Python+Selenium爬虫实现:草料二维码微信群活码自动更新,提升社群运营效率
背景
1.我部门在社群运营工作中,通过将微信群码加入线下海报的方式进行线下引流,每个社区建立一个微信群,目前已有社区微信群500个;
2.微信群码有效期14天,过期必须将线下海报替换,否则群码失效,用户无法扫码加入微信群;
3.使用“草料二维码平台”的活码功能,把生成的活码加入海报,将微信群码作为活码的内容,用户扫描海报上的活码-打开实时的微信群码-进入微信群,以此解决了“群码过期必须线下替换海报”的问题;
4.但运营人员依然需要每14天将活码中的微信群码进行手动更换,耗时严重(全部更换完约8小时),手动更换过程:下载微信群码—查找对应活码—上传微信群码—提交更新。
目标
1.降低人工更新群码的操作时长,提升效率;
2.实现自动化/半自动化办公
3.最终呈现效果:
草料二维码自动更新程序
方法与过程
1.了解当前工作流程
上述流程目前需要人工重复操作500+次,耗时严重;
第3、4步骤耗时占比最大,约占用70%的时间。
2.自动化实现流程
大致流程步骤
着重解决人工操作的第3、4步骤的自动化,
利用Python+Selenium实现自动更新操作:
步骤过程分析
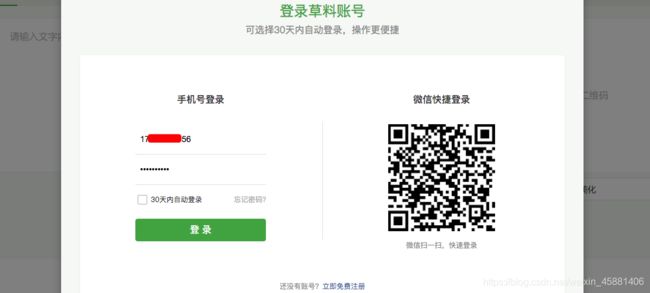
1.需登录草料二维码平台
需模拟登录
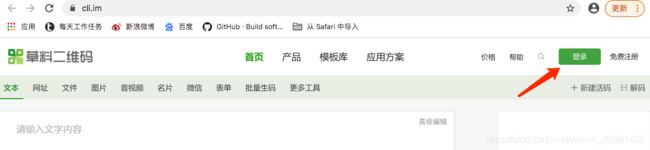
2.获取活码列表
需要获取活码名称;
列表是下拉至底部自动加载,每次加载20个
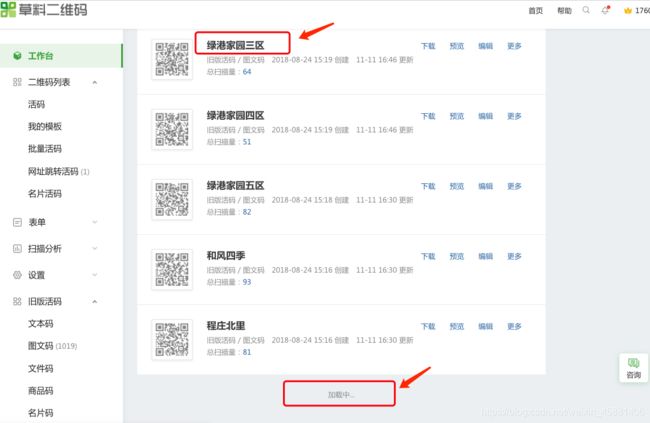
每个活码有独立的编辑页面链接
3.筛除名单
存在不需更新的二维码,需要将其筛除后再开始更新

4.确认名称准确性
手工更换时的第2步中(将微信群码命名保存),可能会存在人为失误导致的图片命名错误,需核对名称准确性。
5.列表显示顺序会变
列表中二维码按更新时间排序,每更新完一个二维码,列表顺序就会变化,且Selenium经常会因网速等原因存在不稳定性导致程序中断,为避免重新运行程序时爬取的数据与第一次的顺序不一致,故将第一次爬取的列表名称顺序以.csv的格式保存至本地,以便复用。
6.需要考虑替换过程中断
因Selenium易被外界因素干扰(网速不稳定、手动误操作等因素)导致程序中断,且每次网页请求耗时较大,在程序设计时要考虑从断点继续进行二维码上传更新的操作,而不是全部从头开始,避免浪费不必要的时间。
具体实现
import time,csv,os
from selenium import webdriver
from bs4 import BeautifulSoup
import pyautogui,pyperclip #用于操作系统窗口,仅支持windows系统
1.登录
#登录草料平台,获取所有二维码信息列表
def login_getqrlist(pages): #通过观察网页可知总页数pages=二维码总数/20
qrlist=[] #用于存储二维码列表信息
user_id='xxx账号xxx'
user_password='xxx密码xxx'
login_url='https://cli.im/' #网页登录地址
driver=webdriver.Chrome()
driver.get(login_url)
time.sleep(1) #等待页面完全加载
login_button=driver.find_element_by_xpath('//*[@id="login_join"]/a[2]') #定位登录按钮
login_button.click() #点击登录按钮

点击登录按钮后弹出: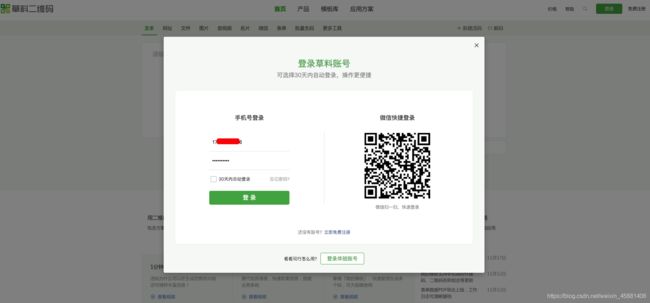
这里是一个iframe前端内嵌页面,访问域名与主网页不同,requests请求无法获取,故:
elementi=driver.find_element_by_xpath('//*[@id="iframe"]') #定位iframe
driver.switch_to_frame(elementi) #跳进iframe
userid=driver.find_element_by_xpath('//*[@id="loginemail"]') #定位账号输入框
userid.click() #点击账号输入框
userid.send_keys(user_id) #输入账号
userpassword=driver.find_element_by_xpath('//*[@id="loginpassword"]') #定位密码输入框
userpassword.click() #点击密码输入框
userpassword.send_keys(user_password) #输入密码
pyautogui.press('enter') #按下回车
time.sleep(2) #等待页面完全加载
2.爬取二维码列表
登录成功后进入页面: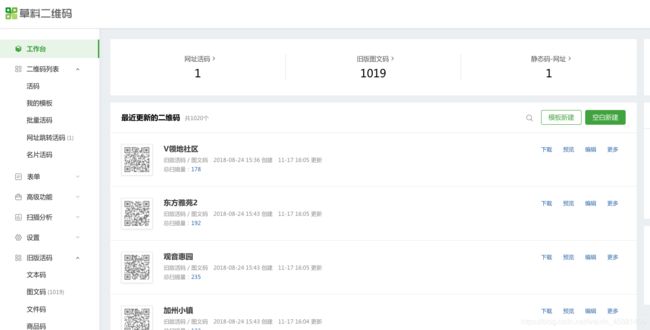
