MobileViT
- 论文下载: https://arxiv.org/abs/2110.02178
- 官方源码(Pytorch实现) : https://github.com/apple/ml-cvnets
- 霹雳吧啦Wz从ml-evnets仓库中剥离的代码: https://github.com/WZMIAOMIAO/deep-learning-for-image-processing/tree/master/pytorch_classification/MobileViT
- MobileViT对应博文: https://blog.csdn.net/qq_37541097/article/details/126715733
ABSTRACT:
Light-weight convolutional neural networks (CNNs) are the de-facto for mobile vision tasks. Their spatial inductive biases allow them to learn representations with fewer parameters across different vision tasks. However, these networks are spatially local. To learn global representations, self-attention-based vision trans-formers (ViTs) have been adopted. Unlike CNNs, ViTs are heavy-weight. In this paper, we ask the following question: is it possible to combine the strengths of CNNs and ViTs to build a light-weight and low latency network for mobile vision tasks? Towards this end, we introduce MobileViT, a light-weight and general-purpose vision transformer for mobile devices. MobileViT presents a different perspective for the global processing of information with transformers, i.e., transformers as convolutions. Our results show that MobileViT significantly outperforms CNN- and ViT-based networks across different tasks and datasets. On the ImageNet-1k dataset, MobileViT achieves top-1 accuracy of 78.4% with about 6 million parameters, which is 3.2% and 6.2% more accurate than MobileNetv3 (CNN-based) and DeIT (ViT-based) for a similar number of parameters. On the MS-COCO object detection task, MobileViT is 5.7% more accurate than MobileNetv3 for a similar number of parameters.
Our source code is open-source and available at: this https URL.
轻量级卷积神经网络(CNN)是移动视觉任务的事实。它们的空间归纳偏见使它们能够在不同的视觉任务中用较少的参数学习表征。然而,这些网络在空间上是局部的。为了学习全局表征,基于自我注意的视觉转换器(ViTs)已被采用。与CNN不同,ViTs是重量级的。在本文中,我们提出了以下问题:是否有可能结合CNN和ViTs的优势,为移动视觉任务建立一个轻量级和低延迟的网络?为此,我们介绍了MobileViT,一个用于移动设备的轻量级和通用的视觉变换器。MobileViT为用变换器进行全局信息处理提出了一个不同的视角,即变换器作为卷积。我们的研究结果表明,MobileViT在不同的任务和数据集上明显优于基于CNN和ViT的网络。在ImageNet-1k数据集上,MobileViT在大约600万个参数的情况下达到了78.4%的最高准确率,在类似的参数数量下,比MobileNetv3(基于CNN)和DeIT(基于ViT)要准确3.2%和6.2%。在MS-COCO物体检测任务中,在参数数量相近的情况下,MobileViT比MobileNetv3的准确率高5.7%。
我们的源代码是开源的,可在以下网站获得:这个https URL。
1. 前沿
当前纯Transformer模型存在的问题:
- Transformer参数多,算力要求高
- Transformer缺少空间归纳偏置
- Transformer迁移到其他任务比较繁琐
- Transformer模型训练困难
- 比较好理解
- 之前在讲解MSA时提到,纯Transformer结构对空间位置信息并不敏感。但是对于图像来说,空间位置信息是非常重要的。为了解决这个问题,常用的方法是加入位置偏置(位置编码)
- 相比CNN而言。之所以会相对繁琐是因为缺少空间归纳偏置。在ViT中采用的是绝对位置偏置(编码),编码的长度和输入token长度一致。这也就意味着,在训练模型的时候,在我们指定输入图像尺度之后,绝对位置偏置的编码序列长度就已经固定了。如果后期要更改输入图像的尺寸,那么输入的token长度和绝对位置编码长度不一致,这样就无法进行相加,也就没法继续后续的操作 —— 模型无法训练。针对这个问题,现有的方法一般是进行插值 —— 将绝对位置编码插值到与输入token序列相同的长度。但是使用插值这种方法又会引入一个新的问题 —— 将插值后的模型拿来用可能会出现掉点的情况。对于CNN模型,如果训练尺度是224×224,在384×384尺度上进行测试,一般是会出现涨点的情况。而通过插值方式得到的Transformer模型在一个相对更大的分辨率上进行测试,可能会掉点,这与CNN是不一样的。所以一般使用插值调节绝对位置编码之后,还需要对网络进行一个微调,以尽可能避免掉点的情况 —— 这样就导致过于繁琐。
如果我们采用Swin-Transformer中的相对位置偏置,那么是不是就会解决插值的问题?的确如此,在Swin-Transformer中,相对位置编码对输入图片的尺度并不敏感,只和设置的Window大小有关。但如果训练模型的输入图片尺度和迁移到其他任务的图片尺度相差过大时,一般还是会对Window的尺寸进行调整。举个例子,一般我们会将Swin-Transformer在ImageNet数据集进行预训练,此时的图片大小尺寸为224×224。如果我们要将模型迁移到目标检测任务中,此时输入图片的分辨率为1280×1280。很明显,输入图片尺寸发生了非常大的变化,如果此时不去调整Window的尺寸,那么迁移后的效果依旧会受到一定的影响(会掉点)。为了避免这种情况,一般还是会将Window的尺寸设置的更大一些。然而,一旦调整Window的尺寸,那么网络的相对位置编码的序列长度也会发生变化,所以还是会带来一些问题。
这里我们说了一些位置编码带来的问题,并不是说位置编码没有作用,只是说当前普遍采用的位置编码有很多值得优化的地方。在Swin-Transformer v2论文中,就针对v1中采用的相对位置编码进行优化。
- 相对CNN而言
在MobileViT论文中,作者将CNN架构和Transformer架构进行混合,原因是CNN架构本身就带有空间归纳偏置,所以在使用CNN后就不需要再单独设计位置编码了。并且CNN相比Transformer模型更加容易收敛,因此结合CNN架构可以加速整体模型的收敛速度、整个网络的训练过程更加稳定。
1.1 MobileViT与Transformer模型对比

