【Pytorch Lighting】第 10 章:扩展和管理培训
大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
个人主页-Sonhhxg_柒的博客_CSDN博客
欢迎各位→点赞 + 收藏⭐️ + 留言
系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟
文章目录
技术要求
管理培训
保存模型超参数
解决方案
高效调试
解决方案
使用 TensorBoard 监控训练损失
解决方案
扩大培训
使用多个工人加速模型训练
解决方案
GPU/TPU 训练
解决方案
混合精度训练/16位训练
解决方案
控制训练
使用云时保存模型检查点
解决方案
更改检查点功能的默认行为
解决方案
从保存的检查点恢复训练
解决方案
使用云时保存下载和组装的数据
解决方案
进一步阅读
概括
到目前为止,我们已经在深度学习( DL ) 领域踏上了一段激动人心的旅程。我们已经学会了如何识别图像,如何创建新图像或生成新文本,以及如何在没有完全标记集的情况下训练机器。一个公开的秘密是,为 DL 模型获得良好的结果需要大量的计算能力,通常需要图形处理单元( GPU ) 的帮助。自从数据科学家不得不手动将训练分配到 GPU 的每个节点时,我们已经走了很长一段路。PyTorch Lightning 混淆了与管理底层硬件或将训练下推到 GPU 相关的大部分复杂性。
在前面的章节中,我们已经通过蛮力推倒了训练。但是,当您必须处理大规模数据的大量培训工作时,这样做是不切实际的。在本章中,我们将对大规模训练模型和管理训练所面临的挑战进行细致入微的看法。我们将描述一些常见的陷阱以及如何避免它们的提示和技巧。我们还将描述如何设置您的实验,如何使模型训练对底层硬件中的问题具有弹性,以及如何利用硬件来提高训练效率等。将本章视为您更复杂的培训需求的现成估算器。
在本章中,我们将介绍以下主题以帮助训练 DL 模型:
- 管理培训
- 扩大培训
- 控制训练
技术要求
在本章中,我们将使用 PyTorch Lightning 1.5.2 版本。请使用以下命令安装此版本
管理培训
在本节中,我们将介绍您在使用过程中可能遇到的一些常见挑战管理 DL 模型的训练。这包括在保存模型参数和高效调试模型逻辑方面进行故障排除。
保存模型超参数
有通常需要保存模型的超参数。一些原因是可重复性、一致性以及某些模型的网络架构对超参数极为敏感。
在不止一种情况下,您可能会发现自己无法从检查点加载模型。LightningModule类的load_from_checkpoint方法失败并出现错误。
解决方案
检查点只不过是模型的保存状态。检查点包含模型使用的所有参数的精确值。但是,默认情况下,传递给__init__模型的超参数不会保存在检查点中。在LightningModule类的__init__中调用self.save_hyperparameters 也会将参数的名称和值保存在检查点中。
检查您是否将其他参数(例如学习率)传递给LightningModule类的__init__模型。如果是,那么您需要确保这些参数的值也被捕获在您的检查点中。为此,请在LightningModule类的__init__中调用self.save_hyperparameters 。
以下代码片段显示了我们如何在实现的卷积神经网络-循环神经网络( CNN-RNN ) 级联模型中使用self.save_hyperparameters作为第 7 章中的 CNN -Long Short-Term Memory ( LSTM ) 架构:
def __init__(self, cnn_embdng_sz, lstm_embdng_sz, lstm_hidden_lyr_sz, lstm_vocab_sz, lstm_num_lyrs, max_seq_len=20):
super(HybridModel, self).__init__()
"""CNN"""
resnet = models.resnet152(pretrained=False)
module_list = list(resnet.children())[:-1]
self.cnn_resnet = nn.Sequential(*module_list)
self.cnn_linear = nn.Linear(resnet.fc.in_features,
cnn_embdng_sz)
self.cnn_batch_norm = nn.BatchNorm1d(cnn_embdng_sz,
momentum=0.01)
"""LSTM"""
self.lstm_embdng_lyr = nn.Embedding(lstm_vocab_sz,
lstm_embdng_sz)
self.lstm_lyr = nn.LSTM(lstm_embdng_sz, lstm_hidden_lyr_sz,
lstm_num_lyrs, batch_first=True)
self.lstm_linear = nn.Linear(lstm_hidden_lyr_sz,
lstm_vocab_sz)
self.max_seq_len = max_seq_len
self.save_hyperparameters()在前面代码片段,__init__中的最后一行调用self.save_hyperparameters。
高效调试
实验使用和调试用 PyTorch 编写的 DL 模型可能是一个非常耗时的过程,原因如下:
- 使用大量数据训练 DL 模型。培训过程可能需要数小时或数天才能运行,甚至在 GPU 或张量处理单元( TPU )等高性能硬件上。使用多批数据和时期迭代地执行训练。这种笨拙的训练-验证-测试循环可能会导致编程逻辑中的错误出现延迟。
- Python 不是编译语言;它是一种解释性语言。诸如拼写错误和缺少导入语句之类的语法错误不会像在 C 和 C++ 等编译语言中那样事先被捕获。只有在运行该特定代码行时才会出现此类错误Python 虚拟机。
PyTorch 闪电可以吗有助于快速发现编程错误,以节省纠正错误后重复重新运行所浪费的时间?