for i in range(pages-1):
js = "window.scrollTo(0,document.body.scrollHeight)"#直接移动到最底部,多次下拉直至加载所有数据
driver.execute_script(js)
time.sleep(1) #等待完全加载
html=BeautifulSoup(driver.page_source,'html.parser') #解析完全加载后的网页内容
qr_info_list=html.find_all('div',class_='recentInfoBox___2HjKc') #所有二维码信息
for qr_info in qr_info_list:
qr_name=qr_info.find('div',class_='pointer___2P78s').text
qr_id=qr_info.find('span',class_='allScan___KBL7S')['data-analyze-desc']
qrlist.append([qr_id,qr_name]) #储存每个二维码的名称、id
driver.close() #关闭浏览器
return qrlist #返回列表
3.筛除无用名单及标准化名称
适用规则:目前运营人员已经将草料活码名称通过特殊符号标记:“-”开头或者数字开头的二维码是不需要更新的二维码(已经放弃运营的),其他的二维码需要每2周做更新。
def filtrate_qrlist(qrlist):
print('筛除规则为:筛掉名称为“-或数字”开头的二维码信息;标准化规则为:保留二维码名称中"-"之前的社区名')
new_qrlist=[]#用于储存筛选并标准化后的二维码列表
old_qrlist=qrlist
for qr in old_qrlist:
lsname=list(qr[1]) #将二维码的名称字符串转化为列表形式
if (lsname[0] != '-') and (lsname[0].isdigit() == False) : #如果名称首个字符不为"-" 且 首个字符不是数字的
ls_clname=[]
for str_ in lsname:
if str_ != '-':
ls_clname.append(str_) #重新组成二维码名称
else:
break
str_clname=''.join(ls_clname)
ls_clid=qr[0].split('|')
clid=ls_clid[0] #提取出二维码id数字,去掉多余符号
new_qrlist.append([clid,str_clname])
print('名称标准化完成:id:{},二维码名称:{}'.format(clid,str_clname))
else:
continue
return new_qrlist #返回列表
4.核对二维码名称
替换前的准备,将上一步返回的二维码名称列表与待上传的二维码文件名做核对,若有错误则告知运营人员去修改为正确文件名。
def check_pic(new_qrlist,pic_path): #传入参数:第3步返回的列表及本地图片所在文件夹路径
print('----------开始确认是否存在不匹配的图片名----------')
file_name=[]
error_name=[]
dirs=os.listdir(pic_path)
for qr in new_qrlist:
qrname=qr[1]
filename=qrname+'.png'
file_name.append(filename)
for filename in file_name:
if filename not in dirs:
error_name.append(filename)
print('未匹配到文件名称:{}'.format(filename))
else:
continue
return error_name #返回
5.保存待替换二维码名称
将筛除和标准化后的二维码信息、以及生成本地待替换二维码图片所在文件路径,保存至.csv文件
def save_qrlist(qrlist,filepath): #传入参数:第3步返回的列表及本地图片所在文件夹路径
count=0
with open('qrlist.csv','w',newline='') as file:
writer=csv.writer(file)
title=['次序','id','名称','图片位置']
writer.writerow(title)
for qr in qrlist:
count+=1
qr_id=qr[0]
qr_name=qr[1]
pic_filepath=filepath+'\\'+qr_name+'.png'
writer.writerow([count,qr_id,qr_name,pic_filepath])
#[[次序,id,名称,图片路径]]
6.读取.csv并自动上传更新图片
读取第5步中的.csv文件,获取待更新二维码信息:名称、图片路径
