OpenPAI调研手册
OpenPAI调研
OpenPAI 是一个提供完整的 AI 模型训练和资源管理能力的开源平台。OpenPAI 支持各种规模的本地环境、云环境和混合环境,并且可以根据用户需求定制和扩展平台,使用户和管 理员可以更轻松地完成日常 AI 任务。
1.1 OpenPAI 架构
OpenPAI 的主要设计目标是促进多用户进行全流程 AI 开发,并为此引入了支持多用户共享模型和数据的 Marketplace,v0.14.0 及以前的版本框架由 Kubernetes、Hadoop、Yarn 组成,v1.0.0 及以后的版本框架由 Kubernetes 统一管理,v1.0.0 的架构如图 1.1 所示。

1.2 OpenPAI安装手册
1.2.1 集群规划
根据OpenPAI手册要求,至少需要三台机器用于构建集群。下面以三台机器的配置为例,介绍OpenPAI的安装部署过程,三台机器的作用及地址示例如表1.1所示。

此外,OpenPAI项目文档建议系统为Ubuntu 16.04 LTS,但是Ubuntu 18.04也是可以的;其次,master和worker必须为物理机器(如果是虚拟机需要考虑显卡直通虚拟机,不适合生产环境),dev可以是硬盘空间不少于40G的虚拟机(只在安装、维护系统时使用,不必浪费物理机资源);最后,由于kubernetes不支持swap,安装系统时不可添加swap分区,否则重启时节点会挂掉。
1.2.2 基础环境准备
(1)网络设置:根据集群规划过程中的IP地址对集群网络进行设置,主要包括ip地址、子网掩码、网关、dns名称服务器的设置,设置完网络后使用restart命令刷新,使得三台机器可在同一局域网内相互访问。
(2)远程访问设置:首先为每台机器安装openssh-server,随后配置ssh允许root权限的用户登录,最后启动ssh进行访问。
(3)安装Docker:由于OpenPAI是基于kubernetes实现容器集群管理系统的,所以先要在没一台机器上安装Docker容器。首先,需要对操作系统的配置进行更新;随后,执行安装Docker的命令;最后,安装nvidia-container-runtime,并添加阿里云镜像源地址。
(4)配置主节点master:只需在已有基础上,单独在主节点机器上配置NTP。
1.2.3 安装OpenPAI
(1)克隆OpenPAI项目,选择需要安装的OpenPAI版本。
(2)配置config文件和layout文件:由于官方建议的配置方式中的gcr.azk8s.cn以及shaiictestblob01.blob.core.chinacloudapi.cn已经停止维护,所以需要使用阿里云的镜像和docker hub的镜像进行搭配来配置config;layout文件则根据硬件参数进行配置。
(3)安装、部署Kubernetes:直接执行安装脚本,控制台正常退出代表安装成功;部署完成后会出现config、ID、username等信息。
(4)浏览器中输入master节点ip即可使用OpenPAI进行开发。
1.3 OpenPAI基础管理
1.3.1 前端管理界面
Web portal提供了一些基本的管理功能,安装成功后如果以管理员身份登录,则可以在左侧栏上找到几个有关管理的按钮,如图1.2所示。

(1)服务界面:服务页面显示了Kubernetes中部署的OpenPAI服务。

(2)硬件利用界面:硬件页面显示集群中每个节点的CPU、GPU、内存、磁盘和网络的利用率,不同的利用率以不同的颜色显示,如果将鼠标悬停在这些彩色圆圈上,则页面会显示确切的利用率百分比。

