python对csv文件的处理,pandas 数据预处理csv,案例详细
文章目录
-
- csv文件的导入
- CSV文件的导出
- 不导出行号和标签,可分别将index或header设置为False
- 使用columns参数设置想导出的列
- 数据清理分组
- 排序
- 删除
- 缺失值处理
- 缺失值的删除
- 缺失值的填充
papadas的用法请参考 pandas数据预处理(Series DataFrame)详解附带案例
Pandas提供read_csv函数导入一个csv文件,导入的结果是一个DataFrame
csv文件的导入
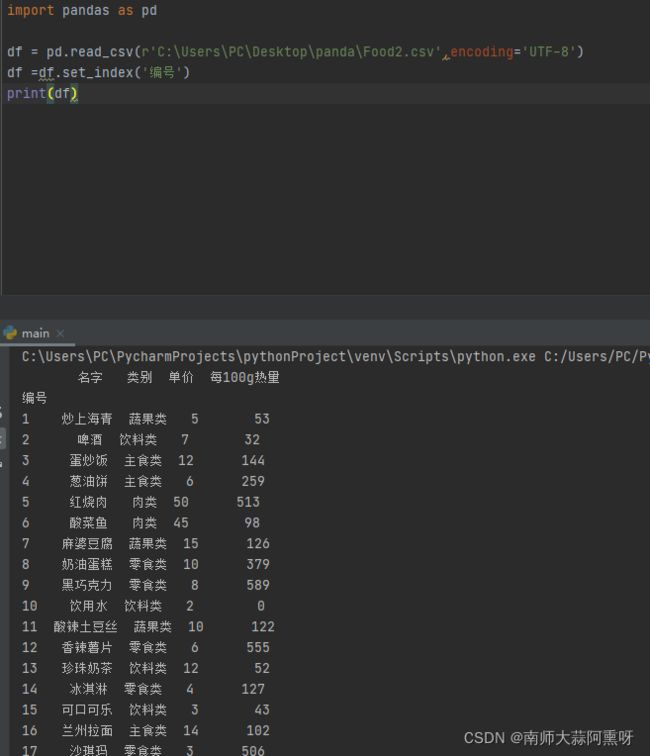
food文件内容可用记事本创建改后缀为csv
编号,名字,类别,单价,每100克热量
1,炒上海青,蔬果类,5,53
2,啤酒,饮料类,7,32
3,蛋炒饭,主食类,12,144
4,葱油饼,主食类,6,259
5,红烧肉,肉类,50,513
6,酸菜鱼,肉类,45,98
7,麻婆豆腐,蔬果类,15,126
8,奶油蛋糕,零食类,10,379
9,黑巧克力,零食类,8,589
10,饮用水,饮料类,2,0
11,酸辣土豆丝,蔬果类,10,122
12,香辣薯片,零食类,6,555
13,珍珠奶茶,饮料类,12,52
14,冰淇淋,零食类,4,127
15,可口可乐,饮料类,3,43
16,兰州拉面,主食类,14,102
17,沙琪玛,零食类,3,506
18,烤鸡翅,肉类,15,185
19,北京烤鸭,肉类,55,436
20,西瓜,蔬果类,20,31

import pandas as pd
df = pd.read_csv(r'C:\Users\PC\Desktop\panda\Food2.csv',encoding='UTF-8')
df =df.set_index('编号')
print(df)
如果提供的csv文件并不包含字段名,第一行开始就是内容,则要在导入时使用names参数拟定字段名
import pandas as pd
df = pd.read_csv(r'C:\Users\PC\Desktop\panda\Food2.csv',encoding='UTF-8',names=['a','b','c','d','e'])
df =df.set_index('a')
print(df)

CSV文件的导出
pandas提供to_csv函数将DataFrame转换成文本内容
函数第一个参数是导出路径,seq参数可以指定分隔符
import pandas as pd
b =[{'姓名':'张三','年龄':16,'成绩':88},{'姓名':'张2','年龄':15,'成绩':87},{'姓名':'张1','年龄':18,'成绩':98}]
a = pd.DataFrame(b)
a.to_csv(r'C:\Users\PC\Desktop\panda\info01.csv',sep=',')

