数学建模——多目标规划模型(智能优化算法NSGA-II)
摘要
本篇笔记对数学建模中常见的多目标规划问题提供了解法:在建立传统的多目标规划的常用模型的基础上,使用智能优化算法对多目标规划问题进行求解,通过Pareto Front直观展现非劣解的分布情况,以解决传统的多目标规划问题将多目标转化为单目标问题带来的只有单一解的问题。并结合一些伪代码,流程图对遗传算法算法本身进行了分析,阅读了一定的材料之后给出利用自己写的简单的具有“变异算子”,“交叉算子”,“选择算子”的代码完成对飞机巡航路线的设计。最后利用Matlab的gamultiobj函数实现对布置的课后作业的求解。
关键词:多目标规划;智能优化算法;遗传算法;Pareto Front
一、多目标规划及其非劣解
-
概念:
研究多于一个的目标函数在给定区域上的最优化,称为多目标规划。通常记作:MOP(multi-objective-programming)。
要注意的是多目标规划的目标之间是相互冲突的(不然就不是多目标),是不能将多个目标合并成为一个统一的目标来求解的,这是判断一个问题是否是多目标规划问题的关键。例如:设计一辆汽车,既要安全(重量大),又要省油;设计一种导弹,既要射程远,又要节约燃料。这样的各个目标之间是冲突的,才能被称为多目标规划问题。
建模时要注意,多目标求解的目标数尽量保持在2~3个比较合适,目标数量过多会给我们的求解带来困难。 -
多目标规划模型的组成:
(1) 两个以上的目标函数
(2) 若干个约束条件 -
多目标规划模型的主要描述形式:
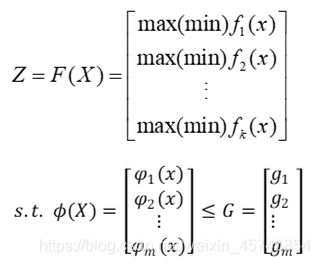
式中X=[x_1,x_2,…,x_n ]^T为决策变量。我们把

可以写成:s.t. x∈Ω 其中x=(x_1,x_2,…,x_n)所在的空间Ω称为决策空间,F(x)所在的空间称为目标空间
缩写形式:
Max(min)Z=F(X)----(1)
s.t. ϕ(X)≤G
若有n个决策变量,k个目标函数,m个约束方程,则
- Z=F(x)-----k维函数变量
- ϕ(X)-----m维向量函数
- G-----m维常数向量
- 多目标规划的非劣解
多目标规划问题,不能只顾一个目标函数的最优,而不顾其他的目标函数。多目标规划需要作出复合选择:
(1) 目标函数的选择
(2) 决策变量的选择
衡量某一个方案的好坏无法用一个指标来衡量,需要多个目标进行比较,这些目标有时不是很协调,甚至是对立的。
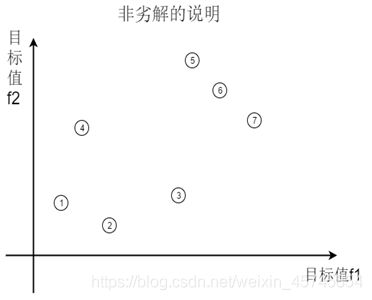
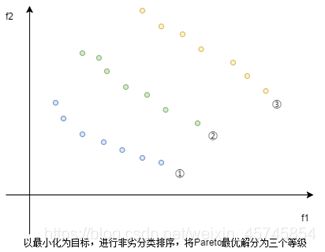
由上图(假设要求f1和f2都达到最大):1和2比较,1的f2指标大于2的f2指标,但2的f1指标大于1的f1指标,于是二者的较优性无法比较,即无法确定这两个方案的优劣。
而在各个方案之间,显然,4比1好,3比2好,5比4好,7比3好……
而对于方案5,6,7之间则无法比较优劣性,且没有比他们更好的其他方案,所以他们被称为多目标规划问题的非劣解,或者Pareto最优解,而其他的解被称为劣解。
定义1:
对于最小化问题,一个向量u=(u_1,u_2,…,u_m)支配(优于)另一个向量v=(v_1,v_2,…,v_m),当且仅当u_i≤v_i, i=1,2,…,m,并且存在j∈1,2,3,…,m,u_j
对于任意的两个自变量向量x_1,x_2∈Ω,如果下列条件成立:
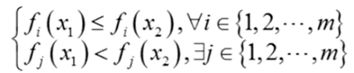
那么向量f_1 (x_1 ),f_2 (x_1 ),…,f_m (x_1),支配(优于)向量f_1 (x_2 ),f_2 (x_2 ),…,f_m (x_2),则称x_1支配x_2。
定义3:
如果Ω中没有支配(优于)x的解,则x是问题的一个pareto最优解,(非劣解,有效解,非支配解)。
Pareto最优解的全体被称为Pareto最优解集。Pareto最优解集在目标函数空间的像集被称为Pareto Front(Pareto 前沿,阵面)。
当目标函数处于冲突状态时,就不会存在使所有目标函数同时达到最大或最小值的最优解,有可能一个解在目标上最好,而在另一个目标上是最差。于是我们只能寻求非劣解(又称非支配解或帕累托解)。
二、多目标规划及其求解方法
对于多目标规划的解法,这里主要介绍两类:传统的多目标解法和智能优化算法,其中智能优化算法目前是国际上比较流行的多目标规划的求解方法,算法已经被Matlab集成。
-
传统解法——多目标规划转换为单目标规划
① 效用最优化模型
思想:规划问题的各个目标函数可以通过一定的方式进行求和运算。这种方法将一系列的目标函数与效用函数建立相关关系,各目标之间通过效用函数协调,使多目标规划问题转化为传统的单目标规划问题:
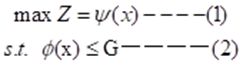
是与各目标相关的效用函数的和函数。
在用效用函数作为规划目标时,需要确定一组权值λ来反映原问题中各目标函数在总体目标中的权重,即:
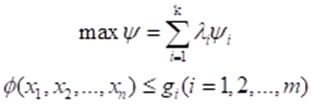
其中,权重值和为1:
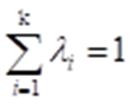
② 罚款模型(理想点法)
思想: 规划决策者对每一个目标函数都能提出所期望的值(或称满意值);通过比较实际值f_i与期望值f*_i之间的偏差来选择问题的解,其数学表达式如下:
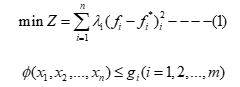
其中λ_i是与第i个目标相关的权重。
③ 约束模型
理论依据 :若规划问题的某一目标可以给出一个可供选择的范围,则该目标就可以作为约束条件而被排除出目标组,进入约束条件组中。
假如,除第一个目标外,其余目标都可以提出一个可供选择的范围,则该多目标规划问题就可以转化为单目标规划问题:
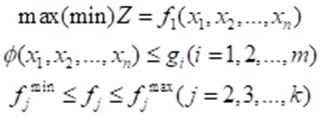
④ 目标达到法
首先将多目标规划模型化为如下标准形式:
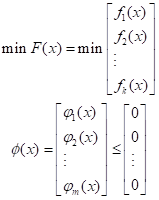
在求解之前,先给出与目标函数相对应的一组理想化的期望目标f_i^* (i=1,2,3,…,k),每一个目标对应的权重系数为:ω_i^* (i=1,2,3,…,k),再设γ为一松弛因子,那么多目标规划模型转换为:
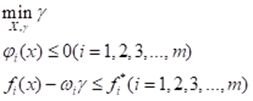
用目标达到法求解多目标规划的计算过程,可以通过调用Matlab软件系统优化工具箱中的fgoalattain函数实现。 -
智能优化算法求解
① 传统算法与智能优化算法的比较:
在上述的传统的算法中,整体的思想都是将多目标规划转化为但目标规划问题,如果要得到多个解的话,就要进行多次的运行,无法得到pareto最优解集,整体上的效率并不高。而智能优化算法能在一次运行过程中找到Pareto最优解集中的多个解,且不限于Parato前沿解集的形状和连续性,易于解决不连续的,凹的Pareto前沿。
② 基于精英策略的快速非支配排序遗传算法(NSGA-II)
(1)算法概述
遗传算法( Genetic Algorithm , GA) 是借鉴生物界自然选择和群体进化机制形成的一种全局寻优算法。为方便理解,首先从宏观角度了解遗传算法。
在遗传算法中,将问题空间的决策变量通过一定的编码方法转换为遗传空间中的个体。将目标函数转化成为一定的适应值,这个适应值将作为评价个体优劣的依据。

遗传算法中涉及到三个算子:选择算子,交叉算子和变异算子,这三个算子模拟了种群遗传和变异产生后代,并且适者生存的过程。其中选择算子反映了“适者生存”,通过种群个体的“适应值”判断个体能否被加入交配池进行交配产生“子代个体”。交叉算子则是模拟种群产生个体的过程,互相交换“染色体”完成产生下一代的过程,而这里的染色体可以理解为编码的序列,具体的我们下面会通过一个例子进行说明。最后变异算子则是较小概率的改变个体的“染色体序列”,实现新个体的出现。
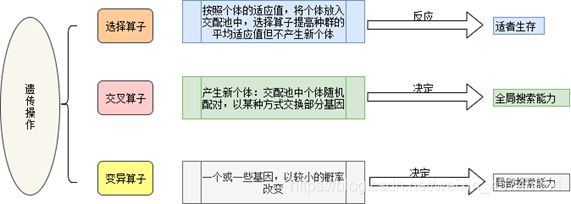
需要说明的是遗传算法中需要确定的参数有:编码串长度、种群大小、交叉和变异概率。编码串长度由优化问题所要求的求解精度决定。种群大小表示种群中所含个体的数量 ,种群较小时,可提高遗传算法的运算速度 ,但却降低了群体的多样性,可能找不出最优解;种群较大时 ,又会增加计算量 ,使遗传算法的运行效率降低。一般取种群数目为20~100。交叉操作是遗传算法中产生新个体的最主要的方法,所以交叉的概率应该设定得比较大,保证种群能进行充分的交配,但若过大可能破坏群体的优良模式。一般取 0. 4~0. 99。变异概率也是影响新个体产生的一个因素,变异概率小 ,产生新个体少;变异概率太大 ,又会使遗传算法变成随机搜索。一般取变异概率为0. 0001~0. 1。遗传算法常采用 的收敛判据有:规定遗传代数;连续几次得到的最优个 体的适应值没有变化或变化很小等。
下面我们给出遗传算法的流程图,说明遗传算法的主要流程:
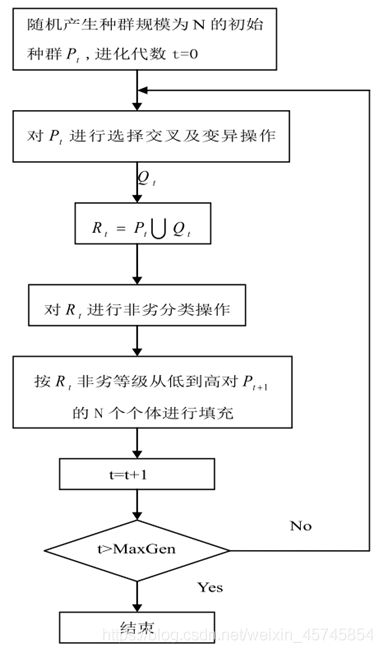
首先,建立一个随机的种群规模大小为 N 的初始种群P_0,并初始化计数器 t=0。然后对种群 P_t进行遗传操作产生子代种群Q_t,将P_t和Q_t合并产生R_t,并对具有 2N 规模的种群R_t进行非劣分类操作,并生成下一代种群P_(t+1)。
进化代数计数器 t 加 1 并判断 t 是否大于最大进化代数 MaxGen。如果是,那么该算法结束;否则,继续进化。如此循环,直到进化到指定的最大进化代数。
每一个个体都有其对应的适应值,正如每一个决策变量都有其对应的目标函数值。非劣分类操作的原则即是根据上述的由优化问题的目标函数对应转换成的个体的适应值来进行筛选。在进行非劣分类排序时需要保存的值有两个S_p和n_p。S_p对应的被个体p支配的集合,n_p对应个体p被多少个其他的个体所支配,保存这个被其他个体的个数,即是n_p。这个过程也被称为“快速非支配排序算法”的过程。
我们以需求目标最小值来描述“快速非支配排序算法”过程:
首先找出n_p=0的所有点,即这些点不被任何点所支配,并且保存这些点的S_p,将这些点标记为Pareto等级①。不考虑等级①的点(即图中蓝色的点,或者说删除这些点),在剩余的点中继续寻找n_p=0的点,标记为Pareto等级②……以此类推分完所有的等级。其中①中的解是最好的,也就是前面所提到的精英解集,它只支配其他解而不被其他任何解支配,②中的个体只被 ①不被其它解支配,依次类推。
但在实际的操作中,并不需要完成对所有的等级的分类——由于整个种群R_t的种群大小为2N,新种群P_(t+1)的N个位置不能容纳所有的非劣等级。当考虑被允许的最后一个等级中的解时,该非劣等级可能存在比新种群剩下位置更多的个体。在这种情况下,使用密度估计的方法从最后一等级选择位于该等级较稀疏区域的个体填充满新种群。这里着重要指出的是R_t的非劣分类和P_(t+1)填充过程可以一起执行。这样,对每一个非劣等级先看它的大小,看它是否 能被新种群容纳,如果不能,那么就不必再进行非劣分类,这样能减少该算法的运行时间。

b. 拥挤选择算子以及交叉算子与变异算子的实现
拥挤距离的定义
在上述的“快速非支配排序算法”的叙述中,我们提到了“密度估计”,需要选择较为“疏松”的个体填充P_(t+1)中不足的个体数量。这样是为了使Pareto Front宽广度和均匀度更加合理。
拥挤距离:第i个个体的拥挤距离定义为第i+1和i-1个体的所有目标函数值的差的和。第一个和最后一个个体的距离设为无穷大——
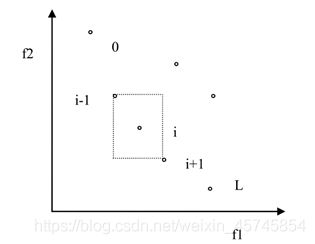
拥挤选择算子
下面给出拥挤距离的求解算法: 第一步:对该层(等 Pareto 排序值)的所有点排序,排序结果如上图所示。
对于两个目标函数值的而言,先选择其中一个目标函数 然后按照该目标函数值从小到大的顺序进行排列,按式(3)计算距离,进而可以用下面的第三步计算拥挤距 离,至到累积完所有的目标函数。
第二步:每个点的拥挤距离d_i初始化为 0;

伪代码如下:
1. def crowding_distance_assignment( I )
2. nLen = len( I ) #I中的个体数量
3. for i in I:
4. i.distance = 0 #初始化所有个体的拥挤距离
5. for objFun in M: #M为所有目标函数的列表
6. I = sort( I, objFun ) #按照目标函数objFun进行升序排序
7. I[0] = I[ len[I]-1 ] = ∞ #对第一个和最后一个个体的距离设为无穷大
8. for i in xrange( 1, len(I) - 2 ):
9. I[i].distance = I[i].distance + ( objFun( I[i+1] ) - objFun( I[i-1] ) )/(Max(objFun()) - Min(objFun()) )


c. 交叉算子
d. 变异算子
(4) 在Matlab中的使用
在Matlab中可以通过函数gamultiobj函数来进行基于快速非支配排序精英策略的遗传算法。
具体使用格式
1. gamultiobj - Find Pareto front of multiple fitness functions using genetic algorithm
2.
3. This MATLAB function finds x on the Pareto Front of the objective functions
4. defined in fun.
5.