(3)用户管理界面:用户管理界面用于创建、修改、删除用户,创建时可以选择管理员用户和非管理员用户两种用户类型。此页面仅在以基础认证模式(基础认证模式为默认的认证模式)部署OpenPAI时才显示,如果集群使用AAD来管理用户,则此页面不可用。
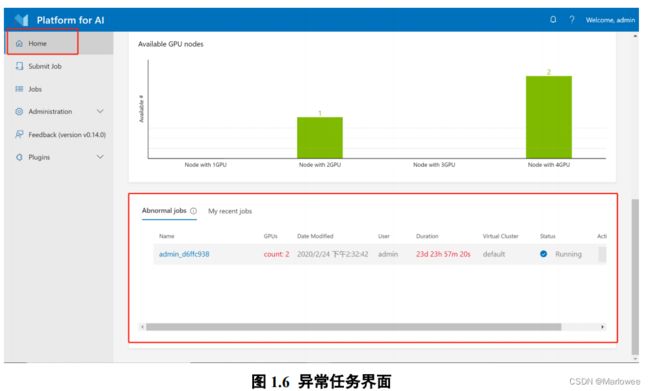
(4)任务异常界面:主页上为管理员提供了abnormal jobs部分。如果任务运行超过5天或GPU使用率低于10%,则将其视为异常任务,管理员可根据需要选择停止异常任务。
1.3.2 设置数据存储
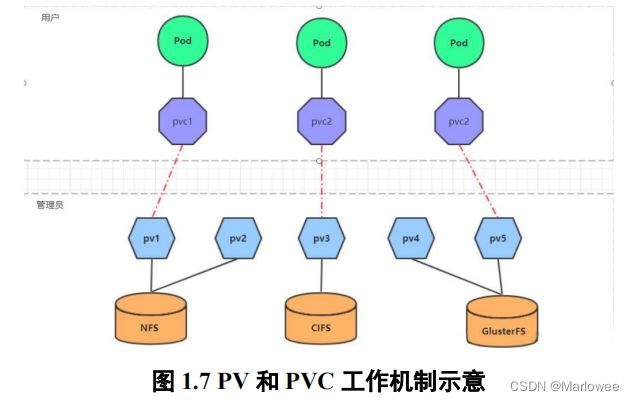
当前,存储数据的方式和种类有很多,为了方便的使用和管理,Kubernetes提出了PV和PVC的概念。PV(Persistent Volume)相当于磁盘分区,是对底层的共享存储的一种抽象;PVC(Persistent Volume Claim)则是用户向kubernetes系统发出的一种资源需求申请。在OpenPAI中,主要使用PV进行数据存储,存储过程遵循以下步骤:
(1)在Kubernetes上创建PV和PVC作为PAI存储。
(2)确认工作程序节点具有正确的环境。
(3)将PVC授权给特定的用户组。
1.3.3 设置虚拟集群
OpenPAI支持两种调度器:Kubernetes default scheduler和Hivedscheduler。
Hivedscheduler是一个用于深度学习的Kubernetes Scheduler。它支持虚拟集群划分、拓扑感知的资源保证、性能优化的Gang Scheduling,这些都是Kubernetes default scheduler不支持的。并且目前只有Hivedscheduler支持虚拟集群设置,Kubernetes default scheduler不支持。
假如我们有3个节点:worker1、worker2、worker3,它们都在 default 虚拟集群中。现在我们要创建两个虚拟集群:一个叫default,包含两个节点;另一个叫new,包含一个节点,那么可以这样配置GPU虚拟集群:
代码片段1.1:设置GPU虚拟集群
# services-configuration.yaml
...
hivedscheduler:
config: |
physicalCluster:
skuTypes:
DT:
gpu: 1
cpu: 5
memory: 56334Mi
cellTypes:
DT-NODE:
childCellType: DT
childCellNumber: 4
isNodeLevel: true
DT-NODE-POOL:
childCellType: DT-NODE
childCellNumber: 3
physicalCells:
- cellType: DT-NODE-POOL
cellChildren:
- cellAddress: worker1
- cellAddress: worker2
- cellAddress: worker3
virtualClusters:
default:
virtualCells:
- cellType: DT-NODE-POOL.DT-NODE
cellNumber: 3
...
如果添加CPU机器,OpenPAI手册建议直接设置一个纯 CPU 的虚拟集群,不要在一个虚拟集群中混合CPU节点和GPU节点
1.3.4 设置Docker镜像缓存
Docker镜像缓存在OpenPAI中的实现为docker-cache服务,可以帮助用户避免部署服务或用户提交任务超过限制时等待的问题。Docker镜像缓存被配置为一个以Azure Blob Storage 或Linux文件系统为存储后端的pull-through缓存。此外, 通过提供的docker-cache配置分发脚本,用户可以方便地使用自己的docker registry或者pull-through cache。
Docker 镜像缓存提供了三种使用方式:
(1)启动使用Azure Blob Storage作为存储后端的缓存服务:在安装时将config.yaml配置文件中的相关字段设置为Azure Blob Storage,并完成安装,如代码片段1.2所示。
代码片段1.2:设置Azure Blob Storage作为存储后端
enable_docker_cache: true
docker_cache_storage_backend: "azure"
docker_cache_azure_account_name: "forexample"
docker_cache_azure_account_key: "forexample"
(2)启动使用Linux文件系统作为存储后端的缓存服务:同理,将配置文件中的相关字段设置为Linux文件系统,并完成安转,如代码片段1.3所示。
代码片段1.3:设置Linux文件系统作为存储后端
enable_docker_cache: true
docker_cache_storage_backend: "filesystem"
# docker_cache_azure_account_name: ""
# docker_cache_azure_account_key: ""
# docker_cache_azure_container_name: "dockerregistry"
docker_cache_fs_mount_path: "/var/lib/registry"
(3)使用自定义的 registry:对于希望OpenPAI集群使用自定义的registry的用户,一个简单的方式是修改./contrib/kubespray/docker-cache-config-distribute.yml,该 playbook负责修改集群内每个节点的docker daemon配置。
在默认设置下,该playbook会添加kube-master节点的30500端口作为docker-cache service的入口,所以仅需要修改该文件中的 {{ hostvars[groups[‘kube-master’][0]][‘ip’] }}:30500为相应的:字符串即可使用自定义的registry,如代码片段1.4所示。
代码片段1.4:设置Linux文件系统作为存储后端
roles:
- role: '../roles/docker-cache/install'
vars:
enable_docker_cache: true
docker_cache_host: "{{ hostvars[groups['kube-master'][0]]['ip'] }}:30500"
tasks:
- name: Restart service docker config from /etc/docker/daemon.json after update
ansible.builtin.systemd:
name: docker