欺诈检测相关论文
欺诈检测相关论文
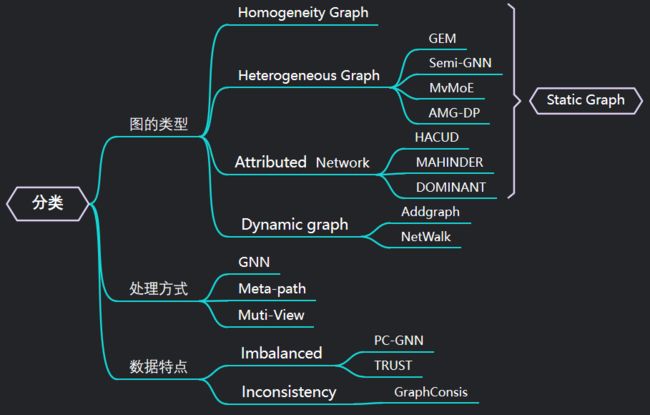
- 一、分类
-
- 1、GEM
- 2、HACUD
- 3、MAHINDER
- 4、Semi-GNN
- 5、MvMoE
- 6、AMG-DP
- 7、AddGraph
- 8、NetWalk
- 9、DOMINANT
- 10、GraphConsis
- 11、PC-GNN
- 12、TRUST
- 二、类别不平衡
一、分类
1、GEM

来自蚂蚁金服的论文,他们提出GEM模型,是一个异质图神经网络方法,用于支付宝中恶意账户的检测。数据量有4.5亿个用户。
作者从数据中总结了来自攻击者的两个主要特征:
1、攻击者要承受计算资源带来的成本,所以大多数攻击者只在少数计算资源上注册或频繁地登录。(x:设备id,y:账户id,左:正常,右:异常)
2、攻击者受攻击时间的限制,通常要在很短的时间内完成既定目标,所以恶意账户的行为可能在有限的时间内爆发。(x:时间,y:账户id,左:正常,右:异常)
异质图构建:
设备聚集:从不同设备角度(如ip地址,电话等)提取D个子图,每个子图都包含G中所有节点。
行为聚集:矩阵X=[N,p+|D|], 前p维 表示账户i行为,0~T时间划分p个时间段,每个时间段有一个行为次数,最后D为表示所属设备(子图)的one-hot编码
2、HACUD
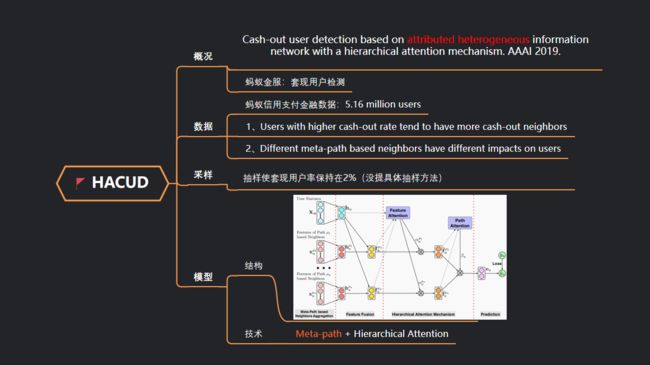

来自蚂蚁金服的论文,他们提出HACUD模型,将实际场景建模为属性异质信息网络。用于信用支付中套现用户的检测。数据量级5百万用户
数据:
三类节点:用户U、商家M、设备D,每个节点都有丰富的属性
两种元路径:UU(用户和用户有资金交易)、UMU(用户和用户有相同的交易商家)
作者从数据中观测到两个现象:
1、套现率高的用户往往有更多的套现邻居。这意味着用户的特征可以源于他们基于元路径的邻居的特征。
2、不同的基于元路径的邻居对用户有不同的影响。这意味着不同元路径对用户重要程度不同,可以用注意力机制去捕获。
模型:
初始数据是 用户属性 和 基于元路径的用户邻居属性。
然后使用分层注意力机制获得在邻居粒度和邻居类型层面的向量表示。
最后将用户表示送入分类器训练模型。
3、MAHINDER

来自阿里的论文,他们提出MAHINDER模型,将实际场景建模为多视图属性异质信息网络。用于信用支付中违约用户的检测。数据量189万用户
属性异质网络划分为三种视图:社交视图、资金视图、设备视图
作者从数据中观测到的现象:
1、不同视图下不同直接违约邻居数量下,违约者的概率和提升有明显差异。(说明1、用户的特征可以用邻居的特征来表示,2、不同的path重要性不同,使用attention机制进行捕获)
2、同一视图不同链接类型下,违约者的概率有明显差异。(所以对meta-path编码的时候,链接类型也进行了编码)
模型:
首先人工选取元路径;
其次使用LSTM建模元路径的细粒度语义;
最后使用注意力整合不同的元路径获取用户表示送入后续分类器。
4、Semi-GNN