解决方案
PyTorch Lightning 框架提供了不同的参数,可以在模型训练期间传递给Trainer模块,以减少调试时间。这里是其中的一些:
- limit_train_batches:这个可以将参数传递给Trainer以控制要用于训练时期的数据子集。以下代码片段提供了一个示例:
import pytorch_lightning as pl ... # use only 10% of the training data for each epoch trainer = pl.Trainer(limit_train_batches=0.1) # use only 10 batches per epoch trainer = pl.Trainer(limit_train_batches=10)
此设置对于调试在一个纪元之后发生的一些问题很有用。它节省了时间,因为它加快了一个 epoch 的运行时间。
请注意,有类似的参数,分别命名为limit_test_batches和limit_val_batches用于测试和验证数据。
- fast_dev_run:这个参数限制训练、验证和测试批次以快速检查错误。与limit_train / val / test_batches参数不同,该参数禁用检查点、回调、记录器等,并且只运行一个 epoch。所以,顾名思义,这个参数应该只在用于快速调试的开发。您可以在以下代码片段中看到它的实际效果:
import pytorch_lightning as pl ... # runs 5 train, val, test batches and then terminate trainer = pl.Trainer(fast_dev_run=5) # run 1 train, val, test batch and terminate trainer = pl.Trainer(fast_dev_run=True) - max_epochs:这个参数限制 epoch 的数量,一旦达到max_epochs参数的数量,训练就会终止。
以下代码片段显示了我们在训练 CNN 模型时如何使用此参数以将训练限制为 100 个 epoch:
trainer = pl.Trainer(max_epochs=100, gpus=-1)使用 TensorBoard 监控训练损失
这是重要的是要确保在整个训练过程中训练损失在不收敛的情况下收敛陷入局部最小值。如果不收敛,则需要调整学习率、批量大小或优化器等参数并重新开始训练过程。我们如何可视化损失曲线来监控损失是否在不断减少?
解决方案
默认情况下,PyTorch Lightning 支持TensorBoard框架,该框架提供跟踪和可视化指标,例如训练损失。您可以通过调用LightningModule代码中的log()方法来保存在每个批次和 epoch 执行期间计算的损失。例如,下面的代码片段展示了我们如何在第 7 章,半监督学习中在model.py 中定义的HybridModel类的training_step方法的定义中注册损失:
def training_step(self, batch, batch_idx):
loss_criterion = nn.CrossEntropyLoss()
imgs, caps, lens = batch
outputs = self(imgs, caps, lens)
targets = pk_pdd_seq(caps, lens, batch_first=True)[0]
loss = loss_criterion(outputs, targets)
self.log('train_loss', loss, on_epoch=True)
