Keras深度学习实战(34)——构建聊天机器人
Keras深度学习实战(34)——构建聊天机器人
-
- 0. 前言
- 1. 模型与数据集分析
-
- 1.1 命名实体识别
- 1.2 数据集分析
- 1.3 模型分析
- 2. 实现聊天机器人
-
- 2.1 命名实体提取模型
- 2.2 意图提取模型
- 2.3 模型整合
- 小结
- 系列链接
0. 前言
随着自然语言处理技术的飞速发展以及互联网上对话语料的不断积累,聊天机器人取得了迅速的发展,得到了学术界的广泛关注,并且在现实世界中也得到了一定的应用。当前,聊天机器人可以分为检索式聊天机器人和生成式聊天机器人,而检索式聊天机器人由于其生成的回复流畅且计算资源消耗小,仍然是目前实际应用中聊天机器人的主要实现手段。本节中,我们将学习检索式聊天机器人的基本原理,并实现其中的关键核心技术。
1. 模型与数据集分析
通常我们可以利用聊天机器人执行一些常见的查询 (query),在实际场景中,尤其是可以从数据库中查找结果或利用查询 API 获得查询结果时非常有用。鉴于此,可以使用两种方式设计聊天机器人:
- 将非结构化用户查询转换为结构化形式,根据转换后的结构从数据库中查询,即检索式聊天机器人
- 根据输入文本生成响应数据,即生成式聊天机器人
在本节中,我们将采用第一种方法,因为使用此方法,我们可以在将预测结果传递给用户之前,对其进行进一步的调整。将用户查询转换为结构化格式需要以下两个步骤:
- 识别查询单词中的命名实体 (
various entities) - 了解查询的意图 (
intent)
1.1 命名实体识别
命名实体识别在多个行业中都有着广泛的应用。例如,用户想去哪里?用户正在考虑购买哪种产品?在这些简单示例中,命名实体识别是从现有城市名称或产品名称的字典中进行的简单查找。但考虑以下情况:用户想从苏州到上海旅行。在此情况下,虽然计算机知道苏州和上海都是城市名称,但无法解析哪个是出发城市,哪个城市是目的城市。
虽然我们可以添加一些启发式的方法,例如在目标城市之前添加 to 得到 to city 作为命名实体,在出发城市前添加 from 得到 from city 作为另一个命名实体,但是该方法扩展性差,因为我们需要在此类示例中人工重复此过程。为了降低对手动调整特征的依赖性,神经网络可以派上用场,使用机器学习方法进行特征工程获取输出。
1.2 数据集分析
为了构建聊天机器人,我们将使用航空公司相关的用户查询数据集,相关数据集可以在 gitcode 链接中下载,其中包含了大量关于航空数据的用户查询,下载完成后进行解压。
1.3 模型分析
接下来,我们使用航空公司相关的用户查询数据集,构建相关模型,以从查询中提取命名实体以及查询意图:
- 使用一个带有查询标签和查询中每个单词所属的实体的数据集:
- 如果我们没有带标记的数据集,则需要在查询中手动标记实体,以获取足够数量训练数据样本
- 由于给定单词周围的单词可能会对分类结果产生影响,因此使用基于长短时记忆网络 (
Long Short Term Memory,LSTM) 的模型解决此问题 - 另外,影响给定单词预测结果的单词可能在给定单词的左侧或右侧,因此我们使用双向
LSTM解决该问题 - 预处理输入数据集,以便可以将其输入到
LSTM的多个时间戳中 - 对输出数据进行独热编码,以优化模型
- 构建返回查询中每个单词所属实体的模型
- 构建另一个用于提取查询意图的模型
2. 实现聊天机器人
接下来,我们利用 Keras 实现之前定义的模型架构。
2.1 命名实体提取模型
(1) 首先导入数据集,并加载训练与测试数据:
import numpy as np
import pickle
import os
DATA_DIR="atis/"
train_fname = os.path.join(DATA_DIR, 'atis.train.pkl')
test_fname = os.path.join(DATA_DIR, 'atis.test.pkl')
def load_ds(fname):
with open(fname, 'rb') as stream:
ds,dicts = pickle.load(stream)
print('Done loading: ', fname)
print(' samples: {:4d}'.format(len(ds['query'])))
print(' vocab_size: {:4d}'.format(len(dicts['token_ids'])))
print(' slot count: {:4d}'.format(len(dicts['slot_ids'])))
print(' intent count: {:4d}'.format(len(dicts['intent_ids'])))
return ds,dicts
train_ds, dicts = load_ds(train_fname)
test_ds, dicts = load_ds(test_fname)
数据加载完成后,打印出的统计信息如下所示,其中 sample 是用户查询,slot 是单词所属命名实体,intent 表示查询的意图:
Done loading: atis/atis.train.pkl
samples: 4978
vocab_size: 943
slot count: 129
intent count: 26
Done loading: atis/atis.test.pkl
samples: 893
vocab_size: 943
slot count: 129
intent count: 26
(2) 为 query、slot 和 intent 中的每个单词分配不同 ID:
t2i, s2i, in2i = map(dicts.get, ['token_ids', 'slot_ids','intent_ids'])
i2t, i2s, i2in = map(lambda d: {d[k]:k for k in d.keys()}, [t2i,s2i,in2i])
query, slots, intent = map(train_ds.get, ['query', 'slot_labels', 'intent_labels'])