1.2 MobileViT与CNN模型对比

1.3 Transformer模型与CNN模型对比(包含推理时间对比)

可以看到,实际推理时间中,MobileNet v2的速度是最快的,MobileViT虽然有最少的参数量,但ShuffleNet v2论文表明,参数量和推理速度并无直接的关系。
2. 模型结构
2.1 标准的Visual Transformer(ViT)
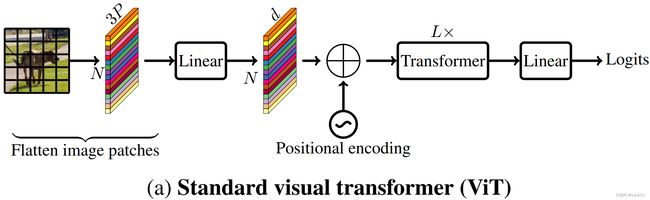
这里给出的Transformer模型和之前讲的Vision Transformer有一些不同,最主要的是上图并没有class token(class token其是参考Bert网络的),对于视觉任务而言,class token并非必需的,因此这幅图展示的是一个更加标准的视觉Transformer架构。
首先将输入图片划分为一个个patch,之后将patch数据进行展平(Flatten),之后再经过Linear Mapping得到每一个patch对应的token向量,将所有的token放在一起就得到了token序列tokens。接着,为tokens加上位置编码(偏置),这里的位置编码可以是绝对位置编码,也可以是相对位置编码。之后,再将tokens经过 L L L层Transformer Block进行信息提取,最后经过一个全连接层得到最终的输出。
展平+线性映射是可以通过一个卷积来实现的。
在经过全连接层之前一般会有一个Average Pooling层
2.2 MobileViT

其中:
Conv: 普通的卷积层MV2: 就是MobileNet v2中的Bottleneck结构(逆残差结构)MobileViT block: 如上图所示。
2.2.1 MobileViT block结构
在MobileViT block结构中,输入为 X ∈ R C × H × W \mathcal{X}\in \mathbb{R}^{C\times H \times W} X∈RC×H×W的特征图。首先通过卷积核大小为 n × n n \times n n×n的卷积层实现局部的表征建模(代码中为 3 × 3 3 \times 3 3×3卷积层),之后再经过一个 1 × 1 1 \times 1 1×1卷积层调整特征图的通道数。之后进行全局表征建模,分三步 —— ① Unfold -> ② Transformer Block -> ③ Fold。之后再经过 1 × 1 1 \times 1 1×1卷积来调整特征图通道数,将其还原回 R C × H × W \mathbb{R}^{C\times H \times W} RC×H×W(与输入特征图保持一致),之后再经过一个shortcut与输入特征图进行concat拼接,最后再经过一个 n × n n \times n n×n卷积(源码中为3×3)进行特征融合,得到MobileViT block的输出特征图。
通过分析不难看出,MobileViT block的核心是全局表征建模的部分
2.2.2 全局表征建模

在Visual Transformer中,每一个token都需要和其他的token计算相似度,这需要巨大的计算量。而在MobileViT block中的Transformer block中,一个token并不是和所有的token计算相似度,而是和它相同位置的token计算相似度,如下所示。