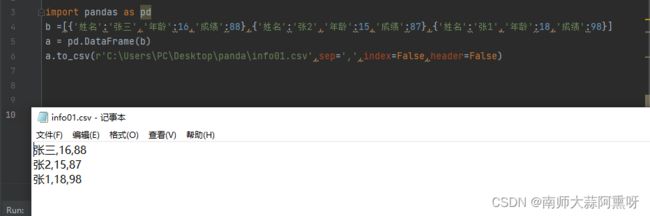
不导出行号和标签,可分别将index或header设置为False
import pandas as pd
b =[{'姓名':'张三','年龄':16,'成绩':88},{'姓名':'张2','年龄':15,'成绩':87},{'姓名':'张1','年龄':18,'成绩':98}]
a = pd.DataFrame(b)
a.to_csv(r'C:\Users\PC\Desktop\panda\info01.csv',sep=',',index=False,header=False)
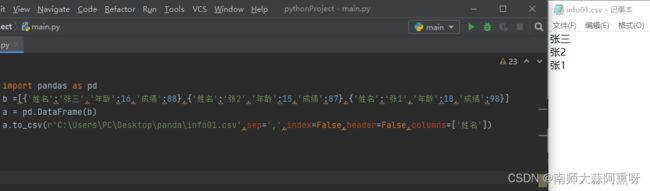
使用columns参数设置想导出的列
import pandas as pd
b =[{'姓名':'张三','年龄':16,'成绩':88},{'姓名':'张2','年龄':15,'成绩':87},{'姓名':'张1','年龄':18,'成绩':98}]
a = pd.DataFrame(b)
a.to_csv(r'C:\Users\PC\Desktop\panda\info01.csv',sep=',',index=False,header=False,columns=['姓名'])
数据清理分组
还是以Food.csv为例子继续讲解
分组
可将DataFrame按某个标签值进行分组,如将食物按类别分组
得到的结果可以用for来遍历,遍历的每个元素都是一个DataFrame
import pandas as pd
df = pd.read_csv(r'C:\Users\PC\Desktop\panda\Food2.csv',encoding='UTF-8')
group =df.groupby('类别')
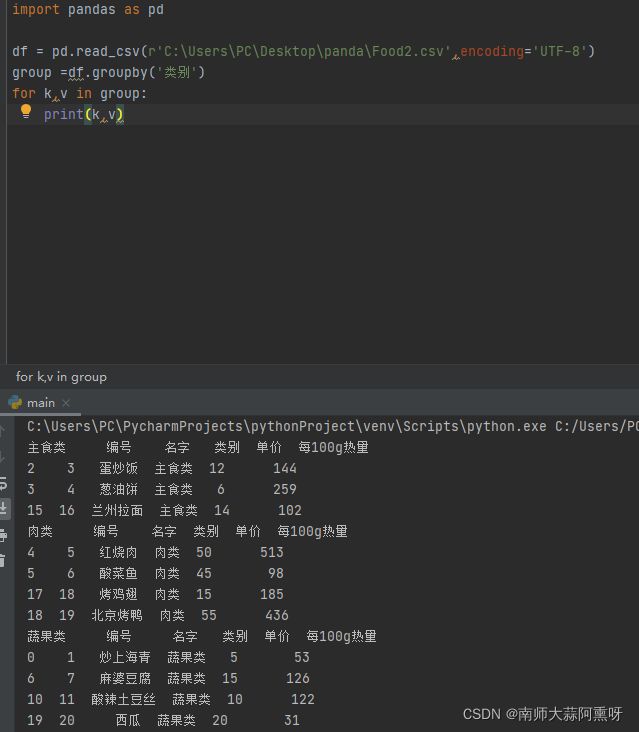
for k,v in group:
print(k,v)
计算每个类别最高热量的食物,其他函数(求和、求平均等)用法相同
import pandas as pd
df = pd.read_csv(r'C:\Users\PC\Desktop\panda\Food2.csv',encoding='UTF-8')
group =df.groupby('类别')
print(group.max())

排序
sort_index按索引排序
sort_values按值排序,可以指定一个或多个列名
注意排序操作不会改变原来的DataFrame,而是生成新的DataFrame
import pandas as pd
df = pd.read_csv(r'C:\Users\PC\Desktop\panda\Food2.csv',encoding='UTF-8')
print(df.sort_values('每100g热量'))
print("--------------------------------------------")
print(df.sort_values('每100g热量',ascending=False))#倒序
print("--------------------------------------------")
print(df.sort_values(['类别','每100g热量']))#先排序类别再排序热量

删除
使用drop函数进行删除,注意:
1.删除列时,需要指定轴方向 axis=1
2.删除操作不会改变原来的DataFrame,而是生成新的DataFrame
import pandas as pd
df = pd.read_csv(r'C:\Users\PC\Desktop\panda\Food2.csv',encoding='UTF-8')
print('删除第一行')
print(df.drop(1))#删除第一行
print('删除第一第二行')
print(df.drop([1,2]))#删除第一第二行
print('删除编号这一列')
print(df.drop('编号',axis=1))#删除编号这一列
print('删除编号和名字这两列')
print(df.drop(['编号','名字'],axis =1))#删除编号和名字这两列

