【Transformer】24、A Survey of Visual Transformers

本博客还有多个超详细综述,感兴趣的朋友可以移步:
卷积神经网络:卷积神经网络超详细介绍
目标检测:目标检测超详细介绍
语义分割:语义分割超详细介绍
NMS:让你一文看懂且看全 NMS 及其变体
数据增强:一文看懂计算机视觉中的数据增强
损失函数:分类检测分割中的损失函数和评价指标
Transformer:A Survey of Visual Transformers
机器学习实战系列:决策树
YOLO 系列:v1、v2、v3、v4、scaled-v4、v5、v6、v7、yolof、yolox、yolos、yolop
文章目录
-
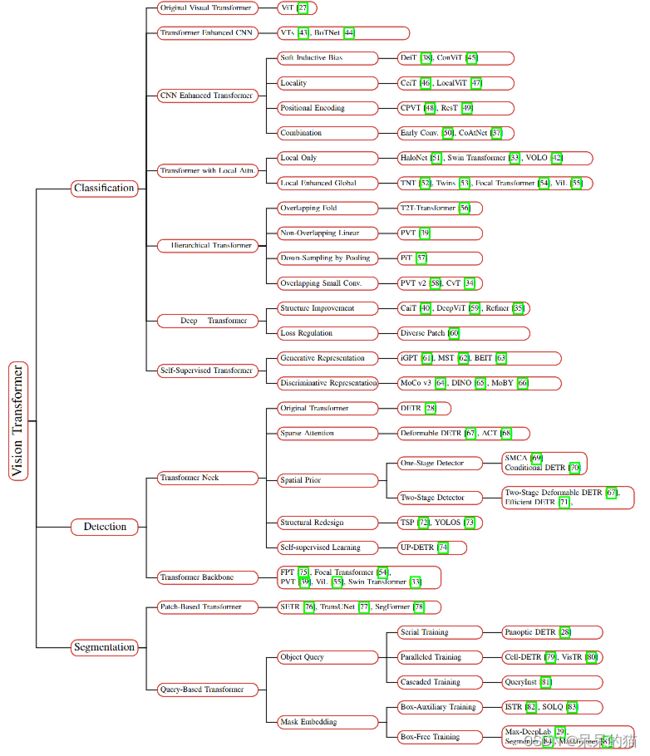
- 一、Transformer 是如何在计算机视觉中使用的
- 二、原始 Transformer
- 三、分类中的 Transformer
-
- 3.1 Original Visual Transformer
- 3.2 Transformer Enhanced CNN
- 3.3 CNN Enhanced Transformer
- 3.4 Local Attention Enhanced Transformer
- 3.5 Hierarchical Transformer
- 3.6 Deep Transformer
- 3.7 Transformers with Self-Supervised Learning
- 3.8 讨论
- 四、检测中的 Transformer
-
- 4.1 Transformer Neck
-
- 4.1.1 Original Detector
- 4.1.2 Transformer with Sparse Attention
- 4.1.3 Transformer with Spatial Prior
- 4.1.4 Transformer with Redesigned Structure
- 4.1.5 Transformer Detector with Self-Supervised Learning
- 4.2 Transformer Backbone
- 4.3 讨论
- 五、分割中的 Transformer
-
- 5.1 Patch-based Transformer
- 5.2 Query-Based Transformer
-
- 5.2.1 Transformer with Object Queries
- 5.2.2 Transformer with Mask Embeddings
- 5.3 讨论
- 六、总结
-
- 6.1 Summary of Recent Improvements
- 6.2 Discussion on Visual Transformer
- 6.3 Learnable Embeddings in Different Visual Tasks
一、Transformer 是如何在计算机视觉中使用的
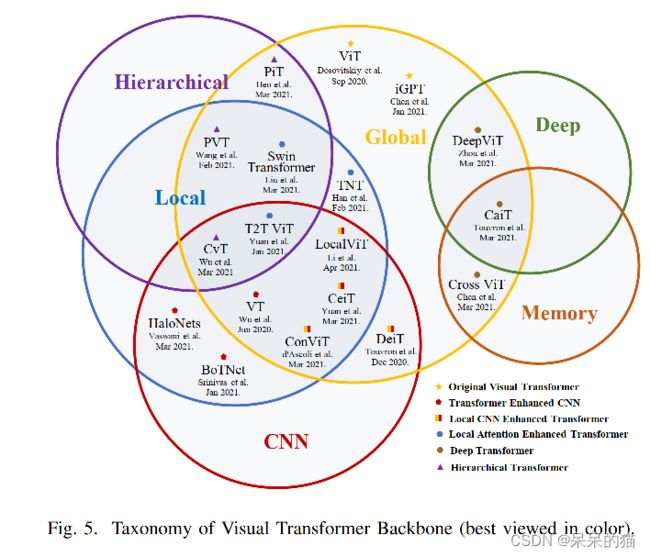
我们已知 Transformer 最开始是在 NLP 中使用的,如 GPT、BERT 等,而视觉任务长期都是被 CNN 统治的。受 NLP 中的 self-attention 能够捕捉长距离信息的特点启发,研究者们开始在视觉任务中使用 self-attention, 并开发出了一系列适用于视觉任务的变体。如拆分 attention 后的 channel-attention/spatial-attention,捕捉像素和像素关系的 Non-local 等模块,并且会嵌入 CNN 网络中,帮助网络关注重点区域。之后,很多研究者直接使用了 NLP 的 Transformer 的网络结构,如 ViT,并且在图像分类上取得了超越 CNN 的效果。
如图1所示,在 ViT 之后,又出现了很多相关变体。图 2 展示了不同任务下的不同 Transformer 结构及修改点。下面会分别介绍视觉任务中的典型的 Transformer。
二、原始 Transformer
NLP 中的 Transformer 解决的是序列的任务,encoder 对输入序列进行编码,decoder 对输出序列进行预测。其中,最核心的部分就是 self-attention。
1、 Attention
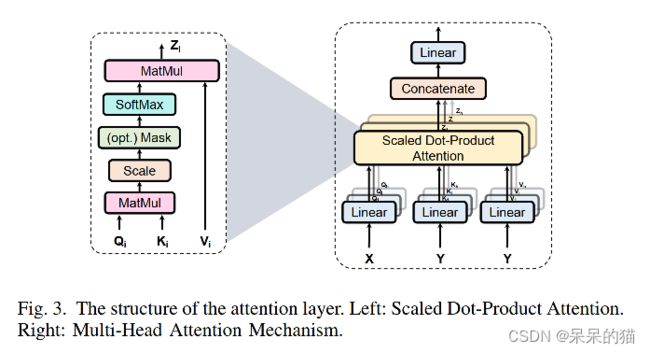
如图 3 所示,attention 的输入有三个——Q、K、V,分别代表 query(查询)、key、value,在视觉任务中,self-attention 的这三个元素都是输入特征图的变体,cross-attention 中 Q 是输入的变体,K 和 V 都是输出的变体。
以图 3 为例,一个 Q 对应一个 K,它俩做了点乘之后,得到相关性矩阵,然后和 V 相乘,就会得到加权后的 V 作为输出。规范化格式如下,其中 ( d k ) \sqrt(d_k) (dk) 为缩放因子,softmax 为归一化操作。
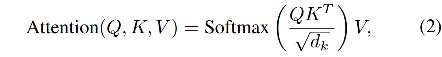
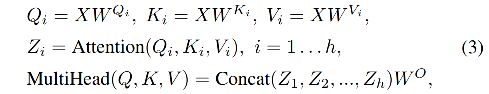
![]()
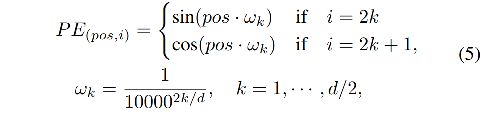
2、 Multi-Head Attention
单个 head 的 self-attention 的容量有限,所以出现了 multi-head self-attention (MHSA)结构,能够保证学到更丰富的信息,多头的输出会被 concat 起来作为输出。
3、 Position-wise Feed-Forward Networks
MHSA 的输出会输入两个串联的 FFN 网络中,FFN 可以看做是将每个位置都同等看待,但每层使用不同参数的结构。
4、Position Encoding
由于 Transformer 在每个输入的处理都是相同的,所以无法保留序列的信息,故需要对位置进行编码,一般都使用 sine 和 cosine 函数编码。
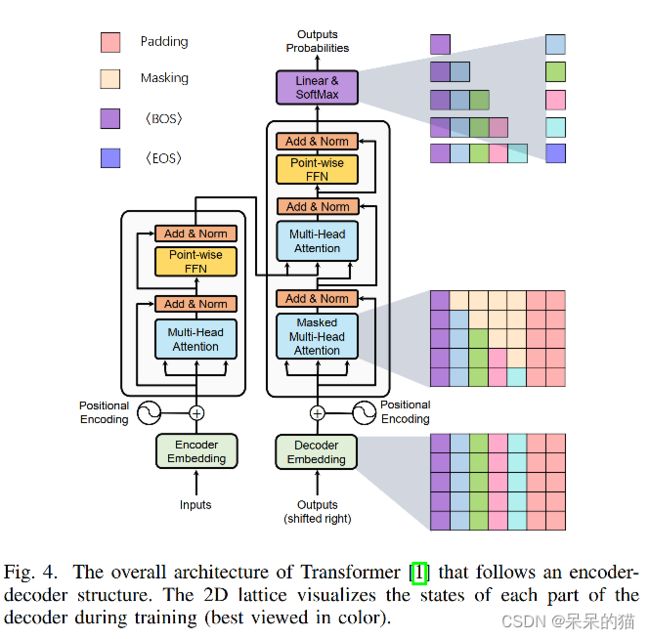
5、Transformer 模型
模型结构如图 4 所示,包括 6 个 encoder,6 个 decoder:
- 每个 encoder 都是由 2 层组成,① MHSA 层用来提取权重,② FFN 层用来提取特征表达。
- 每个 decoder 都进行 cross-attention (接收来自 encoder 的输出和上一层 decoder 的输出)
三、分类中的 Transformer
ViT 首次将 Transformer 引入图像分类并且取得了比 CNN 更好的效果。
Transformer 有很好的的全局信息建模能力,但在前面的浅层 stage 会缺失局部信息。
-
使用 CNN 增强 Transformer 的方法使得 Transformer 中引入了 CNN 的归纳偏置能力;
-
使用 local attention 增强 Transformer 的方法重新设计了 patch 和 attention block 来提高 Transformer 的局部建模能力,是一个 CNN-free 的结构。
此外,CNN 的强大能力很大程度上来自于层级特征和深度结构,所以,层级 Transformer 和 深度 Transformer 也被提出了。前者是使用金字塔代替了固定尺寸的结构,后者可以防止注意力地图过于平滑,并增加了它在深层的多样性。
