数据挖掘(四)KNN
1.KNN 概述
k-近邻(kNN, k-NearestNeighbor)算法是一种基本分类与回归方法,我们这里只讨论分类问题中的 k-近邻算法。
一句话总结: 近朱者赤近墨者黑!
k 近邻算法的输入为实例的特征向量,对应于特征空间的点;输出为实例的类别,可以取多类。k 近邻算法假设给定一个训练数据集,其中的实例类别已定。分类时,对新的实例,根据其 k 个最近邻的训练实例的类别,通过多数表决等方式进行预测。因此,k近邻算法不具有显式的学习过程。
k 近邻算法实际上利用训练数据集对特征向量空间进行划分,并作为其分类的“模型”。 k值的选择、距离度量以及分类决策规则是k近邻算法的三个基本要素。
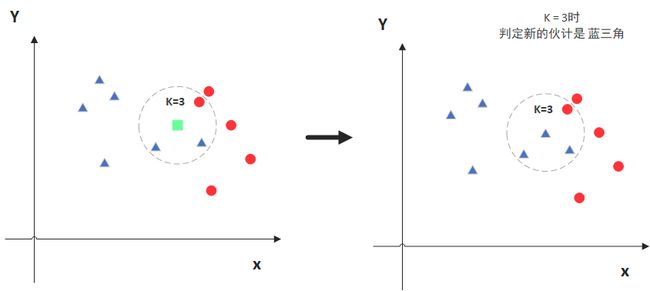
图中绿色的点就是我们要预测的那个点,假设K=3。那么KNN算法就会找到与它距离最近的三个点(这里用圆圈把它圈起来了),看看哪种类别多一些,比如这个例子中是蓝色三角形多一些,新来的绿色点就归类到蓝三角了。
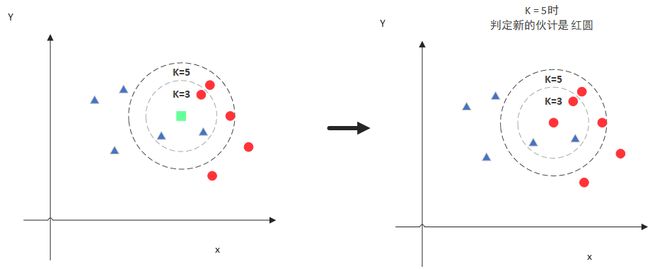
但是,当K=5的时候,判定就变成不一样了。这次变成红圆多一些,所以新来的绿点被归类成红圆。从这个例子中,我们就能看得出K的取值是很重要的。
2.KNN 场景
电影可以按照题材分类,那么如何区分 动作片 和 爱情片 呢?
- 动作片: 打斗次数更多
- 爱情片: 亲吻次数更多
基于电影中的亲吻、打斗出现的次数,使用 k-近邻算法构造程序,就可以自动划分电影的题材类型。
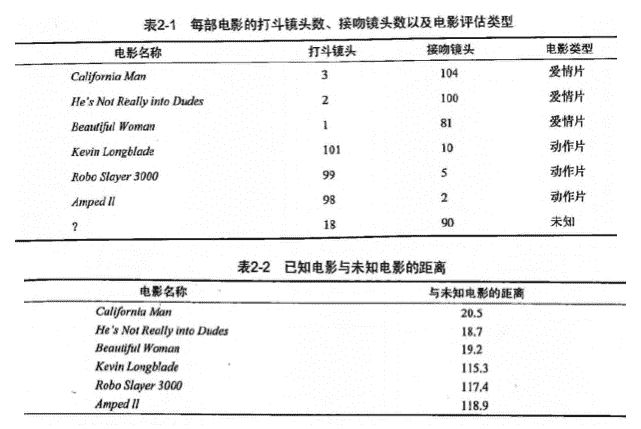
现在根据上面我们得到的样本集中所有电影与未知电影的距离,按照距离递增排序,可以找到 k 个距离最近的电影。
假定 k=3,则三个最靠近的电影依次是, He's Not Really into Dudes 、 Beautiful Woman 和 California Man。
knn 算法按照距离最近的三部电影的类型,决定未知电影的类型,而这三部电影全是爱情片,因此我们判定未知电影是爱情片。
3.KNN 原理
KNN 工作原理
- 假设有一个带有标签的样本数据集(训练样本集),其中包含每条数据与所属分类的对应关系。
- 输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行比较。
- 计算新数据与样本数据集中每条数据的距离。
- 对求得的所有距离进行排序(从小到大,越小表示越相似)。
- 取前 k (k 一般小于等于 20 )个样本数据对应的分类标签。
- 求 k 个数据中出现次数最多的分类标签作为新数据的分类。
KNN 通俗理解
给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的 k 个实例,这 k 个实例的多数属于某个类,就把该输入实例分为这个类。
KNN 开发流程
收集数据: 任何方法
准备数据: 距离计算所需要的数值,最好是结构化的数据格式
分析数据: 任何方法
训练算法: 此步骤不适用于 k-近邻算法
测试算法: 计算错误率
使用算法: 输入样本数据和结构化的输出结果,然后运行 k-近邻算法判断输入数据分类属于哪个分类,最后对计算出的分类执行后续处理
KNN 算法特点
优点: 精度高、对异常值不敏感、无数据输入假定
缺点: 计算复杂度高、空间复杂度高
适用数据范围: 数值型和标称型
