机器学习编译器的前世今生

作者|Chip Huyen
翻译|胡燕君、贾川、程浩源
我承认,在大学的编译器课上哭了,后来我选择成为一名机器学习工程师,以为再也不用被编译器烦扰。
然而,当我逐渐了解ML模型如何投入生产应用,关于编译器的问题不断涌现。在许多用例中,尤其是用边缘设备运行ML模型时,模型的成功与否仍然取决于运行它的硬件(https://hardwarelottery.github.io/)。因此,了解模型的编译和优化,以及模型在不同硬件加速器上的运行非常重要。
理想情况下,我们不需要特别关注编译器,一切都会“正常工作”。然而,要实现这个目标还有很长的路要走。
如今,越来越多公司希望用边缘设备运行ML模型,运行ML模型的硬件越来越多,为了让ML模型能在硬件加速器上更好地运行,也诞生了越来越多编译器——例如MLIR dialects、TVM、XLA、 PyTorch Glow、cuDNN等。根据PyTorch创始人Soumith Chintala的说法,随着ML的应用逐渐成熟,公司之间的竞争将转向谁能更好地编译和优化模型。

ML的下一个战场是编译器(Soumith Chintala,Venture Beat 2020)
了解编译器的工作原理可以帮你选对编译器,让模型在所选硬件上的运行效果达到最佳,也能帮你诊断模型性能问题并加快模型运行速度。
本文对ML编译器进行了通俗介绍。ML编译器始于边缘计算的兴起,这使编译器不再是系统工程师的专属,而是全体ML从业者关心的领域。如果你已十分了解用边缘设备运行ML的重要性,可以跳过下文第一部分。
然后我将谈及在边缘设备部署ML模型的两个主要问题:兼容性和性能,并说明编译器如何解决这些问题,以及它的工作原理。本文最后还将提供关于如何通过几行代码来显著提高ML模型速度的参考资料。
1
云计算 VS 边缘计算
想象一下,你已经训练出一个出色的ML模型,其精度远超你的期望,然后你迫不及待地部署这个模型,来让用户使用。
最简单的方法是将模型打包并通过托管云服务(如AWS或GCP)进行部署,这也是许多公司在最初使用ML时的做法。云服务在这方面贡献巨大,使得企业可以轻松将ML模型投入生产。
但是,云部署也有很多缺点。首先是成本。ML模型需要进行大量计算,而计算的成本很高。早在2018年,Pinterest、Infor、Intuit等大公司每年在云服务上的开销就已超数亿美元。而对于中小型公司来说,这个数字每年可能在5-200万美元之间。初创公司在云服务方面稍有不慎,可能就会导致破产。
