【目标检测】54、YOLO v7 | 又是 Alexey AB 大神!专为实时目标检测设计
文章目录
-
- 一、背景
- 二、方法
-
- 2.1 结构
- 2.2 Trainable bag-of-freebies
- 三、效果

论文:YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors
代码:https:// github.com/WongKinYiu/yolov7
出处:暂无
作者:Chien-Yao,Alexey AB (和 YOLOv4 同)
时间:2022.07
主要贡献如下:
- 专为实时目标检测器设计了一些 trainable bag-of-freebies 方法,在不带来额外推理消耗的情况下,很大的提升了检测效果
- 提出了两个问题:很好用的 re-parameterized 方法如何代替原来的模块;dynamic label assignment 方法应该如何处理分配到不同的输出层
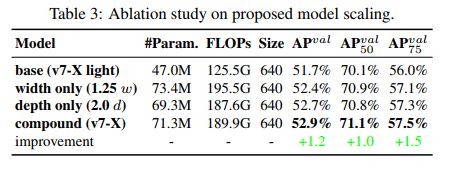
- 专为实时目标检测器提出了 extend 和 compound scaling 方法,可以促进实时方法有效的利用参数和计算
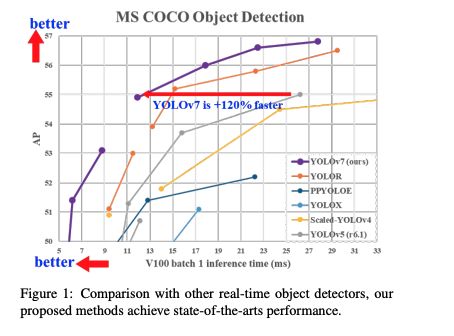
- YOLOv7 比 SOTA 方法减少了 40% 参数量,50% 计算量,且推理更快,效果更好
一、背景
本文还是从实时目标检测的角度出发,因为现在在边端设备部署深度学习模型的需求很强烈:
- MCUNet、NanoDet 探索了在边端 CPU 上的推理速度提升
- YOLOX、YOLOR 探索了在不同的 GPU 上的推理速度提升
- 还有一些方法探索了 efficient architecture
- MobileNet、ShuffleNet、GhostNet 研究了在 CPU 上能使用的结构
- 对 ResNet、DarkNet、DLA 等网络使用 CSPNet 方法优化架构后,获得了在 GPU 上能使用的结构
本文从哪个个方面入手来解决实时目标检测的问题呢? —— 提出 trainable bag-of-freebies 来优化训练过程
YOLOv7 从优化方法、优化模块等方面入手,通过提高训练过程的 cost 来提高检测效果,但不会提高推理过程的 cost。
YOLOv7 的思路是什么:
- 重参数化和 label assignment 对网络的效果都比较重要,但近来提出的方法中,或多或少会有些问题
- YOLOv7 会从发现的这些问题入手,并提出对应的解决方法
在正文前,YOLOv7 也总结了一下现有的 SOTA 实时目标检测器,大多基于 YOLO 和 FCOS,要想成为一个优秀的实时检测器,一般需要具有如下几个特点,并且主要从 4/5/6 三点来提出问题并解决:
- a faster and stronger network architecture
- a more effective feature integration method [22, 97, 37, 74, 59, 30, 9, 45]
- a more accurate detection method [76, 77, 69]
- a more robust loss function [96, 64, 6, 56, 95, 57]
- a more efficient label assignment method [99, 20, 17, 82, 42]
- a more efficient training method.
“结构重参数化” 的实质:训练时的结构对应一组参数,推理时我们想要的结构对应另一组参数,只要能把前者的参数等价转换为后者,就可以将前者的结构等价转换为后者。
二、方法
2.1 结构
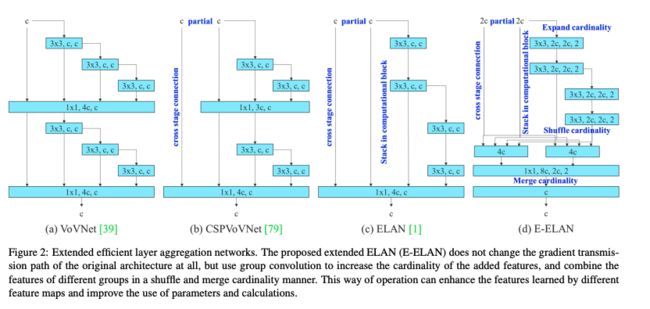
1、Expand efficient layer aggregation networks
一般为了设计高效的结构,会从参数量、计算量、计算复杂度的角度处理,或者输入- 输出通道数、点乘数量、模型尺度等。
CSPVoVNet(如图 2b)是 VoVNet 的变体,其为了让不同层的权重学习到更具有区分性的特征,分析了 gradient path。
ELAN(如图 2c)是考虑 “如何设计一个高效的网络?”,最后得出结论,通过控制梯度的最大最小路径,可以让深度网络收敛的很快。
所以,作者提出了 Extended-ELAN (E-ELAN),如图 2d 所示。
E-ELAN 使用了 expand、shuffle、merge cardinality 来实现对 ELAN 网络的增强,E-ELAN 仅仅改变了 computation block 的结构,transition layer 的结构没有改变。
具体是怎么实现的呢?
- 首先,使用 group convolution 来增大 channel 和 computation block(所有 computation block 使用的 group 参数及 channel multiplier 都相同)
- 接着,将 computation block 得到的特征图 shuffle 到 g g g 个 groups,然后 concat,这样一来,每个 group 中的特征图通道数和初始结构的通道数是相同的
- 最后,将 g g g 个 group 的特征都相加
2、Model scaling for concatenation-based models
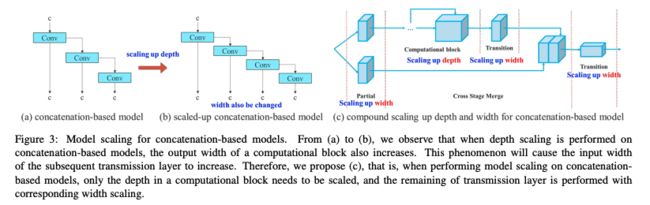
Model scaling 的主要目标是调整一下参数来实现对模型的缩放,让模型适应于不同的推理速度要求。Scaled-YOLOv4 就是调整了模型的 stage 数量等实现了模型尺度的缩放,一般使用 PlainNet 或 ResNet。
当这些架构在执行放大或缩小时,每一层的入度和出度都不会改变,因此我们可以独立分析每个缩放因子对参数量和计算量的影响。
然而,如果将这些方法应用到级联结构中,当对深度进行放大或缩小缩放时,宽度也会被改变,如图3 (a)和(b)所示。由此可知,对于级联结构,不能单独分析其宽度或深度的变化,只能联合分析。
以增加深度为例,就会改变 transition layer 的输入通道数,所以,作者考虑了宽度尺度因子,如图 3c 所示,本文提出的【混合缩放法】可以保证缩放前后模型的最优结构不被改变。
混合缩放法是怎么做的?
当对级联结构的网络进行尺度缩放时,只缩放 computational block 的深度,transmission layer 的其余部分只进行宽度的缩放。
2.2 Trainable bag-of-freebies
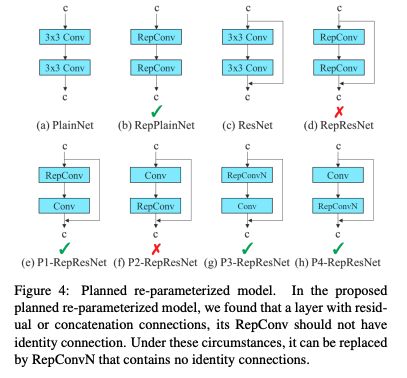
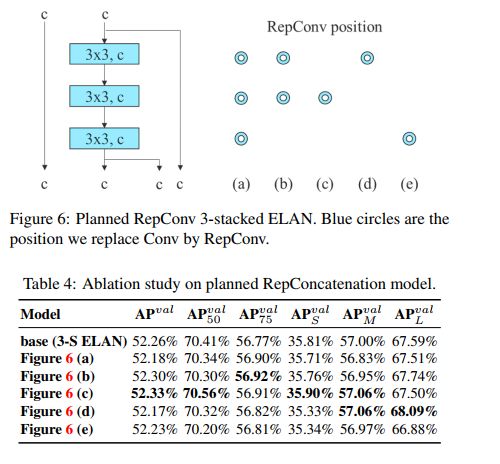
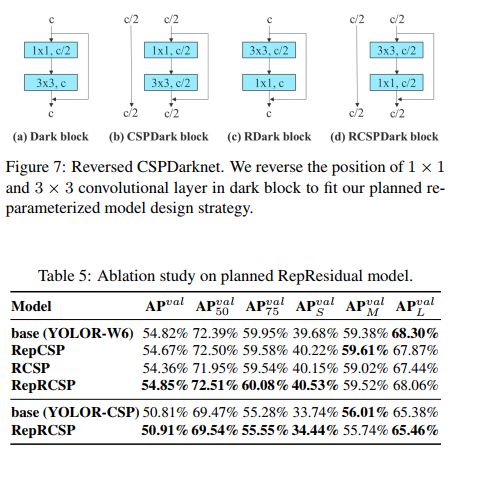
1、Planned re-parameterized convolution
尽管 RepVGG 中提出的 RepConv 比 VGG 效果好了很多,但当将这种结构用到 ResNet 或 DenseNet 时,效果反而会下降。
YOLOv7 作者通过 “分析重参数化卷积的梯度反向传播方式”,来探索了重参数化卷积的结构要如何和其他网络进行结合。
首先回顾一下 RepConv 是怎么做的?