token (词汇表中的单词),slot (单词所属命名实体)和 intent 的 ID 的示例如下:
Token Entity Intent
BOS:178 O:128 airfare:3
cheapest:296 B-cost_relative:21 airfare:3
tomorrow:853 B-depart_date.today_relative:29 flight:14
cleveland:304 B-fromloc.city_name:48 aircraft:1
denver:351 B-city_name:17 ground_service:21
获取查询中相对应的查询、意图和实体的示例样本:
for i in range(2):
print('{:4d}:{:>15}: {}'.format(i, i2in[intent[i][0]],
' '.join(map(i2t.get, query[i]))))
print('intent:', i2in[intent[i][0]])
for j in range(len(query[i])):
print('{:>33} {:>40}'.format(i2t[query[i][j]],
i2s[slots[i][j]]))
print('*'*74)
以上代码的输入如下所示,其中顶部的句子是一个查询语句 query,slot 代表每个单词所属的对象类型;左侧单词表示查询中的单词,右侧表示单词所属实体对象,其中 O 代表一个非命名实体对象;此外,共有 23 种意图类别用于描述查询的意图 intent。
0: flight: BOS i want to fly from boston at 838 am and arrive in denver at 1110 in the morning EOS
intent: flight
BOS O
i O
want O
to O
fly O
from O
boston B-fromloc.city_name
at O
838 B-depart_time.time
am I-depart_time.time
and O
arrive O
in O
denver B-toloc.city_name
at O
1110 B-arrive_time.time
in O
the O
morning B-arrive_time.period_of_day
EOS O
(3) 接下来,将数据转换为一个列表,其中每个列表对应于数据集中的一个查询:
i2t2 = []
i2s2 = []
c_intent=[]
for i in range(4978):
a_query = []
b_slot = []
c_intent.append(i2in[intent[i][0]])
for j in range(len(query[i])):
a_query.append(i2t[query[i][j]])
b_slot.append(i2s[slots[i][j]])
i2t2.append(a_query)
i2s2.append(b_slot)
i2t2 = np.array(i2t2)
i2s2 = np.array(i2s2)
i2in2 = np.array(c_intent)
# 打印查询中单词、命名实体和意图示例
print(i2t2[1])
print(i2s2[1])
print(i2in2[1])
打印出查询中单词、单词所属命名实体类别和查询意图的示例如下:
['BOS', 'what', 'flights', 'are', 'available', 'from', 'pittsburgh', 'to', 'baltimore', 'on', 'thursday', 'morning', 'EOS']
['O', 'O', 'O', 'O', 'O', 'O', 'B-fromloc.city_name', 'O', 'B-toloc.city_name', 'O', 'B-depart_date.day_name', 'B-depart_time.period_of_day', 'O']
flight
(4) 创建输入和输出数据集:
final_sentences = []
final_targets = []
final_docs = []
for i in range(len(i2t2)):
tokens = ''
entities = ''
intent = ''
for j in range(len(i2t2[i])):
tokens= tokens + i2t2[i][j] + ' '
entities = entities + i2s2[i][j] +' '
intent = i2in2[i]
final_sentences.append(tokens)
final_targets.append(entities)
final_docs.append(intent)
使用以上代码可以得到最终查询、单词所属命名实体类别和意图的列表,如下所示:
query: BOS what flights are available from pittsburgh to baltimore on thursday morning EOS
slots: O O O O O O B-fromloc.city_name O B-toloc.city_name O B-depart_date.day_name B-depart_time.period_of_day O
intent: flight
(5) 接下来,我们将每个输入句子中的单词转换为单词 ID,形成的对应 ID 列表:
from collections import Counter
counts = Counter()
for i,sentence in enumerate(final_sentences):
counts.update(sentence.split())
sentence_words = sorted(counts, key=counts.get, reverse=True)