6. x = gamultiobj(fun,nvars)
7. x = gamultiobj(fun,nvars,A,b)
8. x = gamultiobj(fun,nvars,A,b,Aeq,beq)
9. x = gamultiobj(fun,nvars,A,b,Aeq,beq,lb,ub)
10. x = gamultiobj(fun,nvars,A,b,Aeq,beq,lb,ub,nonlcon)
11. x = gamultiobj(fun,nvars,A,b,Aeq,beq,lb,ub,options)
12. x = gamultiobj(fun,nvars,A,b,Aeq,beq,lb,ub,nonlcon,options)
13. x = gamultiobj(problem)
14. [x,fval] = gamultiobj(___)
15. [x,fval,exitflag,output] = gamultiobj(___)
16. [x,fval,exitflag,output,population,scores] = gamultiobj(___)
- 用遗传算法求解最优解问题
例1:
已知敌方100个目标的经度、纬度如表1所示。
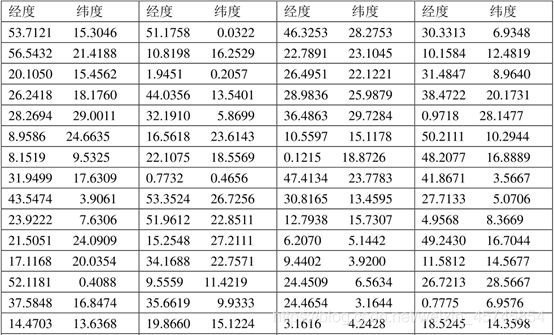
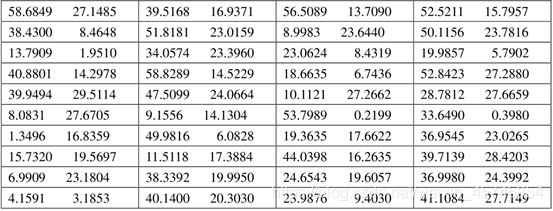
下面给出模拟遗传算法的Matlab代码
1. function primerRun(routeData)
2. %%-------------------数据初始化-------------------------------------
3. sj0=routeData; %完成经纬度的加载
4. x=sj0(:,1:2:8); %提取纬度
5. x=x(:);
6. y=sj0(:,2:2:8); %提取经度
7. y=y(:);
8. sj=[x y]; %经纬度组成向量
9. mylocation=[70,40]; %我方经纬度
10. sj=[mylocation;sj;mylocation];
11. sj=sj*pi/180; %转化为弧度
12. distance=zeros(102); %二维距离数组初始化为0
13. %二维数组计算出地图上任意两点的距离
14. for i=1:101
15. for j=i+1:102
16. distance(i,j)=6370*acos(cos(sj(i,1)-sj(j,1))*cos(sj(i,2))*cos(sj(j,2))+sin(sj(i,2))*sin(sj(j,2)));
17. end
18. end
19. distance=distance+distance';
20.
21. %%-----------------------改良圈算法得到一个较优解----------------------
22. N=50; %一个种群有50个个体,这个精度由问题的精确性给出,这里取50
23. g=100; %进化代数定义为进化100代
24. rand('state',sum(clock)); %matlab随机数为伪随机数,这里定义一个种子,初始化随机发生器
25. for k=1:N %改良圈算法初始化种群
26. c=randperm(100); %产生1~100的一个全排列
27. c1=[1,c+1,102]; %生成初始圈
28. for t=1:102 %修改圈
29. flag=0; %退圈标志
30. for m=1:100
31. for n=m+2:101
32. if distance(c1(m),c1(n))+distance(c1(m+1),c1(n+1))<distance(c1(m),c1(m+1))+distance(c1(n),c1(n+1))
33. c1(m+1:n)=c1(n:-1:m+1);
34. flag=1;
35. end
36. end
37. end
38. if flag==0
39. J(k,c1)=1:102;
40. break; %记录下较好的解后跳出循环
41. end