缺失值处理
缺失值的表现形式
NaN:表示非数字,出现于数字中的缺失数据
Python中的None也被当做NaN处理
缺失值的判断:
DataFrame提供isna或isnull函数可以判断表中是否存在缺失值
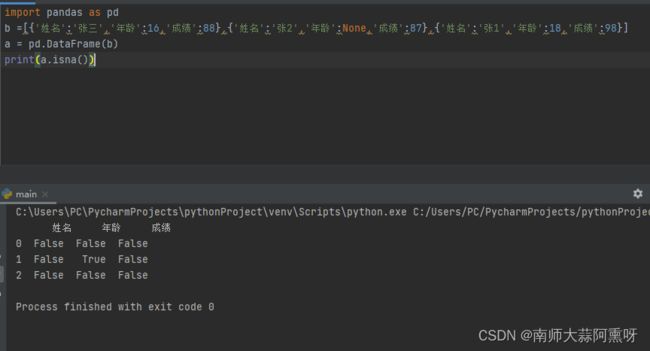
import pandas as pd
b =[{'姓名':'张三','年龄':16,'成绩':88},{'姓名':'张2','年龄':None,'成绩':87},{'姓名':'张1','年龄':18,'成绩':98}]
a = pd.DataFrame(b)
print(a.isna())
缺失值的删除
使用dropna函数会删除包含空数据的所有行
import pandas as pd
b =[{'姓名':'张三','年龄':16,'成绩':88},{'姓名':'张2','年龄':None,'成绩':87},{'姓名':'张1','年龄':18,'成绩':98}]
a = pd.DataFrame(b)
print(a.dropna())

dropna函数的参数中,axis可以指定删除的方向(行或列);how可以指定有一个空值就删除还是所有的都是空值才删除
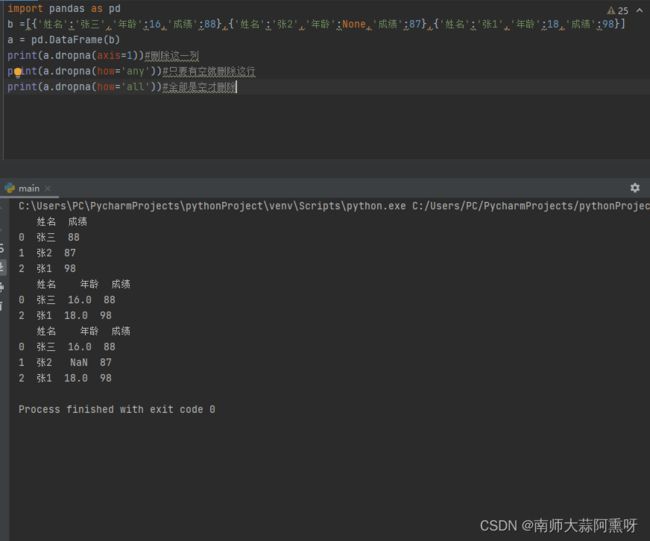
import pandas as pd
b =[{'姓名':'张三','年龄':16,'成绩':88},{'姓名':'张2','年龄':None,'成绩':87},{'姓名':'张1','年龄':18,'成绩':98}]
a = pd.DataFrame(b)
print(a.dropna(axis=1))#删除这一列
print(a.dropna(how='any'))#只要有空就删除这行
print(a.dropna(how='all'))#全部是空才删除
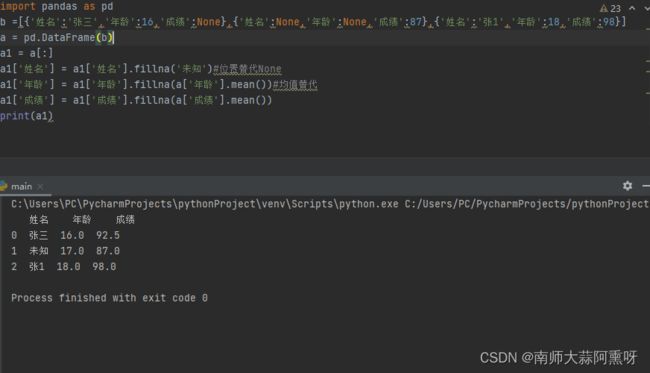
缺失值的填充
使用fillna函数填充缺失值,可以指定一个值替换表中的空值
处理时可以按列分别处理
import pandas as pd
b =[{'姓名':'张三','年龄':16,'成绩':None},{'姓名':None,'年龄':None,'成绩':87},{'姓名':'张1','年龄':18,'成绩':98}]
a = pd.DataFrame(b)
a1 = a[:]
a1['姓名'] = a1['姓名'].fillna('未知')#位置替代None
a1['年龄'] = a1['年龄'].fillna(a['年龄'].mean())#均值替代
a1['成绩'] = a1['成绩'].fillna(a['成绩'].mean())
print(a1)