return loss这调用self.log 会在内部保存损失值,为此,如前所述,PyTorch Lightning 默认使用 TensorBoard 框架。我们还为这个损失指标命名:train_loss。on_epoch =True参数指示 PyTorch Lightning 框架不仅记录每个批次的损失,还记录每个时期的损失。
我们已经描述了对前面损失度量的跟踪。接下来,我们描述损失度量的可视化。在本节的其余部分,我们将使用tensorboard.ipynb笔记本。从 notebook 中可以看出,我们只需将 TensorBoard 指向模型训练期间 PyTorch Lightning 框架创建的 Lightning_logs 目录的位置。因此,从Lightning_logs的父目录启动tensorboard.ipynb笔记本。这是执行可视化技巧的代码:
%load_ext tensorboard
%tensorboard --logdir "./lightning_logs"在前面的代码片段中,我们首先加载tensorboard扩展,然后使用--logdir命令行参数向其提供Lightning_logs目录的位置。
执行时在笔记本单元格中,TensorBoard 框架在单元格下方启动,如以下屏幕截图所示:

图 10.1 – 用于可视化损失的 TensorBoard
重要的提示
TensorBoard 框架可能需要几秒钟才能显示出来,特别是如果您在模型训练期间已经运行了数千个 epoch。TensorBoard 加载所有指标数据需要更多时间。
未来回到前面代码片段中training_step方法定义中调用self.log时用于损失度量的名称train_loss ,TensorBoard 显示两个损失图表。向下滚动到 TensorBoard 中的epoch和hp_metric图表下方,然后展开以下屏幕截图所示的train_loss_epoch和train_loss_step选项卡:
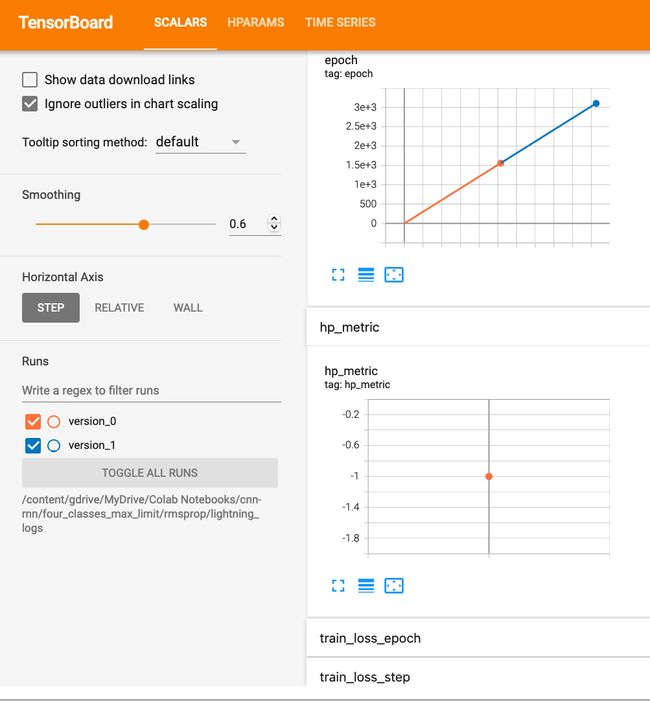
图 10.2 – TensorBoard 损失图表选项卡
笔记PyTorch 闪电框架会自动将_epoch和_step附加到我们在代码中提供的名称train_loss中,以区分 epoch 指标和 step 指标。这是因为我们要求框架记录每个 epoch 的损失以及通过将on_epoch=True参数传递给self.log前面代码片段中的每一步。
以下屏幕截图显示了两个损失图表:
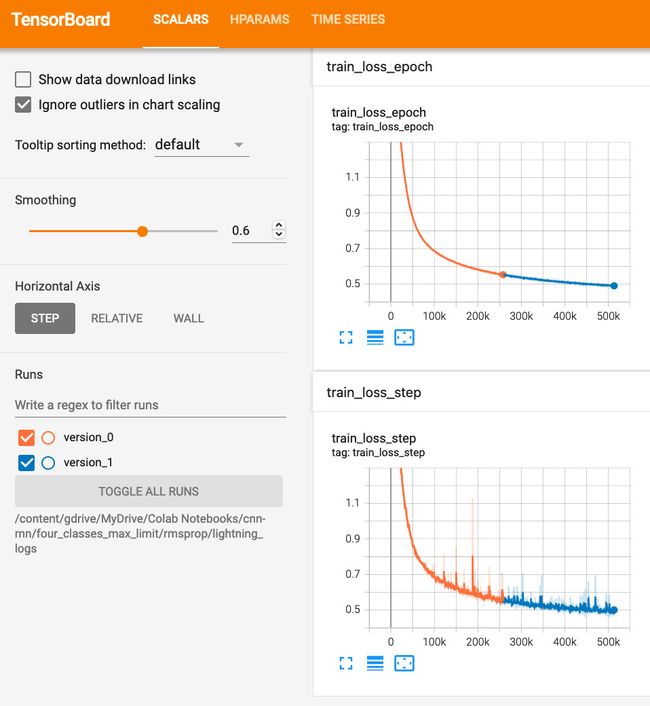
图 10.3 – TensorBoard 损失图表
最后,注意不同的颜色会自动用于不同的版本。从上图左下角可以看出,version_0 使用了橙色,version_1使用了蓝色。如果您的训练过程跨越多个版本,那么您可以选择显示这些版本中的一个或多个版本的指标,方法是选中这些版本号旁边的复选框或单选按钮。为了例如,以下屏幕截图中的训练共有 8 个版本。我们对版本 0 到 5 使用了0.001的学习率值,但是由于训练没有收敛,然后我们将学习率值降低到0.0003并重新开始训练,结果创建了后续版本。我们在以下屏幕截图中仅选择了 6、7 和 8 来可视化学习率值为0.0003的损失曲线:
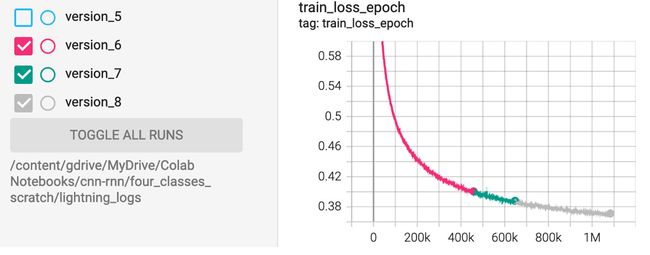
图 10.4 – TensorBoard 选择版本
扩大培训
扩大训练要求我们加快大量数据的训练过程,更好地利用 GPU 和 TPU。在本节中,我们将介绍一些有关如何有效使用 PyTorch Lightning 中的规定来完成此任务的技巧。