def read_qrlist():
count=0
qrlist=[]
with open('qrlist.csv','r') as file:
reader=csv.reader(file)
for line in reader: #跳过第一行
if count==0:
count=1
continue
else:
qrlist.append(line)
return qrlist
#[[次序,id,名称,路径]]
自动上传更新
def update_pic(qrlist):
sum=len(qr_list)
print('----------开始替换二维码图片,共{}个----------'.format(sum))
count=int(input('从第几个开始替换?(全部替换输入:1):'))
driver=webdriver.Chrome()
for qr in qrlist[count-1:]:
qr_url='https://cli.im/user/active/edit/'+str(qr[1])+'?p=1' #草料二维码编辑页面链接
pic_name=qr[2]
pic_path=qr[3]
driver.get(url=qr_url) #打开每个二维码的编辑页面
time.sleep(1)
try: #应对首次登陆或中途弹出登陆页面
userid=driver.find_element_by_xpath('//*[@id="loginemail"]')
userid.send_keys('xxx账号xxx')
userpassword=driver.find_element_by_xpath('//*[@id="loginpassword"]')
userpassword.send_keys('xxx密码xxx')
button_sign=driver.find_element_by_xpath('//*[@id="login-btn"]')
button_sign.click()
time.sleep(1)
except:
pass
button_up=driver.find_element_by_xpath('//*[@id="upload-img-up"]/input') #定位上传按钮
button_up.click() #点击上传按钮,此时系统弹出窗口—待选择文件
pyperclip.copy(pic_path) #复制本地图片路径
pyautogui.hotkey('ctrlleft','v') #模拟键盘操作,粘贴本地图片路径到系统弹出窗口的文本框中
time.sleep(1)
pyautogui.press('enter') #模拟键盘操作,按回车键,打开图片
time.sleep(2) #等待上传完毕
button_enter=driver.find_element_by_xpath('//*[@id="save_btn"]') #定位确认按钮
button_enter.click() #点击确认按钮,完成上传更新
print('替换成功:{},当前第{}个'.format(pic_name,qr[0]))
time.sleep(3) #等待更新完毕
driver.close() #关闭浏览器
7.运行程序
首先尝试运行main1函数,确保图片全部匹配后 继续运行main2开始自动上传更新
main1():
def main1():
print('开始前请确保所有群码名称与草料码名中的首个“-”之前社区名称准确对应,且群码图片格式全部为.png')
page=int(input('输入将要替换图片的页数:'))
filepath=input('输入图片所在的文件路径,右键点击群码图片-属性-文件位置,直接复制粘贴于此:')
qrlist = login_getqrlist(page) #爬取所有草料码信息
newqrlist = filtrate_qrlist(qrlist) #筛除、标准化
errorfile=check_pic(newqrlist,filepath) #对本地图片名称进行匹配核对
if errorfile: #如果有未匹配图片名
print('有未匹配的群码图片名或群码图片缺失,请修改群码名称后重新启动程序,按F5')
else:
saveqrlist(newqrlist,filepath)
main1() #执行 main1函数
main2():
def main2():
qrlist=read_qrlist()
update_pic(qrlist)
main2() #执行main2函数,如果程序中断,可重新运行main2填写断点序号继续更新
总结
- 原人工操作完成全部更新需要8小时,现人工操作时长仅需2~2.5小时
- 提示信息尽量做到了通俗易懂,使运营人员安装好环境后即可上手操作
- 过程中遇到的问题:
1、注意iframe的跳入跳出对爬虫的影响
2、注意使用pyautogui,pyperclip的过程中,遇到模拟操作延时性问题;且仅可用于windows