DenseNet网络结构详解及代码复现
1. DenseNet论文详解
Abstract:
如果在靠近输入和靠近输出层之间包含更短的连接,那么卷积神经网络可以很大程度上更深,更准确和高效地进行训练。根据这一结果,我们提出了DenseNet(密集卷积网络): 对于每一层,所有前一层地特征图作为输入,而这一层地特征图用作所有后续层地输入。优势有:缓解了梯度消失问题,加强了特征传播,鼓励特征复用,并很大程度上减小了参数的数量。
1.1. Introduction
随着卷积神经网络的不断加深,出现了一个问题——关于输入或梯度在经过很多层到达网络的终点(或起点)时,它可能会消失。对于此问题的解决方法:
- ResNet和Highway Networks通过
identity connection将信号从一层绕传到另一层 - Stochastic depth在训练期间随机掉落层来缩短ResNet,以允许更好的信息和梯度流动
- FractalNets重复组合多个具有不同数量卷积块的平行层序列,以获得较大的标称深度,同时在网络中保持许多短路径
这些方法都有一个共同点:创建了从早期层到后期层的短路径
为了确保网络中各层之间最大的信息流,我们将所有层直接连接到彼此。为了保持前馈性质,每一层都从所有前面的层获得额外的输入,并将自己的特性映射传递给所有后续层。与resnet相比,我们从来没有在将特性传递到一个层之前通过累加来组合它们,相反,我们通过特征连接来组合它们。我们将此方法称为DenseNet
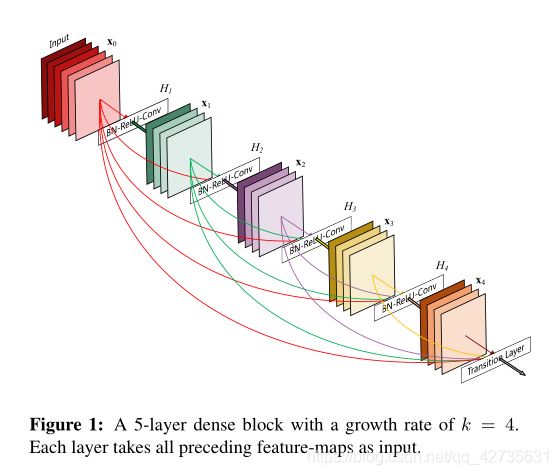
DenseNet的优势:
- 改进了信息和梯度的流动,使得易于训练
- 密集连接具有正则化效益,减少了训练集规模较小的过拟合问题
1.2. DenseNets
1.2.1 Compare nets
- Traditional nets: x l = H l ( x l − 1 ) x_l=H_l(x_{l-1}) xl=Hl(xl−1)
- ResNets: x l = H l ( x l − 1 ) + x l − 1 x_l=H_l(x_{l-1}) + x_{l-1} xl=Hl(xl−1)+xl−1
- DenseNets: x l = H l ( [ x 0 , x 1 , … , x l − 1 ] ) x_l=H_l([x_0,x_1,\dots,x_{l-1}]) xl=Hl([x0,x1,…,xl−1])
参数说明:
- x 0 x_0 x0:卷积网络得输入的单个图像
- 此网络有 L L L层,每一层实现一个非线性变换 H l H_l Hl,其中 l l l表示第 l l l层
- x l x_l xl:第 l l l层的输出
1.2.2 Architecture of net
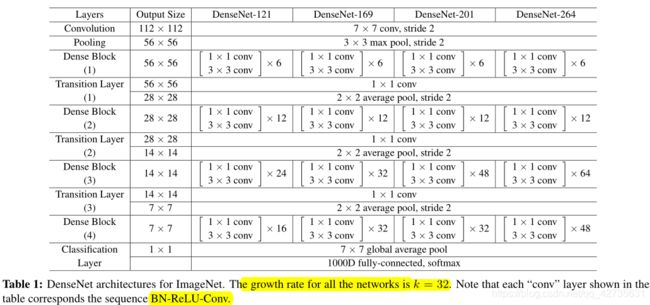
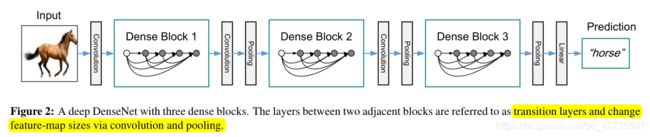
Composite function:定义为3个连续操作的复合函数
BN:batch normalizationReLU:rectified linear unitConv:convolution
Pooling layers
当feature-map的大小发生改变时, x l = H l ( [ x 0 , x 1 , … , x l − 1 ] ) x_l=H_l([x_0,x_1,\dots,x_{l-1}]) xl=Hl([x0,x1,…,xl−1])中的拼接操作是不可行的,需要通过下采样层来改变feature-map的大小,下采样层的组成为:
- BN层
- 1x1卷积层
- 平均层化层
Growth rate
如果每个函数 H l H_l Hl产生 k k k个feature-maps,那么可以得出第 l l l层有 k 0 + k ⋅ ( l − 1 ) k_0+k \cdot (l-1) k0+k⋅(l−1)个输入feature-maps,其中 k 0 k_0 k0是输入层的通道数,我们将k作为网络的growth rate。从表1,可知growth rate为32
Bottleneck layers
虽然每一层只产生 k k k个feature-maps,但是由于输入很多,我们需要在每一次3x3卷积之前引入一个1x1卷积以减少feature-maps的数量,从而减小参数并提高效率,在实验中,我们发现这种设计对DenseNet很有效,我们让每个1x1卷积产生 4 k 4k 4k个特征图,这样我们的函数 H l H_l Hl为:
BNReLUConv(1x1)BNReLUConv(3x3)
Compression
为了进一步提高模型紧凑型,我们可以减少transition layer输出的特征图数量。如果dense block包含m个特征图,我们让dense block后的transition latyer生成 ⌊ θ m ⌋ \lfloor \theta m\rfloor ⌊θm⌋个特征图,其中 θ \theta θ为压缩因子,在我们的实验中设置 θ = 0.5 \theta=0.5 θ=0.5
Implementation Details
- 在进入第一个
dense block时,对输入图像进行16(或为growth rate两倍)输出通道的卷积 - 对于
3x3卷积,输入的四周用一个像素填充0,以保证feature-map的大小不变 - 使用
1x1卷积,然后使用2x2平均池化作为两个dense block的过渡层 - 在最后一个
dense block的末端,执行一个全局平均池化,然后加一个softmax分类器
2. 基于Pytorch代码复现
2.1 模型搭建
import torch.nn as nn
import torch
from torchvision import models
class _DenseLayer(nn.Module):
def __init__(self, num_input_features, growth_rate, bn_size, drop_rate=0):
super(_DenseLayer, self).__init__()
self.drop_rate = drop_rate