使用多个工人加速模型训练
怎么可能PyTorch Lightning 框架有助于加快模型训练?要知道的一个有用参数是num_workers,它来自 PyTorch,PyTorch Lightning 在此基础上构建,提供有关工人数量的建议。
解决方案
PyTorch Lightning 框架提供了许多用于加速模型训练的规定,例如:
- 您可以为num_workers参数设置一个非零值以加快模型训练。以下代码片段提供了一个示例:
import torch.utils.data as data ... dataloader = data.DataLoader(num_workers=4, ...)
最佳num_workers值取决于批量大小和您的配置机器。一般准则是从等于计算机上中央处理单元( CPU ) 核心数的数量开始。正如在https://pytorch-lightning.readthedocs.io/en/stable/guides/speed.html#num-workers找到的文档中提到的,“最好的办法是慢慢增加 num_workers ,一旦看到就停止你的训练速度没有再提高。 ”
请注意,PyTorch Lightning 提供了有关num_workers的建议,如下面的输出截图所示,当模型训练在DataLoader上使用num_workers=1参数运行时发出的输出:

图 10.5 – 使用 num_workers=1 参数运行的模型训练输出
如前面屏幕截图中突出显示的文本所示,框架会发出警告。以下是前面屏幕截图中显示的用户警告旁边的全文:
"UserWarning: The dataloader, train dataloader, does not have many workers which may be a bottleneck. Consider increasing the value of the `num_workers` argument` (try 4 which is the number of cpus on this machine) in the `DataLoader` init to improve performance."注意Jupyter 笔记本环境Google Colaboratory ( Google Colab )、Amazon SageMaker 和 IBM Watson Studio等允许您为 Jupyter notebook 设置底层硬件的配置。
例如,在 Google Colab 中,在Change Runtime Type设置中,您可以将Runtime shape字段设置为High-RAM而不是Standard,以便您可以将num_workers参数的值增加到DataLoader。
GPU/TPU 训练
一个 CPU 是通常不足以达到模型训练所需的速度。使用 GPU 是一种选择。如果您使用的是 Google Cloud 或 Colab 等基于笔记本的服务,那么 TPU 也是一种选择。这是专为 DL 模型设计的处理单元。现在让我们看看 PyTorch Lightning 框架如何帮助利用 GPU/TPU 硬件。
解决方案
如果您运行 Jupyter notebook 的机器的底层硬件有 GPU/TPU,那么您应该使用它来加速训练。PyTorch Lightning 框架通过简单更改作为参数传递给Trainer的标志,可以非常轻松地切换到 GPU/TPU 。以下代码片段中提供了一个示例:
import pytorch_lightning as pl
...