3.1 Original Visual Transformer
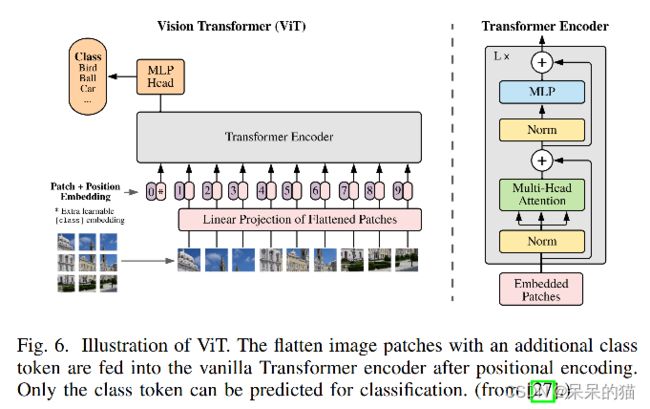
ViT 是第一个被提出解决图像分类问题的 Transformer backbone,因为原始的 Transformer 的输出是一个 token 序列,所以作者先将图片切分成了“无重叠”的块儿,然后映射为 patch embedding。同样也给每个 patch 加上了 1D 的可学习的位置编码来保持空间信息,然后送入 encoder(图6)。
类似于 BERT,ViT 也插入了可学习的 [class] embedding,该值是代表了 encoder 的输出,并且作为类别预测结果。
此外,当输入图像为任意大小时,会使用 2D 插值补充预训练的位置编码,来保证输入的序列性。
在使用一个大数据集(JFT-300M,包含300 million 图像)进行预训练后,ViT 达到了比当时各种 CNN 方法相似或更好的效果。
3.2 Transformer Enhanced CNN
如前面提到的一样,Transformer 有两个主要部分:
- MHSA
- FFN
Cordonnier 等已经证明,卷积层可以被有多个头的 MHSA 来近似,Dong 等人证明了如果没有跳连和 FFN, MHSA 可能对“token uniformity”具有很强的归纳偏置。所以,Transformer 在理论上具有比 CNN 更强的模型容纳能力。
但 Transformer 也由于 self-attention 的存在,导致计算量非常大,尤其在浅层的时候,分辨率很大,self-attention 的计算量与分辨率呈平方关系。
类似于之前将 attention 模块嵌入 CNN 的方法,目前也有很多方法开始将 Transformer 模块嵌入 CNN backbone 中来代替一部分 convolution blocks。
1、VTs: 卷积是将每个像素同等看待,不会考虑其重要性。Visual Transformer(VT)将输入图像的语义信息解耦为不同通道的内容,并且通过 encoder blocks 对不同通道进行关联。
一个 VT-block 包含三个部分:
- tokenizer:将输入解耦成不同语义集合的 token
- encoder:聚合不同 token 之间的语义信息
- projector:重建原始像素空间的特征
通过将 ResNet 的最后一层的替换为 VT-blocks,在 ImageNet 上的准确率提高了 4.6-7%,参数量和计算量都更小了。
3.3 CNN Enhanced Transformer
归纳偏置可以被表示为数据分布或可解空间的一系列假设,一般表现为位置或平移不变性。因为在局部邻域内方差很大,并且在全图中区域稳定,这些卷积偏置可以高效的处理图像数据。但强偏置也会在使用大数据集后限制 CNN 的上限。所以,也有一些人使用 CNN 的偏置来提升 Transformer 并且加速收敛。如:
- soft approximation
- direct locality processing
- direct replacement of the positional encoding
- Structural combinations
1、DeiT:
为了缓解 ViT 对大型数据集的依赖,Touvron 等提出了一个 Data-efficient image Transformer (DeiT),来提高适应性。基于 ViT-B,DeiT-B 使用了数据增强和正则化的方法在 ImageNet 上达到了 83.1% 的 top-1 acc。同时,在预训练的时候采用了 teacher-student 的策略,即使用 teacher 的伪标签来训练token(形式上类似于 class token)。经验上来说,CNN 是比 Transformer 更好的 teacher,而且实验发现 distilled 模型比 teacher 的表现更好。
这个现象可以解释为:CNN teacher 可以将其归纳偏置传递给 student,所以基于 token-based distillation 方法,使得 DeiT-B达到了 85.2% top-1 acc(没有其他数据辅助)。所以,值得研究联合训练的方法来为 Transformer 引入归纳偏置。
2、ConViT:
类似于双通道attention方法[22],[100],ConViT[45] 给 Transformer 分支附加了一个 convolution 分支,通过 Gated Positional Self-Attention (GPSA) 来引入卷积偏置。GPSA 可以被分为两部分:① 普通 self-attention weights;② 模拟 conv weights。ConViT 比 DeiT 高了 0.6-3.2% top-1 acc。
3、CeiT & LocalViT:
上面的方法使用 soft 的方法学习归纳偏置,还有一些直接学习归纳偏置的方法。如 CeiT [46] 和 LocalViT[47],通过直接给 FNN 加上一个 depth-wise conv 来抽取位置信息。并且取得了比原始 DeiT 更好的效果。
4、CPVT & ResT:
一些方法尝试使用卷积内在的位置信息来生成不同分辨率的输入。如 ResT[49] 假设位置编码和输入之间是有关系的,所以将位置编码和输入之间相加可以被看成是像素级的输入进行加权乘法,使用 3x3 的深度可分离卷积来实现(padding=1)。
另外,[102] 中提到,padding 为 0 的卷积可以编码绝对位置信息,所以 CPVT[48] 使用一系列 convolution 来代替位置编码。
上面两种方法得益于卷积位置embedding,在使用小模型的情况下,分别给 ResT-Lite 和 PVT-Tiny 带来了1.3% 和 1.4% 的提升。
5、Early Conv. & CoAtNet:
除了内部的特征融合,一些方法还对不同 Transformer 结构进行了结合。对于标准的圆柱结构,Xiao 等人使用多个堆叠的 stride-2 的 3x3 核来代替原始的 patchify stem(单个无重叠的 large kernel)。这个操作在 ImageNet-1k 上带来了1-2% 的提升,并且有助于促进 ViT 的下游任务稳定和泛化。
对于多层级结构,Dai 等提出了对模型进行最优结合来帮助性能 trade-off。他们提出了 Convolution and Attention Network (CoAtNet) 来联合 CNN 和 Transformer 的优势。因为深度可分离卷积可以很好的嵌入 attention block,并且在浅层垂直的堆叠卷积比原始的分层方法更有效。
3.4 Local Attention Enhanced Transformer
ViT 将输入图像看做一个 patch 序列,使用 patch embedding的方法,忽略了图像和文本之间的 gap,可能会损失图像的信息。
卷积是使用固定的滤波器来进行特征提取的,这种处理方式可以解决大多数小数据集的问题,但是对大数据集表现不好。
而 local-attention 方法可以根据 local 元素的关系来动态的生成attention weights,来提升局部特征的抽取能力并且是 convolution-free 的结构。
1、TNT
ViT 只关注全局 patch 的聚合,忽略了其内部的交互。