42. end
43. end
44. J(:,1)=0;
45. J=J/102; %转换为染色体编码
46. %%---------------------------------------------遗传算法主体---------------------------------------
47. for k=1:g %循环进行种群交配
48. A=J; %得到亲代的初始的染色体
49. c=randperm(N);%产生一个1~50的全排列,作为初始的染色体交换对象
50. %------------------------------------交叉操作-----------------------------------------------
51. for i=1:2:N
52. F=2+floor(100*rand(1)); %保证圈的起始点和终点不变的条件下,产生要进行染色体交换的地址
53. temp=A(c(i),[F:102]); %中间变量保存值
54. A(c(i),[F:102])=A(c(i+1),[F:102]); %交叉操作
55. A(c(i+1),F:102)=temp;
56. end
57. by=[];
58. %-----------------------------------变异操作-----------------------------------------
59. %循环保证by非空
60. while ~length(by)
61. by=find(rand(1,N)<0.1); %返回向量或者矩阵中不为0的元素的位置索引
62. end
63. B=A(by,:);%产生变异操作的初始染色体
64. for j=1:length(by)
65. bw=sort(2+floor(100*rand(1,3))); %产生变异操作的三个索引
66. B(j,:)=B(j,[1:bw(1)-1,bw(2)+1:bw(3),bw(1):bw(2),bw(3)+1:102]);%交换位置
67. end
68. G=[J;A;B];%父代和子代的种群合在一起
69. [SG,ind1]=sort(G,2);
70. num=size(G,1);
71. long=zeros(1,num);%路径长度的初始值
72. for j=1:num
73. for i=1:101
74. long(j)=long(j)+distance(ind1(j,i),ind1(j,i+1));
75. end
76. end
77. [slong,ind2]=sort(long);%对路径长度由小到大排序
78. J=G(ind2(1:N),:);%优胜劣汰
79. end
80. path=ind1(ind2(1),:),flong=slong(1)
81. xx=sj(path,1);
82. yy=sj(path,2);
83. plot(xx,yy,'-o');
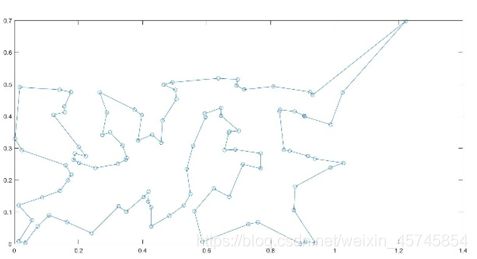
三、多目标规划应用实例(例题)
例一:
某厂生产A和B两种型号的摩托车,每辆车平均生产时间和利润分别为A种:3小时,100元;B种:2小时,80元。该厂每周生产时间为120小时,但可加班48小时,加班时间生产每辆车的利润为:90元(A种),70元(B种),市场每周需要A,B两种车各30辆以上,问如何安排每周的生产计划,在尽量满足市场需求的条件下使利润最大,加班时间最少,建立数学模型,并求解分析。
解:提取题目信息绘制表格:

设:
- f_1利润,f_2:加班时间
- x_1----正常时间生产A型号的件数
- x_2----加班时间生产A型号的件数
- x_3----正常时间生产B型号的件数
- x_4----加班时间生产B型号的件数
建立下面的数学模型:
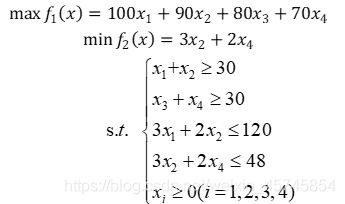
由于智能优化算法涉及到算子的选择问题,以及终止代数的不同,运行了多次后这里给出某一次运行得到的解:

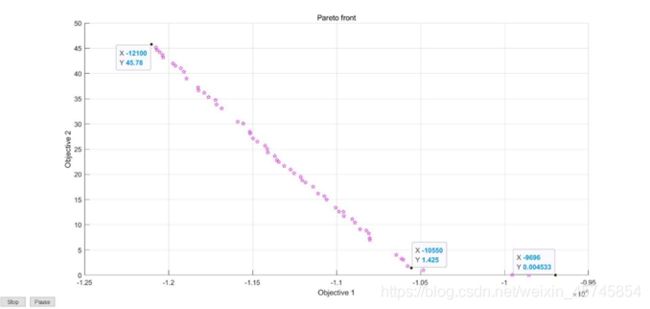
