【Pytorch Lighting】第 9 章:部署和评分模型
大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
个人主页-Sonhhxg_柒的博客_CSDN博客
欢迎各位→点赞 + 收藏⭐️ + 留言
系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟
文章目录
技术要求
本地部署和评分深度学习模型
pickle (.PKL) 模型文件格式
部署我们的深度学习模型
保存和加载模型检查点
使用 Flask 部署和评分模型
部署和评分可移植模型
ONNX 格式是什么?为什么这有关系?
保存和加载 ONNX 模型
使用 Flask 部署和评分 ONNX 模型
下一步
进一步阅读
概括
在不知情的情况下,您可能已经体验过迄今为止介绍的一些模型。回想一下您的照片应用程序如何自动检测照片集中的面孔或将所有照片与特定朋友组合在一起。这只不过是一个实际的图像识别深度学习模型(卷积神经网络(CNNs)),或者您可能熟悉 Alexa 听您的声音或 Google 在搜索查询时自动完成您的文本。这些是基于 NLP 的深度学习模型,让我们的工作变得更轻松。或者您可能已经看到一些电子购物应用程序或社交媒体网站建议产品的标题;这就是半监督学习的全部荣耀!但是,您如何使用在 Python Jupyter 笔记本中构建的模型并使其可在设备上使用,无论是扬声器、电话、应用程序还是门户网站?如果没有应用程序集成,经过训练的模型仍然是一个没有实际意义的统计对象。
为了让模型在生产环境中被消费和使用,我们必须以某种方式使模型可用,以便它可以与各种最终用户应用程序集成。使用模型的一种流行方式是通过 REST API 端点。创建 API 端点后,可以将模型插入任何应用程序服务器,并为各种终端应用程序或边缘设备提供服务。模型的部署涉及将模型转换为目标文件并稍后加载该目标文件以进行评分。对模型进行评分意味着获得针对给定输入的预测输出。要对模型进行评分,我们应该能够将模型集成到应用程序中,即部署它。在这一章当中,我们将主要介绍如何使用 PyTorch Lightning 框架执行这些活动,以及我们如何轻松地将 PyTorch Lightning 模型投入生产。我们将使用 Flask(一种流行的 Web 开发框架)来创建一个简单的 API 端点以部署模型。
模型消费面临的另一个挑战是训练模型的框架非常多,例如 PyTorch Lightning(当然!)、Caffe 和 TensorFlow。所有这些框架都有自己的文件格式,并且通常需要数据科学家将一个模型的输出与另一个模型的输出集成。在生产环境中部署时,模型可能需要以与框架无关的方式使用。在本章中,我们将对比使用检查点在 PyTorch Lightning 框架中本地部署和评分模型的方法与ONNX(开放神经网络交换)格式,这是一种可移植且可互操作的格式,使深度学习模型能够跨平台传输构架。
我们将在本章中介绍以下主题:
- 本地部署和评分深度学习模型
- 部署和评分可移植模型
技术要求
本章的代码已经在 macOS 上使用 Anaconda 或在 Google Colab 中使用 Python 进行开发和测试。如果您使用的是其他环境,请对您的环境变量进行适当的更改。在运行代码之前,请确保您拥有正确的版本。
在本章中,我们将主要使用以下 Python 模块,并在其版本中提及:
- pytorch-lightning (version 1.5.10)
- torch (version 1.11.0)
- requests (version 2.27.1)
- torchvision (version 0.12.0)
- flask (version 2.0.2)
- pillow (version 8.2.0)
- numpy (version 1.21.3)
- json (version 2.0.9)
- onnxruntime (version 1.10.0))
为了确保这些模块一起工作并且不会不同步,我们使用了特定版本的 torch、torchvision、torchtext、torchaudio 和 PyTorch Lightning 1.5.2。您还可以使用相互兼容的最新版 PyTorch Lightning 和torch compatible。
!pip install torch==1.10.0 torchvision==0.11.1 torchtext==0.11.0 torchaudio==0.10.0 --quiet
!pip install pytorch-lightning==1.5.2 --quiet源数据集链接如下:
- Kaggle – 组织病理学癌症检测数据集:https ://www.kaggle.com/c/histopathologic-cancer-detection
这与我们在第 2 章“使用第一个深度学习模型起步”中使用的数据集相同,用于创建我们的第一个深度学习模型。这是包含癌症肿瘤图像和带有正负识别标记的图像的数据集。它由 327,680 张彩色图像组成,每张图像的大小为 96x96 像素,并从淋巴结扫描中提取。数据是根据 CC0 许可证提供的。原始数据集的原始链接是GitHub - basveeling/pcam: The PatchCamelyon (PCam) deep learning classification benchmark.。但是,在本章中,我们将使用 Kaggle 源,因为它已经从原始数据集中进行了重复数据删除。
本地部署和评分深度学习模型
一旦一个深度学习模型被训练出来,它基本上就包含了关于它的结构的所有信息,也就是它的模型权重、层数等等。让我们以后能够使用这个模型在新数据集的生产环境中,我们需要以合适的格式存储这个模型。转换数据对象的过程转换成可以存储在内存中的格式称为序列化。一旦模型以这种方式序列化,它就是一个自治实体,可以传输或转移到不同的操作系统或不同的部署环境(例如登台或生产)。
但是,一旦将模型转移到生产环境中,我们必须以原始格式重建模型参数和权重。这个消遣的过程从序列化的格式称为反序列化。
还有一些其他方法可以将 ML 模型生产化,但最常用的方法是在训练完成后首先使用“some”格式序列化模型,然后在生产环境中对模型进行反序列化。
序列化的 ML 模型可以保存为各种文件格式,例如 JSON、pickle、ONNX 或预测模型标记语言( PMML )。PMML 可能是最古老的文件在 SPSS 时代用于数据科学的打包软件中用于生产模型的格式。然而,近年来,pickle和 ONNX 等格式得到了更广泛的使用。
我们将在本章中看到其中的一些实际应用。
pickle (.PKL) 模型文件格式
最多当前的培训是使用 Python 完成的环境,pickle是序列化模型的一种简单快捷的格式。它在大多数框架中也原生可用。许多框架(例如scikit-learn )也使用pickle文件格式来默认存储它们的模型。pickle文件格式将模型转换为人类不可读的字节形式,并以其特殊格式以面向对象的方式存储模型。
ML 社区经常调用这个过程使用pickle文件格式进行序列化pickling和反序列化un-pickling。我们可以pickle具有以下数据类型的对象:布尔值、整数、浮点数、复数、字符串、元组、列表、集合、字典、类和函数。Un-pickling 将字节流转换为 Python 层次结构,以便可以使用模型。
泡菜有一些优点;例如,它跟踪以前序列化的对象,在 Python 中有许多内置方法,这使得反序列化变得容易和快速,并且通过单独存储类具有简单的导入功能。
pickle的主要缺点是它是 Python 原生的,不提供跨语言支持。即使是不同版本的 Python(例如 2.x 和 3.x)也可能存在兼容性问题。
部署我们的深度学习模型
我们首先看在第 2 章的深度学习模型中,第一个深度学习模型起步。我们使用 CNN 架构构建了一个图像识别模型。这是一个使用 Adam 优化器的三层卷积 CNN 模型(有五个全连接层)。您可以在 GitHub 页面上找到该模型:https ://github.com/PacktPublishing/Deep-Learning-with-PyTorch-Lightning/tree/main/Chapter02 。
我们使用的数据集是组织病理学癌症检测数据集,该模型可以使用二元分类器预测图像是否包含转移性癌症。
由于我们已经训练了这个模型,下一个合乎逻辑的步骤是了解我们如何将其投入生产并将其集成到应用程序中。
我们将从上次停止的地方开始我们的流程,使用经过训练的模型,看看我们如何部署和评分。
保存和加载模型检查点
什么时候我们训练一个深度学习模型,我们继续更新模型参数在每个时期。换句话说,模型的状态在整个训练过程中不断变化。尽管在训练进行时状态在内存中,但 PyTorch Lightning 框架会定期自动将模型状态保存到检查点。这是一个重要的功能,因为如果由于某种原因被中断,保存的检查点可用于恢复模型训练。此外,在模型完全训练后,我们可以使用其最终检查点来实例化模型的最终状态并使用模型进行评分;这是使用LightningModule类的恰当命名的load_from_checkpoint方法完成的。
默认情况下,PyTorch Lightning 框架会在每个 epoch 之后在当前工作目录的Lightning_logs/version_