类似于 Network In Network (NIN),Han 等人提出了 Transformer iN-Transformer (TNT)[52] 模型来同时进行 patch-level 和 pixel-level 的聚合。
TNT 中的每一层都包含两个连续的 block:
- ① inner block:对每个 patch 内部进行 pixel-wise 的建模;
- ② outer block:抽取每个 patch 的全局信息。
然后使用线性映射层将两个 block 进行连接,将像素映射到对应的 patch。所以,TNT 能够在浅层保留更多的局部信息。
2、Swin Transformer
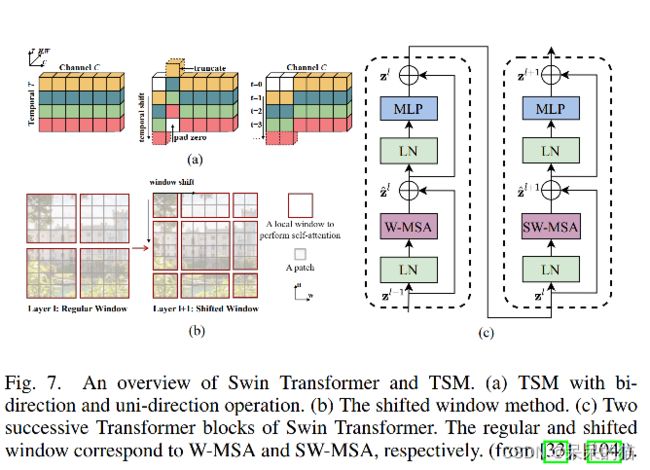
Temporal Shift Module (TSM) [104] 通过在时域维度对部分 channel 进行移动来促进相邻帧的信息交互(图7a),类似于 2D TSM,Liu 等提出了 Shifted windows (Swin) Transformer[33],使用空间维度可平移的窗口来建模全局和边界特征。
使用patch partition 和 patch merging 操作实现的层级结构能够起到空间降维和通道信息交互的作用。此外,两个相邻层的连续的 window-wise 的 attention layer 能够促进 windows 间的信息交互(图7b-c),类似于 CNN 中的感受野扩大。这样能够在 attention 层将计算复杂度从 O ( 2 n 2 C ) O(2n^2C) O(2n2C) 降低到了 O ( 4 M 2 n C ) O(4M^2nC) O(4M2nC),其中 n n n 是 patch 长度, M M M 是 window size。Swin Transformer 在 ImageNet 上达到了 84.2% 的 top-1 的 acc。
3、Twins & ViL
Twins 是一个将 local 和 global 分开的 Transformer,使用了Spatially Separable Self-Attention mechanism (SSSA) 来代替 Swin 的复杂设计。类似于深度可分离卷积或 window-wise TNT block[52]。local attention 层能够捕捉细粒度特征,global attention 能够捕捉长距离特征。
另外一个类似的方法是 ViL[55],使用一系列的局部 embedding 来代替单个的 global token,每个 local embedding 仅仅和其邻域的信息进行交互。就是这样的简单操作,也可和 Swin 的性能媲美。
4、VOLO
Vision Outlooker(VOLO)使用 outlook attention 来关注比其他 attention 方法更细的特征。其由三部分组成:unfold、linear-wights、refold。其整个结构类似于 patch-wise 的动态 convolution。VOLO 比 LV-ViT 高 0.4-1.2% top-1 acc。
3.5 Hierarchical Transformer
ViT 的结构其实是一个圆柱型结构,也就是整个网络中使用的分辨率都是相同的,这样也就会忽略图像的细节信息。所以也有一些 Transformer 网络采用了和 CNN 网络类似的层级结构。
1、T2T-ViT:
层级 Transformer 的范式最初是由 Tokens-to-Token ViT (T2T-ViT) 来提出的。其中使用了 layer-wise T2T transformation 来将邻域的token聚集为一个token。这种通过重叠展开操作实现的周围聚合操作,可以同时实现分层结构和局部化。但也由于重复计算,使得计算复杂度很高。
2、PVT:
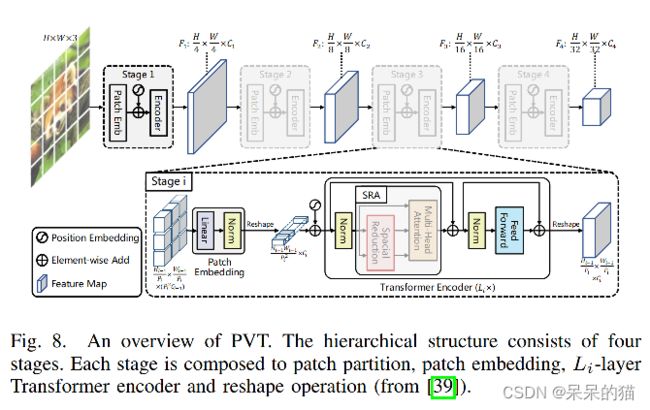
另外一个层级 Transformer 的例子是 Pyramid Vision Transformer (PVT),前面提到重复使用冗余 token 会使得 T2T-ViT 计算量较大。
PVT 使用 non-overlapping 的 patch partition 的方法来降低序列长度,并且使用 linear patch embedding 的方法来保持 channel 维度的连续。
这个方法可以将 Transformer 使用到需要较大输入和细粒度特征的密集预测任务中。
此外, spatial-reduction attention (SRA) 层也能够在每个 attention block 中通过学习 low-resolution 的 key-value pair 来显著的降低计算量(图9)。
3、PiT & CvT:
类似于 PVT 的压缩方法,Pooling-based Vision Transformer(PiT)和 Convolutional vision Transformer (CvT) 使用 pooling 和 convolution 来实现 token embedding。
CvT 通过使用卷积映射代替线性层,提高了 PVT 中的 SRA。且由于卷积而引入的局部语义信息,也能够使得 CvT 泛化到没有位置编码的任意形式的输入。
3.6 Deep Transformer
我们已知,增大模型的深度可以让网络学习到更复杂的特征表达。最近的工作将这种深层结构应用于Transformer,并通过分析 cross-patch[60]与 cross-layer[35],[59]的相似性,以及 residual blocks[40]的贡献,并进行了大量实验来研究其可扩展性。
在深度 Transformer 中,更深层的特征往往不太具有代表性(attention collapse[59]),patch 被映射到不太突出的表达特征(patch over-smoothing[60])。为了弥补上述缺陷,下面的方法也从多个方面提出了相应的解决方案。
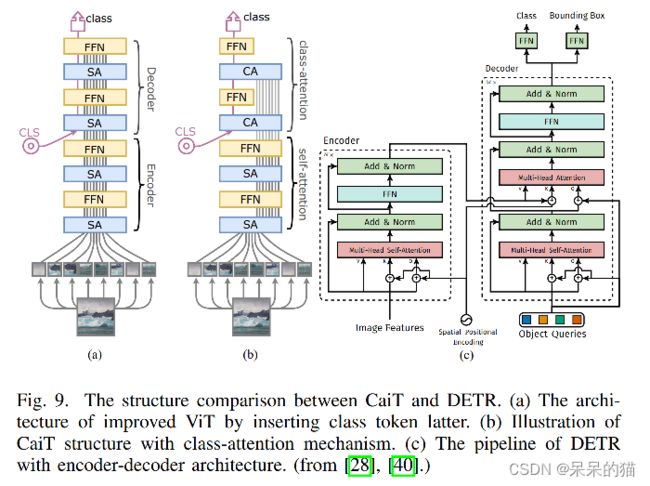
1、CaiT:
从结构方面,Touvron 等提出了 efficient Class-attention in image Transformeation(CaiT[40])。包含两阶段:
① Multiple self-attention stages without class token
在每个层,使用很小的值来初始化一个可学习的对角矩阵,利用该矩阵来动态更新通道权重。
② Last few class-attention stages with frozen patch embedding
之后的 class-token 被插入来进行模型全局表达。类似于 DETR ,有 encoder 和 decoder 结构(图9c)。
这样区分开来是基于一个假设—— class token 是在前向传播中对 patch embedding 的梯度无影响的。
CaiT 在蒸馏策略[38]的加持下,获得了 imagenet 1k 的 86.5% top-1 acc。
2、DeepViT & Refiner:
由于 Deep Transformer 会面临注意力崩溃和过平滑的问题,但仍然能够较好的保留不同 attention head 的 attention map 的多样性。
Zhou 等人提出了 DeepViT,聚合 cross-head 的 attention map,并且使用线性层重新生成了一个新的来提高 cross-layer 特征的多样性。