# use 2 gpus
trainer = pl.Trainer(gpus=2)
# use all gpus
trainer = pl.Trainer(gpus=-1)您可以使用传递给Trainer的gpus参数来指定 GPU 的数量。你可以将其设置为-1以指定您要使用所有 GPU。以下代码片段显示了我们在训练 CNN 模型时如何使用此参数:
trainer = pl.Trainer(max_epochs=100, gpus=-1)对于 TPU 训练,请使用Trainer的tpu_cores参数,如下所示:
# use 1 TPU core
trainer = Trainer(tpu_cores=1)
# use 4 TPU cores
trainer = Trainer(tpu_cores=4)请注意,在 Google Colab 中,您可以更改运行时类型以将硬件加速器设置为GPU或TPU而不是None。
以下屏幕截图显示了Google Colab 中的笔记本设置弹出对话框:

图 10.6 – Google Colab 中的笔记本设置
这将帮助您在 Google Colab 上启用 GPU 服务。
混合精度训练/16位训练
深度学习模型例如 CNN 将高维对象(例如图像)转换为低维对象(例如张量)。换句话说,我们不需要精确的计算,如果我们可以牺牲一点精度,那么我们可以在速度上得到很大的提升。TPU 提高性能的方法之一就是使用这个概念。但是,对于非 TPU 环境,此功能不可用。
利用更好的正如我们在上一节中讨论的那样,GPU 或多 CPU 等处理单元显着提高了训练性能。但是我们还可以在框架级别启用较低的精度吗?PyTorch Lightning 允许您通过简单地将名为precision的附加参数传递给Trainer模块来使用混合精度训练。
解决方案
混合精度训练使用两种不同位数的浮点数——较高的 32 位和较低的 16 位。这减少了模型训练期间的内存占用,进而提高了训练性能。
PyTorch Lightning 支持 CPU 和 GPU 以及 TPU 的混合精度训练。以下示例显示了如何将精度选项与gpus选项一起使用:
import pytorch_lightning as pl
...
trainer = pl.Trainer(gpus=-1, precision=16)这使得模型可以更快地训练,并且性能提升可以与将 epoch 训练时间减少一半一样大。在第 7 章中,我们看到通过使用 16 位精度,我们将 CNN 模型的训练速度提高了大约 30-40%。
控制训练
有通常需要有一个审计、平衡和控制机制在训练过程中。想象一下,您正在训练一个模型 1,000 个 epoch,而网络故障会在 500 个 epoch 后导致中断。如何从某个点恢复训练,同时确保不会丢失所有进度,或从云环境中保存模型检查点?让我们看看如何应对这些通常是工程师生活中不可或缺的实际挑战。
使用云时保存模型检查点
笔记本托管在 Google Colab 等云环境中具有资源限制和空闲超时期限。如果在模型开发过程中超出这些限制,则笔记本电脑将被停用。由于云环境固有的弹性(这是云的价值主张之一),当笔记本停用时,底层计算和存储资源将被停用。如果您刷新已停用笔记本的浏览器窗口,笔记本通常会使用全新的计算/存储资源重新启动。
在云环境中托管的笔记本由于资源限制或空闲超时时间而停用后,将无法再访问检查点目录和文件。解决此问题的一种方法是使用已安装的驱动器。
解决方案
正如我们之前提到的,PyTorch Lightning 会自动将最后一个训练 epoch 的状态保存在一个检查点中,该检查点默认保存在当前工作目录中。但是,启动笔记本的机器的当前工作目录不是在云笔记本中保存检查点的好选择,因为它们的底层基础设施具有瞬态性,如上一节所述。在这样的环境中,云提供商通常会提供可以从笔记本电脑访问的持久存储。
接下来,我们将描述如何在 Google Colab 中使用 Google Drive 持久存储,它只不过是一个云笔记本。我们将按以下步骤进行:
- 首先,我们将 Google Drive 导入到我们的 notebook 中,如下:
from google.colab import drive drive.mount('/content/gdrive') - 然后,我们可以使用以/content/gdrive/MyDrive开头的路径来引用 Google Drive 中的目录。请注意,在执行前面的drive.mount()语句期间,将提示您进行身份验证,如以下屏幕截图所示:

图 10.7 – 输入授权码
- 单击连接到 Google Drive 按钮。在下一个弹出窗口中选择您的帐户。然后,在下一个弹出窗口中单击允许,如下所示:。

图 10.8 – 允许访问 Google Drive
- 然后,使用PyTorch Lightning Trainer模块的default_root_dir参数将检查点路径更改为您的 Google Drive。例如,以下代码将检查点存储在 Google Drive 的Colab Notebooks/cnn目录中。它的完整路径是/content/gdrive/MyDrive/Colab Notebooks/cnn,如以下代码片段所示:
import pytorch_lightning as pl ... ckpt_dir = "/content/gdrive/MyDrive/Colab Notebooks/cnn" trainer = pl.Trainer(default_root_dir=ckpt_dir, max_epochs=100)
在/content/gdrive/MyDrive/Colab Notebooks/cnn目录中,检查点存储在Lightning_logs/version_
更改检查点功能的默认行为
你怎么去关于更改 PyTorch Lightning 框架的检查点功能的默认行为?