首先这里的步骤是重新训练模型通过执行Cancer_Detection.ipynb(可以使用 Google Colab 在Deep-Learning-with-PyTorch-Lightning/Chapter09 at main · PacktPublishing/Deep-Learning-with-PyTorch-Lightning · GitHub找到)。

图 9.1 – CNNImageClassifier 的训练输出
一旦我们的模型经过训练,就可以在您在训练模型时作为参数提供的同一目录下的 Google Drive 中找到它,如下所示:
ckpt_dir = "/content/gdrive/MyDrive/Colab Notebooks/cnn"
ckpt_callback = pl.callbacks.ModelCheckpoint(every_n_epochs=25)
model = CNNImageClassifier()
trainer = pl.Trainer(
default_root_dir=ckpt_dir,
gpus=-1,
# progress_bar_refresh_rate=30,
callbacks=[ckpt_callback],
log_every_n_steps=25,
max_epochs=500)
trainer.fit(model, train_dataloaders=train_dataloader)来自前面的代码,我们可以检查下'/ Colab Notebooks/cnn'目录。我们将下载此文件夹并将其保存在我们的本地目录中,以便在本章中继续使用。
图 9.2 – 检查点目录
一次下载后,我们将它保存在Chapter09目录中并使用正确的检查点路径在后续部分中加载模型;例如:
model = CNNImageClassifier.load_from_checkpoint("./lightning_logs/version_0/checkpoints/epoch=499-step=15499.ckpt")您还可以有以下导入块,它将导入torch.randn模型进入本地目录:
from image_classifier import CNNImageClassifier重要的提示
我们的 CNN 模型在CNNImageClassifier类中定义,该类像往常一样扩展了 PyTorch Lightning 框架提供的LightningModule类。在保存模型时的训练过程中,以及在加载和使用模型时的部署和评分期间,需要可以访问此类定义。因此,我们通过在名为image_classifier.py的自己的文件中定义类定义来使类定义可重用。
使用 Flask 部署和评分模型
烧瓶是一个流行的网络发展框架。在本节中,我们将创建一个简单的 Web 应用程序使用 Flask 使我们的模型可以通过名为predict的 API 访问。API 使用 HTTP POST方法。我们的应用程序有两个主要组件:
- 烧瓶服务器它获取组织病理学扫描的输入图像,转换图像,使用模型对图像进行评分,并返回图像是否包含肿瘤组织的响应。
- 一个 Flask 客户端将组织的组织病理学扫描发送到服务器并显示它从服务器接收到的响应:
1.我们将描述服务器的实现细节。首先,我们导入我们需要的所有工具:
import torch.nn.functional as functional
import torchvision.transforms as transforms
from PIL import Image
from flask import Flask, request, jsonify
from image_classifier import CNNImageClassifier我们使用SoftMax函数torch.nn.功能模块得到概率分布和torchvision.transforms模块来转换图像。PIL代表Python Imaging Library,我们使用它来加载从客户端接收到的图像。当然,如前所述,Flask 框架是我们服务器应用程序的支柱;我们导入request,它提供了一种处理 HTTP 请求的机制,以及jsonify,它提供了发送回客户端的 JSON 表示。ImageClassifier类在image_classifier.py中定义,因此我们也将其导入。
重要的提示
torchvision.transforms中用于调整图像大小和中心裁剪图像的函数需要PIL图像,这就是我们使用PIL模块加载图像的原因。
2.然后,我们加载我们经过全面训练的 CNN 模型:
model = ImageClassifier.load_from_checkpoint("./lightning_logs/version_0/checkpoints/epoch=499-step=15499.ckpt")我们在外面实例化模型API 定义,以便模型将被加载只有一次,而不是每次 API 调用。
3.接下来,我们定义我们的 API 实现使用的辅助函数:
IMAGE_SIZE = 64
def transform_image(img):
transform = transforms.Compose([
transforms.Resize(IMAGE_SIZE),
transforms.CenterCrop(IMAGE_SIZE),
transforms.ToTensor()
])
return transform(img).unsqueeze(0)
def get_prediction(img):
result = model(img)
return functional.softmax(result, dim=1)[:, 1].tolist()[0]transform_image函数将名为img的图像作为输入。它调整图像大小并将其中心裁剪为 32 的大小(使用IMAGE_SIZE变量定义)。然后它将图像转换为张量并在张量上调用unsqueeze(0)以在0位置插入尺寸为1的维度,这是我们的 CNN 模型所要求的。
get_prediction函数将转换后的图像作为输入。它通过模型的输入得到结果,然后在其上调用functional.softmax以获得概率。
4.然后我们实例化 Flask 类并定义一个名为predict的 POST API :
app = Flask(__name__)
@app.route("/predict", methods=["POST"])
def predict():
img_file = request.files['image']
img = Image.open(img_file.stream)
img = transform_image(img)
prediction = get_prediction(img)
if prediction >= 0.5:
cancer_or_not = "cancer"
else:
cancer_or_not = "no_cancer"
return jsonify({'cancer_or_not': cancer_or_not})predict函数具有依次执行以下操作的所有逻辑:从请求中检索图像文件、加载图像、转换图像和获取预测。客户端应该将一个名为image的文件上传到predict API,因此我们在request.files['image']中使用该名称来检索文件。在我们从模型中得到预测后,我们使用0.5作为输出癌症或no_cancer的概率阈值(您可以根据应用需要调整阈值)。jsonify调用负责将字典转换为JSON 表示和发送它在 HTTP 响应中返回给客户端。
5.最后,我们启动我们的 Flask 应用程序:
if __name__ == '__main__':
app.run()经过默认情况下,Flask 服务器启动在5000端口监听发送到 localhost 的请求,如下输出所示:

图 9.3 – 启动 Flask 服务器
6.接下来,我们描述客户端的实现。客户端通过 localhost 的5000端口向服务器发送 HTTP POST请求。我们将在本节的client.ipynb笔记本中工作:
import requests
server_url = 'http://localhost:5000/predict'
path = './00006537328c33e284c973d7b39d340809f7271b.tif'
files = {'image': open(path, 'rb')}
resp = requests.post(server_url, files=files)
print(resp.json())我们定义服务器的 URL使用变量的 POST API名为server_url和使用名为path的变量来定位图像文件。
图 9.4 – 用于对模型进行评分的图像(来自 Kaggle 数据集)
请注意,我们已将这两个图像从数据集中复制到此 GitHub 存储库,因此您无需从 Kaggle 下载完整的数据集。
我们还定义了加载图像文件的文件字典,其中图像作为服务器 API 实现所期望的键名。然后,我们使用 HTTP POST请求将文件发送到服务器并显示 JSON 响应。
以下屏幕截图显示了客户端输出:

图 9.5 – JSON 响应输出
服务器输出显示时间戳当它处理一个 HTTP POST请求时由/predict API 接收,如以及200状态码,表示处理成功:
127.0.0.1 - - [] "POST /predict HTTP/1.1" 200 – 我们可以还可以使用客户端 URL ( cURL ) 命令行工具或其他 APIPostman等测试工具,将请求发送到服务器。以下代码片段显示了curl命令:
curl -F '[email protected]' http://localhost:5000/predict -v这是curl命令的输出:
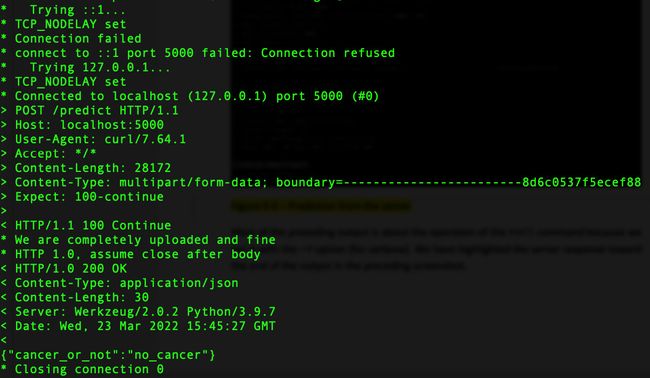
图 9.6 – 来自服务器的预测
大多数前面的输出是关于curl命令的操作是因为我们使用-v选项(用于详细)运行它。我们在前面的屏幕截图中突出显示了服务器对输出末尾的响应。
部署和评分可移植模型
有这么多深度学习可用的框架数据科学家的家门口。PyTorchLightning 框架只是一系列框架中的最新一个,其中包括 TensorFlow、PyTorch,甚至更老的框架,如 Caffe 和 Torch。每个数据科学家(基于他们最初研究的内容或他们的舒适度)通常更喜欢一个框架而不是其他框架。一些框架使用 Python,而其他框架使用 C++。在一个项目中很难标准化一个框架,更不用说一个部门或一个公司。您可能首先在 PyTorch Lightning 中训练模型,然后在一段时间后需要在 Caffe 或 TensorFlow 中刷新它。在不同框架或可移植模型之间转移模型跨框架和语言因此变得必不可少。ONNX 就是这样一种格式为此目的而设计。
在本节中,我们将了解如何使用 ONNX 格式在部署中实现互移植性。
ONNX 格式是什么?为什么这有关系?
ONNX 是一个微软和 Facebook 于 2007 年首次推出的跨行业模型格式。其目标是增强深度学习和与框架无关的硬件并促进互操作性。它已越来越多地被许多框架采用,例如 PyTorch 和 Caffe。以下是 ONNX 格式支持的最新框架的可视化:

图 9.7 – 各种深度学习框架
这使 ONNX 从众多模型格式中脱颖而出的原因在于,它专为深度学习模型而设计(同时也支持传统模型)。它包括一个可扩展计算图模型的定义以及内置运算符。它旨在使数据科学家免于被锁定在任何单一框架中。一旦模型采用 ONNX 格式,它就可以在平台、硬件或设备(GPU 或 CPU)上运行,无论它是否具有 NVIDIA 或 Intel 处理器。
ONNX 因此通过减轻 ML 工程团队的负担来简化整个生产过程,以确保框架支持相应的硬件。ONNX 也非常适用于 Linux、Windows 和 Macintosh 环境,并具有 Python、C 和 Java 的 API,这使其成为跨所有平台的真正通用且统一的模型框架。难怪近几年 ONNX 火了,而且在 PyTorch Lightning 框架中也有内置功能。应该注意的是,虽然许多框架都支持 ONNX,但并非所有框架都支持它(但它正在快速发展)。
保存和加载 ONNX 模型
正如我们前面描述过,PyTorch Lightning 框架使用检查点文件保存模型的状态。检查点文件是一种非常特定于 PyTorch 的加载和部署模型的方式,但它不是部署模型的唯一方式。我们可以使用模型的to_onnx方法将模型导出为 ONNX 格式:
1.首先,我们导入torch模块和image_classifier,其中定义了ImageClassifier类:
import torch
from image_classifier import CNNImageClassifier2.然后,我们加载我们经过全面训练的 CNN 模型:
model = ImageClassifier.load_from_checkpoint("./lightning_logs/version_0/checkpoints/epoch=499-step=15499.ckpt")请确保检查点的路径正确以加载模型。请注意,您的路径将根据检查点文件夹的名称和位置而改变
3.to_onnx方法需要创建 ONNX 文件的路径,在以下代码以及示例名为input_sample的输入。我们的 CNN 模型需要大小为(1, 3, 32, 32)的输入;我们使用torch.randn创建示例:
filepath = "model.onnx"
input_sample = torch.randn((1, 3, 32, 32))
model.to_onnx(filepath, input_sample, export_params=True)这会在当前工作目录中保存一个名为model.onnx的 ONNX 文件。
4.我们使用onnxruntime来加载模型。onnxruntime.InferenceSession加载模型并创建会话对象:
session = onnxruntime.InferenceSession("model.onnx", None)我们将在下一节中描述如何加载 ONNX 模型并将其用于评分。
使用 Flask 部署和评分 ONNX 模型
烧瓶我们用于的客户端-服务器应用程序演示ONNX格式与我们用于检查点格式的格式非常相似:
1.首先,我们导入我们需要的所有工具:
import onnxruntime
import numpy as np
import torchvision.transforms as transforms
from PIL import Image
from flask import Flask, request, jsonify注意我们不需要在这里导入image_classifier因为ImageClassifier类是不再现在需要我们已经将 PyTorch 模型转换为 ONNX 格式。
2.接下来,我们使用onnxruntime通过加载model.onnx来创建会话对象:
session = onnxruntime.InferenceSession("model.onnx", None)
input_name = session.get_inputs()[0].name
output_name = session.get_outputs()[0].name对模型进行评分时需要input_name和output_name。我们实例化会话并在 API 定义之外定义input_name和output_name变量,以便逻辑只执行一次,而不是在每次 API 调用时执行。
3.接下来,我们定义我们的 API 实现使用的辅助函数:
IMAGE_SIZE = 32
def transform_image(img):
transform = transforms.Compose([
transforms.Resize(IMAGE_SIZE),
transforms.CenterCrop(IMAGE_SIZE),
transforms.ToTensor()
])
return transform(img).unsqueeze(0)transform_image函数将名为img的图像作为输入。它调整大小图像并将其中心裁剪为 32 的大小(定义使用IMAGE_SIZE变量)。它然后转换图像到张量并在张量上调用unsqueeze(0)以在0位置插入尺寸为1的尺寸,因为我们的批次中只有一张图像:
def get_prediction(img):
result = session.run([output_name], {input_name: img})
result = np.argmax(np.array(result).squeeze(), axis=0)
return resultget_prediction函数将转换后的图像作为输入。它将输入传递给模型以获得结果。结果是两个类的 logits 数组。为了预测图像的类别,我们需要找到 logits 的最大值及其所属的类别。因此,我们在压缩数组上使用numpy argmax函数来确定最大 logits 的索引。这为我们提供了具有最大 logits 的图像类别,该类别再次存储在结果变量中。
重要的提示
虽然torchvision.transforms是特定于 PyTorch 的,但我们仍然需要在这个 ONNX 示例中继续使用它,因为这就是我们训练模型的方式。我们不能使用其他图像处理库,例如 OpenCV,因为它们有自己的特点,因此使用这些库转换的图像不会与我们在训练期间使用的完全相同。
此外,虽然ONNX 模型需要一个 NumPy 数组作为输入,我们使用transforms.ToTensor()因为这是我们在训练。参考文档也就是说,“将 [0, 255] 范围内的 PIL 图像或 numpy.ndarray (H x W x C) 转换为 [0.0, 1.0] 范围内形状 (C x H x W) 的 torch.FloatTensor。 "
如前所述,torchvision.transforms中用于调整图像大小和中心裁剪图像的函数需要一个PIL图像,这就是我们使用PIL模块加载图像的原因,如下所述。
4.然后,我们实例化 Flask 类并定义一个名为predict的 POST API :
app = Flask(__name__)
@app.route("/predict", methods=["POST"])
def predict():
img_file = request.files['image']
img = Image.open(img_file.stream)
img = transform_image(img)
prediction = get_prediction(img.numpy())
if prediction == 0:
cancer_or_not = "no_cancer"
elif prediction == 1:
cancer_or_not = "cancer"