Rdfiner[35] 使用线性层来扩展 attention map 的维度,来提升映射的多样性。然后使用 Distributed Local Attention(DLA)来更好的建模 local 和 global 特征。达到了 86% 的 top-1 acc,共81M 参数。
3、Diverse Patch:
从训练策略上入手,Gong 等人提出了三个 patch-wise loss 函数,能够有效促进 patch 的多样性并且缓解过平滑的问题。
3.7 Transformers with Self-Supervised Learning
自监督 Transformer 在 NLP 里边是有比较成熟的使用的,但在 CV 中大多数仍然使用有监督的预训练 Transformer。所以也有方法使用生成式和判别式方法来设计不同的自监督视觉 Transformer。
1、iGPT
对于生成式任务,Chen 等人提出了 image Generative Pre-training Transformer (iGPT) [61],iGPT 不同于 ViT 的 patch embedding,而是直接将图像resize 到了小的分辨率,展平为 1D pixel 序列,然后输入该序列到 GPT-2 来进行自回归像素预测任务。IGPT 能够直接建模 pixel-level 的信息,在低分辨率数据集上达到中等效果,但其需要很大的计算量。
2、BEiT
不同于生成每个原始像素,Bao 等人提出了 BERT-style visual Transformer(BEiT),在潜在空间重建 masked image。
3、MoCo v3
4、DINO
3.8 讨论
1、实验度量分析
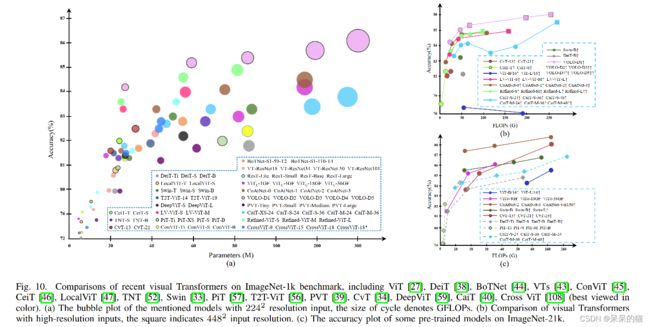
上面的内容是以分类的方法总结了不同的方法。表 1 总结了在主流分类数据集上的效果。图 10a 总结了输入分辨率为 22 4 2 224^2 2242 时的效果,由于 FLOPs 和输入大小是呈平方关系的,所以图 10b 以 FLOPs 为横轴,对比了高分辨率输入下的效果。图 10c 主要对比使用不同数据集来预训练的模型的效果。根据这些对比,可以得到如下的分析:
- 很多由于结构带来提升的方法,对模型大小、输入分辨率等要求比较多,从基础训练测试带来提升的方法(如DeiT/LV-ViT)对不同的模型、任务、输入大小等敏感程度不同。
- 位置对 Transformer 来说是不可或缺的,能从 VOLO 和 Swin 的优势中看出来。
- convolutional patchify stem(ViTc)和 early convolutional stage(CoAtNet)能够较好的提升 Transformer 准确率,尤其是在大数据集上。因为这样能够让浅层捕捉更多的局部细节信息。
- 深度 Transformer 很有潜力,可以看出模型大小和 channel 维度是呈平方关系的,所以该两者的平衡很值得研究。
- CeiT 和 ViT 在小或中(0-40M)数据集上的表现很好,这也说明了这种混合 attention 模块在小模型上还是值得探究的。

2、Visual Transformer 的整个发展
作为一个以 self-attention 为主的模型结构,用于图像分类的 Transformer 主要是从原始 NLP(ViT 和 iGPT),或基于 attention 的 CV 模型(VTs 和 BoTNet)衍生而来的。
之后,很多研究开始探索层级结构,或深层 Transformer 结构,T2T-ViT [56],
PVT [39], CvT [34] 和 PiT [57] 的动机很类似,都是构建层级结构,只是下采样的方法不同。 CaiT [40], Diverse Patch [60], DeepViT [59], 和 Refifiner [35] 致力于解决深层 Transformer 的问题。也有一些方法关注提升 Transformer 模型的基本处理过程,如位置编码、 MHSA、MLP 等。
Transformer 的下一个值得研究的点是位置范式,很多方法通过引入局部 attention 机制或 convolution 机制,为 Transformer 引入位置信息。
3、替代性分析
在 visual Transformer 的发展中,一个很重要的问题在于 Transformer 能否代替卷积。在过去发展的一年多中,基本还没有一个确定的答案。
Transformer 从最开始的结构已经发展到混合结构的形式,全局信息逐步和局部信息融合。虽然 Transformer 在模型能力上略强于 convolution,但 convolution 简单的操作在浅层建模低层语义信息的能力很强,未来,两者的结合可能是趋势。
四、检测中的 Transformer
本节主要介绍目标检测中的 Transformer,可以被分为两个类别:
-
① Transformer 作为 neck
-
② Transformer 作为 backbone
Neck detector 主要基于 Transformer 结构的一种新的表示,object query,即一组学习到的参数,可以看做聚合的全局特征。都是从提升收敛速度或提升性能来进行融合优化的。除了 neck 外,还有一些 Transformer 结构的 backbone。
4.1 Transformer Neck
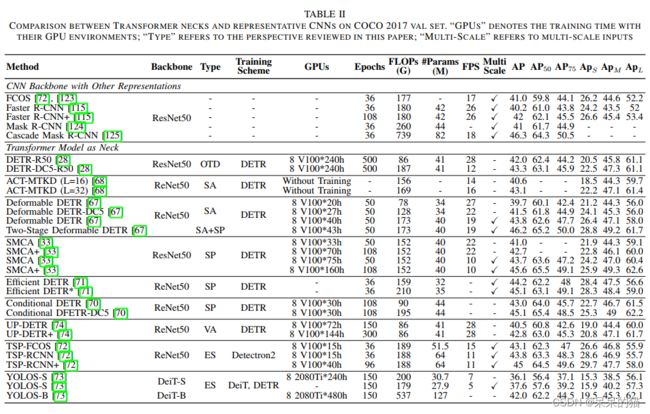
首先来看 DETR[28],是初始的 Transformer detector,也是最开始提出 object query 的,将检测问题构建成了一个序列预测问题。这个方法也引入了一些可以探究的问题,如小目标准确率低,收敛慢等,所以出现了很多方法来解决以下三个问题:
- sparse attention
- spatial prior
- structural redesign
4.1.1 Original Detector
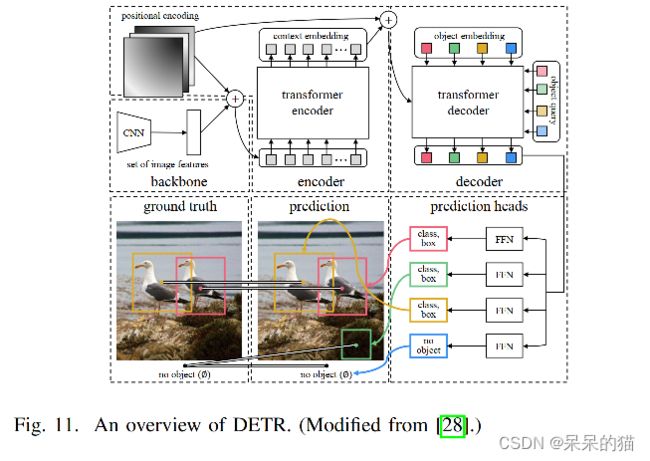
DEtection with TRansformer (DETR)[28] 是第一个端到端的 Transformer 检测器,去除了手工设计和 NMS 后处理,通过引入 object query 和 set prediction 直接对所有目标进行预测。
DETR 使用 encoder-decoder Transformer 作为 neck,FFN 作为预测头(图11)。
Encoder 输入:由 CNN backbone 抽取特征,展平为一维序列,附加位置编码,输入 encoder
Decoder 输入:可学习的位置编码被附加到全零输入中,然后输入给 decoder
Decoder 工作过程:self-attention 模块处理 embedding 之间的关系,cross-attention 将全局特征聚合到 embedding中。
预测头:使用三层 FFN 作为预测头,预测头直接将 decoder 的输出转换成每个目标的 box 坐标和类别得分。类别得分包括 k-class 和 1-special class(对应 no object)。
训练:使用 bipartite matching loss L m a t c h L_{match} Lmatch 来实现预测和真值的一对一的label assign。这种方法类似于学习 match anchors 的方法(AnchorFree)[119]
