如何实现一个HTML5 RPG游戏引擎——第四章,实现情景对话
今天我们来实现情景对话。这是一个重要的功能,沒有它,游戏将变得索然无味。所以我们不得不来完成它。
可是要知道,使用对话可不是一件简单的事,由于它内部的东西非常多,比方说人物头像,人物名称,对话内容。。。
因此我们仅仅能通过数组+JSON来将对话信息装起来,然后依据信息作出不同的显示。接下来我便要向大家展示实现方法。
先看本系列文章文件夹:
怎样制作一款HTML5 RPG游戏引擎——第一篇,地图类的实现
http://blog.csdn.net/yorhomwang/article/details/8892305
怎样制作一款HTML5 RPG游戏引擎——第二篇,烟雨+飞雪效果
http://blog.csdn.net/yorhomwang/article/details/8915020
怎样制作一款HTML5 RPG游戏引擎——第三篇,利用幕布切换场景
http://blog.csdn.net/yorhomwang/article/details/9042571
该引擎是基于lufylegend开发的,学习时请先了解lufylegend。
官方站点地址:http://lufylegend.com/lufylegend
API地址:http://lufylegend.com/lufylegend/api
1,实现后的代码
为了向大家展示封装的必要性,所以我们先看实现后的代码:
- <!DOCTYPE html>
- <html lang="en">
- <head>
- <meta charset="utf-8" />
- <title>LTalk</title>
- <script type="text/javascript" src="../lufylegend-1.7.6.min.js"></script>
- <script type="text/javascript" src="../lufylegendrpg-1.0.0.js"></script>
- <script>
- init(30,"legend",480,320,main);
- LRPGStage.setShortcuts(true);
- LGlobal.setDebug(true);
- var backLayer,loadingLayer,talkLayer;
- var talk;
- var talkContent;
- var talkNum = 0;
- var loadData = [
- {name:"yorhom_face",path:"./yorhom.jpg"},
- {name:"lufy_face",path:"./lufy.jpg"}
- ];
- var imglist = [];
- function main(){
- //添加进度条
- loadingLayer = new LoadingSample1();
- addChild(loadingLayer);
- //载入图片并显示运行进度
- LLoadManage.load(
- loadData,
- function(progress){
- loadingLayer.setProgress(progress);
- },
- gameInit
- );
- }
- function gameInit(result){
- removeChild(loadingLayer);
- imglist = result;
- //初始化层
- backLayer = new LSprite();
- addChild(backLayer);
- talkLayer = new LSprite();
- backLayer.addChild(talkLayer);
- //添加操作button
- addEvent();
- //增加对话内容
- talkContent = [
- {name:"[Yorhom]",msg:"你好,lufy",face:imglist["yorhom_face"]},
- {name:"[lufy]",msg:"你好,yorhom",face:imglist["lufy_face"]},
- {name:"[Yorhom]",msg:"lufylegend最新版本号是哪个版本号啊?",face:imglist["yorhom_face"]},
- {name:"[lufy]",msg:"……你不知道自己看吗?",face:imglist["lufy_face"]},
- {name:"[Yorhom]",msg:"……说得也是",face:imglist["yorhom_face"]},
- ];
- //添加对话
- talkLayer.graphics.drawRect(5,"black",[20,15,400,130],true,"black");
- talkLayer.alpha = 0.8;
- talk = new LTalk(talkContent);
- talkLayer.addChild(talk);
- talkLayer.addEventListener(LMouseEvent.MOUSE_DOWN,say);
- //设置样式
- talk.setNameStyle({x:160,y:40,color:"white",size:12});
- talk.setMsgStyle({x:160,y:70,color:"white",size:10});
- talk.setFaceStyle({x:30,y:30});
- talk.textWidth = 260;
- }
- function addEvent(){
- LEvent.addEventListener(LGlobal.window,LKeyboardEvent.KEY_UP,say);
- }
- function say(){
- if(talkNum < talkContent.length){
- //输出对话
- talk.wind(talkNum,function(){talkNum++;});
- }
- }
- </script>
- </head>
- <body>
- <div id="legend"></div>
- </body>
- </html>
这78行代码就能够实现进行5次对话的效果,先发两张截图,例如以下:
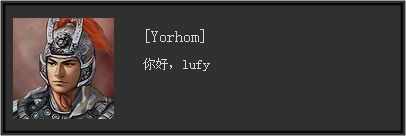

由此可见,本次封装还是非常有作用的。
可是怎样实现呢?请看接下来的解说。
2,LTalk类
LTalk是一个对话类,构造器例如以下:
- function LTalk(content){
- var s = this;
- base(s,LSprite,[]);