4. KNN算法三要素
4.1 关于距离的衡量方法:具体介绍参见K-means介绍
KNN算法中要求数据的所有特征都可以做量化,若在数据特征中存在非数值类型,必须采用手段将其量化为数值。
在sklearn中,KNN分类器提供了四种距离
- 欧式距离(euclidean) - 默认
- 曼哈顿距离(manhatten)
- 切比雪夫距离(chebyshev)
- 闵可夫斯基距离(minkowski)
4.2 K值的选择问题
在KNN分类中,K值的选择往往没有一个固定的经验,可以通过不停调整(例如交叉验证)到一个合适的K值。
- K为1。如果K值被设定为1,那么训练集的正确率将达到100%(将训练集同时作为预测集),因为每个点只会找到它本身,但同时在预测集中的正确率不会太高(极度过拟合)。
- K为较小的值。较小的邻域往往会带来更低的训练误差,但会导致过拟合的问题降低预测集的准确率。
- K为较大的值。较大的邻域会增大训练误差,但能够有效减少过拟合的问题。(注意,这并不意味着预测集的准确率一定会增加)
- K为训练集样本数量。当K极端到邻域覆盖整个样本时,就相当于不再分类而直接选择在训练集中出现最多的类。
在实际应用中,K 值一般选择一个较小的数值,通常采用交叉验证的方法来选择最优的 K 值。随着训练实例数目趋向于无穷和 K=1 时,误差率不会超过贝叶斯误差率的2倍,如果K也趋向于无穷,则误差率趋向于贝叶斯误差率。(贝叶斯误差可以理解为最小误差)
三种交叉验证方法:
- Hold-Out: 随机从最初的样本中选出部分,形成交叉验证数据,而剩余的就当做训练数据。 一般来说,少于原本样本三分之一的数据被选做验证数据。常识来说,Holdout 验证并非一种交叉验证,因为数据并没有交叉使用。
- K-foldcross-validation:K折交叉验证,初始采样分割成K个子样本,一个单独的子样本被保留作为验证模型的数据,其他K-1个样本用来训练。交叉验证重复K次,每个子样本验证一次,平均K次的结果或者使用其它结合方式,最终得到一个单一估测。这个方法的优势在于,同时重复运用随机产生的子样本进行训练和验证,每次的结果验证一次,10折交叉验证是最常用的。
- Leave-One-Out Cross Validation:正如名称所建议, 留一验证(LOOCV)意指只使用原本样本中的一项来当做验证资料, 而剩余的则留下来当做训练资料。 这个步骤一直持续到每个样本都被当做一次验证资料。 事实上,这等同于 K-fold 交叉验证是一样的,其中K为原本样本个数。
4.3 分类决策的准则
明确K个邻居中所有数据类别的个数,将测试数据划分给个数最多的那一类。即由输入实例的 K 个最临近的训练实例中的多数类决定输入实例的类别。
最常用的两种决策规则:
- 多数表决法:多数表决法和我们日常生活中的投票表决是一样的,少数服从多数,是最常用的一种方法。
- 加权表决法:有些情况下会使用到加权表决法,比如投票的时候裁判投票的权重更大,而一般人的权重较小。所以在数据之间有权重的情况下,一般采用加权表决法。
多数表决法图示说明(其中K=4):

5. KNN算法的步骤