反向传播:Hungarian loss 包括对每个预测 label 的negative log-likelihood loss 和 对所有匹配起来的对儿的 box loss。
总的来说,DETR 提供了一种新的 end-to-end 的目标检测方法,object query 机制能够在图像特征交互的过程中逐步学习实例特征。双边匹配能够直接使用于 one-to-one 的标签分配任务,且避免了很多后处理。DETR 在 COCO 上取得了和 CNN 类似的效果,但就是在小目标上效果欠佳,且收敛速度慢。
4.1.2 Transformer with Sparse Attention
DETR 中,大量的 decoder embedding 和 全局特征的交互导致了大量的冗余计算,减慢了收敛速度。所以,一些方法设计了 data-dependent 的 sparse attention 来解决这个问题,如 Deformable DETR[67] 和 ACT。
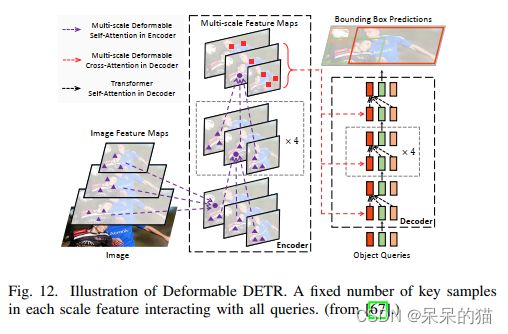
1、Deformable DETR:
Zhu 等人提出了 Deformable DETR,包含一个可学习的 sparse deformable attention 来加速收敛,一个多尺度结构来提升准确率。Deformable DETR 能在比 DETR 少10倍的 epoch 就能到的更高的准确率(尤其是小目标)。参考 FPN,使用 Multi-Scale Deformable Attention (MSDA) 代替了 partial attention block,如图12。
2、ACT:
看了 DETR 的 attention map 后[28],Zheng 等人发现 encoder 中,空间距离很近的元素的 attention map 很相似。为了缓解 encoder 中的冗余序列,所以提出了 Adaptive Clustering Transformer (ACT)
4.1.3 Transformer with Spatial Prior
不同于 anchor 或其他内容/几何特征得到的特征表达。object query 通过随机初始化能够对空间信息进行隐式建模,也可能和 bbox 有弱关联。
1、SMCA
为了使用先验空间关系来强化 object query 和 bbox 的关系,Gao 提出了单阶段方法 Spatially Modulated Cross-Attention(SMCA)来估计每个 object query 的空间先验。SMCA 能够动态的预测每个 object query 的中心点和尺度,生成类高斯的权重图,然后乘到对应的 cross-attention map 上。SMAC 使用多尺度特征来增强 DETR。
在 encoder 中,intra-scale 的 self-attention 在每个尺度内处理特征像素,multi-scale 的 self-attention 平等的聚合不同尺度下相同位置的特征。
在 decoder 中,由每个 object query 生成的 scale-selection attention 权重图被动态的用于对每个 box 选择尺度特征。SMCA 在 COCO 上得到了较好的效果(45.6% mAP),且比 DETR epoch 小 5 倍左右。
2、Conditional DETR
在 DETR 的 decoder cross-attention 中,object query 和 encoder 的位置编码的空间 attention map,和 query-key 的 attention map 是孤立的。
对比不同训练 epoch 数得到的空间 attention map,Meng 等人发现在训练较短的模型中,远端区域的偏差较大。所以他们提出了一个新的空间先验——conditional spatial embedding[70],来表示某个目标远端区域的特征,从位置上来缩小较明显特征的空间有效区域。
这种 conditional spatial embedding 是从 cross-attention 的参考点和 decoder embedding 学习得到的。参考点是作为可学习的参数来代替 object query 或 object query 的预测输出。
不同于 DETR 的预测头,Conditional DETR 使用参考点作为附加输入来定位 box。
这两个改进( conditional spatial embedding & 使用参考点作为附加输入来定位 box)让其在训练快了 8x 的情况下,还在 COCO 上带来了 1.8% mAP 的提升。
3、Two-stage Deformable DETR:
[67] 中,Zhe 等使用两阶段结构来增强空间先验。不同于可学习的 object query,其从 encoder 的 output 中生成 Top-k 个区域提议,然后输入到 Transformer 的 encoder 中进行进一步的精细化调整,类似于 CNN 的两阶段方法,能够在只带来一点计算量增加的基础上,提升 Deformable DETR 的效果。
4、Efficient DETR:
在 Deformable DETR 中,object queries 可以被看做一系列的参考点。经过训练之后,不同的初始化点也会收敛成相似的分布。所以 Yao 等人提出了两阶段 Efficient DETR[71],由 dense proposal generation 和 sparse set prediction 组成。整体结构类似于两阶段 Deformable DETR,但这里 Efficient DETR 的 dense 和 sparse 部分是共享相同的检测头的。
Efficient DETR 只有单个 decoder 层,但也达到了和 DETR 类似的结果,且训练 epoch 少了 14x 之多。而且,两个堆叠的 decoder layer 带来的提升很少,所以如何提升深层堆叠的 decoder 的效果也很值得研究。
4.1.4 Transformer with Redesigned Structure
除过聚焦于优化 cross-attention 外,还有一些工作重新设计了只有 encoder 的结构来避免 decoder 的问题。如 TSP[72],继承了 [28] 的思想,生成了 decoder 和 object query。YOLOS[73] 结合了 DETR 的 encoder-decoder neck,和 ViT 的 encoder backbone 来重新设计出了 encoder-only 的检测器。
1、TSP:
为了控制 Transformer 层的 attention map的稀疏性,Sun 等人[72] 提出,大的训练周期主要是由 cross-attention 的收敛缓慢造成的,并提出了 encoder-only 的 DETR,称为 TSP-FCOS 和 TSP-RCNN,来加速模型的收敛。
具体来说,他们生成了一系列大小固定的 Features of Interests(FoI)或 proposals [115] 送入 Transformer encoder。然后使用 matching distillation 来解决双边匹配的不稳定性。尤其在刚开始训练的时候。对比 DETR,TSP 训练 epoch 少了 5-10x,推理速度快了 1.5-2x。
2、YOLOS:
受 ViT 和 DETR 的启发,Fang 等人提出了 YOLOS,一个纯 sequence-to-sequence 的 Transformer,统一了分类和检测任务。YOLOS 也继承了 ViT 的结构,并且使用固定尺度的可学习 detection token 代替了 class token,类似于 DETR decoder 的输入。然后把这些 object token 和 patch 进行 concat,再输入 encoder 。首先在分类任务中对 object token 进行预训练,然后在 detection 数据集中对其进行微调。YOLOS 不但提升了 DETR 的效果,而且为视觉任务提供了通用的框架。
4.1.5 Transformer Detector with Self-Supervised Learning
受 NLP Transformer 的启发,Dai 等人提出了Unsupervised Pre-training DETR (UP-DETR) 来从 3 个方面帮助监督训练。
- 给所有 object queries 分配一个从输入图像中随机 crop 出的 patch,decoder 的目标就是定位这个 patch 的位置。
- 为了避免在预训练的时候过度学习位置偏置,也构建了一个辅助的重建任务,来保证特征的差别性。
- multi-query 的定位是将多个不同的 patch 分配给不同的 object queries,来模拟多目标检测任务,加快收敛速度 。
4.2 Transformer Backbone
上面也介绍了很多用于图像分类的 Transformer backbone。这些 backbone 很容易就可以嵌入不同的网络结构中,如 Mask-RCNN/RetinaNet/DETR 等,来实现密集预测任务。
层级结构,如 PVT,将 Transformer 构造为一个 high-to-low 分辨率的结构,来学习多尺度特征。
这种局部增强结构将 backbone 构造为 local-to-global 的组合,能够高效的抽取短距离和长距离依赖,避免了二次计算开销。如 Swin、ViL、Focal Transformer。
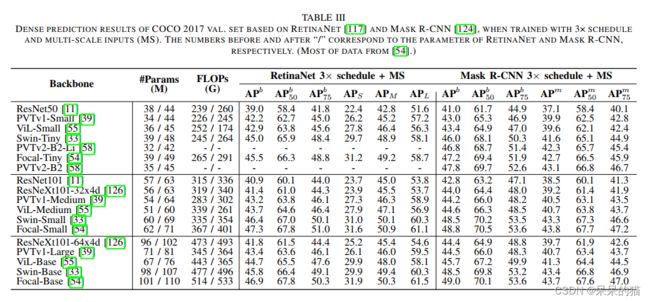
表3对比了不同结构的效果。Transformer 结构的模型比 CNN 的模型高了 2-6.8%,表明了 Transformer 在密集预测中的效果。
类似于 FPN,Zhang 等人提出了 Feature Pyramid Transformer (FPT) [75] ,通过结合 non-local 和 multi-scale 特征来专门来解决密集预测任务。使用了三个 attention 模块来建模空间和尺度的交互,包括 self-attention、top-down cross-attention、bottom-up cross channel attention。FPT 作为一个通用流行的 backbone,取得了很好的效果。
4.3 讨论
SMAC 和 Conditional DETR 在训练 epoch 为 108 时,分别达到了 42.7% 和 43% 的 mAP。
两阶段检测器和 TSP-RCNN[72] 使用 proposal 代替了 object queries。
这些看起来不同但本质相似的操作都提升了检测器的准确率。
从 multi-scale(MS)特征来看,能够弥补 Transformer 在小目标上的效果问题。
Deformable DETR 和 SMCA 对 DETR 分别带来了 5.2% 和 3.1% 的 APs 的提升。
encoder-only 的结构减少了 Transformer 层的数量,明显提升了 FLOPs,YOLOS-B 537 GFLOPs。
encoder-decoder 结构能够较好的平衡 GFLOPs 和 层数的关系,但深层 decoder 层可能会导致训练时间过长和过平滑问题。所以,将 SA 融合进有 MS 和 SP 的深层 decoder 很有研究价值。
五、分割中的 Transformer
Transformer 在分割中的使用主要有两种方式:
- patch-based Transformer
- query-based Transformer
query-based 方法可以进一步被分解为 Transformer with object query 和 Transformer with mask embedding。
5.1 Patch-based Transformer
CNN 需要很多的 decoder 堆叠来得到高层特征,也就是扩大感受野。
但对于 Transformer 来说,patch-based Transformer 是对全局特征的建模,将输入图像看成一个 patch 序列,然后输入柱状的 encoder 中。
Transformer 这种分辨率恒定的方法使得其只使用简单的 decoder 就能够在分割任务上获得较好的效果。
很多工作也开始研究将 patch-based Transformer 和不同的网络结构[124,128] 进行结合。
1、SETR:
受 ViT 启发,Zheng 等人将分类任务的模型扩展到了分割任务,并且提出了 SETR[76]。SETR 使用 Transformer encoder 替代了 CNN backbone,使用了 ViT 的输入输出结构(除过未使用 class token)。此外,还使用了三种 decoder 来实现逐个像素的分类:
- naive up-sampling (Naive)
- progressive upsampling (PUP)
- multi-level feature aggregation (MLA)
SETR 也证实了 Transformer 在分割任务上的可能性,但就是计算量很大。
2、TransUNet:
TransUNet[77] 是第一个用于医学图像分割的 Transformer。可以被看成 SETR 的变体(使用 MLP decoder),或一个 U-Net 和 Transformer 的混合模型。
3、Segformer:
Segformer 使用一系列简单和有效的方法来提升 Transformer 在语义分割的效果,如 hierarchical structure [39], overlap patch projection [34], efficient attention mechanism [34], [39], 和 convolutional position embeddings [48], [53]。
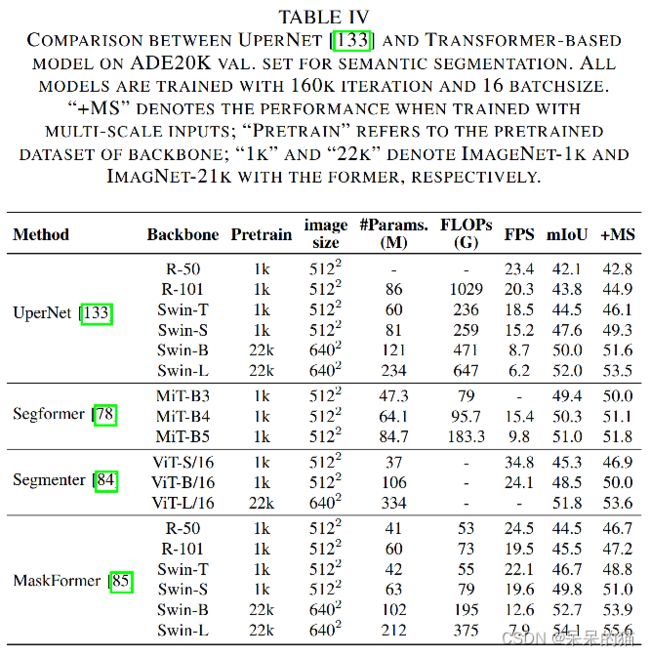
不同于 CNN decoder 使用很多层的堆叠来实现感受野的扩大,Segformer 设计了一个轻量级的 decoder(只包含4层 MLP),来对 encoder 特征进行全局聚合。Segformer-B5 在 ADE20K 上取得了 51.8% mIoU 的 SOTA,且比 SETR 小 4x。
5.2 Query-Based Transformer
Query 是 decoder 输入和输出嵌入的可学习 embedding,和 patch embedding 相比,query embedding 能够更公平的聚合每个 patch 的信息。query-based Transformer 能够移除手工特征和后处理。
最近,很多人都试图将这种表达分为两个类别:
- 一种由 object query 驱动的框架仍然是由检测任务来监督学习
- 一种仅仅由分割任务来驱动
