:07s/图像的方法进行了比较。CTPN通过使用450的比例尺,它减少到0:09s/图像,同时在ICDAR 2013上获得0.92/0.77/0.84的P/R/F。
结论:
连接主义文本提议网络(CTPN)——一种高效的文本检测器,可以进行端到端的培训。CTPN直接在卷积映射中检测精细比例文本建议序列中的文本行。CTPN开发了垂直锚机制,可以联合预测每个提案的精确位置和文本/非文本分数,这是实现文本精确定位的关键。CTPN提出了一个网络内RNN层,它优雅地连接顺序文本提议,允许它探索有意义的上下文信息。这些关键技术的发展导致了检测高度挑战性文本的强大能力,错误检测更少。CTPN在五个基准上实现了最新的性能,每幅图像的运行时间为0:14s,因此非常高效。
Seglink
CVPR2017的一篇论文《Detecting Oriented Text in Natural Images by Linking Segments》介绍了一种可以检测任意角度文本的检测算法,这种方法被称为Seglink。
SegLink的算法原理:
SegLink主要思想是将文本分解为两个局部可检测的元素,即片段(分割)和链接。段是覆盖单词或文本行的一部分的定向框;一个链接连接两个相邻的段,表示它们属于同一个单词或文本行。这两个元素都被一个端到端训练的全卷积神经网络在多个尺度上密集地检测到。最终的检测是通过结合由链接连接的段而产生的。与以前的方法相比,SegLink在准确性、速度和训练的容易用性等方面都有所提高。在标准的ICDAR 2015附带性(挑战4)基准上,它达到了75.0%的f-mrasure,大大超过了之前的最佳指标。它在512×512图像上以超过20 FPS的速度运行。此外,SegLink能够检测长行非拉丁文本,如中文。
SegLink模型的主要思想:
SegLink的方法用前馈CNN模型检测文本。给定一个大小为wI×hI的输入图像I,该模型输出固定数量的片段和链接,然后通过它们的置信度分数进行过滤,并组合成整个单词边界框。边界框是一个旋转的矩形,用b=(xb,yb,yb,wb,hb,θb)表示,其中xb,yb是中心的坐标,wb,hb是宽度和高度,θb是旋转角。
SegLink模型的网络结构如下:

该模型以VGG16作为网络的主要骨干,将其中的全连接层(fc6, fc7)替换成卷积层(conv6, conv7),后面再接上4个卷积层(conv8, conv9, conv10, conv11),其中,将conv4_3,conv7,conv8_2,conv9_2,conv10_2,conv11这6个层的feature map(特征图)拿出来做卷积得到segments(切片)和links(链接)。这6个层的feature map(特征图)尺寸是不同的,每一层的尺寸只有前一层的一半,从这6个不同尺寸的层上得到segment和link,就可以实现对不同尺寸文本行的检测了(大的feature map擅长检测小物体,小的feature map擅长检测大物体)。
segments检测:
segment也是有方向的边界框,用s =(xs、ys、ws、hs、θs)表示。SegLink通过估计输入图像上的一组默认框的置信度分数和几何偏移量来检测片段。每个默认框都与一个特征地图位置相关联,它的分数和偏移量可以从该位置的特征中预测出来。为简单起见,SegLink只将一个默认框与一个特征映射位置关联起来。
links检测
在segment与segment的link(链接)方面,主要存在两种情况,一种是层内链接检测(Within-Layer Link Detection)、另一种是跨层链接检测(Cross-Layer Link Detection)。如下图:

Within-Layer Link Detection:
层内链接检测表示同一特征层,每个segment与8邻域内的segment的连接状况,链接不仅是将片段组合成整个单词的必要条件,而且还有助于分离两个相邻的单词——在两个相邻的单词之间,链接应该被预测为负的。
Cross-Layer Link Detection:
Seglinks网络中,在不同的特征层上以不同的尺度检测到片段。每一层都可以处理一系列的尺度。Seglinks使这些范围重叠,以避免错过它们边缘的尺度。但结果是,同一单词的片段可以同时在多层上检测到,从而产生冗余。为了解决这个问题,Seglinks进一步提出了另一种类型的链接,称为跨层链接。一个跨层链接将两个特征层上的段按照相邻的索引连接起来。
合并算法
合并算法的思想如下:
前馈后,网络产生许多段和链路(数量取决于图像大小)。在组合之前,输出片段和链接将通过它们的置信度分数进行过滤。分别为分段和链接设置了不同的过滤阈值,即α和β。将每个segment看成node,link看成edge,建立图模型,然后,在图上执行深度优先搜索(DFS),以找到其连接的组件。每个组件都包含一组由链接连接的段。用B表示一个连接的组件,该组件中的段按照Alg1中的程序进行组合。
Alg1算法其实就是一个平均的过程。先计算所有的segment的平均θ作为文本行的θ,再根据已求的θ为已知条件,求出最可能过每个segment的直线(线段,这里线段就是以segment最左和最右的为边界),以线段中点作为word的中心点(x,y),最后用线段长度加上首尾segment的平均宽度作为word的宽度,用所有segment的高度的平均作为word的高度。