解决方案
PyTorch Lightning 框架默认自动将最后一个训练 epoch 的状态保存到当前工作目录。为了让用户改变这种默认行为,框架在 pytorch_lightning.callbacks 中提供了一个名为ModelCheckpoint的类。我们将在本节中描述一些此类自定义的示例,如下所示:
- 首先,您可以选择保存每第n个 epoch 的状态,而不是保存最后一个训练 epoch 的状态,如下所示:
import pytorch_lightning as pl ... ckpt_callback = pl .callbacks.ModelCheckpoint(every_n_epochs=10) trainer = pl.Trainer(callbacks=[ckpt_callback], max_epochs=100) - 传递给ModelCheckpoint的every_n_epochs参数指定保存检查点的周期。我们将值10用于前面代码片段中的every_n_epochs参数。然后使用回调数组参数将ModelCheckpoint传递给Trainer 。前面的代码会将检查点保存在当前工作目录中,但当然,您可以使用传递给Trainer的default_root_dir参数更改该位置,如下所示:
import pytorch_lightning as pl ... ckpt_dir = "/content/gdrive/MyDrive/Colab Notebooks/cnn" ckpt_callback = pl .callbacks.ModelCheckpoint(every_n_epochs=10) trainer = pl.Trainer(default_root_dir=ckpt_dir, callbacks=[ckpt_callback], max_epochs=100) - 这个定制只存储一个 10 倍数的 epoch 之后的最新检查点——也就是说,它在第 10个epoch 之后保存一个检查点,然后用第 20个epoch 之后的检查点替换它,然后在第 30个epoch之后替换它, 等等。
- 但是,如果您想保存五个最近的检查点而不是一个,或者如果您想保存所有检查点怎么办?
- 您可能希望保存多个检查点,以便以后对检查点执行一些比较分析。您可以使用 ModelCheckpoint 的save_top_k参数来完成此操作。框架默认只存储最新的检查点,因为save_top_k参数的默认值为1。
- 您可以将save_top_k设置为-1以保存所有检查点。当它与every_n_epochs=10参数一起使用时,将保存所有 10 的倍数的检查点,如下所示:
import pytorch_lightning as pl ... ckpt_dir = "/content/gdrive/MyDrive/Colab Notebooks/cnn" ckpt_callback = pl .callbacks.ModelCheckpoint(every_n_epochs=10, save_top_k=-1) trainer = pl.Trainer(default_root_dir=ckpt_dir, callbacks=[ckpt_callback], max_epochs=100)
以下屏幕截图显示所有 10 的倍数的检查点均已保存到 Google 云端硬盘。请注意,epoch 编号从0开始,因此以epoch=9开头的检查点用于第 10个epoch,以epoch=19开头的检查点用于第 20个epoch,依此类推:

图 10.9 – 10 的倍数的所有检查点
请注意,您还可以使用ModelCheckpoint对象的best_model_path和best_model_score属性来访问最佳模型检查点。
从保存的检查点恢复训练
唠叨之一DL 模型的一个方面是它们需要很长时间(通常是几天)才能完成训练过程。在此期间,如何查看任何中间结果?或者,如果训练过程因失败而中断,如何从保存的检查点恢复训练?