self.dense_layer = nn.Sequential(
nn.BatchNorm2d(num_input_features),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=num_input_features, out_channels=bn_size * growth_rate, kernel_size=1, stride=1, padding=0, bias=False),
nn.BatchNorm2d(bn_size * growth_rate),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=bn_size * growth_rate, out_channels=growth_rate, kernel_size=3, stride=1, padding=1, bias=False)
)
self.dropout = nn.Dropout(p=self.drop_rate)
def forward(self, x):
y = self.dense_layer(x)
if self.drop_rate > 0:
y = self.dropout(y)
return torch.cat([x, y], dim=1)
class _DenseBlock(nn.Module):
def __init__(self, num_layers, num_input_features, bn_size, growth_rate, drop_rate=0):
super(_DenseBlock, self).__init__()
layers = []
for i in range(num_layers):
layers.append(_DenseLayer(num_input_features + i * growth_rate, growth_rate, bn_size, drop_rate))
self.layers = nn.Sequential(*layers)
def forward(self, x):
return self.layers(x)
class _TransitionLayer(nn.Module):
def __init__(self, num_input_features, num_output_features):
super(_TransitionLayer, self).__init__()
self.transition_layer = nn.Sequential(
nn.BatchNorm2d(num_input_features),
nn.ReLU(inplace=True),
nn.Conv2d(in_channels=num_input_features, out_channels=num_output_features, kernel_size=1, stride=1, padding=0, bias=False),
nn.AvgPool2d(kernel_size=2, stride=2)
)
def forward(self, x):
return self.transition_layer(x)
class DenseNet(nn.Module):
def __init__(self, num_init_features=64, growth_rate=32, blocks=(6, 12, 24, 16), bn_size=4, drop_rate=0, num_classes=1000):
super(DenseNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(in_channels=3, out_channels=num_init_features, kernel_size=7, stride=2, padding=3, bias=False),
nn.BatchNorm2d(num_init_features),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
)
num_features = num_init_features
self.layer1 = _DenseBlock(num_layers=blocks[0], num_input_features=num_features, growth_rate=growth_rate, bn_size=bn_size, drop_rate=drop_rate)
num_features = num_features + blocks[0] * growth_rate
self.transtion1 = _TransitionLayer(num_input_features=num_features, num_output_features=num_features // 2)
num_features = num_features // 2
self.layer2 = _DenseBlock(num_layers=blocks[1], num_input_features=num_features, growth_rate=growth_rate, bn_size=bn_size, drop_rate=drop_rate)
num_features = num_features + blocks[1] * growth_rate
self.transtion2 = _TransitionLayer(num_input_features=num_features, num_output_features=num_features // 2)
num_features = num_features // 2
self.layer3 = _DenseBlock(num_layers=blocks[2], num_input_features=num_features, growth_rate=growth_rate, bn_size=bn_size, drop_rate=drop_rate)
num_features = num_features + blocks[2] * growth_rate