上图为Pareto Front图像,横轴Objective_1为第一个目标,即加班时间;纵轴Objective_2为第二个目标,即工厂利润。
其中主要的三个拐点已经标记出,由上图我们可以看到加班时间最小化与利润最大化之间是存在冲突的,和多目标规划定义符合。
利用Matlab代码求解后得到上图所示的Pareto front。由图像可知:当加班时间在45小时时,收益达到最大值12100元,而当加班时间小于1.5小时时,利润变动变化较小,基本保持在1000元左右。对于其他的情况,工厂决策者可以根据工厂实际情况进行方案选择。
求解代码如下:
1. function y=example1Fun(x)
2. y(1)=-100*x(1)-90*x(2)-80*x(3)-70*x(4);
3. y(2)=0*x(1)+0*x(3)+3*x(2)+2*x(4);
1. clear
2. clc
3. fitnessfcn=@example1Fun;
4. nvars=4;
5. lb=zeros(1,4);
6. ub=[];
7. A=[-1,-1,0,0;0,0,-1,-1;3,2,0,0;0,3,0,2];
8. b=[-30,-30,120,48]';
9. Aeq=[];
10. beq=[];
11. options=gaoptimset('paretoFraction',0.3,'populationsize',200,'generations',300,'stallGenLimit',200,'TolFun',1e-10,'PlotFcns',@gaplotpareto);
12. [x,fval]=gamultiobj(fitnessfcn,nvars,A,b,Aeq,beq,lb,ub,options)
例2:
某工厂共有工人300名,生产A,B,C,D四种产品,要求每人每周平均生产时间在40~48小时内,C为国防用产品,每周至少生产150件,而每周至多可以提供能源20吨标准煤。其他数据如下表:
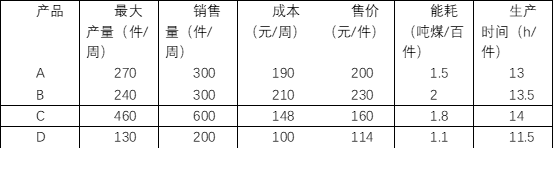
问如何安排每周的生产,才能使纯利润最高,而能耗最少?试建立数学模型并求解。
解:设利润函数为f_1,能耗函数为f_2。A,B,C,D四种产品分别生产x_1,x_2,x_3,x_4件。

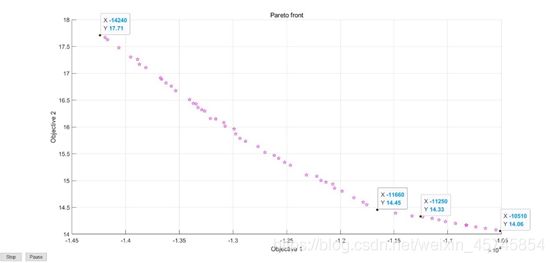
利用Matlab代码求解后得到下图所示的Pareto front。由图像可知:当煤耗量达到17.71t时所获得的利润也达到了最大值14240元;当煤耗量在14.45t~14.33t之间波动时,最大利润波动不大;当煤耗量达到最小14.06t时,利润值也达到了10510元。
对于其他的情况,我们给出相应的决策变量以及对应的决策空间的解,管理者可以根据工厂的实际情况进行相应的选择。
Matlab代码如下:
1. function y=example2Fun(x)
2. y(1)=-10*x(1)-20*x(2)-12*x(3)-14*x(4);
3. y(2)=0.01*(1.5*x(1)+2*x(2)+1.8*x(3)+1.1*x(4));
1. clear
2. clc
3. fitnessfcn=@example2Fun;
4. nvars=4;
5. A=[13,13.5,14,15;-13,-13.5,-14,-15;1.5,2,1.8,1.1];
6. b=[48*300 -40*300 2000]';
7. Aeq=[];
8. beq=[];
9. lb=[0,0,150,0];
10. ub=[270 240 460 130];
11. options=gaoptimset('paretoFraction',0.3,'populationsize',200,'generations',300,'stallGenLimit',200,'TolFun',1e-10,'PlotFcns',@gaplotpareto);
12. [x,fval]=gamultiobj(fitnessfcn,nvars,A,b,Aeq,beq,lb,ub,options)
决策变量取值以及对应解空间:

