机器学习-决策树概述及对鸢尾花数据分类python实现利用graphviz模块画出决策树
文章目录
-
- 1. 决策树概述
- 2. 理论分析
-
-
- 2.1 特征选择
-
- 2.1 1 熵&条件熵
- 2.1.2 信息增益
- 2.1.3 信息增益比
- 2.2 决策树的生成
-
- 2.2.1 ID3算法
- 2.2.2 C4.5算法
- 2.2.3 决策树的修剪
-
- 3. python实现
-
-
- 3.1 数据集
- 3.2 python代码
- 3.3 运行结果
-
1. 决策树概述
决策树(decision tree)是一种基本的分类与回归方法,在分类问题中,表示基于特征对实例进行分类的过程。学习时,利用训练数据,根据损失函数最小化的原则建立决策树模型;预测时,对新的数据,利用决策树模型进行分类。决策树的学习通常包括3个步骤:特征选择、决策树的生成和决策树的修剪。
决策树算法的基本思想:递归地选择最优特征,并根据该特征对训练数据进行分割,使得各个子数据集有一个最好的分类的过程。这个过程就是特征空间的划分,也是决策树的构建。
2. 理论分析
2.1 特征选择
通过信息增益或信息增益比,选择对数据分类影响最大的特征,即在这个最有特征的选择下,子集合有着最好的分类。信息增益和信息增益比涉及熵的概念。
2.1 1 熵&条件熵
在信息论、概率统计、通信原理中,熵(entropy)是表示随机变量不确定性的度量。设是一个取有限个值得离散随机变量,其分布概率 P ( X = x i ) = p i P(X=x_{i})=p_{i} P(X=xi)=pi,随机变量 X X X的熵定义为:
H ( X ) = − ∑ i = 1 n p i log p i ⋯ ⋯ i = 1 , 2 , … , n H(X)=-\sum_{i=1}^{n} p_{i} \log p_{i} \cdots \cdots i=1,2, \ldots, n H(X)=−i=1∑npilogpi⋯⋯i=1,2,…,n
熵只依赖于 X X X的分布,而与 X X X的取值无关,所以将 X X X的熵记做:
H ( p ) = − ∑ i = 1 n p i log p i H(p)=-\sum_{i=1}^{n} p_{i} \log p_{i} H(p)=−i=1∑npilogpi
设随机变量 ( X , Y ) (X,Y) (X,Y),其联合概率分布为: P ( X = x i , Y = y i ) = p i j , ⋅ i = 1 , 2 , … , n P\left(X=x_{i}, Y=y_{i}\right)=p_{i j}, \cdot i=1,2, \ldots, n P(X=xi,Y=yi)=pij,⋅i=1,2,…,n 。条件熵 H ( Y ∣ X ) H(Y|X) H(Y∣X)表示在已知随机变量 X X X的条件下随机变量 Y Y Y的不确定性。随机变量 X X X给定的条件下随机变量 Y Y Y的条件熵(conditional entropy) H ( Y ∣ X ) H(Y|X) H(Y∣X),定义为 X X X给定条件下 Y Y Y的条件概率分布的熵对 X X X的数学期望:
H ( Y ∣ X ) = − ∑ i = 1 n p i H ( Y ∣ X = x i ) , ⋯ p i = P ( X = x i ) , ⋯ i = 1 , 2 , … , n H(Y \mid X)=-\sum_{i=1}^{n} p_{i} H\left(Y \mid X=x_{i}\right), \cdots p_{i}=P\left(X=x_{i}\right), \cdots i=1,2, \ldots, n H(Y∣X)=−i=1∑npiH(Y∣X=xi),⋯pi=P(X=xi),⋯i=1,2,…,n
当熵和条件熵中的概率是由数据估计(特别是极大似然估计)得到时,所对应的熵与条件熵分别称为经验熵(empirical entropy)和经验条件熵(empirical conditional entropy)
2.1.2 信息增益
信息增益(information gain)表示得知特征 X X X的信息而使得类 Y Y Y的信息的不确定的减少程度。即特征 A A A对训练数据集 D D D的信息增益 g ( D , A ) g(D,A) g(D,A),定义为集合 D D D的经验熵 H ( D ) H(D) H(D)与特征 A A A给定条件下 D D D的经验条件熵 H ( D ∣ A ) H(D|A) H(D∣A)之差:
g ( D ∣ A ) = H ( D ) − H ( D ∣ A ) g(D|A)=H(D)-H(D|A) g(D∣A)=H(D)−H(D∣A)