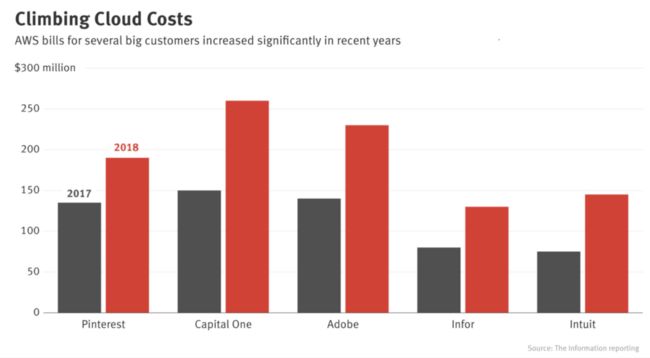 AWS使用量激增,企业云账单金额飙升(图源The Information, 2018)
AWS使用量激增,企业云账单金额飙升(图源The Information, 2018)
随着云计算费用不断攀升,越来越多公司试图将计算转移到消费设备(边缘设备)。在边缘设备上完成的计算越多,对云服务的需求就越少,他们要支付的费用就越少。
除了能降低成本,边缘计算还有许多优势。首先,边缘计算的可运行范围更广。当模型位于公有云上时,向云端发送并接收数据需要依赖稳定的网络连接。但边缘计算可以使模型在没有网络连接或连接不稳定的情况下继续运行,比如在农村地区或发展中国家。
其次,边缘计算可以减少网络延迟的困扰。如果必须使用网络传输数据(将数据发送到云端的模型进行预测,然后将预测发送回用户),那么某些用例可能就无法实现。在许多情况下,网络延迟比推理延迟更严重。例如,你或许能够将ResNet50模型的推理延迟从30毫秒降低到20毫秒,但其网络延迟可能会高达数秒,具体情况取决于你的所在地网络。
第三,边缘计算可以更好地保护敏感的用户数据。云计算ML模型意味着可能要通过网络来发送用户数据,增加了数据被拦截的风险。同时,云计算还将诸多用户的数据存储在同一位置,这意味着一旦发生数据泄露就会影响许多人。据《安全》杂志2020年报道,近80%的公司在过去18个月内曾遭遇过云数据泄露(https://www.securitymagazine.com/articles/92533-nearly-80-of-companies-experienced-a-cloud-data-breach-in-past-18-months)。边缘计算使得企业可以更安全地传输和存储用户数据,避免违反GDPR等数据保护条例。
2
编译:兼容性
相对于云计算,边缘计算具有许多优势,因此许多企业正竞相开发针对不同ML用例优化的边缘设备。谷歌、苹果、特斯拉等知名巨头都宣布自研芯片。与此同时,不少ML硬件初创公司也融资数十亿美元来开发更好的AI芯片。
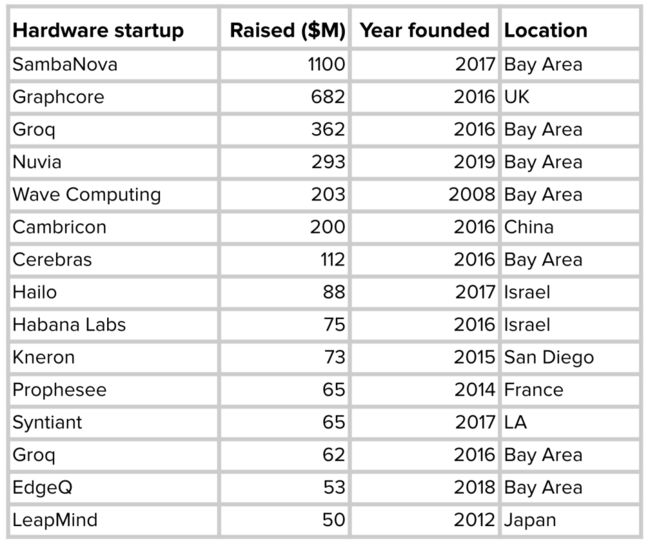 AI硬件初创公司的不完全统计(融资信息来自CrunchBase)
AI硬件初创公司的不完全统计(融资信息来自CrunchBase)
运行ML模型的硬件产品变多了,于是就出现一个问题:如何让使用任意框架构建的模型可以在任意硬件上运行?
