猿创征文|Python快速刷题网站——牛客网 数据分析篇(十六)
一个帅气的boy,你可以叫我Love And Program
⌨个人主页:Love And Program的个人主页
如果对你有帮助的话希望三连支持一下博主
前言
本文将继续学习pandas 中级函数 部分内容
大佬用户成就值比例
现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
牛客网有很多7级红名大佬这是众所周知的,小白希望知道这些大佬的成就值各自占据了所有人成就值总和的百分之多少,你能帮他吗?

输出描述:
第一列输出行好,第二列输出计算7级用户的成就值占所有人成就值总和的比例,以小数形式输出,小数位保留不用管。
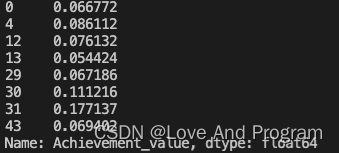
- 读题找出重点:计算7级用户的成就值占所有人成就值总和的比例
- 使用比值的思想
首先找到全部七级大佬们的成就值
data[data['Level'] == 7].Achievement_value
其次,在将其比一个所有人的成就值
data.Achievement_value.sum()
汇总代码如下:
import numpy as np
import pandas as pd
data= pd.DataFrame({
"Nowcoder_ID":[178372,989717,783650,723570,456568],
"Level":[7,1,2,6,7],
"Achievement_value":[8711,13,130,5666,11234],
"Num_of_exercise":[500,3,32,433,899],
"Graduate_year":[2017,2016,2010,2019,2017],
"Language":['CPP','Java',np.nan,'C','Python'],
"Continuous_check_in_days":[1230,10,45,564,1349],
"Number_of_submissions":[120,1,2,1,np.nan]
})
print(data[data['Level'] == 7].Achievement_value/data.Achievement_value.sum())

这里我们进接一下思路,使用函数式编程apply()函数解答,传入全部七级大佬们各自的成就值,使用lambda匿名函数搭建函数式,与上述结果一样:
print(data[data['Level'] == 7].Achievement_value.apply(lambda x:x/data['Achievement_value'].sum()))

最终代码整理如下:
DA21 大佬用户成就值比例
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',')
print(Nowcoder[Nowcoder['Level'] == 7].Achievement_value/Nowcoder.Achievement_value.sum())
# print(Nowcoder[Nowcoder['Level'] == 7].Achievement_value.apply(lambda x:x/Nowcoder['Achievement_value'].sum()))
用户最高的正确率
现有一个Nowcoder.csv文件,它记录了牛客网的部分用户数据,包含如下字段(字段与字段之间以逗号间隔):
牛客网有那么多刷题的用户,有的人身经百战,刷题无数但是反复提交了多次错误的代码debug之后才能通过,牛牛想知道牛客网最高的正确率能有多少,为了公平起见,他决定只统计刷题数量大于10题的用户,请你帮帮他。

输出描述:
直接输出计算的正确率(刷题量/代码提交次数),保留3位小数。
- 读题找出重点:最高的正确率能有多少、只统计刷题数量大于10题的用户
- 同样使用比值的思想,更加贴切与应用
找到在统计刷题数量大于10题条件下的刷题量与提交代码次数,即可完成题目要求:
import numpy as np
import pandas as pd
data= pd.DataFrame({
"Nowcoder_ID":[178372,989717,783650,723570,456568],
"Level":[7,1,2,6,7],
"Achievement_value":[8711,13,130,5666,11234],
"Num_of_exercise":[500,3,32,433,899],
"Graduate_year":[2017,2016,2010,2019,2017],
"Language":['CPP','Java',np.nan,'C','Python'],
"Continuous_check_in_days":[1230,10,45,564,1349],
"Number_of_submissions":[120,1,2,1,np.nan]
})
a = Nowcoder[Nowcoder['Num_of_exercise']>10].Num_of_exercise
b = Nowcoder[Nowcoder['Num_of_exercise']>10].Number_of_submissions
print((a/b).max().round(3))
或是使用另一种更为直观的方法,将刷题数量大于10题的用户单独做一个整体,结果与上述相似:
condition = data['Num_of_exercise'] > 10
right_rate = data[condition]['Num_of_exercise']/data[condition]['Number_of_submissions']
print('{:.3f}'.format(right_rate.max()))
最终代码整理如下:
DA22 牛客网用户最高的正确率
import pandas as pd
Nowcoder = pd.read_csv('Nowcoder.csv', sep=',')
# a = Nowcoder[Nowcoder['Num_of_exercise']>10].Num_of_exercise
# b = Nowcoder[Nowcoder['Num_of_exercise']>10].Number_of_submissions
# print((a/b).max().round(3))
cond = Nowcoder['Num_of_exercise'] > 10
right_rate = Nowcoder[cond]['Num_of_exercise']/Nowcoder[cond]['Number_of_submissions']
print('{:.3f}'.format(right_rate.max()))