来自蚂蚁金服的论文,他们提出Semi-GNN模型,将实际场景建模为异质图。用于花呗中欺诈用户的检测,是第一篇使用半监督图神经网络进行欺骗检测的论文。
作者收集了4百万个有label的用户,然后从有label的用户的一跳朋友/同学/同事 中采样没有label的用户,所以一共是1亿用户。
从关系(朋友/同学/同事)、app、昵称、地址四个角度分别构建视图。
数据现象: 欺诈常呈团伙聚集, 标注为负样本的用户, 其邻居节点也可疑.
基于上述假设, 受DeepWalk启发, 作者设计的无监督部分Loss希望:邻近节点的表示相似, 不同节点的表示差异较大。
模型:
模型分为两部分:监督学习部分(左)和无监督学习部分(右),两部分模型结构相同。
使用层次注意机制聚合视图内特征和视图间特征,得到用户表示。
监督学习:利用预测的标签和实际标签计算损失
无监督学习:利用邻近节点的表示相似, 不同节点的表示差异较大,来计算损失。
5、MvMoE

这篇是来自阿里的论文,他们提出MvMoE模型,将实际场景建模为多视图异构网络。在阿里电商数据上实验,是一个信用风险预测和信用限额设置的双任务模型。数据量544万用户
三种视图:user profiles、user sequential behaviors、user relationship
他们的数据不缺label,下个月就可以拿到这个月实验用户的label
采样: 对正样例向上采样,使正样例率在10%左右。(这里的正样例 就是 违约用户)
模型:
1、将异构多视图数据源,进行全面的用户建模。
2、分别采用多层感知器(MLP)、双向长短期记忆(BiLSTM)和图神经网络(GNN)对每个视图的特征进行编码。
3、使用层次注意机制按重要性聚合视图内特征和视图间特征。
4、使用视图感知专家混合结构,来捕获不同任务的更好的信息。
5、利用CRF任务的输出,根据财务先验知识,通过每个任务塔之间的渐进网络来引导CLS任务。
6、AMG-DP

来自蚂蚁金服的论文,他们提出AMG-DP模型,将实际场景建模为多重图。用于信用支付中还款拖欠用户的检测。每个月有150万用户,一共用了10个月的数据
数据中观测到两个现象:
1、不同关系为刻画违约用户提供了不同的角度(所以作者将多重图根据关系transfer/transaction/social/use划分为不同的视图,做聚合的时候把边也考虑了进来)
2、有更多违约邻居的用户更可能是违约用户(所以可以通过聚合邻居的特征来表示用户)
模型:
根据relation划分multi-view graph,
分别在multi-view graph上做GAT聚合,聚合包括两个点和两点之间的边的属性,
再对不同的关系做attention聚合,得到用户最终表示
最后预测用户的违约概率
7、AddGraph

来自阿里的论文,他们提出Addgraph模型,将实际场景建模为同质图动态图。在Digg数据集上进行异常边的检测,数据集包含3w节点、8w边
假设: 认为图中存在的边是正常的边,对不存在的边进行采样认为是异常边。
模型:
按时间段划分 t 个快照图
使用gcn学习快照图中每个节点的表示
快照节点表示序列通过attention得到short embedding
当前快照和最后一个快照表示得到current embedding
通过GRU整合short/current embedding得到最终每个节点表示
通过最大化正常边和异常边之间的margin来得到损失
8、NetWalk
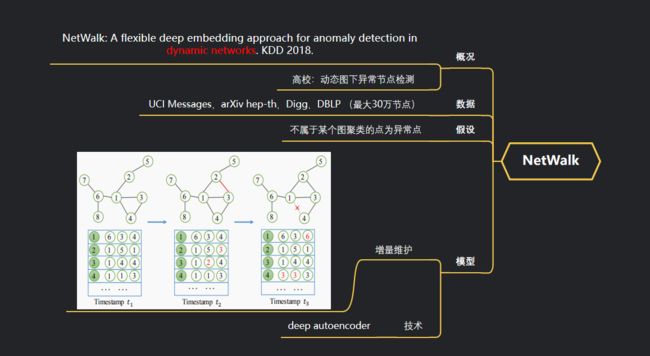
来自高校的论文,他们提出NetWalk模型,模型的主要思路是提出一种动态图embedding的方法,再用其节点表示进行异常检测。
作者在4个数据集上进行异常节点的检测,最大的数据集包含30w节点
假设:不属于某个图聚类的点为异常点
模型:
由网络中每个节点为起始节点,生成 walk
通过最小化每条walk的所有节点对距离和最小化自编码器的重构误差,来学习每个节点的向量表示。
通过聚类得到聚类中心点,计算新来的边/点到中心点的距离,来判断该边/点是否异常。
动态图 增量维护:
Network为每个顶点维持一个reservoir,存放的是对顶点邻居采样的集合,集合大小是固定的。
新来边的时候,针对里面的每个顶点,都会以概率p替换。删除边的时候只针对删除了的顶点进行替换。
然后,通过reservior去产生新的walk更新网络。
9、DOMINANT

来自高校的论文,他们提出DOMINANT模型,将实际场景建模为同质图,进行异常节点的检测。
数据:使用了三个数据集,最大数据集有1w个节点
假设:图重构过程中属性和结构信息丢失多的节点为异常节点
模型:
使用gcn对图中每个节点(带有属性)进行编码,
通过解码节点属性和图结构来学习图的结构和属性信息
最小化属性重构和结构重构的受损,得到每个用户的表示
对每个用户进行异常度打分 排序。
10、GraphConsis
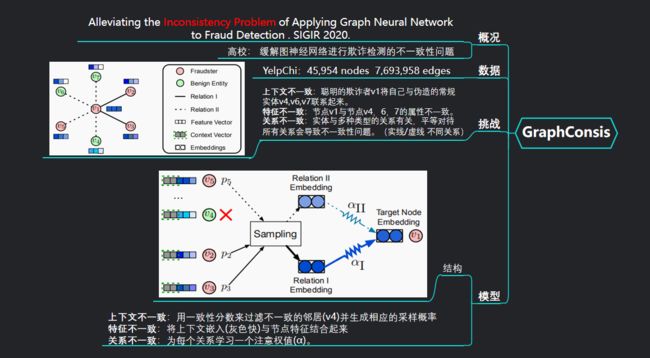
来自高校的论文,他们提出GraphConsis模型,将实际场景建模为同质图,主要用来缓解图神经网络进行欺诈检测时的不一致问题。
数据:在垃圾邮件评论数据集上进行实验,包含4w多用户和7百多万边。
不一致问题:
针对3个不一致的解决方法:
11、PC-GNN

这篇来自阿里的论文,他们提出PC-GNN模型,将实际场景建模为同质图,主要用来解决图神经网络进行欺诈检测时的类别不平衡问题。
数据:在垃圾邮件评论数据集上进行实验,包含4w多用户和3百多万边。
类别不平衡时,如果欺诈用户聚合的邻居中有大量正常节点,就会将欺诈用户隐藏。(和上篇论文中上下文不一致类似)
12、TRUST
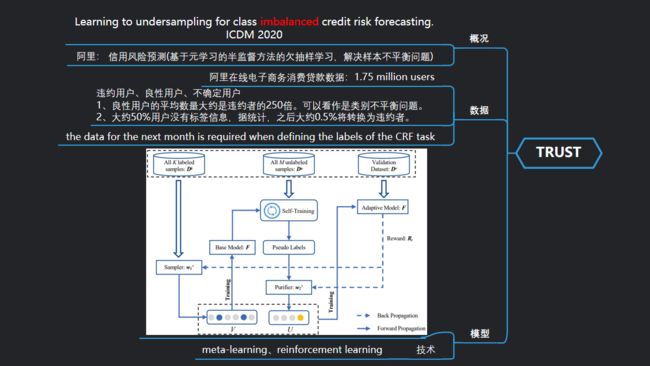
来自阿里的论文,他们提出TRUST模型,进行信用风险的预测,是一个基于元学习的半监督方法的欠抽样学习,可以解决样本不平衡问题。
数据:在阿里在线电子商务消费贷款数据上进行实验,有175万用户。
在该场景中,用户被分为3类,违约用户、良性用户、不确定用户(贷款了但还没到还款日期)
训练:
采样器W1从有标记的数据集Dk中采样一部分数据V,通过训练得到一个基本分类器F;
未标记的数据Du通过分类器F得到数据的label,再通过采样器w2采样部分数据U;
用数据 V 和 U 来训练模型 F;
通过验证集Dv在模型F上的效果来进行反向传播;
循环这个过程直到收敛,整个迭代学习的过程是元学习的思想。
二、类别不平衡