RepConv 其实是将 3x3 卷积、1x1 卷积、恒等映射合成了一个卷积,经过将 RepConv 和其他结构结合后,作者发现,RepConv 影响了 ResNet 中的残差结构,影响了 DenseNet 中的级联结构。
所以,作者使用没有恒等映射的 RepConv(RepConvN)来 planned re-parameterized convolution,并在 PlainNet 和 ResNet 中使用,如图 4 所示。
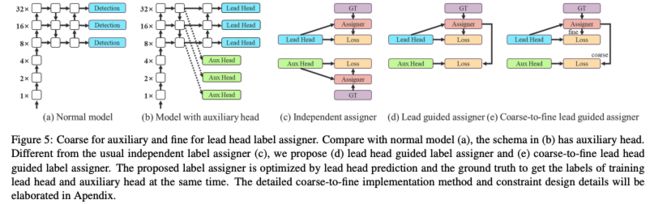
2、Coarse for auxiliary and fine for lead loss
Deep supervision 一般被用于训练深层的网络,主要是通过在中间从增加额外的 auxiliary head 来实现,浅层网络的全是是用该辅助 loss 来训练的。
ResNet 和 DenseNet 其实收敛的已经比较好了,但使用 Deep supervision 仍然恩公提升效果,如图 5a 和 5b 分别展示了 无/有 deep supervision 的结构。
其中:
- Lead head:负责最终输出的 head
- Auxiliary head:负责辅助训练的 head
确定了监督方式后,作者又讨论了 label assignment,对于单阶段检测器,为了实现更好的效果,一般会使用预测结果的 quality 或 distribution 作为参考,然后和 gt 进行结合,生成 soft label( autoassign、atss、IoU score、OTA 、TOOD 等),如 YOLOv1 中使用预测和真值的 IoU 作为 objectness 的 soft label。
那么作者就提问了:如何分别给 auxiliary head 和 lead head 分别分配 soft label 呢?
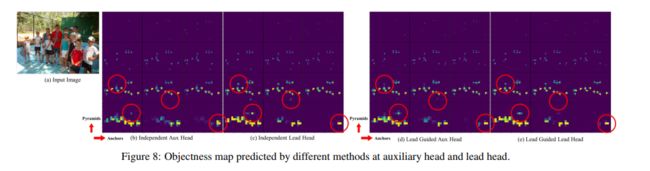
现有的方法如图 5c,将两个 head 分开,然后使用各自的检测结果和 gt 来进行 label assignment。
本文作者提出了一个新的方法,使用 lead head prediction 来同事指导 auxiliary head 和 lead head,也就是使用 lead head 结果作为指导,来生成 coarse-to-fine hierarchical labels,这个 label 用于两个 head 的学习,如图 5d 和 5e 所示。
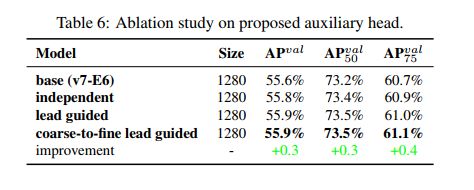
