FCN理论部分

2015 CVPR
论文地址: https://arxiv.org/abs/1411.4038
代码地址 (Caffe): https://github.com/BVLC/caffe/wiki/Model-Zoo#fcn
文章目录
- ABSTRACT
- 1. FCN网络概况
- 2. Convolutionalization, 卷积化
- 3. FCN网络
-
- 3.1 FCN-32s
- 3.2 FCN-16s
- 3.3 FCN-8s
- 4. 损失计算: Cross Entropy Loss
- 参考
ABSTRACT
Convolutional networks are powerful visual models that yield hierarchies of features. We show that convolutional networks by themselves, trained end-to-end, pixels-to-pixels, exceed the state-of-the-art in semantic segmentation. Our key insight is to build “fully convolutional” networks that take input of arbitrary size and produce correspondingly-sized output with efficient inference and learning. We define and detail the space of fully convolutional networks, explain their application to spatially dense prediction tasks, and draw connections to prior models. We adapt contemporary classification networks (AlexNet, the VGG net, and GoogLeNet) into fully convolutional networks and transfer their learned representations by fine-tuning to the segmentation task. We then define a novel architecture that combines semantic information from a deep, coarse layer with appearance information from a shallow, fine layer to produce accurate and detailed segmentations. Our fully convolutional network achieves state-of-the-art segmentation of PASCAL VOC (20% relative improvement to 62.2% mean IU on 2012), NYUDv2, and SIFT Flow, while inference takes one third of a second for a typical image.
卷积网络是产生特征层次结构的强大视觉模型。我们展示了卷积网络本身,经过端到端、像素到像素的训练,超过了语义分割领域的最新技术。我们的主要见解是构建“全卷积”网络,该网络接受任意大小的输入并通过有效的推理和学习产生相应大小的输出。我们定义并详细说明了全卷积网络的空间,解释了它们在空间密集预测任务中的应用,并与先前的模型建立了联系。我们将当代分类网络(AlexNet、VGG 网络和 GoogLeNet)改编为全卷积网络,并通过微调将其学习表示转移到分割任务中。然后,我们定义了一种新颖的架构,它将来自深层、粗略层的语义信息与来自浅层、精细层的外观信息相结合,以产生准确和详细的分割。我们的全卷积网络实现了最先进的 PASCAL VOC 分割(相对于 2012 年的 62.2% 平均 IU 提高了 20%)、NYUDv2 和 SIFT Flow,而典型图像的推理需要三分之一秒。
- FCN网络是首个E2E的针对像素级预测的全卷积网络.
- 全卷积的含义是指将分类网络中的FC层 (全连接层)替换为了卷积层 -> 网络的输入大小可以任意
1. FCN网络概况
FCN网络是语义分割中非常重要的网络, 它的地位相当于目标检测中的Faster R-CNN. 虽然FCN非常简单, 但却非常有效.

可以看到FCN-8与GT相差并不是很大, 说明FCN网络是非常有效的.
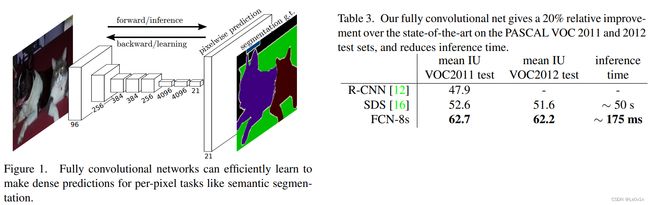
Table 3表明, 在PASCAL VOC测试集上, 与当时的SOTA方法相比, FCN在mean IoU上有20%的提升, 而且在速度上也有巨大的提升.
看左图, 我们发现FCN网络其实是比较简单的, 就是通过卷积, 下采样得到最终的预测特征层 (channel = 21), 因为PASCAL VOC的类别有20, 加上背景就是21. 紧接着对21通道的特征图进行上采样, 就得到和原图同样大小的特征图 (只不过它的channel是21). 这张21通道的特征图上每一个像素的值的范围就为21. 对每个像素的21个值进行softmax处理, 就可以得到该像素针对每一个类别的预测概率, 取概率最大的类别最为该像素的预测类别 -> 这就是FCN的思想.
2. Convolutionalization, 卷积化

在早期的分类网络中经常用使用全连接层 (FC层), 比如AlexNet, VGG -> 网络最后使用3个FC层.
对于FC层而言, 网络的输入大小是固定的, 更改网络输入而不更改FC层就会报错. 对于卷积层而言就不没有这种顾虑, 所以作者想要把FC层使用卷积层来替换, 这就是Convolutionalization.
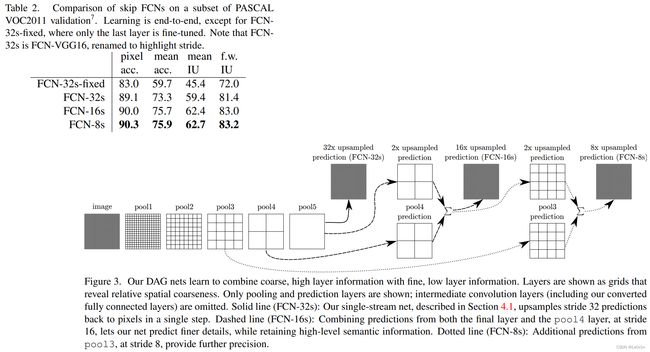
- 32s: 将预测特征图上采样32倍还原回原图大小
- 16s: 将预测特征图上采样16倍还原回原图大小
- 18s: 将预测特征图上采样8倍还原回原图大小
3. FCN网络
3.1 FCN-32s
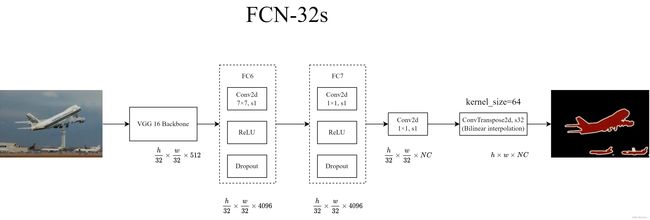
FC6和FC7不会改变特征图的shape, 后面的1×1卷积是为了改变通道数, 注意这里的NC是包含背景的, 如果使用的是PASCAL VOC, 那么NC = 20 + 1 = 21. 接下来再经过一个转置卷积进行32倍的上采样, 恢复到原图的大小.
在原论文的代码中, 使用的双线性插值的参数来初始化转置卷积的初值.
其实这里的转置卷积是被冻结的(不会进行反向传播 -> 不会更新参数), 所以这里完全可以不同转置卷积, 而是使用PyTorch提供的双线性插值方法就可以实现相同的上采样效果.
Q1: 那么为什么要冻结转置卷积的参数呢?
A1: 作者说经过实验发现, 冻结和不冻结, 对于实验结果来说没有什么差别, 所以冻结转置卷积可以加速网络训练(对网络推理没有影响)
Q2: 既然冻不冻结转置卷积效果都一样, 那么为什么要使用转置卷积, 直接使用双线性插值不是更加高效吗?
A2: 这里转置卷积不冻结的效果不行是因为它的上采样率太大了, 因为直接上采样32倍, 有点强人所难了
在对恢复到原图大小的特征图 ( h × w × N C h \times w \times NC h×w×NC)在channel方向进行softmax处理就可以得到每一个像素所属的类别.
虽然FCN网络看起来比较简单, 但是它的效果是非常不错的.
3.2 FCN-16s
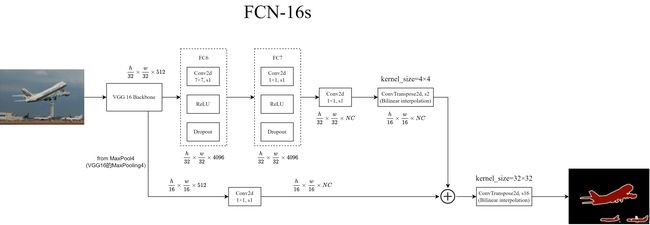
FCN-16s融合了来自MaxPooling4的特征图信息.
3.3 FCN-8s
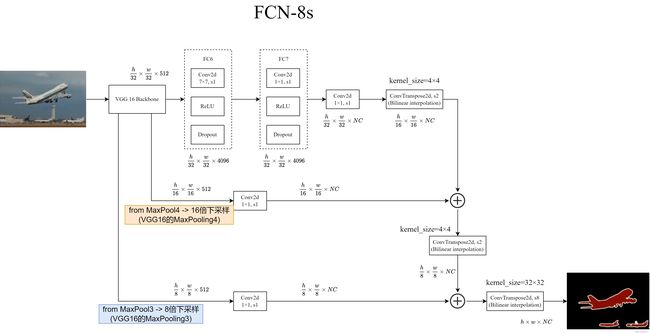
FCN-8s融合了来自MaxPooling4和MaxPooling3的特征图信息.
4. 损失计算: Cross Entropy Loss
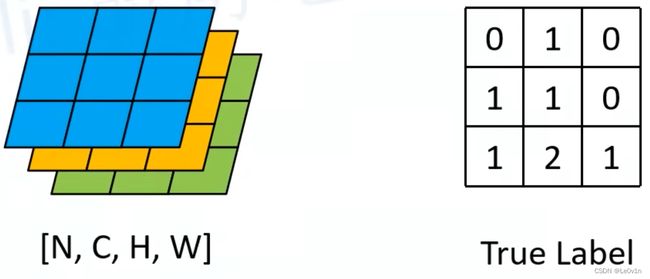
左图为还原为原图大小的预测特征图, 这里为了方便理解, 通道数设置为3 (可以理解为类别数为2+1), H和W均为3.
对预测特征图的每一个pixel在channel方向上进行softmax就可以得到每个像素针对每个类别的概率. 此时就可以跟Ground Truth进行比较, 这里的计算是Cross Entropy Loss, 得到每个像素的Loss后再求平均就可以得到网络最终的Loss.
参考
- https://www.bilibili.com/video/BV1J3411C7zd