神经网络压缩的方式与实验
前言
二年级我在参加全国大学生集成电路创新创业大赛的时候,有幸见到了将CNN网络Deploy到FPGA的设计,在这之后我便一直想完成该设计。写下本文的时间是2020年4月份,三年级寒假刚开始,我便为了完成这项工作开始从头学起Machine Learning的理论基础,并且在了解过一些开源的Verilog-CNN的项目之后,一直存在着一些疑惑,但由于开发FPGA的设备都在校园,所以一直没有机会实践证实。
深度学习已被证明在包括图像分类(Image Classification),目标检测(Object Detection),自然语言处理(Natural Language Processing)等任务上能够取得相当不错的效果。现如今,大量的应用程序都配备了与之相关的深度学习算法,而人们使用这些应用程序甚至无法察觉到这种技术的存在。
目前看到过的将CNN网络Deploy到FPGA上的优秀项目是:CNN-FPGA
该项目解答了两个我困惑的问题:
-
复杂的CNN网络具有如此多的参数、学习板卡的LUT资源是否足够
答案是不够的,只能实现相当小的网络,该项目的输入图像大小为28 * 28的RGB图像,但好在其使用的是标准的CNN架构,还有优化的可能,这个过程我们叫做网络压缩(Network Compression)。
-
如何处理FPGA不擅长的浮点数运算
答案是将Bias和Weight转化成有符号的定点数,这个过程叫做网络量化(Network Quantization),属于网络压缩众多方法的一类。
这无疑说明了网络压缩是完成该设计必不可少的一步,本文主要记录我在网络压缩(Network Compression)的主要四种方案的实践经历:
- Knowledge Distillation:让小的Model借由观察大Model的行为让自己学习的更好。
- Network Pruning:将已经学习好的大Model做裁剪,再训练裁减后的Model。
- Weight Quantization:用更好的方案表示Model中的参数,以此来降低运算量和存储。
- Design Architecture:将原始的Layer用更小的参数来表现,比如深度可分离卷积的架构。
正文
本次实践所使用的数据集是李宏毅老师2020机器学习作业三的数据集 food-11,相关程式的编写也围绕着作业三展开,即对作业三的模型进行压缩。
网络压缩理论:点击前往
Kaggle地址:点击前往
作业说明:点击前往
原始的网络结构如下图:
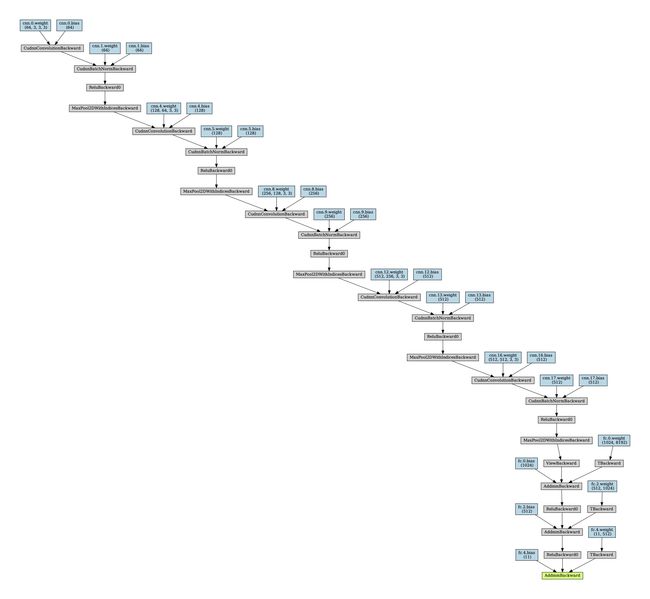
该图是一个标准的CNN架构,如果因为网站图床压缩文件导致图片失真, 可以点击这里查看原图:
40个epoch之后,训练集的准确率收敛在0.9左右,验证集的准确率收敛在0.7左右,表现优秀。
| Solutions | Flops | Param | Train Acc | Val Acc | epochs |
|---|---|---|---|---|---|
| Standard CNN | 1100.19M | 12.833M | 0.9 | 0.7 | 40 |
然后本次实验的目的是使用网络压缩的方案,将上文中的网络进行优化,并观察优化过后的模型表现如何。
在下面的文章中,我会首先尝试用Design Architecture的办法重新设计Model,其次该Model还可以用作Knowledge Distillation和Network Pruning,最后我们做Weight Quantization。
Design Architecture
在本次设计中,我采用了深度可分离卷积的架构,关于其实现原理与理论不做赘述。它的核心思想是将原来的Convolution操作转化成depthwise(DW)和pointwise(PW)两个操作。DW是指每一个filter只对一个channel进行卷积,PW是将DW操作后的feature map进行加权组合。总的来说,我们需要将原来的卷积单元进行改造即可,Pytorch中为了实现卷积的DW操作,为Conv层提供了group参数。
将原来的网络进行深度可分离卷积的重构之后,结构如下图
同样,你可以点击这里查看原图。
| Solutions | Flops | Param | Train Acc | Val Acc | epochs |
|---|---|---|---|---|---|