输入: 训练数据集 T = { ( x 1 , y 1 ) , ( x 2 , y 2 ) … . . . ( x N , y N ) } , x 1 T=\left\{\left(\mathrm{x}_{1}, \mathrm{y}_{1}\right),\left(\mathrm{x}_{2}, \mathrm{y}_{2}\right) \ldots . . .\left(\mathrm{x}_{\mathrm{N}}, \mathrm{y}_{\mathrm{N}}\right)\right\}, \mathrm{x}_{1} T={(x1,y1),(x2,y2)…...(xN,yN)},x1 为实例的特征向量, y i = { c 1 , c 2 , … c k } \mathrm{yi}=\left\{\mathrm{c}_{1}, \mathrm{c}_{2}, \ldots \mathrm{c}_{k}\right\} yi={c1,c2,…ck} 为实剅类别。
输出: 实例 x \mathrm{x} x 所属的类别 y \mathrm{y} y 。
步骤:
- 选择参数 K K K
- 计算末知实例与所有已知实例的距离 (可选择多种计算距离的方式)
- 选择最近 K K K 个已知实例
- 根据少数服从多数的投眎法则(majority-voting), 让末知实例归类为 K \mathrm{K} K 个最邻近样本中最多数的类别。加权表决法同理。
6.K-Means与KNN有什么区别
-
KNN
- KNN是分类算法
- 监督学习
- 喂给它的数据集是带label的数据,已经是完全正确的数据
- 没有明显的前期训练过程,属于memory-based learning
- K的含义:来了一个样本x,要给它分类,即求出它的y,就从数据集中,在x附近找离它最近的K个数据点,这K个数据点,类别c占的个数最多,就把x的label设为c
-
K-Means
- 1.K-Means是聚类算法
- 2.非监督学习
- 3.喂给它的数据集是无label的数据,是杂乱无章的,经过聚类后才变得有点顺序,先无序,后有序
- 有明显的前期训练过程
- K的含义:K是人工固定好的数字,假设数据集合可以分为K个簇,由于是依靠人工定好,需要一点先验知识
-
相似点
- 都包含这样的过程,给定一个点,在数据集中找离它最近的点。即二者都用到了NN(Nears Neighbor)算法,一般用KD树来实现NN。
7.实验
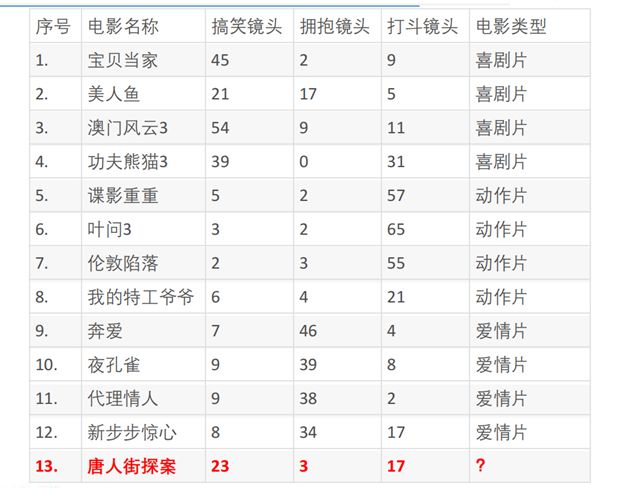
from sklearn.neighbors import KNeighborsClassifier
train_x = [[45, 2, 9],
[21, 17, 5],
[54, 9, 11],
[39, 0, 31],
[5, 2, 57],
[3, 2, 65],
[2, 3, 55],
[6, 4, 21],
[7, 46, 4],
[9, 39, 8],
[9, 38, 2],
[8, 34, 17]]
train_y = ['喜剧片', '喜剧片','喜剧片','喜剧片',
'动作片', '动作片','动作片','动作片',
'爱情片','爱情片','爱情片','爱情片',]
#构建knn分类模型,并指定 k 值
KNN=KNeighborsClassifier(n_neighbors=3)
#使用训练集训练模型
KNN.fit(train_x,train_y)
#评估模型的得分
score=KNN.score(train_x,train_y)
print(score)
x_test=[[23,3,17]]
predict_result=KNN.predict(x_test)
print(predict_result)
knn与kmeans区别