一个框架要在某种硬件上运行,它必须得到硬件商的支持。例如,尽管Google早在2018年2月就已公开发布TPU,但直到2020年9月,TPU才支持PyTorch。在此之前,如果想使用TPU,就必须要使用Google的TensorFlow或JAX。
要使一种硬件(或平台)支持某一框架需要耗费大量时间和工作量。将ML工作负载映射到硬件需要了解并利用硬件的基础架构。然而,有一个基础性问题必须克服:不同的硬件类型有不同的内存布局和计算原语,如下图所示:
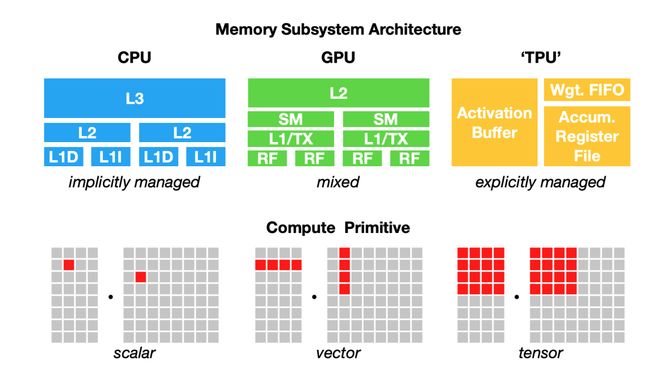 不同硬件后端的计算原语和内存布局(图源:https://arxiv.org/abs/1802.04799)
不同硬件后端的计算原语和内存布局(图源:https://arxiv.org/abs/1802.04799)
例如,从前,CPU的计算原语是数字(标量),GPU的计算原语是一维向量,而TPU的计算原语是二维向量(张量)。但是,如今许多CPU具有向量指令,而一些GPU具有二维张量核心。给定一个256张图像 x 3 通道 x 224 W x 224 H的batch,如果要对这个batch执行卷积算子,一维向量计算原语和二维向量计算原语将有很大不同。同样,还要考虑不同的L1、L2和L3布局和缓冲区大小,如此方能有效地利用内存。
正因如此,框架开发人员更倾向于只支持少数服务器级别的硬件(如GPU),而硬件商也倾向于只向少数框架提供自己的内核库(例如,英特尔的OpenVino工具库仅支持Caffe、TensorFlow、MXNet、Kaldi和ONNX。NVIDIA自己则有CUDA和cuDNN)。将ML模型部署到新硬件(例如手机、嵌入式设备、FPGA 和 ASIC)需要耗费大量的人力。
如何在任意硬件后端运行使用任意框架构建的模型?图上每个空格都需要一种编译器?
中间表示 (IR)
与其针对每种新的硬件类型和设备配备新的编译器和库,何不创建一个中间媒介来桥接框架和平台?框架开发人员将不再需要支持每种类型的硬件,而是只需将他们的框架代码“翻译”成这种中间媒介。这样,硬件商就只需要支持一个中间框架。
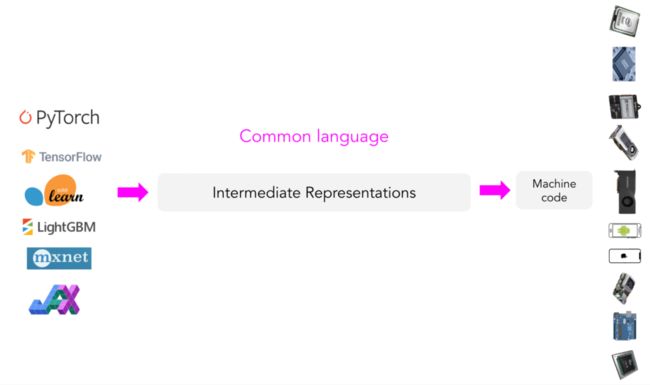 中间表示(IR)作为中间媒介
中间表示(IR)作为中间媒介
这种中间媒介称为中间表示(IR)。IR是编译器工作的核心。编译器在模型原始代码的基础上生成一系列高级和低级中间表示,然后生成硬件原生代码以在特定平台上运行模型。
编译器通常利用代码生成器(codegen)根据IR生成机器原生代码。ML编译器中最常用的代码生成器是Vikram Adve和Chris Lattner开发的LLVM,LLVM改变了我们对系统工程的理解。TensorFlow XLA((译注:2022年10月,Google宣布开源OpenXLA))、NVIDIA CUDA编译器 (NVCC)、MLIR(用于构建其他编译器的元编译器)和TVM都在使用LLVM。
生成代码的过程也称为“降级(lowering)”,因为是将高级的框架代码“降低”为低级的硬件原生代码。准确地说,这个过程不能称作“翻译”,因为两种代码之间不是一对一的映射关系。
高级IR通常是ML模型的计算图。对于熟悉TensorFlow的人来说,这里的计算图类似TensorFlow 1.0中的计算图,那时TensorFlow还没有切换到Eager Execution模式。TensorFlow 1.0在运行模型之前会先构建模型计算图,计算图可让TensorFlow了解模型,从而优化运行时。