| Standard CNN | 1100.19M | 12.833M | 0.9 | 0.7 | 40 |
| Design Architecture | 31.21M | 256.78K | 0.85 | 0.6 | 100 |
虽然收敛的速度变慢了很多,并且在Training Set 以及Validation Set上的准确度有所下降,但是计算量和参数量都有了显著的下降。
Knowledge Distillation
也许我们设计的网络在Validation Set上的表现不够好是因为训练的数据集有一些噪声。Knowledge Distillation,也叫知识蒸馏能够解决该问题。核心思想是准备一个pretrained的好Model,然后让我们的网络学习该Model的输出,这样我们的网络不仅能学习图片中是何种食物,也能学习到概率分布。
首先面对的问题是pretrained的Model从哪里来,在这里我踩了很多坑,尝试使用了从头开始训练的resnet18、VGG16、GoogleNet等网络,在经过很多次的epoch之后验证集上的准确率仍然只有0.7,最后使用Transfer Learning的方式,移植了resnet34网络,并且为了省时间只训练了全连接层,仅仅5个epoch,就达到了0.86的准确率,最终迭代了20次后在训练集与验证集上的准确率都达到了0.9。
Knowledge Distillation实现的方式是将训练数据预先丢进我们有的pretrained的好Model(以后简称TeacherNet)即上文中提到的resnet34网络,将它得到的输出送给我们的网络,不过还需要重新定义我们的Loss函数,既要考虑到StudentNet的输出,也要考虑到TeacherNet的输出,在李宏毅老师的投影片里,Loss的定义如下:
L o s s = α T 2 × K L ( Teacher’s Logits T ∣ ∣ Student’s Logits T ) + ( 1 − α ) ( 原本的Loss ) Loss = \alpha T^2 \times KL(\frac{\text{Teacher's Logits}}{T} || \frac{\text{Student's Logits}}{T}) + (1-\alpha)(\text{原本的Loss}) Loss=αT2×KL(TTeacher’s Logits∣∣TStudent’s Logits)+(1−α)(原本的Loss)
| Solutions | Flops | Param | Train Acc | Val Acc | epochs |
|---|---|---|---|---|---|
| Standard CNN | 1100.19M | 12.833M | 0.9 | 0.7 | 40 |
| Design Architecture | 31.21M | 256.78K | 0.85 | 0.6 | 100 |
| Knowledge Distillation | 31.21M | 256.78K | 0.82 | 0.8 | 80 |
根据测试的结果可以看到深度可分离卷积架构学习TeacherNet之后,准确率有了很大的提高,并且他们所需要的参数和计算量相同。
Network Pruning
所谓的网络剪枝,是给我们的网络瘦身,去除掉一些没有用的节点。在这里我使用的是neural pruning的方式,删除掉不重要的节点。因为采用Weight pruning的方式,如果直接删除无用的weight会破坏矩阵导致不能使用GPU进行运算加速,或者将无用的weight置0,这样并不会实际意义上节省空间。
第一个要解决的问题是,如何衡量节点的重要性。根据李宏毅老师的作业三、有一个简单的方法:batchnorm layer的因子來決定neuron的重要性。 (By Paper Network Slimming)
然后被剪枝的网络是Design Architecture中设计的深度可分离卷积架构,其在验证集的准确率是0.58左右、将网络的weight按照rate的比例来剪枝,得到如下结果:
| rate | train_acc | valid_acc | epoch |
|---|---|---|---|
| 0.9500 | 0.7110 | 0.5808 | 0 |
| 0.9500 | 0.7122 | 0.5808 | 1 |
| 0.9500 | 0.7161 | 0.5828 | 2 |
| 0.9500 | 0.7121 | 0.5802 | 3 |