chars = sentence_words
max_chars = len(chars)
sentence_word_to_int = {word: i for i, word in enumerate(sentence_words, 1)}
sentence_int_to_word = {i: word for i, word in enumerate(sentence_words, 1)}
mapped_reviews = []
for review in final_sentences:
mapped_reviews.append([sentence_word_to_int[word] for word in review.split()])
(6) 然后,我们将每个输出单词转换为单词ID:
from collections import Counter
counts = Counter()
for i,sentence in enumerate(final_targets):
counts.update(sentence.split())
target_words = sorted(counts, key=counts.get, reverse=True)
chars = target_words
nb_chars = len(target_words)
print(nb_chars)
target_word_to_int = {word: i for i, word in enumerate(target_words, 1)}
target_int_to_word = {i: word for i, word in enumerate(target_words, 1)}
mapped_targets = []
for review in final_targets:
mapped_targets.append([target_word_to_int[word] for word in review.split()])
(7) 填充输入并对输出进行独热编码,在填充输入之前确定查询 query 的最大长度,打印统计的查询的最大长度,其值为 48:
length_sent = []
for i in range(len(mapped_reviews)):
a = mapped_reviews[i]
b = len(a)
length_sent.append(b)
print(max_len)
接下来,将输入和输出的最大长度填充为 50 ,因为没有输入查询长度超过 48 个单词:
from keras.preprocessing.sequence import pad_sequences
max_len = np.max(length_sent) + 2
x = pad_sequences(maxlen=max_len, sequences=mapped_reviews, padding="post", value=0)
y = pad_sequences(maxlen=max_len, sequences=mapped_targets, padding="post", value=0)
然后,我们将输出转换为独热编码:
from keras.utils import to_categorical
y2 = [to_categorical(i, num_classes=nb_chars+1) for i in y]
y2 = np.array(y2)
(8) 将数据集拆分为训练和测试数据集,并构建模型:
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, y2, test_size=0.20)
from keras.layers import Input, Embedding, Dropout, Dense, Bidirectional, LSTM
from keras import Model
input = Input(shape=(50,))
model = Embedding(input_dim=max_chars+1, output_dim=32, input_length=50)(input)
model = Dropout(0.1)(model)
model = Bidirectional(LSTM(units=100, return_sequences=True, recurrent_dropout=0.1))(model)
out = (Dense(124, activation="softmax"))(model)
model = Model(input, out)
model.summary()
模型的简要信息输出如下:
Model: "functional_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) [(None, 50)] 0
_________________________________________________________________
embedding (Embedding) (None, 50, 32) 28544
_________________________________________________________________
dropout (Dropout) (None, 50, 32) 0
_________________________________________________________________
bidirectional (Bidirectional (None, 50, 200) 106400
_________________________________________________________________
dense (Dense) (None, 50, 124) 24924
=================================================================
Total params: 159,868
