【Python & 数据挖掘】KNN算法
一、前言
今天是10.24程序员节,赶在一天最后的小尾巴来写一篇关于KNN算法的博客,同时祝大家节日快乐!
二、算法思想
1、K近邻分类方法的基本思路是:
不对预先的训练数据集进行任何处理,当测试一个新来的数据属于哪个类时,计算下它与训练集中所有实例的距离,从中选出K个距离最小(近)的实例,统计下这K个实例属于哪个类的最多,就将新来的数据归为哪一类。
谚语:“走路像鸭子,叫起来像鸭子,看起来像鸭子,那它很可能就是鸭子”。
2、例子
举例来说,如果我们有下面的训练集,其中每个实例有5个属性,最后一列标出了它们属于哪一类?
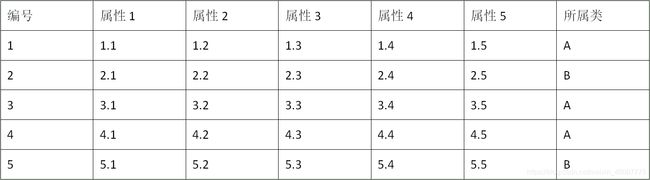
假设现在有一个新数据(2.11,2.21,2.22,2.23,2.24,2.25),我们取K = 3,在训练集中与它距离最近的三个实例肯定是实例1,2,3,其中两个属于A类,一个属于B类,那我们就将新数据归为A类。
三、Python实现
代码:
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Time : 2020/10/23 17:23
# @Author : Up_Long
# @FileName: 4-1.py
# @Software: PyCharm
# KNN算法
'''
KNN的原理就是当预测一个新的值x的时候,根据它距离最近的K个点是什么类别来判断x属于哪个类别。
距离计算:
欧几里德距离,KNN算法最简单粗暴的就是将预测点与所有点距离进行计算,然后保存并排序,选出前面K个值看看哪些类别比较多。
'''
import csv
import math
import random as rd
import operator
import numpy as np
# 读文件
def read(filename, split=0.7):
# 定义训练集和测试集列表
trainLines = []
testLines = []
# 读文件并划分集合
with open(filename, 'r', encoding='UTF-8') as f:
lines = csv.reader(f)
lines = list(lines)
for x in range(len(lines) - 1):
for y in range(np.array(lines).shape[1]): # 将数据转为float类型,以便使用pow函数计算欧几里得距离(pow函数计算时需要两个变量为int或者float类型)
lines[x][y] = float(lines[x][y])
if rd.random() < split:
trainLines.append(lines[x])
else:
testLines.append(lines[x])
return trainLines, testLines
# 计算欧几里德距离
def distances(instance1, instance2, length): # 单个测试数据,单个训练数据,单个数据去掉列表元素后的长度
distance = 0
for x in range(length): # 单个数据各个元素相减求平方后累加,得到距离
distance += pow((instance1[x] - instance2[x]), 2)
return math.sqrt(distance)
# 求k个邻近数据
def neighbors(train, test, k): # train,单个test数据,k
distance = [] # 定义存放距离数据的列表
length = len(test) - 1 # 去掉最后一个元素求长度,最后一个元素存放该数据的类别
for x in range(len(train)): # 遍历训练集,得到训练集每个数据与单个测试集距离列表
dist = distances(train[x], test, length)
distance.append((train[x], dist)) # 不断将测试集数据和dist数据以元祖形式存入列表中
distance.sort(key=operator.itemgetter(1)) # 根据dist数据值进行排序
neighbors = [] # 定义存放k个临近数据的列表
for x in range(k):
neighbors.append(distance[x][0]) # 取距离列表中的每个元祖第一个元素,即每个训练集数据
return neighbors
# 求最相似类别
def response(neighbors):
classVotes = {}
for x in range(len(neighbors)):
response = neighbors[x][-1] # 获取每个数据的类别(数据最后一列存放该数据的类别)
if response in classVotes: # 统计k个邻近数据中,每个类别的数据个数
classVotes[response] += 1
else:
classVotes[response] = 1
sortVotes = sorted(classVotes.items(), key=operator.itemgetter(1), reverse=True) # 按照每个类别的个数进行降序排序
return sortVotes[0][0] # 返回最相似的类别对应名称
# 测试集预测准确性测试
def accuracy(test, predictions):
correct = 0
for x in range(len(test)):
if test[x][-1] == predictions[x]:
correct += 1
return (correct / float(len(test))) * 100.0
# 主函数
def main():
train = []
test = []
split = 0.70
# 按split的比例划分训练集和测试集
train, test = read('knn_data.csv', split)
print('Train set:' + repr(len(train)))
print('Test set:' + repr(len(test)))
preditions = []
k = 3
# 训练
for x in range(len(test)):
neighbor = neighbors(train, test[x], k) # 得到训练集与单个测试数据的k个邻近数据
result = response(neighbor) # 对单个测试数据的k个邻近数据进行统计,得到最相似的类别
preditions.append(result) # 将每个预测的最相似类别保存到预测列表中
print('predicted=' + repr(result) + ',actual=' + repr(test[x]))
# 预测
acc = accuracy(test, preditions) # 遍历测试集,对比测试集类别和预测列表中的类别是否一样,并返回预测准确率
print('Accuracy:' + repr(acc) + '%')
if __name__ == '__main__':
main()