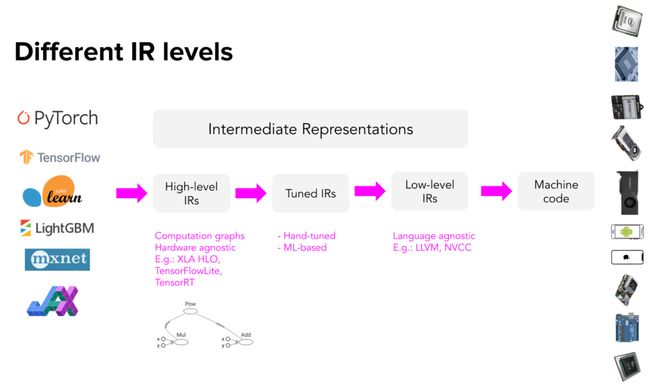 高级IR和低级IR
高级IR和低级IR
高级IR通常与硬件无关(无论在什么硬件上运行),而低级IR通常与框架无关(无论模型是用什么框架构建的)。
3
优化:性能
完成代码“降级”后,在所选硬件上运行模型时可能还会遇到性能问题。Codegen非常擅长将IR降级为机器代码,但受目标硬件后端的影响,机器代码的运行效果可能不够好。生成的代码可能无法充分利用数据局部性和硬件缓存,或者无法使用可以加速代码的高级功能,例如向量操作或并行操作。
典型的ML工作流程需要用到许多框架和库。例如,用 Pandas/Dask/Ray 从数据中提取特征;用NumPy执行向量化;用LightGBM等树模型来生成特征,然后用由不同框架(如sklearn、TensorFlow或Transformers)构建的各种模型来进行预测。
尽管这些框架内部的个别功能可能得到优化,但跨框架的优化几乎不存在。一种简单的方法是把数据搬运到不同的功能上分别计算,但这会导致整个工作流的速度下降一个数量级。斯坦福 DAWN实验室的研究人员的一项研究发现:与手动优化代码相比,使用NumPy、Pandas和TensorFlow的典型ML工作负载在一个线程中的运行速度要慢23倍(http://www.vldb.org/pvldb/vol11/p1002-palkar.pdf)。
在生产中,数据科学家/ML工程师常用pip来安装他们工作所需的包,在开发环境中运行状况良好,于是他们将模型部署到生产环境。当他们在生产中遇到性能问题时,他们的所在公司通常会聘请优化工程师来根据运行的硬件优化模型。
 Cruise优化工程师的工作描述
Cruise优化工程师的工作描述
 Mythic优化工程师的职位描述
Mythic优化工程师的职位描述
然而优化工程师十分稀缺,薪资要求也高,因为这份工作既要懂机器学习,也要懂硬件架构。另一个办法是采用优化编译器(Optimizing Compiler),即可以优化代码的编译器,也可以自动优化模型。在将ML模型代码降级为机器代码的过程中,编译器可以分析模型计算图以及其中包含的算子(如卷积算子、循环算子、交叉熵等),然后设法加快计算速度。
前文总结:编译器可以把ML模型和它赖以运行的硬件桥接起来。优化编译器包含两部分:降级与优化。这两部分有时也可以整合在一起。优化可能发生在从高级IR到低级IR的任何阶段。
-
降级:编译器为模型生成硬件原生代码,让模型可以在特定硬件上运行。
-
优化:编译器根据硬件环境优化模型。
4
如何优化ML模型
优化ML模型的方法有两种:局部优化和全局优化。局部优化是指优化模型的某一个或某一组算子;全局优化是指端到端优化整个计算图。
目前已有一些标准的局部优化方法,大部分是通过提高并行度或减少芯片内存访问来加速模型。以下是四种常见的方法。
-
向量化:给定一个循环或嵌套循环,但单次不止执行一个元素,而是使用硬件原语执行在内存中连续的多个元素。
-
并行:给定一个输入数组(或者n维数组),将其分割为多个不同的独立工作块,分别对每个工作块执行操作。
-