实验结果:
Seglink使用三个公共数据集(即ICDAR 2015附带文本(挑战4)、MSRA-TD500和ICDAR 2013)和标准评估指标,对方法进行实验得到了如下几张表的实验结果。首先是在ICDAR 2015 Incidental Text上的实验结果。表1列出并比较了拟议方法和其他最先进方法的结果。一些结果来自在线排行榜。SegLink的表现大大优于其他方法。就f-measure而言,它的表现比第二好的高10.2%。考虑到某些方法的精度接近甚至高于SegLink,改进主要来自Recall。如图6所示,Seglink的方法能够从非常杂乱的背景中区分文本。此外,由于其明确的链接预测,SegLink可以正确地分离彼此非常接近的单词。

在 数据集MSRA-TD500的实验数据如表2所示:根据表2,SegLink在精度和f-测量方面得分最高。得益于其完全卷积设计,SegLink的运行速度为8.9 FPS,比其他产品快很多。SegLink也很简单。SegLink的推理过程是检测网络中的一个前向传递,而之前的方法【《Detecting texts of arbitrary orientations in natural images》、《Robust text detection in natural scene images》、《Multi-oriented text detection with fully convolutional networks.》】涉及复杂的基于规则的分组或过滤步骤。
数据集MSRA-TD500的实验数据如表2所示:根据表2,SegLink在精度和f-测量方面得分最高。得益于其完全卷积设计,SegLink的运行速度为8.9 FPS,比其他产品快很多。SegLink也很简单。SegLink的推理过程是检测网络中的一个前向传递,而之前的方法【《Detecting texts of arbitrary orientations in natural images》、《Robust text detection in natural scene images》、《Multi-oriented text detection with fully convolutional networks.》】涉及复杂的基于规则的分组或过滤步骤。
TD500包含许多混合语言(英语和汉语)的长文本行。图7显示了SegLink如何处理此类文本。可以看到,段和链接沿着文本线密集检测。它们会产生很长的边界框,很难从传统的对象检测器中获得。尽管中英文文本在外观上存在巨大差异,但SegLink能够同时处理它们,而无需对其结构进行任何修改。


Seglink在数据集IC13上的实验结果如表3所示。表3将SegLink与其他最先进的方法进行了比较。分数由中央提交系统使用“Deteval”评估协议计算。SegLink在f-measure方面取得了非常有竞争力的结果。只有一种方法在f-度量方面优于SegLink。然而,该主要用于检测水平文本,不太适合定向文本。就速度而言,SegLink在512×512图像上的运行速度超过20 FPS,比其他方法快得多。

局限性:
SegLink的一个主要限制是需要手动设置两个阈值,α和β。在实际应用中,通过网格搜索可以找到了阈值的最优值。简化这些参数将是seglink未来工作的一部分。另一个缺点是,SegLink无法检测到字符间距非常大的文本。图8.a、b显示了这两种情况。检测到的链接连接相邻的段,但无法连接遥远的段。
总结:
SegLink提出一种新的文本检测策略,由一个简单和高效的CNN模型实现。在水平方向、面向方向和多语言的文本数据集上的优越性能很好地证明了SegLink是准确、快速和灵活的。在未来,将进一步探索其在检测弯曲文本等变形文本方面的潜力。此外,研究人员还想将SegLink扩展到一个端到端识别系统。
参考文献:
Liu C Y, Chen X X, Luo C J, Jin L W, Xue Y and Liu Y L. 2021. Deep learning methods for scene text detection and recognition. Journal of Image and Graphics,26(06):1330-1367(刘崇宇,陈晓雪,罗灿杰,金连文,薛洋,刘禹良. 2021. 自然场景文本检测与识别的深度学习方法. 中国图象图形学报,26(06):1330-1367)[DOI:10. 11834 / jig. 210044]
Tian Z, Huang W L, He T, He P and Qiao Y. 2016. Detecting text in natural image with connectionist text proposal network / / Proceedings of the 14th European Conference on Computer Vision. Amsterdam, The Netherlands: Springer: 56-72 [ DOI: 10. 1007 / 978-3-319- 46484-8_4]
Shi B G, Bai X and Belongie S. 2017b. Detecting oriented text in natural images by linking segments/ / Proceedings of 2017 IEEE Conference on Computer Vision and Pattern Recognition. Honolulu, USA: IEEE: 2550-2558 [DOI: 10. 1109 / CVPR. 2017. 371]
Ren S Q, He K M, Girshick R B and Sun J. 2015. Faster R-CNN: towards real-time object detection with region proposal networks/ / Proceedings of 2015 Annual Conference on Neural Information Processing Systems. Montreal, Canada: [s. n. ]:91-99
Girshick, R.: Fast r-cnn (2015), in IEEE International Conference on Computer Vision (ICCV)
R. B. Girshick, J. Donahue, T. Darrell, and J. Malik. Rich feature hierarchies for accurate object detection and semantic segmentation. In CVPR, 2014