5.2.1 Transformer with Object Queries
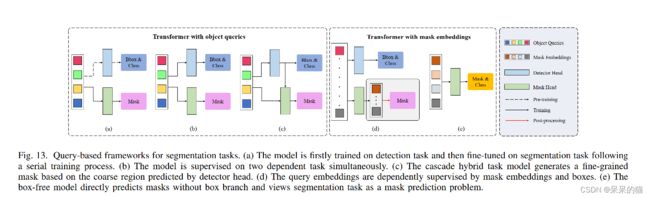
对基于 object query 的方法来说,有三种训练方式。
- 基于 DETR 预训练得到的 object query,再使用 mask 头来基于分割任务进行微调(图13a)
- 不使用多阶段训练方式,object query 同时使用检测和分割任务同时进行建模,常见于端到端的网络(图13b)
- 另一种方法,试图通过混合级联网络来弥合不同任务分支之间的差距 ,其中输出的 box 作为 mask head 的输入(图13c)
1、Panoptic DETR:
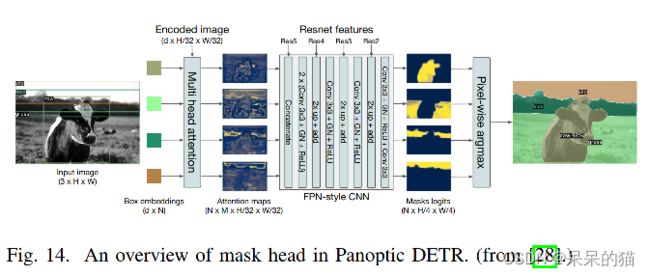
query-based Transformer 是被 DETR 首次引入检测任务的,DETR 通过使用预训练得到的 object query 来训练 mask head 的方法,也同样将其扩展到了全景分割的任务上。
对 object query 和 encoded feature 使用 cross-attention 的方法,来对每个目标使用 attention map,然后使用 上采样,再使用空间选择机制来融合所有的二值 mask。其在 COCO 全景分割数据集上达到了 45.1% Panoptic Quality(PQ)。
2、Cell-DETR:
类似于 Faster RCNN 到 Mask RCNN 的扩展,Prangemeier 等人使用 DETR 来实现了端到端的实例分割(Cell-DETR)。其使用 DETR 中的 mask head 的 cross-attention,然后使用 pixel-adaptive convoution[130] 来代替加法操作。不同于 DETR 中的串联训练方式,Cell-DETR 会同时给不同任务分配不同的 heads/branches,无重叠的 mask 是由 U-Net 分支生成的,class label 作为每个 query 的输出。
3、VisTR:
另外一个方向就是视频实例分割(Video instance segmentation TRansformer, VisTR),该方法将视频实例分割(VIS)建模成了一个并行序列预测问题。主要方法是一个基于实例序列层面的双边匹配 loss 来保持输出的顺序,这样能够保证直接进行一对一的预测。
具体来说,2D CNN backbone 能够抽取每个帧的特征,有 3D 位置编码的 encoder-decoder Transformer 能够建模像素级和实例级特征的相似性。类似于 Cell-DETR,分别使用两个并行的 heads 来预测不同 frame 的每个实例的 box 和 mask。VisTR 在 YouTube VIS 数据集上达到了 35.3% 的准确率,是 single model 方法的最优。
4、QueryInst:
另一个方法是 QueryInst[81],该方法能够用混合任务的级联结构来解决两个不相关branches 的gap。QueryInst 的目标是通过一系列的并行动态 mask heads (with shared queries)给 mask RoI feature 和 object queries 建立一个 one-to-one 的对应关系。
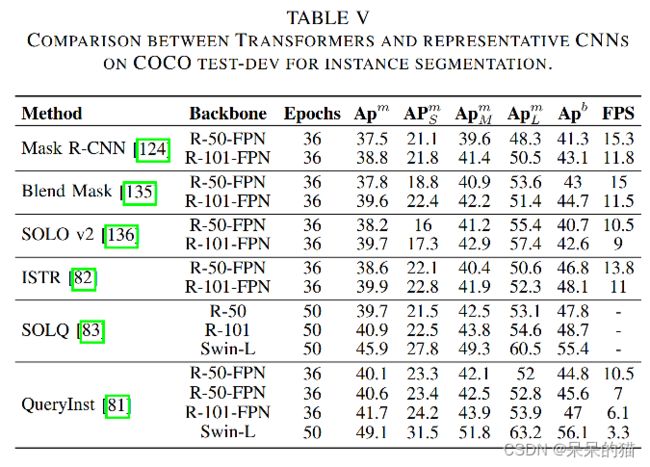
基于 Sparse RCNN 和 Cascade Mask RCNN 的更新策略,QueryInst 根据前面 stage queries 和当前 stage 的 box 来预测 mask。dynamic mask head 可以并行的训练来促进检测和分割任务的交互。此外,query embedding 和 MSA 共享,来相互促进两个子任务的效果。QueryInst 在 Swin 的基础上,获得了 COCO 实例分割任务的 SOTA。
5.2.2 Transformer with Mask Embeddings
另外一种方法是直接使用 query 来预测 mask,这种学习 mask-based query 的方法被称为 mask embedding。不同于 object query,mask embedding 仅仅被分割任务监督。如图 13d,两个分开的 query 集合被并行的用于不同的任务。对于语义分割和 box-free 的框架,有一些方法是移除了 object query,直接通过 mask embedding 来预测 mask。
1、ISTR&SOLQ
为了直接使用 2D mask label 来监督 1D 序列输出,ISTR[82] 在实例分割中使用了一个 mask 预编码的方法将 mask label 编码为低维 mask embedding。类似 ISTR,Dong 等人提出更简单的框架 SOLQ[83],并且为 mask embedding 探索了三种可逆的压缩编码方式(Sparse Coding,PCA,DCT)。
也就是使用一系列统一的 queries 并行的执行多种特征学习:分类、检测、mask encoding。基于原始的 DETR 检测头,SOLQ 添加了一个 mask branch (MLP)来产生 mask embedding loss。
ISTR 和 SOLQ 都获得了类似的结果并且超越之前的方法,但是这两种方法也导致了 A P b o x AP^{box} APbox 和 A P s e g AP^{seg} APseg 的较大差距,需要进一步探索。
2、Max-Deeplab:
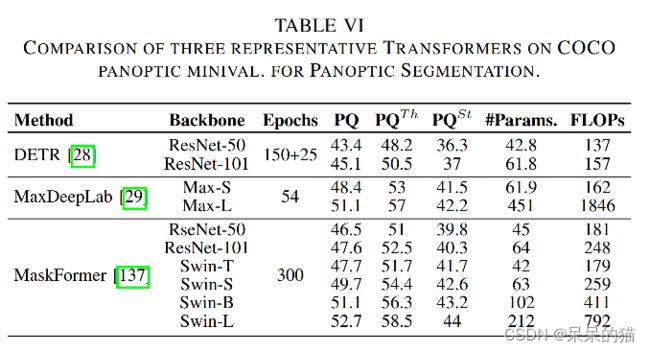
受端到端 Transformer 检测器[28] 的启发,Wang 等人提出了 Max-DeepLab[29],也是第一个 query-based 端到端的全景分割 Transformer 结构。 Max-DeepLab 直接通过 PQ-style 双边 matching loss 和一个双路 Transformer 结构来产生一系列独一无二的 labeled-mask 预测。给定一系列 mask embedding 和一个图像作为输入, Max-DeepLab 分别使用 memory 和 CNN path 对其进行处理,然后预测 non-labeled mask(使用 FFN)和对应的 label (使用叉乘)。该端到端的 box-free 结构在 COCO test 集上达到了 51.3% PQ。但由于其辅助 loss 和双路结构,导致计算量很大,尤其是高分辨率输入时。
Segmenter:
Strudel 等人提出了一个 convolution-free 模型——Segmenter[84],该方法将语义分割任务看成一个序列到序列的任务。在 Segmenter 中,pre-trained Transformer backbone 已经聚合了不同 patches 之间的关系,mask embedding 也被分配给每个类别,然后和 patches 一起送入 encoder 中,然后对 embedding 和 patches 使用标量相乘的方法来预测得到每个 patch 的 labeled-mask。Segmenter 当时也是超越了 CNN 在语义分割数据集上的效果。
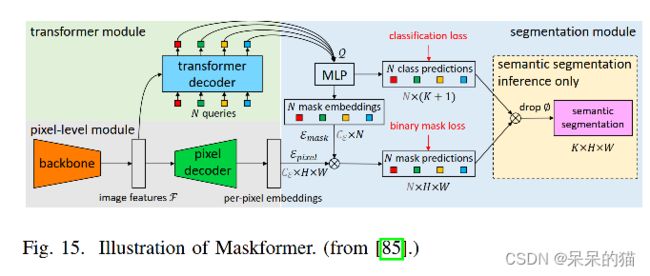
3、Maskformer:
不同于主流的语义分割方法一般是在像素级别来预测 mask,Cheng 等人将语义分割任务看做一个预测 mask 的问题。
也就是使用并行的 Transformer-CNN decoder 来分别处理 mask embedding 和 per-pixel features。之后,通过使用点乘和 sigmoid,使得模型预测一系列的重叠的二值 mask。
在推理的时候,使用矩阵相乘来将其进行结合并生成最终的预测(图15)。MaskFormer 在语义分割(55.6 mIoU on ADE20K)和全景分割任务(52.7 PQ on COCO)都取得了 SOTA 的效果。
5.3 讨论
作为一个基础但又挑战的任务,分割也从 Transformer 中获得了很好的效果。
表四在 ADE20K (170类)上对比了语义分割任务。可以看出 Transformer 在大类别数据集上的表现优于小类别数据集。
表五对比了 COCO 2017 的实例分割任务。Transformer with mask embedding 比之前的方法在分割和检测任务上的表现都好。且在 box 准确率上带来了好大的提升,在分割上带来的较小的提升,所以导致了 A P b o x AP^{box} APbox 和 A P s e g AP^{seg} APseg 的较大差距。
基于级联结构,QueryInst 获得了 SOTA 效果。
表六对比了全景分割。Max-DeepLab 能够通过 mask prediction 方法较好地解决全景分割任务的前景和背景,Maskformer 通过在语义分割上使用这种方式,并且统一了语义和实例层面的分割任务。
所以,Transformer 能够通过 mask prediction 的方式来将多种分割任务统一到 box-free 框架中。
六、总结
6.1 Summary of Recent Improvements
1、对于分类问题,深度层级的 Transformer backbone 可以有效减少计算复杂度,并且避免深层中的特征过平滑。
浅层 convolution 能够捕捉低层特征,这些特征能够增强鲁棒性并且降低浅层的计算复杂度。
卷积映射和局部 attention 两个方法都能够提高 Transformer 的定位能力。且卷积映射[48,49] 可以作为新的方法来代替位置编码
2、对于检测问题,得益于 encoder-decoder 的结构,Transformer necks 的计算量比 encoder-only detector 要少很多。所以,decoder 是必须的,但也不能堆叠太多,否则会造成收敛缓慢[71,72]。
此外,sparse attention 有益于减少计算复杂度且能够加速收敛的。
3、对于分割问题,encoder-decoder 的结构能够将三种不同的分割任务进行统一,通过 mask embedding 来统一成一个 mask 预测的问题[29,84,137]。这种 box-free 的方式在多个数据集上都达到了 SOTA。且 box-based 的 Transformer 混合任务的级联模型也被证明了能够在实例分割中获得好的效果。
6.2 Discussion on Visual Transformer
尽管现在的 Transformer 已经出现了很多不同的模型,但被认为最主要的问题还是效率低下。
1、How Transformer Bridge The Gap Between Language and Vision
在语言模型中,句子中的每个单词都可以被看做最小单元,最终来表示高层(高维)的语义信息。在视觉任务中,每个像素其实是低维的语义信息,但不能和嵌入特征匹配。
所以,关键的地方在建立一个 image-to-vector的转换,并且保持图像特征。
如,ViT 将图像的低维信息直接转换为 patch embedding。
Early Conv[50] 和 CoAtNet[37] 使用卷积来提取高维特征作为 patch,减少了一些冗余。
2、The Relationship Between Transformer,Self-attention,CNN
**卷积:**卷积具有很强的偏置归纳能力,如位置/平移不变性,权重共享、稀疏连接等等。虽然卷积的操作比较简单,但也有比较低的上限。
**自注意力:**当给定足够多的 heads 时,自注意力机制能够表达任何卷积层。这种 fully-attentional 操作可以有选择的结合高层和低层特征,并且根据特征之间的关系来动态生成 attention map。但计算量较大,且上限低于 CNN。
Transformer: Dong 等人证明,当训练没有残差连接或 FFN 的深度层时,self-attention 层会对 “token uniformity” 表现出强烈的归纳偏置。
这也表示了 Transformer 由两个主要的部分构成:self-attention 模块(聚合token的关系)和 position-wise FFN(抽取输入的特征)。
尽管 Transformer 有较强的全局建模能力,但卷积能够高效的处理低层特征,并且强化 Transformer 的定位能力,并且通过 padding 来引入位置特征。
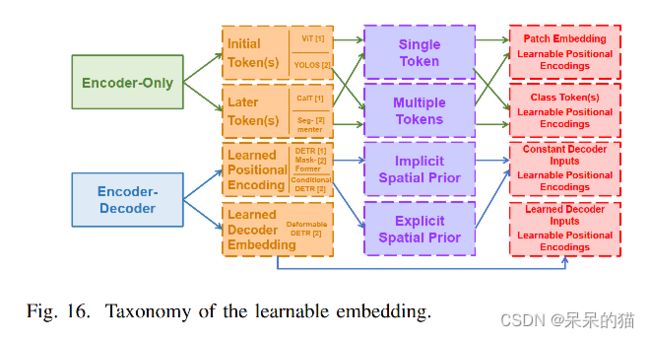
6.3 Learnable Embeddings in Different Visual Tasks
Transformer 模型使用可学习的 embedding 来实现不同的视觉任务。
从监督任务角度出发,这些 embedding 方式可以被分为三个类别:
- class token
- object query
- mask embedding。
结构上: 这三个类别的模型在结构上也有很大的联系,都是 encoder-only 或 encoder-decoder 模式,如图 16 所示。
位置上: 在 encoder-only Transformer 中的可学习 embedding 可以被分解为 initial token 和 later token。但学习 positional encoding 和 decoder input embedding 都在 encoder-decoder 结构中使用了。
数量上: encoder-only 的设计,使用了不同数量的 token。ViT 和 YOLOS 在初始层后面添加了不同数量的 token,CaiT 和 Sgementer 使用了一个 token 来表示最后几层的特征。
在encoder-decoder 结构中,decoder 的可学习位置编码(object query 或 mask embedding)是和 decoder 输入或直接或间接地联系在一起的。
受多头注意力机制的启发,多种初始化 token 的策略也被认为能够提高分类任务的效果。然而,DeiT 表明,这些 tokens 经过训练后,会收敛为相似的结果,并没有很大作用。
但 YOLOS 证明,使用多个初始化 token 能够将分类和检测任务进行统一化,但计算量会很大。CaiT 证明 later class token 能够降低 FLOPs 并带来一些提升(79.9%→80.5%)。Segmenter 也证明了该策略在分割上的效果。
Encoder-decoder 结构的 Transformer 通过使用 object query(mask embedding)标准化了检测和分割的结构。
通过结合多个 later token 和 object queries(mask embedding),统一了encoder-decoder Transformer 的不同任务的 learnable embedding。