return jsonify({'cancer_or_not': cancer_or_not})predict函数具有按顺序执行以下操作的所有逻辑:retrieve请求中的图像文件,加载图像,变换图像,并得到预测。这客户端应该将名为image的文件上传到predict API,因此我们在request.files['image']中使用该名称来检索文件。
我们使用img.numpy()将transform_image函数返回的张量转换为 NumPy 数组。
在我们从返回图像类别的模型中得到预测后,我们定义规则,如果预测为0,则属于no_cancer类,如果为1,则属于cancer类。jsonify调用负责将字典转换为 JSON 表示形式并在 HTTP 响应中将其发送回客户端。
5.最后,我们启动我们的 Flask 应用程序:
if __name__ == '__main__':
app.run()如上例所述,Flask 服务器默认在5000端口开始监听发送到 localhost 的请求,如下输出所示:

图 9.8 – Flask 服务器准备就绪
重要的提示
确保终止检查点服务器在您启动之前的上一个示例中ONNX 服务器;否则,你会得到一个错误上面写着诸如“地址已在使用”之类的内容,因为该服务器已经在侦听5000端口,您正尝试在该端口启动新服务器。
客户端代码完全相同(client.ipynb),因为客户端不关心服务器的内部实现——无论服务器使用本地基于检查点的模型实例还是基于 ONNX 的模型实例进行评分。
以下屏幕截图显示了客户端输出:

图 9.9 – 模型预测
如同我们在前面的例子中描述的,服务器输出显示时间戳当它处理一个 HTTP POST请求时/predict API接收到的,以及表示处理成功的200状态码:
127.0.0.1 - - [] "POST /predict HTTP/1.1" 200 – 当然,我们也可以使用 cURL 命令行工具将请求发送到我们的 ONNX 服务器:
curl -X POST -F '[email protected]' http://localhost:5000/predict -v下一步
现在我们已经了解了如何部署和评分深度学习模型,请随意探索有时伴随模型使用的其他挑战:
- 我们如何扩展大规模工作负载的评分,例如每秒提供 100 万个预测?
- 在一定的往返时间内,我们如何管理评分吞吐量的响应时间?例如,请求进入和服务分数之间的往返不能超过 20 毫秒。您还可以考虑在部署时优化此类 DL 模型的方法,例如批量推理和量化。
- Heroku 是一个流行的部署选项。您可以在 Heroku 上免费部署一个简单的 ONNX 模型。您可以在没有前端的情况下部署模型,也可以使用简单的前端来上传文件。您可以更进一步,使用生产服务器,例如 Uvicorn、Gunicorn 或 Waitress,并尝试部署模型。
- 也可以将模型保存为.pt文件并使用 JIT 编写模型脚本,然后执行推理。您可以尝试此选项并比较性能。
这样的部署挑战通常由机器学习工程团队在云工程师的帮助下处理。此过程通常还涉及创建可以自动扩展以解决传入工作负载的复制系统。
进一步阅读
以下是PyTorch Lightning 网站的Inference in Production页面的链接: https ://pytorch-lightning.readthedocs.io/en/latest/common/production_inference.html 。
要了解有关 ONNX 和 ONNX 运行时的更多信息,请访问他们的网站:https ://onnx.ai和https://onnxruntime.ai。
概括
数据科学家通常在模型部署和评分方面发挥支持作用。但是,在某些公司(或可能没有配备齐全的工程或 ML-Ops 团队的小型数据科学项目)中,可能会要求数据科学家执行此类任务。本章应该有助于您为进行测试和实验部署以及与最终用户应用程序的集成做好准备。
我们在本章中看到了 PyTorch Lightning 如何在 Flask 应用程序的帮助下通过 REST API 端点轻松部署和评分以供使用。我们已经看到了如何通过检查点文件或通过诸如 ONNX 之类的可移植文件格式本地执行此操作。我们已经看到如何使用不同的文件格式(例如 ONNX)来帮助现实生产环境中的部署过程,其中多个团队可能使用不同的框架来训练模型。
回顾过去,我们从介绍我们的第一个深度学习模型开始我们的旅程,然后依次研究越来越多的高级算法来完成各种任务,例如 GAN、半监督学习和自我监督学习。
我们还看到了如何使用预先训练的模型或开箱即用的模型(例如 Flash)来实现训练大型深度学习模型的一些目标。
在下一章中,我们将汇编一些重要的技巧,这些技巧将有助于在您练习深度学习之旅时进行故障排除,并指导您作为一个现成的估算者来扩展您的模型以适应大量工作负载。