Trainable params: 159,868
Non-trainable params: 0
_________________________________________________________________
在以上代码中,我们使用双向 LSTM,LSTM 层输出维度为 100,因此双向 LSTM 输出维度为 200。
(9) 编译并拟合模型:
model.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["acc"])
history = model.fit(x_train,y_train,
batch_size=64,
epochs=10,
validation_data=(x_test,y_test),
verbose=1)
训练完成的模型应用在查询中,为每个单词分配正确的命名实体的准确率约为 96%:
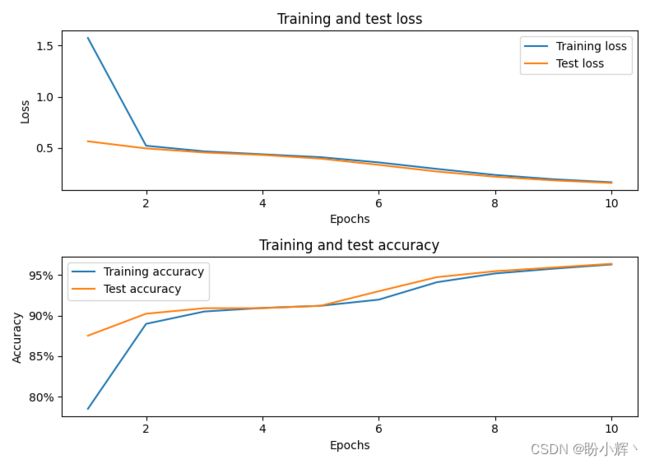
2.2 意图提取模型
现在,我们已经建立了一个命名实体提取模型,该模型在预测查询中的实体时具有较高的准确率,本节中,我们继续提取查询的意图。
(1) 我们可以重用在上一个模型中使用的大多数变量,将每个查询的意图转换为一个 ID:
from collections import Counter
counts = Counter()
for i,sentence in enumerate(final_docs):
counts.update(sentence.split())
intent_words = sorted(counts, key=counts.get, reverse=True)
chars = intent_words
nb_chars = len(intent_words)
intent_word_to_int = {word: i for i, word in enumerate(intent_words, 1)}
intent_int_to_word = {i: word for i, word in enumerate(intent_words, 1)}
mapped_docs = []
for review in final_docs:
mapped_docs.append([intent_word_to_int[word] for word in review.split()])
(2) 将查询的意图转换为独热编码:
classes = len(np.unique(mapped_docs)) + 1
print(classes)
doc2 = [to_categorical(i[0], num_classes=classes) for i in mapped_docs]
doc3 = np.array(doc2)
(3) 将数据集划分为训练和测试数据集、构建模型,然后编译并训练模型:
from sklearn.model_selection import train_test_split
x_train, x_test, y_train, y_test = train_test_split(x, doc3, test_size=0.2)
input = Input(shape=(50,))
model2 = Embedding(input_dim=max_chars+1, output_dim=32, input_length=50)(input)
model2 = Dropout(0.1)(model2)
model2 = Bidirectional(LSTM(units=100))(model2)
out = (Dense(classes, activation="softmax"))(model2)
model2 = Model(input, out)
model2.compile(optimizer="adam", loss="categorical_crossentropy", metrics=["acc"])
history = model2.fit(x_train, y_train,
batch_size=64,
epochs=10,
validation_data=(x_test, y_test),
verbose=1)
训练完成的模型在验证数据集中,识别查询的意图类别的准确率约为 92%:

2.3 模型整合
我们已经构建并训练了 2 个模型,其中第 1 个模型预测查询中的实体,第 2 个模型提取查询的意图。在本小节中,我们综合使用以上 2 个模型。
(1) 我们首先定义一个函数,该函数接受查询并将其转换为结构化格式:
def preprocessing(text):
text2 = text.split()
a=[]
for i in range(len(text2)):
a.append(sentence_word_to_int[text2[i]])
return a
(2) 定义用于输入查询文本,并对其使用定义的预处理函数 preprocessing 进行预处理,以便可以将其传递给模型:
text = "BOS i would fly from boston to dallas EOS"
# 对输入文本进行预处理
indexed_text = preprocessing(text)
# 打印预处理后的列表
print(indexed_text)
# 填充输入列表
padded_text=np.zeros(50)
padded_text[:len(indexed_text)]=indexed_text
padded_text=padded_text.reshape(1,50)
# 打印填充后的列表
print(padded_text)
预处理输入文本,将其转换为单词 ID 列表,打印列表结果如下:
# 预处理后的列表
[1, 14, 41, 40, 4, 11, 3, 23, 2]
# 填充后的列表
[[ 1. 14. 41. 40. 4. 11. 3. 23. 2. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0.]]