解决方案
如本章所述,托管在 Google Colab 等云环境中的笔记本具有资源限制和空闲超时期限。如果在模型开发过程中超过了这些限制,则 notebook 将被停用,其底层文件系统将无法访问。在这种情况下,您应该使用云提供商的持久存储来保存检查点;例如,使用 Google Colab 时使用 Google Drive 存储检查点。
但即便如此,训练也可能由于超时或由于底层基础设施中的某些问题、程序逻辑中的问题等而中断。在这种情况下,PyTorch Lightning 框架允许您使用Trainer的ckpt_path参数恢复训练。这对于 DL 算法很重要,因为它们通常需要对大量数据进行长时间的训练,因此有助于避免浪费时间重新训练模型。
以下代码使用保存的检查点来恢复模型训练:
import pytorch_lightning as pl
...
ckpt_dir = "/content/gdrive/MyDrive/Colab Notebooks/cnn"
latest_ckpt = "/content/gdrive/MyDrive/Colab Notebooks/cnn/lightning_logs/version_4/checkpoints/epoch=39-step=1279.ckpt"
ckpt_callback = pl .callbacks.ModelCheckpoint(every_n_epochs=10, save_top_k=-1)
trainer = pl.Trainer(default_root_dir=ckpt_dir, callbacks=[ckpt_callback], ckpt_path=latest_ckpt, max_epochs=100)这个代码片段使用Trainer的default_root_dir参数指定 Google Drive 中保存检查点的位置。此外,ModelCheckpoint类被赋予every_n_epochs和save_top_k参数,以便保存对应于所有 10 倍数的 epoch 的检查点。最后但同样重要的是,代码使用epoch=39-step=1279.ckpt(对应于第 40个epoch,因为 epoch 编号从 0 开始)作为Trainer的ckpt_path参数的值。
以下屏幕截图显示了 PyTorch Lightning 框架如何从检查点文件恢复状态(如输出的第一行中突出显示的那样),以便可以在第 40个epoch 之后恢复训练:
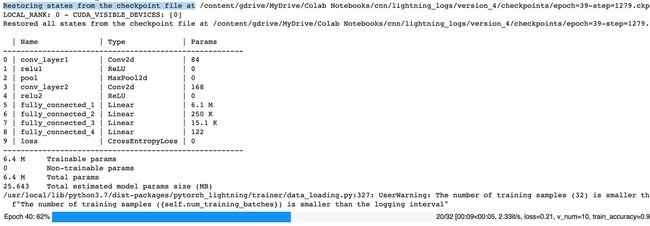
图 10.10 – 恢复训练
如进度条开始前屏幕截图的最后一行所示,训练在第 40 个 epoch 恢复(同样,实际上是第 41 个epoch,因为 epoch 编号从 0 开始)。
注意我们用于恢复训练的检查点的位置:lightning_logs/version_4/checkpoints/epoch=39-step=1279.ckpt。它是version_4。因此,后续检查点 50 到 100 将保存在version_5目录下,如下图所示:

图 10.11 – 保存在 version_5 目录下的检查点 50 到 100
这有助于我们跟踪所有保存的检查点作为故障安全机制,并使用不同时间范围内的模型来比较模型训练结果。
使用云时保存下载和组装的数据
这用于训练 DL 模型的数据的下载和组装通常是一次性处理步骤。诚然,有时您可能会意识到您需要进一步清理已处理的数据或获取更多数据以创建更好的模型,但数据不会超过某个点而发生变化——它必须被冻结。
另一方面,模型训练可能需要几天甚至几周才能完成。它涉及对数据进行数千或数十万次迭代,调整模型的超参数,并重新启动或恢复训练以通过避免局部最小值来实现收敛。我们如何确保不会不必要地重做数据处理步骤?我们如何在整个训练过程中提供相同的处理数据副本?