循环分块(Loop Tiling):修改循环中的数据访问顺序,从而更好地利用硬件的内存布局和缓存。这种优化方法对硬件的依赖极高。适合CPU的访问模式未必适合GPU。详情可参考Colfax Research提供的可视化解释
(https://colfaxresearch.com/how-series/#ses-10)。
-
算子融合:将多个算子融合为一个算子,可以避免冗余的内存访问。例如,对同一数组执行两个操作需要两次循环,但经过融合后就只需要一次循环。详情可参考Matthias Boehm提供的例子。(https://mboehm7.github.io/teaching/ss19_amls/04_AdvancedCompilation.pdf)
 来自Colfax Research的可视化解释
来自Colfax Research的可视化解释
 来自Matthias Boehm的算子融合例子
来自Matthias Boehm的算子融合例子
Weld编译优化器的缔造者Shoumik Palkar表示,在一定的条件下,这些标准局部优化方法可以将模型运行速度提升3倍左右。(https://www.youtube.com/watch?v=JbTqNuCIJM4)
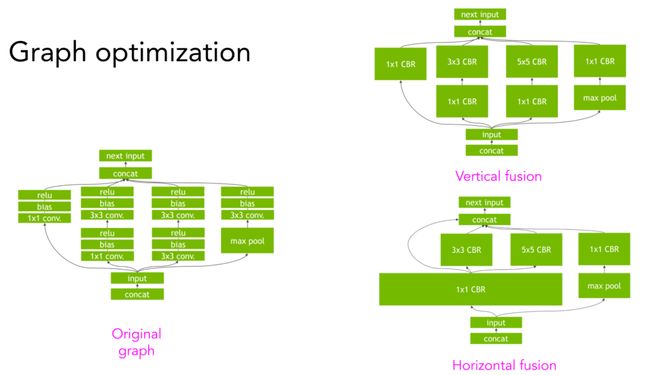 卷积神经网络计算图的垂直融合&水平融合(图源TensorRT)
卷积神经网络计算图的垂直融合&水平融合(图源TensorRT)
实现更大的速度提升需要运用到计算图中更高层次的结构。例如,给定一个卷积神经网络及其计算图,可进行垂直或水平方向的融合,从而减少内存访问,加快模型运行速度。详情可参考NVIDIA的TensorRT 团队提供的可视化解释(https://developer.nvidia.com/tensorrt)。
5
人工设计 VS 基于ML的编译器
人工设计优化规则
正如上文的垂直/水平融合例子所示,执行计算图的方法很多。例如,给定3个算子A、B、C,可以融合A与B,B与C,也可融合A、B、C。
通常,框架和硬件商的优化工程师能根据经验探索出执行模型计算图的最佳方法。例如,NVIDIA可能会安排一名工程师甚至一个工程师团队来专门研究如何让ResNet-50模型在NVIDIA的DGX A100服务器上运行得更快(所以,不应太看重MLPerf基准测试结果(https://mlcommons.org/en/inference-datacenter-10/)。因为即使一种常见模型在某种硬件上可以运行得相当快,也并不代表任何模型使用该种硬件都能获得同样的高速度。这种模型可能只是经过过度优化而已)。
人工设计优化规则有一些不足之处。首先,得出的优化规则可能不是最优的。谁也不能保证工程师想出来的优化方法就是最佳方案。
其次,人工设计出的优化规则不具备自适应性。如果要针对新的框架或新的硬件架构优化模型,还得重新耗费大量人力。
何况,模型优化取决于计算图中的算子,这又增加了复杂性。优化卷积神经网络不同于优化递归神经网络,后者又不同于优化Transformer模型。NVIDIA和Google专注于针对自家硬件优化ResNet和BERT等常见模型。但如果ML研究人员又发明出新的模型架构呢?那他们就得先自行优化这种新模型,证明它具备高性能,才能让硬件商采用并继续优化这种模型。
用ML来加速ML模型
我们的目标是找到执行计算图的最快方法。那么能不能将所有可能的方法都尝试一遍,记录每种方法的运行时间,然后找到时间最短的一种呢?