(3) 接下来,预测输入的意图:
pred_index_intent = np.argmax(model2.predict(padded_text),axis=1)
print(intent_int_to_word[pred_index_intent[0]])
使用训练后的模型可以预测出查询的意图与航班有关,输出预测结果如下所示:
flight
(4) 提取与查询中的单词相关的命名实体:
pred_entities = np.argmax(model.predict(padded_text),axis=2)
for i in range(len(pred_entities[0])):
if pred_entities[0][i]>1:
print('word: ',text.split()[i], 'entity: ',target_int_to_word[pred_entities[0][i]])
打印模型预测结果,可以看到模型已将单词正确分类为正确的实体。
word: boston entity: B-fromloc.city_name
word: dallas entity: B-toloc.city_name
现在我们已经确定了命名实体和查询意图,我们就可以使用预定义的 SQL 查询(或 API),其中参数由模型提取的实体填充,并且每个意图都可能具有不同的 API / SQL 查询来为用户提供所需信息。
小结
随着深度学习的快速发展,聊天机器人也受到越来越多的关注。聊天机器人作为一种新颖的人机交互方式,正在成为移动搜索和服务的入口之一。本节中,我们首先介绍了聊天机器人的分类方法和基本原理,并重点介绍了检索式聊天机器人的构建方法和关键核心技术,最后使用 Keras 实现了构建聊天机器人的关键模型。
系列链接
Keras深度学习实战(1)——神经网络基础与模型训练过程详解
Keras深度学习实战(2)——使用Keras构建神经网络
Keras深度学习实战(3)——神经网络性能优化技术
Keras深度学习实战(4)——深度学习中常用激活函数和损失函数详解
Keras深度学习实战(5)——批归一化详解
Keras深度学习实战(6)——深度学习过拟合问题及解决方法
Keras深度学习实战(7)——卷积神经网络详解与实现
Keras深度学习实战(8)——使用数据增强提高神经网络性能
Keras深度学习实战(9)——卷积神经网络的局限性
Keras深度学习实战(10)——迁移学习详解
Keras深度学习实战(11)——可视化神经网络中间层输出
Keras深度学习实战(12)——面部特征点检测
Keras深度学习实战(13)——目标检测基础详解
Keras深度学习实战(14)——从零开始实现R-CNN目标检测
Keras深度学习实战(15)——从零开始实现YOLO目标检测
Keras深度学习实战(16)——自编码器详解
Keras深度学习实战(17)——使用U-Net架构进行图像分割
Keras深度学习实战(18)——语义分割详解
Keras深度学习实战(19)——使用对抗攻击生成可欺骗神经网络的图像
Keras深度学习实战(20)——DeepDream模型详解
Keras深度学习实战(21)——神经风格迁移详解
Keras深度学习实战(22)——生成对抗网络详解与实现
Keras深度学习实战(23)——DCGAN详解与实现
Keras深度学习实战(24)——从零开始构建单词向量
Keras深度学习实战(25)——使用skip-gram和CBOW模型构建单词向量
Keras深度学习实战(26)——文档向量详解
Keras深度学习实战(27)——循环神经详解与实现
Keras深度学习实战(28)——利用单词向量构建情感分析模型
Keras深度学习实战(29)——长短时记忆网络详解与实现
Keras深度学习实战(30)——使用文本生成模型进行文学创作
Keras深度学习实战(31)——构建电影推荐系统
Keras深度学习实战(32)——基于LSTM预测股价
Keras深度学习实战(33)——基于LSTM的序列预测模型