表示由于特征 A A A而使得对数据集 D D D的分类的不确定性减少的程度,信息增益大的特征,具有更强的分类特征。
2.1.3 信息增益比
特征 A A A对训练数据集 D D D的信息增益 g R ( D , A ) g_{R}(D,A) gR(D,A)比,定义为信息增益 g ( D , A ) g(D,A) g(D,A)与训练数据集 D D D关于特征A的值得熵 H A ( D ) H_{A}(D) HA(D)之比:
g R ( D , A ) = g ( D , A ) H A ( D ) g_{R}(D, A)=\frac{g(D, A)}{H_{A}(D)} gR(D,A)=HA(D)g(D,A)
其中, H A ( D ) = − ∑ i = 1 n log 2 ∣ D i ∣ ∣ D ∣ H_{A}(D)=-\sum_{i=1}^{n} \log _{2} \frac{\left|D_{i}\right|}{|D|} HA(D)=−∑i=1nlog2∣D∣∣Di∣, n n n是特征 A A A取值的个数。
2.2 决策树的生成
2.2.1 ID3算法
ID3算法澳洲计算机科学家Ross Quinlan发明的,全称是Iterative Dichotomiser 3。其算法的核心是在决策树的各个结点上应用信息增益准则选择特征,递归地构建决策树。从根节点开始,对接点计算所有可能特征的信息增益,选择信息增益最大的特征作为结点的特征,由该特征的不同取值建立子结点,再对子节点递归地调用以上方法,构建决策树,直到所有特征的信息增益均很小或者没有特征可以选择为止。
2.2.2 C4.5算法
在ID3算法上进行了改进,用信息增益比来选择特征。规避了以信息增益作为划分准则,偏向选取值较多的特征的问题。
2.3 CART算法
分类与回归树,CART(classification and regression tree),其本质是二分类树。CART是在给定输入随机变量条件下输出随机变量的条件概率分布的学习方法。CART假设决策树二叉树,内部结点特征的取值为“是”和“否”,左分支是取值为“是”的分支,右分支是取值为“否”的分支。这样的决策树等价于递归地二分每个特征,将输入空间及特征空间划分为有限个单元,并在这些单元上确定预测的概率分布,也就是在输入给定的条件下输出的条件概率分布。
2.2.3 决策树的修剪
通过训练模型产生的决策树,对测试数据的分类效果不确定,会产生过拟合现象,构建过于复杂的决策树。这是需要对已经生成的决策树进行简化,即剪枝(pruning)。减掉已经生成的某些子树,或叶结点。
3. python实现
3.1 数据集
选用iris数据集作为本次训练测试的数据,通过使用sklearn.tree.DecisionTreeClassifier()使用CART算法,对iris数据进行分类。
3.2 python代码
from sklearn import tree #导入决策树
from sklearn.datasets import load_iris #导入datasets创建数组
from sklearn.model_selection import train_test_split #数据集划分
import graphviz #导入决策树可视化模块
iris = load_iris()#鸢尾花数据集
iris_data=iris.data #选择训练数组
iris_target=iris.target #选择对应标签数组
clf = tree.DecisionTreeClassifier() #创建决策树模型
clf=clf.fit(iris_data,iris_target) #拟合模型
dot_data = tree.export_graphviz(clf, out_file=None) #以DOT格式导出决策树
graph = graphviz.Source(dot_data) #直接使用Source类来直接实例化一个Source对象, 传入的参数就是dot源码, 然后可以调用render方法渲染
graph.render(r'iris') #使用garphviz将决策树渲染PDF,文件名叫iris
X_train, X_test, y_train, y_test = train_test_split(iris_data, iris_target, test_size=0.2)
clf.fit(X_train, y_train,)
print('分类准确率:',clf.score(X_test, y_test))
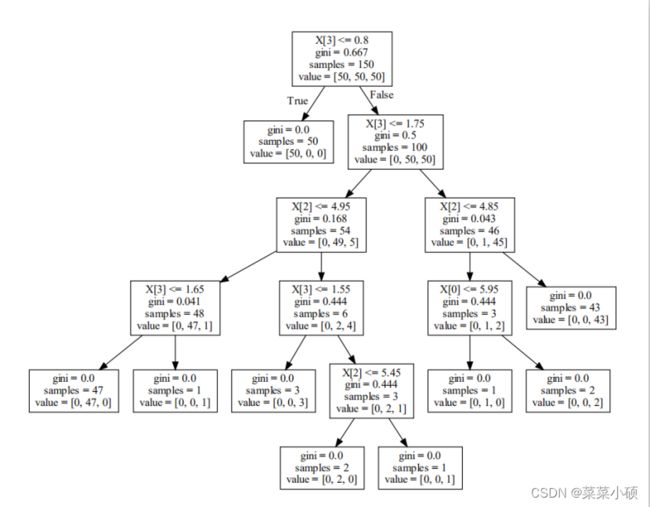
3.3 运行结果
通过graphviz模块导入pdf,生成DOT文件可视化决策树。