可以。但问题是,潜在的方法及其组合实在太多,难以一一穷尽。但如果借助ML呢?
-
用ML可以缩小搜索空间(即所有可能方法的集合),不必尝试所有方法。
-
用ML还可以预测每种方法的所需用时,不必耗费时间等待计算图完成执行。
然而,要预估某种方法执行计算图的所需用时非常困难,因为这需要对计算图作出大量假设。目前的技术只能做到关注计算图的一小部分。
如果你曾在GPU上运行PyTorch,你应该见过下列设置:
torch.backends.cudnn.benchmark=True当设置为True时,就启用了cuDNN autotune。cuDNN autotune会在一组预先设定的执行卷积算子的方法中探索最快的一种。如果每次迭代的卷积神经网络形状都一致,启用cuDNN autotune可以大大提高效率。除了首次运行卷积算子时速度较慢以外(因为cuDNN autotune需要花时间探索最快的方法),在后续运行中,cuDNN都可以利用autotune的缓存结果直接选择最快的配置。
虽然cuDNN autotune可以提高效率,但它只适用于卷积算子,而且应该只在PyTorch和MXNet上能用。更通用的解决方案是autoTVM,它是开源编译器堆栈TVM的一部分。autoTVM可针对子图寻找最佳执行方法,而不只是针对一个算子,所以它的搜索空间要复杂得多。autoTVM的工作原理也很复杂,但可以总结如下:
1. 将计算图分割为多个子图。
2. 预测每个子图的大小。
3. 分配时间为每个子图寻找最佳执行方法。
4. 将每个子图的最佳执行方法组合起来,执行整个计算图。
autoTVM能计算每种方法的实际运行时间,从而收集真实数据用以训练成本模型,令成本模型预测未来某种方法的所需时间。这种做法的好处是,由于成本模型是根据运行时产生的数据训练的,所以它可以适应任何硬件,坏处是等待成本模型训练完善需要更长时间。
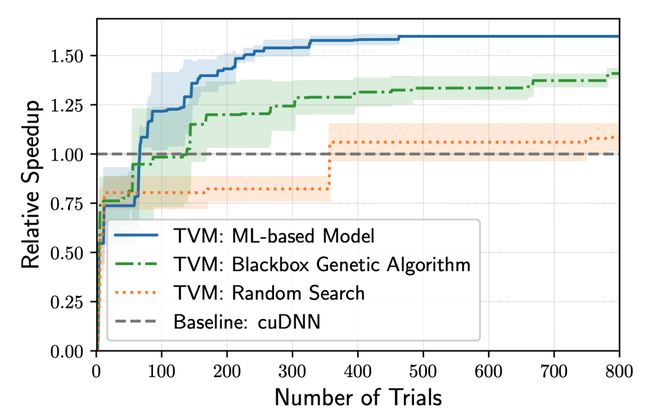 基于ML的TVM带来的提速(以用cuDNN在NVIDIA TITAN X上运行ResNet-50模型的速度为基准);基于ML的TVM大约需要70次迭代才能超越cuDNN的性能;实验数据来自陈天奇等人。
基于ML的TVM带来的提速(以用cuDNN在NVIDIA TITAN X上运行ResNet-50模型的速度为基准);基于ML的TVM大约需要70次迭代才能超越cuDNN的性能;实验数据来自陈天奇等人。
TVM之类的编译器具有自适应性、灵活性,能帮助用户方便地尝试新硬件,例如苹果公司在2020年11月发布的M1芯片。
M1是一个基于ARM的片上系统(SoC),ARM架构我们或多或少都有所了解,但是M1的ARM实现仍然有很多新颖的地方,需要大量优化才能使各种ML模型在M1芯片上快速运行。