- if(!content){
- s.content = [];
- }else{
- s.content = content;
- }
- s.x = 0;
- s.y = 0;
- s.textWidth = LStage.width;
- s.talkIndex = 0;
- s.faceX = 0;
- s.faceY = 0;
- s.nameX = 0;
- s.nameY = 0;
- s.nameColor = "black";
- s.nameFont = "宋体";
- s.nameSize = "15";
- s.msgX = 0;
- s.msgY = 0;
- s.msgColor = "black";
- s.msgFont = "宋体";
- s.msgSize = "15";
- }
当中,textWidth属性是为了设置文字区宽度的,设置后,假设文字过多而超出这个区域就会自己主动换行。talkIndex指对话编号。faceX,faceY指人物头像位置。nameX,nameY指人物名称的位置;nameColor,nameFont,nameSize分别用来设置名称颜色,字体,尺寸。msgX,msgY,msgColor,msgFont,msgSize同分别代表对话内容的x坐标,y坐标,颜色,字体,尺寸。
设定好刚才的那些属性后,就能够自己定义对话样式了。
这个类构造时要传个參数,这个參数是对话内容。是一个数组套JSON的格式,例如以下:
- [
- {name:"名称",msg:"内容",face:头像图片},
- {name:"名称",msg:"内容",face:头像图片},
- {name:"名称",msg:"内容",face:头像图片},
- {name:"名称",msg:"内容",face:头像图片},
- {name:"名称",msg:"内容",face:头像图片},
- ];
每往这个列表里加一条,就会多一段对话。
3,wind方法
接下来看看wind方法:
- LTalk.prototype.wind = function(num,completeFunc){
- var s = this;
- if(!num || num == null)num = 0;
- if(!completeFunc)completeFunc = null;
- s.talkIndex = num;
- s.removeAllChild();
- if(s.talkIndex < s.content.length){
- var talkObject = s.content[s.talkIndex];
- var faceBitmapdata = new LBitmapData(talkObject.face);
- var faceBitmap = new LBitmap(faceBitmapdata);
- faceBitmap.x = s.faceX;
- faceBitmap.y = s.faceY;
- s.addChild(faceBitmap);
- var name = new LTextField();
- name.x = s.nameX;
- name.y = s.nameY;
- name.size = s.nameSize;
- name.color = s.nameColor;
- name.font = s.nameFont;
- name.text = talkObject.name;
- name.width = s.textWidth;
- name.setWordWrap(true,name.getHeight()+5);
- s.addChild(name);
- var msg = new LTextField();
- msg.x = s.msgX;
- msg.y = s.msgY;
- msg.size = s.msgSize;
- msg.color = s.msgColor;
- msg.font = s.msgFont;
- msg.text = talkObject.msg;
- msg.width = s.textWidth;
- msg.setWordWrap(true,msg.getHeight()+7);
- msg.wind(completeFunc);
- s.addChild(msg);
- }else{
- trace("Error: Param exceeds the size of the content!");
- }
- }
这个方案有两个參数,第一个是播放序号,第二个參数是输出完成后调用的函数。
首先我们推断一下參数num是不是没定义,假设是就自己主动设0,然后再推断第二个參数是否定义,假设沒有,就设为null。这样做能够确保程序运行无误。接着,我们把控制播放序号的属性talkIndex设为num,然后清空一次,以便不和上次输出的重叠在一起。接着推断talkIndex有沒有超出最大值,沒有的话就运行输出命令。代码例如以下:
- var talkObject = s.content[s.talkIndex];
- var faceBitmapdata = new LBitmapData(talkObject.face);
- var faceBitmap = new LBitmap(faceBitmapdata);
- faceBitmap.x = s.faceX;
- faceBitmap.y = s.faceY;
- s.addChild(faceBitmap);
- var name = new LTextField();
- name.x = s.nameX;
- name.y = s.nameY;
- name.size = s.nameSize;
- name.color = s.nameColor;
- name.font = s.nameFont;
- name.text = talkObject.name;
- name.width = s.textWidth;
- name.setWordWrap(true,name.getHeight()+5);
- s.addChild(name);
- var msg = new LTextField();
- msg.x = s.msgX;
- msg.y = s.msgY;
- msg.size = s.msgSize;
- msg.color = s.msgColor;
- msg.font = s.msgFont;
- msg.text = talkObject.msg;
- msg.width = s.textWidth;
- msg.setWordWrap(true,msg.getHeight()+7);
- msg.wind(completeFunc);
- s.addChild(msg);
熟悉lufylegend的朋友不难理解这些,就是将名称,内容,头像所有加到界面上。显示内容为构造器參数中相应的内容。
wind做好后,大家想让文本逐字显示时仅仅用写一行obj.wind();就可以了。
4,更改样式&手动清空对话&重设数据
刚才我们看了控制文字,图片样式的几个属性,有非常多,假设一个一个用手改就会非常麻烦,并且要写非常多行代码,因此我们加几个控制样式的方法,它们各自是:setFaceStyle,setNameStyle,setMsgStyle。运用时仅仅用传入參数就可以了。
实现方法例如以下:
- LTalk.prototype.setFaceStyle = function(styleData){
- var s = this;
- if(!styleData.x){s.faceX = 0;}else{s.faceX = styleData.x;}
- if(!styleData.y){s.faceY = 0;}else{s.faceY = styleData.y;}
- }
- LTalk.prototype.setNameStyle = function(styleData){
- var s = this;
- if(!styleData.x){s.nameX = 0;}else{s.nameX = styleData.x;}
- if(!styleData.y){s.nameY = 0;}else{s.nameY = styleData.y;}
- if(!styleData.color){s.nameColor = "black";}else{s.nameColor = styleData.color;}
- if(!styleData.font){s.nameFont = "宋体";}else{s.nameFont = styleData.font;}
- if(!styleData.size){s.nameSize = "15";}else{s.nameSize = styleData.size;}
- }
- LTalk.prototype.setMsgStyle = function(styleData){
- var s = this;
- if(!styleData.x){s.msgX = 0;}else{s.msgX = styleData.x;}
- if(!styleData.y){s.msgY = 0;}else{s.msgY = styleData.y;}
- if(!styleData.color){s.msgColor = "black";}else{s.msgColor = styleData.color;}
- if(!styleData.font){s.msgFont = "宋体";}else{s.msgFont = styleData.font;}
- if(!styleData.size){s.msgSize = "15";}else{s.msgSize = styleData.size;}
- }
值得注意的是,參数是一个JSON对象。格式例如以下:
- /*给msg和name设置样式时传的參数*/
- {x:x坐标,y:y坐标,color:文字颜色,size:文字尺寸}
- /*给face设置样式时传的參数*/
- {x:x坐标,y:y坐标}
OK,给对话设定样式就搞定了。
再加一个手动清空对话的方法,这样一来能够方便用户手动清空对话:
- LTalk.prototype.clear = function(){
- var s = this;
- s.removeAllChild();
- s.die();
- }
最后加一个重设对话数据的函数:
- LTalk.prototype.setData = function(content){
- var s = this;
- s.content = content;
- }
5,Debug输出
前面在设计类时,没考虑到大家debug,所以都没添加什么debug输出。这次想到了,就顺便做一下,顺便把曾经的也做了一下。今天就仅仅呈现LTalk中的Debug输出,代码例如以下:
- LTalk.prototype.showData = function(){
- var s = this;
- for(var key in s.content){
- trace("----------No."+key+"----------");
- trace("Name: " + s.content[key].name);
- trace("Msg: " + s.content[key].msg);
- trace("Face: " + s.content[key].face);
- }
- }
调用此方法输出例如以下:

6,源码
源码不多,大家能够拿下去測试一下:
- /**
- *LTalk.js
- */
- function LTalk(content){
- var s = this;
- base(s,LSprite,[]);
- if(!content){
- s.content = [];
- }else{
- s.content = content;
- }
- s.x = 0;
- s.y = 0;
- s.textWidth = LStage.width;
- s.talkIndex = 0;
- s.faceX = 0;
- s.faceY = 0;
- s.nameX = 0;
- s.nameY = 0;
- s.nameColor = "black";
- s.nameFont = "宋体";
- s.nameSize = "15";
- s.msgX = 0;
- s.msgY = 0;
- s.msgColor = "black";
- s.msgFont = "宋体";
- s.msgSize = "15";
- }
- LTalk.prototype.setData = function(content){
- var s = this;
- s.content = content;
- }
- LTalk.prototype.showData = function(){
- var s = this;
- for(var key in s.content){
- trace("----------No."+key+"----------");
- trace("Name: " + s.content[key].name);
- trace("Msg: " + s.content[key].msg);
- trace("Face: " + s.content[key].face);
- }
- }
- LTalk.prototype.setFaceStyle = function(styleData){