self.transtion3 = _TransitionLayer(num_input_features=num_features, num_output_features=num_features // 2)
num_features = num_features // 2
self.layer4 = _DenseBlock(num_layers=blocks[3], num_input_features=num_features, growth_rate=growth_rate, bn_size=bn_size, drop_rate=drop_rate)
num_features = num_features + blocks[3] * growth_rate
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(num_features, num_classes)
def forward(self, x):
x = self.features(x)
x = self.layer1(x)
x = self.transtion1(x)
x = self.layer2(x)
x = self.transtion2(x)
x = self.layer3(x)
x = self.transtion3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, start_dim=1)
x = self.fc(x)
return x
def DenseNet121(num_classes):
return DenseNet(blocks=(6, 12, 24, 16), num_classes=num_classes)
def DenseNet169(num_classes):
return DenseNet(blocks=(6, 12, 32, 32), num_classes=num_classes)
def DenseNet201(num_classes):
return DenseNet(blocks=(6, 12, 48, 32), num_classes=num_classes)
def DenseNet264(num_classes):
return DenseNet(blocks=(6, 12, 64, 48), num_classes=num_classes)
def read_densenet121():
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = models.densenet121(pretrained=True)
model.to(device)
print(model)
def get_densenet121(flag, num_classes):
if flag:
net = models.densenet121(pretrained=True)
num_input = net.classifier.in_features
net.classifier = nn.Linear(num_input, num_classes)
else:
net = DenseNet121(num_classes)
return net
2.2 训练结果如下
- 训练数据集与验证集大小以及训练参数
Using 3306 images for training, 364 images for validation
Using cuda GeForce RTX 2060 device for training
lr: 0.0001
batch_size: 16
- 使用自己定义的网络训练结果
[epoch 1/10] train_loss: 1.209 val_acc: 0.626
[epoch 2/10] train_loss: 1.035 val_acc: 0.588
[epoch 3/10] train_loss: 0.980 val_acc: 0.679
[epoch 4/10] train_loss: 0.902 val_acc: 0.670
[epoch 5/10] train_loss: 0.838 val_acc: 0.698
[epoch 6/10] train_loss: 0.805 val_acc: 0.712
[epoch 7/10] train_loss: 0.825 val_acc: 0.717
[epoch 8/10] train_loss: 0.765 val_acc: 0.742
[epoch 9/10] train_loss: 0.759 val_acc: 0.755
[epoch 10/10] train_loss: 0.732 val_acc: 0.687
Best acc: 0.755
Finished Training
Train 耗时为:440.4s
- 使用预训练模型参数训练结果
[epoch 1/10] train_loss: 0.505 val_acc: 0.909
[epoch 2/10] train_loss: 0.306 val_acc: 0.931
[epoch 3/10] train_loss: 0.240 val_acc: 0.920
[epoch 4/10] train_loss: 0.209 val_acc: 0.898
[epoch 5/10] train_loss: 0.191 val_acc: 0.931
[epoch 6/10] train_loss: 0.198 val_acc: 0.918
[epoch 7/10] train_loss: 0.152 val_acc: 0.940
[epoch 8/10] train_loss: 0.157 val_acc: 0.929
[epoch 9/10] train_loss: 0.143 val_acc: 0.940
[epoch 10/10] train_loss: 0.150 val_acc: 0.923
Best acc: 0.940
Finished Training
Train 耗时为:478.8s
上一篇:ResNet
下一篇:Mobile Net 系列
完整代码