在M1芯片发布一个月后,OctoML(译注:TVM团队2019年成立的公司,专注于ML模型的部署)表示,autoTVM 进行的优化比苹果公司的Core ML团队人工设计的优化快了近 30%(https://venturebeat.com/2020/12/16/octoml-optimizes-apache-tvm-for-apples-m1-beats-core-ml-4-by-29/)。当然,随着M1的成熟和人工优化的深入发展,自动优化将很难超越人工优化,但系统工程师仍可以利用autoTVM等自动优化工具来加速优化。
虽然自动优化的效果突出,但依然存在一个问题:TVM的速度有可能很慢。需要试遍所有的可能方法,才能确定最佳优化路径,这一过程可能需要耗费数小时,复杂的ML模型甚至可能需要数天。但这是一劳永逸的过程,优化搜索的结果可以被缓存,然后用于优化现有模型,还可以为未来的优化提供基础。
当你针对一种硬件后端优化了一次模型之后,该模型就可以在使用同一硬件后端的多种设备上运行。当你准备好用于生产的模型,并且选定目标硬件来运行推理时,这种优化方法非常适用。
6
不同的编译器
目前最广泛使用的编译器类型,是由主流框架和硬件商开发的、针对特定框架和硬件组合的特定领域编译器。不出所料,最常用的编译器是由最大的框架和硬件商开发的。
-
NVCC(NVIDIA CUDA编译器):闭源;仅适用于 CUDA。
-
XLA(加速线性代数编译器,由Google开发):已作为TensorFlow库的一部分开源;XLA原本打算用于加速TensorFlow模型,但已被运用到JAX。
-
PyTorch Glow(Facebook):已作为PyTorch库的一部分开源;虽然在TPU上启用了XLA+PyTorch,但对于其他硬件还是依赖PyTorch Glow。
第三方编译器通常雄心勃勃(如果某编译器开发商认为自己针对GPU进行的模型优化比NVIDIA做得还要好,这必然需要足够的自信)。第三方编译器的存在很重要,在知名巨头已针对自家产品深度调整自家编译器的情况下,第三方编译器可以帮助小公司推出的新框架、新硬件和新模型时降低开销、提高性能,让小公司也有机会与知名巨头竞争。
我心目中最好的第三方编译器是Apache TVM,它适用于多种框架(包括TensorFlow、MXNet、PyTorch、Keras、CNTK)和多种硬件后端(包括CPU、服务器GPU、ARM、x86、 移动GPU和基于FPGA的加速器)。
另一个我看好的项目是MLIR。它最初也是由LLVM的创建者Chris Lattner在Google发起,但现在,该项目隶属LLVM。MLIR并不是真正意义上的编译器,而是一种元编译器,一种可以让用户构建自己的编译器的基础架构。MLIR可以运行多种IR,包括TVM的IR、LLVM的IR和TensorFlow计算图。
WebAssembly (WASM)
WASM是过去几年中最令我兴奋的技术趋势之一。它拥有高性能、易于使用,而且它的生态发展飞快。截至2021年9月,全球93%的设备都支持WASM。
我们一直在讨论编译器如何为模型生成机器原生代码,让模型可以在特定的硬件后端上运行。那能不能生成一种可以在任何硬件后端上运行的代码?