- var s = this;
- if(!styleData.x){s.faceX = 0;}else{s.faceX = styleData.x;}
- if(!styleData.y){s.faceY = 0;}else{s.faceY = styleData.y;}
- }
- LTalk.prototype.setNameStyle = function(styleData){
- var s = this;
- if(!styleData.x){s.nameX = 0;}else{s.nameX = styleData.x;}
- if(!styleData.y){s.nameY = 0;}else{s.nameY = styleData.y;}
- if(!styleData.color){s.nameColor = "black";}else{s.nameColor = styleData.color;}
- if(!styleData.font){s.nameFont = "宋体";}else{s.nameFont = styleData.font;}
- if(!styleData.size){s.nameSize = "15";}else{s.nameSize = styleData.size;}
- }
- LTalk.prototype.setMsgStyle = function(styleData){
- var s = this;
- if(!styleData.x){s.msgX = 0;}else{s.msgX = styleData.x;}
- if(!styleData.y){s.msgY = 0;}else{s.msgY = styleData.y;}
- if(!styleData.color){s.msgColor = "black";}else{s.msgColor = styleData.color;}
- if(!styleData.font){s.msgFont = "宋体";}else{s.msgFont = styleData.font;}
- if(!styleData.size){s.msgSize = "15";}else{s.msgSize = styleData.size;}
- }
- LTalk.prototype.wind = function(num,completeFunc){
- var s = this;
- if(!num || num == null)num = 0;
- if(!completeFunc)completeFunc = null;
- s.talkIndex = num;
- s.removeAllChild();
- if(s.talkIndex < s.content.length){
- var talkObject = s.content[s.talkIndex];
- var faceBitmapdata = new LBitmapData(talkObject.face);
- var faceBitmap = new LBitmap(faceBitmapdata);
- faceBitmap.x = s.faceX;
- faceBitmap.y = s.faceY;
- s.addChild(faceBitmap);
- var name = new LTextField();
- name.x = s.nameX;
- name.y = s.nameY;
- name.size = s.nameSize;
- name.color = s.nameColor;
- name.font = s.nameFont;
- name.text = talkObject.name;
- name.width = s.textWidth;
- name.setWordWrap(true,name.getHeight()+5);
- s.addChild(name);
- var msg = new LTextField();
- msg.x = s.msgX;
- msg.y = s.msgY;
- msg.size = s.msgSize;
- msg.color = s.msgColor;
- msg.font = s.msgFont;
- msg.text = talkObject.msg;
- msg.width = s.textWidth;
- msg.setWordWrap(true,msg.getHeight()+7);
- msg.wind(completeFunc);
- s.addChild(msg);
- }else{
- trace("Error: Param exceeds the size of the content!");
- }
- }
- LTalk.prototype.clear = function(){
- var s = this;
- s.removeAllChild();
- s.die();
- }
运用时,就仅仅用写这些代码:
- var talkContent = [
- {name:"[Yorhom]",msg:"你好,lufy",face:imglist["yorhom_face"]},
- {name:"[lufy]",msg:"你好,yorhom",face:imglist["lufy_face"]},
- {name:"[Yorhom]",msg:"lufylegend最新版本号是哪个版本号啊?",face:imglist["yorhom_face"]},
- {name:"[lufy]",msg:"……你不知道自己看吗?",face:imglist["lufy_face"]},
- {name:"[Yorhom]",msg:"……说得也是",face:imglist["yorhom_face"]},
- ];
- var talk = new LTalk(talkContent);
- addChild(talk);
- talk.wind();
顺便提示一下,LTalk构造时所传的对话内容參数是一个数组套JSON的格式,它要在游戏图片载入完成后再初始化,否则显示不出对话头像。
最后把測试链接给大家:
http://www.cnblogs.com/yorhom/articles/3132075.html
进入后点击黑框開始对话。祝大家測试愉快~
近天就先讲到这里,下次我们接着研究。
谢谢大家阅读本文,支持就是最大的鼓舞。(^_^)
----------------------------------------------------------------
欢迎大家转载我的文章。
转载请注明:转自Yorhom's Game Box