在Visual Transformer中,是直接将特征图展平成一个tokens,再输入到Transformer block中做Self-Attention。正如刚刚所说,这样的Self-Attention是需要和每个tokens进行相似度计算的。而在MobileViT block中,特征图并不是直接展平为tokens,而是先把特征图划分为patches(上图中是以2×2大小为例)。划分完之后,在实际做Self-Attention时,将每一个patch当中位置相同的token做Self-Attention(简单理解就是图中颜色相同的tokens互相做Self-Attention,颜色不同的不会做)。
通过这样的方式,可以减少做Self-Attention所需的计算量。对于原始的Self-Attention计算过程中,每个token都要和所有的tokens做Self-Attention,MSA的计算量简单记为 c 1 = W H C c_1 = WHC c1=WHC,而先划分patches再对相同颜色的tokens做Self-Attention的计算量为 c 2 = W H C 4 c_2 = \frac{WHC}{4} c2=4WHC,计算量大约减少 3 4 \frac{3}{4} 43。
需要注意的是,MobileViT中这样进行Self-Attention只是减少Self-Attention的计算量,对于整个Transformer Encoder模块而言,计算量并不是减少了 3 4 \frac{3}{4} 43。所以这样做确实可以减少计算量,但是没有那么显著。
Q:为什么MobileViT可以这样做Self-Attention?
A: 在图像数据中其实存在非常多的冗余数据和信息,特别对于大分辨率的图像而言。当 H H H和 W W W比较大的时候,相邻像素之间的信息差异是比较小的,如果在做Self-Attention时,每一个token都要去和其他token做Self-Attention,其是作用不是很大,也挺浪费算力的 —— 在分辨率较高的特征图上对每个token都做Self-Attention的收益并不是很高(不能说没有用,只是速度会拖慢)。
而且在进入Transformer Encoder模块之前,就有一个局部表征建模(Local Representations),所以再做全局表征建模就没必要再做的那么细了。
2.2.3 Unfold & Fold

上面讲到,MobileViT在做Self-Attention时只是将颜色相同的token去做Self-Attention,颜色不同的token之间是不进行信息交互的。那么Unfold就是起到这个作用,如上图所示,将颜色相同的tokens拼成一个序列。之后再将每个序列输入到Transformer Encoder中进行全局表征建模。进行完相似度计算后,再将序列折叠为原来的样子,这就是Fold。
3. Patch Size对模型性能的影响
上面讲过,在将特征图输入到Transformer Encoder模块之前需对其进行Patches处理,划分为一个个patch。那么具体该怎样划分patch,以及不同的patch划分对模型性能有什么影响呢。
从理论可以看到,Patch划分越大,越是可以减少Transformer Encoder的计算量,但patch的大小过大了,那么就会忽略更多的信息,可能会对模型的性能有影响,因此需要对其进行研究。
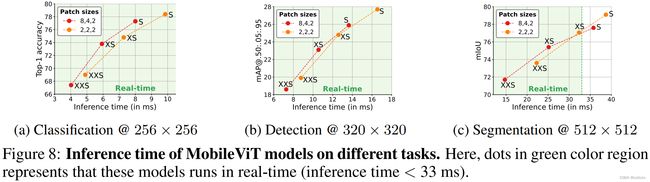
在论文中,作者做了两组实验进行对比,一组是[8, 4, 2],一组是[2, 2, 2],其中数字表示patch的大小。在进行Transformer Encoder之前,特征图的大小为 64 × 64 64 \times 64 64×64,那么patch size=8表示将特征图进行8倍下采样,4表示对特征图进行16倍下采样,2表示对特征图进行32倍下采样。
- 对于分类任务而言,patch size越大,模型推理速度越快,相应的准确率就会低一些。
- 对于目标检测任务而言,该任务对语义细节的要求是要更高一些的。patch size大小对模型性能的影响没有分类任务那么明显,但同样的,当patch size变大后,模型的速度提升,准确率下降。
- 对于分割任务而言,对语义细节要求更高,XS和S模型,小patch size会更有优势(小的patch size可以保留更多的细节信息)。
对于不同的任务而言,patch size的大小需要tradeoff。在源码中,作者只给了[2, 2, 2]这么一个选项。
4. MobileViT模型规格
- MobileViT-S(small) -> 小
- MobileViT-XS(extra small) -> 更小
- MobileViT-XXS(extra extra small) -> 最小
在源码中,作者根据不同的Layer进行配置,Layer的具体划分如下:

对于MObileViT-XXS,Layer 1~5的详细配置信息如下:
| Layer | Out_channels | MV2_exp | Transformer_channels | ffn_dim | patch_h | patch_w | num_heads |
|---|---|---|---|---|---|---|---|
| Layer 1 | 16 | 2 | None | None | None | None | None |
| Layer 2 | 24 | 2 | None | None | None | None | None |
| Layer 3 | 48 | 2 | 64 | 128 | 2 | 2 | 4 |
| Layer 4 | 64 | 2 | 80 | 160 | 2 | 2 | 4 |
| Layer 5 | 80 | 2 | 96 | 192 | 2 | 2 | 4 |
其中:
- Out_channels: 每个Layer输出特征图的通道数
- MV2_exp:逆残差结构的扩充维度大小
- Transformer_channels: Transformer Encoder模块的输入tokens的向量长度(特征图的通道数)
- ffn_dim: Transformer Block中MLP中间层的节点个数(第一个全连接的输出数,也是第二个全连接层的输入数)
- patch_h, patch_w: patch的大小(patch size) -> 默认大小为2×2
- num_heads: Transformer Encoder模块中的MSA中head的个数
参考
- https://blog.csdn.net/qq_37541097/article/details/126715733
- 【15.1 MobileViT网络讲解】