浏览器有一个好处:如果你的模型可以在浏览器上运行,那么这个模型就可以在任何支持浏览器的设备上运行,包括Macbook、Chromebook、iPhone、Android手机等,且无需关心这些设备使用什么芯片。如果苹果决定从英特尔芯片改用ARM芯片,对你也没有影响。
WASM是一个开放标准,它让你得以在浏览器上运行可执行程序。使用sklearn、PyTorch、TensorFlow等框架构建模型后,你不必针对特定硬件编译模型,而是可以将模型编译为WASM。然后你会得到一个可执行文件,可以用JavaScript来执行该文件。
因为WASM是在浏览器中运行,所以它的缺点是速度很慢。尽管WASM已经比JavaScript快得多,但与在设备上运行原生代码相比(例如iOS或Android应用程序),它仍然很慢。Jangda等人的研究显示,编译为WASM的应用程序,其运行速度比原生应用程序平均慢45%(火狐浏览器)到55%(谷歌浏览器)(https://www.usenix.org/conference/atc19/presentation/jangda)。
有许多编译器可以将代码编译到WASM运行时。例如最流行的Emscripten(它使用的也是LLVM Codegen),但它只能将C语言和C++编译成WASM;Scailable可以将scikit-learn模型编译为WASM,但它在GitHub上只有十几个Star,并且已经有几个月没更新了(开发方是不是已经不再维护它了?);TVM应该是目前还能用的唯一一个可将ML模型编译到WASM的编译器(https://tvm.apache.org/2020/05/14/compiling-machine-learning-to-webassembly-and-webgpu)。
温馨提示:如果你打算使用TVM的话,用非官方conda/pip命令可以快速安装(https://tlcpack.ai/),不要看Apache站点上的说明。因为如果你按照后者操作遇到问题,只能去他们的Discord上找人帮忙(https://discord.gg/8jNs8MkayG)。
7
编译器的未来
思考模型在不同的硬件后端上的运行细节很有必要,这样有助于提高模型性能。Austin Huang(https://www.linkedin.com/in/austin-huang-74a75422/)在MLOps Discord上发帖称,只需使用简单的现成工具,例如量化工具、Torchscript、ONNX、TVM等,往往就可以获得两倍的模型加速。
在此我向大家推荐一篇文章(https://efficientdl.com/faster-deep-learning-in-pytorch-a-guide/),它列出了多个在GPU上加速PyTorch模型的有用技巧,甚至无需使用编译器。
在模型部署阶段,有必要尝试不同的编译器,比较哪一个可以带来最佳的性能提升。你可以并行进行实验。如果一个推理请求获得小幅提速,那么数百万或数十亿推理请求就可以累积成巨大回报。
尽管用于机器学习的编译器已经取得巨大进步,但我们还需要很多努力,才能把编译器抽象出来,让广大ML从业者不用再为编译器烦恼。理想的情况是,ML编译器可以像GCC传统编译器一样。GCC会自动将C语言或C++代码降级为机器代码,让大多数C语言程序员不必关心GCC会生成什么中间表示。
未来,相信ML编译器也可以做到这样,当开发者使用框架创建出计算图形式的ML模型,然后ML编译器可以根据任何目标硬件为模型生成机器原生代码,开发者也不必关心编译器生成什么中间表示。TVM等工具可以帮助我们实现这一未来。
8
致谢
感谢Luke Metz、Chris Hoge、Denise Kutnick、Parimarjan Negi、Ben Schreiber、Tom Gall、Nikhil Thorat、Daniel Smilkov、Jason Knight和Luis Ceze,他们耐心地回答了我的问题,帮助我写出了这篇文章。
(本文经授权后由OneFlow编译发布,原文:https://huyenchip.com/2021/09/07/a-friendly-introduction-to-machine-learning-compilers-and-optimizers.html。译文转载请联系OneFlow获得授权。)
其他人都在看
-
TVM:成为深度学习领域的“Linux”
-
进击的PyTorch,和它背后的开源领袖
-
TPU演进十年:Google的十大经验教训
-
LLVM之父Chris Lattner:编译器的黄金时代
-
开源吞噬AI界?从Stable Diffusion的爆火说起
-
OneEmbedding:单卡训练TB级推荐模型不是梦
-
大模型训练难?效率超群、易用的“李白”模型库来了
欢迎体验OneFlow v0.8.0:https://github.com/Oneflow-Inc/oneflow/ https://github.com/Oneflow-Inc/oneflow/
https://github.com/Oneflow-Inc/oneflow/