【目标检测】47、Scaled-YOLOv4 | 能打败大佬的只有大佬自己!官方对 YOLOv4 的线性扩展

文章目录
-
- 一、背景
- 二、 方法
-
- 2.1 CSP-ized YOLOv4
- 2.2 YOLOv4-tiny
- 2.3 YOLOv4-large
- 三、效果
论文:Scaled-YOLOv4: Scaling Cross Stage Partial Network
代码:https://github.com/WongKinYiu/ScaledYOLOv4
作者:Chien-Yao Wang、Alexey AB
出处:CVPR2021
时间:2021.02
贡献:
- 讨论了线性扩大或线性缩小模型的上下限
- 分别分析了大模型和小模型在模型缩放上的重要事项,并得到了 YOLOv4-large 和 YOLOv4-tiny
- Scaled-YOLOv4 在速度和精度上取得了很好的平衡,在 COCO 测试集上达到了 56% AP
一、背景
Model scaling 方法,是通过修改模型的深度和宽度来使其适应不同的设备。如 ResNet 系列,ResNet-152 和 ResNet-101 一般被用于云端 GPU,ResNet-50 和 ResNet-34 一般被用于个人的 GPU,ResNet-18 和 ResNet-10 一般被用于嵌入式设备。
NAS 方法[34] 被提出用来对 EfficientNet-B0 进行 scaling,包括宽度、深度和分辨率,其使用原始的网络来搜寻到最优的合适的网络结构,EfficientNet-B1,然后使用线性 scale-up 方法来得到 EfficientNet-B2 到 EfficientNet-B7。
RegNet[27] 在很大的参数空间 AnyNet 中进行网络结构搜寻,设计了 RegNet,该结构发现了关于 CNN 的一些最优参数设计,如 CNN 的最优宽度为 60 等。
还有 SpineNet、EfficientDet 等方法是已通过 NAS 和 模型尺度缩放得到的针对目标检测设计的方法。
YOLOv4 的 backbone 为 CSPDarkNet53,也和很多模型缩放的结构相关,其 depth 为 65, bottleneck ratio 为 1,width growth ratio 为 2。
所以,Scaled-YOLOv4 是在 YOLOv4 的基础上使用了模型缩放的方法得到的,如图 1 所示。
具体探究过程为:基于 YOLOv4 → YOLOv4-CSP → scaled-YOLOv4
二、 方法
作者将 YOLOv4 经过尺度缩放,分别适用于:general GPU、low-end GPU、high-end GPU
2.1 CSP-ized YOLOv4
YOLOv4 是为在 general GPU 上运行的实时目标检测网络,作者又重新设计了一下,得到更好的 speed/accuracy trade-off 网络 YOLOv4-CSP
Backbone:
CSPDarknet53 的设计, cross-stage 的下采样卷积的计算是没有包含在残差块中的,故可以推理出 CSPDarknet 的计算量为 w h b 2 ( 9 / 4 + 3 / 4 + 5 k / 2 ) whb^2(9/4+3/4+5k/2) whb2(9/4+3/4+5k/2),所以 CSPDarknet stage 在 k>1 的时候的计算量是优于 Darknet 的,CSPDarknet53 的每个 stage 的残差层分别为 1-2-8-8-4,为了得到更好的 speed/accuracy trade-off,将 CSP 的第一个 stage 转换成原始的 Darknet 残差层。
Neck:
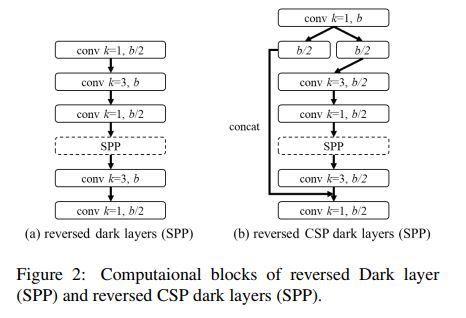
为了进一步降低计算量,也把 YOLOv4 中的 PAN 进一步 CSP-ize,PAN 结构的计算过程如图 2a 所示,它主要是整合来自不同特征金字塔的特征,然后经过两组反向 Darknet 残差层(没有 shortcut 连接),CSP-ization 之后的计算过程如图 2b 所示,降低了 40% 的计算量。
SPP:
SPP 模块也被嵌入 CSPPAN 的第一个 group 的中间位置
2.2 YOLOv4-tiny
YOLOv4-tiny 是为 low-end GPU 设计的,如图 3 所示

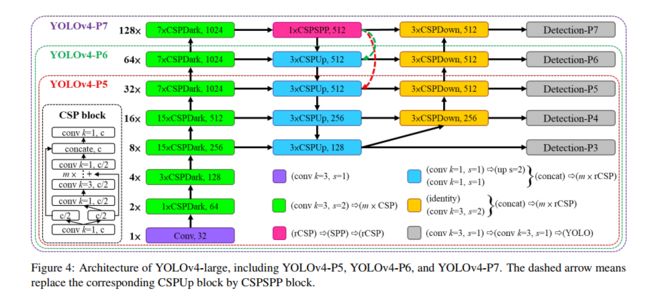
2.3 YOLOv4-large
YOLOv4-large 是为云端 GPU 设计的,为了实现高精度,设计了完整的 YOLOv4-P5,然后缩放得到 YOLOv4-P6 和 YOLOv4-P7,如图 4 所示。
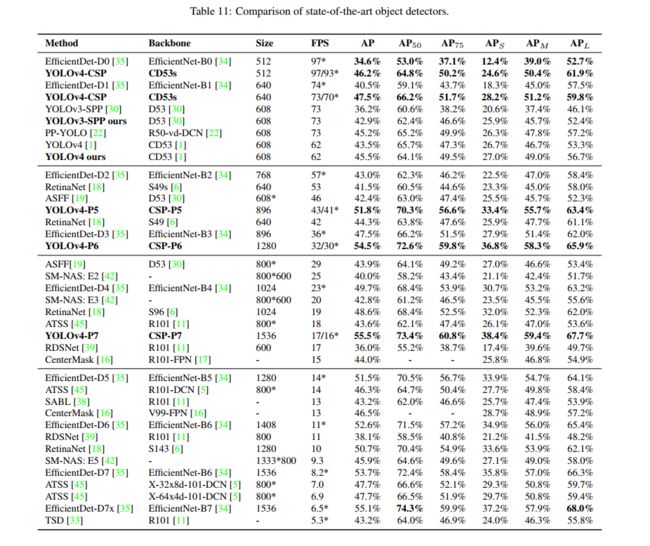
三、效果
1、CSP-ized 对参数量和效果的影响:可以减少约 32% 的计算量

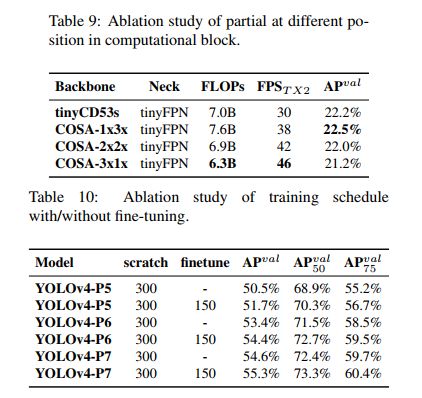
2、tiny (表 9)和 large(表10)模型的对比
3、和 SOTA 的对比