Lead head guided label assigner:
主要基于 lead head 的预测和 gt 来计算,并通过优化过程来生成 soft label,该 soft label 同时充当两个 head 的学习目标,这样做的原因在于, lead head 的学习能力更强一些,其输出更能表达特征,让中间特征以 lead head 的输出作为学习目标还有一个好处,就是 lead head 能够只学习 auxiliary head 没有学习到的特征。
Coarse-to-fine lead head guided label assigner:
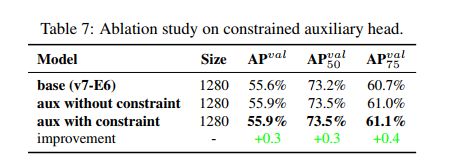
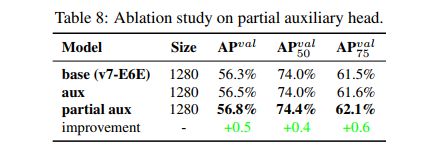
在生成 fine label 和 coarse label 时,fine label 和 lead head assinger 生成的 soft label 是相同的,coarse label 是通过放宽认定 positive targe 的条件来生成的,也就是会将更多 grids 看做 positive target。这样做的原因在于 auxiliary head 的学习能力没有 lead head 强,为了避免信息丢失,需要接收更多的信息来学习,在目标检测任务中,auxiliary head 需要有很高的 recall。
Lead head 的输出,首先过滤一下,保留 high precision 的结果
此外,为了让 coarse positive grids 影响小一些,在 decoder 中设置了限制条件,所以那些 coarse positive grids 不能很好的产生 soft label,这样就能在训练的过程中,让网络自动的调节 fine label 和 coarse label 的重要程度。
其他 BoF:
- Batch normalization in conv-bn-activation topology
- Implicit knowledge in YOLOR
- EMA model
三、效果
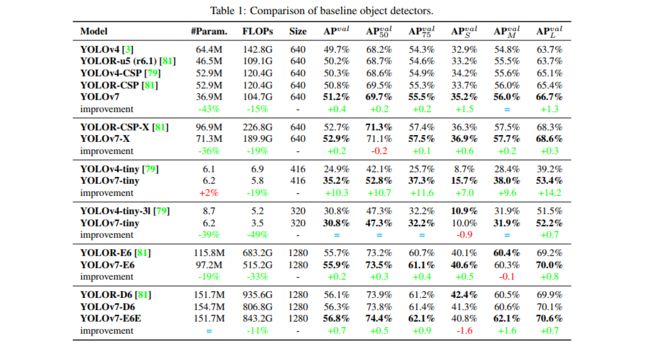
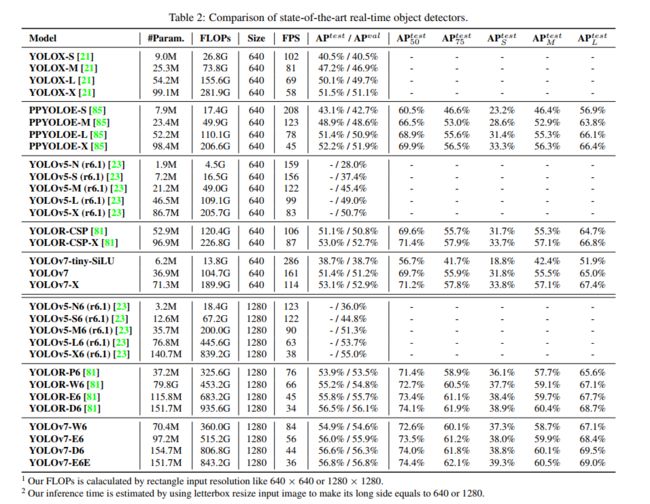
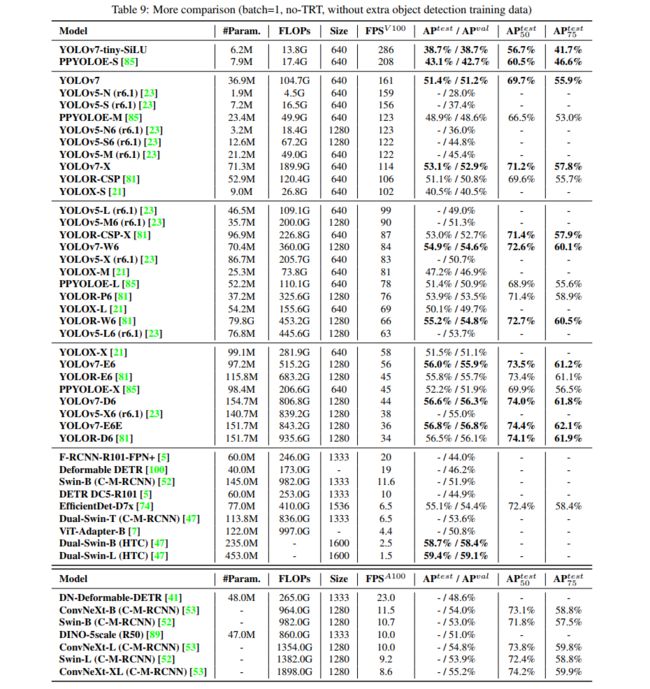
作者以 YOLOv4/scaled-YOLOv4 和当时的 SOTA YOLOR 作为 baseline