解决方案
您可以捆绑处理过的数据并将其保存,然后在整个模型训练过程中取消捆绑并使用数据。这在云笔记本环境中尤为重要,因为其底层基础架构具有瞬态特性,如前一节所述。让我们通过一个例子来学习;以下是如何修改我们在第 7 章,半监督学习中使用的笔记本:
- 在第 7 章“半监督学习”中,我们使用了三种不同的 notebook 进行数据处理:download_data.ipynb、filter_data.ipynb和process_data.ipynb。第二个和第三个笔记本从前一个笔记本的结束点开始和拾取。他们假设上一个笔记本中的数据位于当前工作目录中。换句话说,当前工作目录充当三个笔记本之间的公共上下文,如果笔记本是在云环境中启动的,情况肯定不是这样。这三款笔记本电脑都将分配有自己独立的计算和存储基础设施。以下要点描述了如何解决此问题。
- 您可以将三个笔记本组合在一起。从download_data.ipynb笔记本的内容开始,然后附加来自filter_data.ipynb笔记本的单元格,然后附加来自process_data.ipynb笔记本的单元格。让我们将这个合成的笔记本简称为data.ipynb;它会下载 COCO 2017 数据,对其进行过滤、调整图像大小并创建词汇表。
- 将以下代码单元附加到data.ipynb笔记本以捆绑处理后的数据:
!tar cvf coco_data_filtered.tar coco_data !gzip coco_data_filtered.tar
前面的代码创建了一个名为coco_data_filtered.tar.gz的包并将其存储在当前工作目录中。
- 最后,将以下代码单元附加到data.ipynb笔记本,以将coco_data_filtered.tar.gz包存储在运行data.ipynb笔记本的云基础架构之外的持久存储中。该代码使用已安装的 Google Drive 来保存数据包,但您可以改为使用云提供商支持的任何其他持久性存储:
from google.colab import drive drive.mount('/content/gdrive') !cp ./coco_data_filtered.tar.gz /content/gdrive/MyDrive/Colab\ Notebooks/cnn-rnn
先上代码将 Google Drive 挂载到/content/gdrive。然后,它将数据包保存在Colab\ Notebooks文件夹内名为cnn-rnn的文件夹中。
重要的提示
在执行前面的drive.mount()语句期间,系统会提示您通过 Google 进行身份验证并输入授权码,如本章前一节所述。
进一步阅读
我们已经提到了一些我们发现对常见故障排除有用的关键提示和技巧。您可以随时参考加速模型训练文档以获取有关如何加速训练或其他主题的更多详细信息。这是文档的链接:https ://pytorch-lightning.readthedocs.io/en/latest/guides/speed.html 。
我们已经描述了 PyTorch Lightning 如何默认支持 TensorBoard 日志框架。这是 TensorBoard 网站的链接:https ://www.tensorflow.org/tensorboard 。
此外,PyTorch Lightning 支持 CometLogger、CSVLogger、MLflowLogger 和其他日志记录框架。您可以参考Logging文档,了解如何启用其他记录器类型的详细信息。这是文档的链接:https ://pytorch-lightning.readthedocs.io/en/stable/extensions/logging.html 。
概括
我们开始本书的初衷只是对 DL 和 PyTorch Lightning 是什么感到好奇。任何深度学习新手或 PyTorch Lightning 的好奇初学者都可以尝试简单的图像识别模型,然后通过学习迁移学习( TL ) 等技能或如何利用其他预训练有素的架构。我们继续利用 PyTorch Lightning 框架来处理图像识别模型以及自然语言处理( NLP ) 模型、时间序列和其他传统机器学习( ML ) 挑战。在此过程中,我们了解了 RNN、LSTM 和 Transformers。
在本书的下一部分中,我们探索了奇异的 DL 模型,例如生成对抗网络( GAN )、半监督学习和自监督学习,它们扩展了 ML 领域的可能性,而这些不仅仅是先进的模型,但创造艺术的超酷方式和很多乐趣。我们在最后一节中总结了这本书,介绍了将 DL 模型投入生产和常见故障排除技术以扩展和管理大型培训工作负载。
虽然这本书的目的是让那些正在开始他们的 DL 之旅的人开始并运行,但我们希望那些来自其他框架的人也发现这是一种快速而简单地过渡到 PyTorch Lightning 的方法。
虽然这一章我们的旅程可能即将结束,但您的深度学习之旅才刚刚开始!在人工智能( AI ) 领域,我们仍有许多未解决的问题需要开发新的算法,还有许多未解决的问题需要设计新的架构。未来几年将是成为专注于深度学习的数据科学家最激动人心的时刻!使用 PyTorch Lightning 等工具,您可以专注于做一些很酷的事情,例如研究新方法或构建新模型,同时让框架为您完成繁重的工作。尽管过去几年与 DL 相关的所有浮华、魅力和炒作,ML 社区都几乎没有到达大本营。我们仍处于登顶山峰的早期阶段AGI(Artificial General Intelligence),从AGI顶层的角度来看,将是一台真正可以与人类智能和智力相媲美的机器。成为 DL 社区的一员将使您成为改变人类的冒险的一部分!