| 0.9500 | 0.7111 | 0.5787 | 4 |
| 0.9025 | 0.6726 | 0.5545 | 0 |
| 0.9025 | 0.6713 | 0.5586 | 1 |
| 0.9025 | 0.6627 | 0.5464 | 2 |
| 0.9025 | 0.6690 | 0.5516 | 3 |
| 0.9025 | 0.6745 | 0.5560 | 4 |
| 0.8574 | 0.6200 | 0.5105 | 0 |
| 0.8574 | 0.6216 | 0.5117 | 1 |
| 0.8574 | 0.6199 | 0.5163 | 2 |
| 0.8574 | 0.6134 | 0.5137 | 3 |
| 0.8574 | 0.6223 | 0.5015 | 4 |
| 0.8145 | 0.5771 | 0.4895 | 0 |
| 0.8145 | 0.5735 | 0.4825 | 1 |
| 0.8145 | 0.5749 | 0.4825 | 2 |
| 0.8145 | 0.5781 | 0.4863 | 3 |
| 0.8145 | 0.5813 | 0.4831 | 4 |
| 0.7738 | 0.5461 | 0.4685 | 0 |
| 0.7738 | 0.5446 | 0.4691 | 1 |
| 0.7738 | 0.5481 | 0.4636 | 2 |
| 0.7738 | 0.5426 | 0.4633 | 3 |
| 0.7738 | 0.5478 | 0.4589 | 4 |
在去除掉网络中20%的节点后、准确率下降了10%。虽然准确率看起来蛮低的,但要是被剪枝的网络是经过上文知识蒸馏出来的网络,准确率应该还能提告0.2个百分点。
经过剪枝后的参数量和浮点运算量如下:
| Solutions | Flops | Param | Train Acc | Val Acc | epochs |
|---|---|---|---|---|---|
| Standard CNN | 1100.19M | 12.833M | 0.9 | 0.7 | 40 |
| Design Architecture | 31.21M | 256.78K | 0.85 | 0.6 | 100 |
| Knowledge Distillation | 31.21M | 256.78K | 0.82 | 0.8 | 80 |
| Network Pruning | 50.80M | 171.60K | 0.55 | 0.46 | 5 |
可是不知道为什么、浮点运算居然变多了!?
Weight Quantization
权重量化的方式有很多种,这里只尝试了将原本的float32类型用foat16、或者8bit的数据来进行量化,因为该方式对于FPGA来说实现更加方便。
对于16bit、Pytorch能很方便的将32bit的float转化成16bit的float,这里再给出float32量化到8bit的公式。
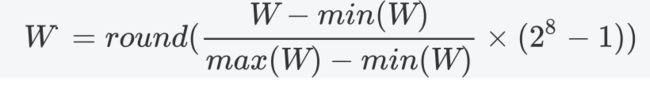
| Solutions | Flops | Param | Train Acc | Val Acc | epochs |
|---|---|---|---|---|---|
| Standard CNN | 1100.19M | 12.833M | 0.9 | 0.7 | 40 |
| Design Architecture | 31.21M | 256.78K | 0.85 | 0.6 | 100 |
| Knowledge Distillation | 31.21M | 256.78K | 0.82 | 0.8 | 80 |
| Network Pruning | 50.80M | 171.60K | 0.55 | 0.46 | 5 |
| Quatization Float16 | 62.43M | 256.78K | 0.80 | 0.59 | 10 |
| Quatization 8bit | 31.21M | 256.78K | 0.80 | 0.59 | 10 |
保存下来8bit的权重参数文件大小比16bit的文件少占用了一半的存储,但是准确率却没有下降。
以上,就是本次实验的内容,为了完成该实验,查阅了很多资料,跑了很长时间的数据,但对一些知识理解还是比较浅的,希望以后的自己能修饰修饰。