SAS基础 2021/10 回顾
SAS 2021/10 回顾
SAS
1.书本知识回顾
变量(数值型/字符型/日期型):名称、类型、长度、输入格式、输出格式、标签
常量/运算符/表达式/语句
1.1 语句
- 数据步: DATA — 数据管理
常见:FILE/PUT/LENGTH/LABEL/KEEP/DROP/WHERE/SET/MERGE/BY/RENAME……
复制与修改/合并(纵向/横向:先排序SORT+BY)/拆分
控制语句:
条件:IF-THEN/IF-THEN-DO/IF-THEN-ELSE/SELECT(3个条件以上)
SELECT..; WHEN 1; WHEN 2; WHEN 3; ....;OTHERWISE N; END;
循环:DO/DO-WHILE/DO-UNTIL
DO V=A TO N BY 步长; 循环内容; LEAVE; END; RUN /LEAVE用于跳出循环/
DO WHILE(继续条件);内容;END;
DO UNTIL(退出条件);内容;END;
……
- 过程步: PROC — 统计分析
其他:CLUSTER/PRINCOMP/FACTOR/TABULATE/GCHART/
GRAPH/CANCORR//DISCRIM/STEPDISC/LIFEREG/LIFETEST/…
| MEANS | FREQ | UNIVARIATE | SORT | 常见 |
|---|---|---|---|---|
| TTEST | ANOVA | LOGISTIC | GLM | 常用 |
| REG | CORR |
常用搭配:
| VAR | OUTPUT | BY |
|---|---|---|
| CLASS | WHERE | ID |
| FREQ | MODEL | LABEL |
| FORMAT | WEIGHT | NOOBS |
CLASS 分组 VS. SORT…BY 分组
注意事项:字符型/数值型–$
INPUT—把字符串转成数值型、日期型(取决于第二个句子format.)
PUT 相反
1.2 SAS 函数
数学函数/统计函数/概率分布函数/随机函数/分位数函数/字符串函数
| 数学函数 | 统计函数 | 字符函数 | 概率分布函数 | 分位数函数 | 随机数函数 |
|---|---|---|---|---|---|
| MAX | MEAN | TRIM(s)去除空格 | PROBNORM | PROBIT | RANUNI |
| MIN | N(非缺失数) | UPCASE(s)大写转小写 | PROBT | NORMAL | |
| MOD | NMISS | LOWCASE(s)小写转大写 | PROBCHI | ||
| SQRT | SUM | LENGTH(s)长度 | PROBF | ||
| CELL | VAR | SUBSTR(s,p,n)从s中第p处取n个字符 | PROBBETA | ||
| FLOOR | STD | REVERSE(s)s的反转结果 | PROBBNML | ||
| INT | CV | TRANWRD(s,s1,s2)s1全部替换成s2 | POISSON | ||
| ROUND | RANGE | INDEX(s,s1)返回s1的位置/无则为0 | |||
| COMPRESS(s,修饰符)保留或删除字符 |
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jlqi12XA-1634542493967)(C:\Users\shiyanshi\AppData\Roaming\Typora\typora-user-images\image-20211016171217288.png)]
1.3 描述性统计分析
集中趋势:样本数/均值/中位数/众数/百分位数
离散程度:极差/方差/标准差/变异系数
分布:偏度/峰度
SAS: MEANS — 给出:N,MEAN, STD, MAX, MIN+ 说明指标
SAS: UNIVARIATE — 给出:描述性统计量/统计测度/位置检验(t/符号秩和检验)/各分位数/观测最高与低的5个
1.4 列联表分析
| 变量 | 相关性分析 | 条件 |
|---|---|---|
| 连续变量 | ||
| 分类变量(属性) | 无序 | n≥40: 单元期望频数 < 5,Pearson卡方; |
| 小样本<40: Fisher精确检验 | ||
| 有序 | Gamma系数 | |
| Tau-c系数 |
2X2中:n≥40:卡方(T:1-5), Fisher(T=1);n<40:Fisher ;
SAS: FREQ
PROC FREQ [];
TABLES [];/*默认频数+百分比*;举例:X1*X2/CHISQ */
BY [];
OUTPUT []...;
WEIGHT;/*作为观测权重的变量*/
1.5 统计推断:参数估计+假设检验
统计推断 — 从总体中抽取部分进行样本抽查进行估计与推断
参数估计 — 通过样本观测值进行统计推断总体重点位置参数
| 参数估计 | 条件 | |
|---|---|---|
| 点估计 | 某个适当统计量的观测值作为某未知参数的估计值 | |
| 区间估计 | 在点估计的基础上,给一个参数区间估计总体参数,给出可靠度即置信区间100(1-α)%,α是区间估计的显著性水平 | 均值μ |
| 方差 |
假设检验 — 显著性检验;先做参数或分布的某种假设再检验统计量;根据其大小拒绝or接受
流程:建立零假设H0;备择假设H1----建立统计分布、统计量、概率-----给定α、决定结果
| 假设检验 | 已知 | 未知 | 方法 |
|---|---|---|---|
| 参数检验 | 分布 | 总体参数 | t检验 |
| 非参数检验 | 分布、参数 | 秩和检验 |
SAS:TTEST— 独立/成对/两独立样本T;
两组时考虑方差齐性
PROC TTEST [];
CLASS/PAIRED;
VAR [];
RUN;
1.6 方差分析ANOVA
几因素方差分析:观测变量受两类因素调控—因素变量+随机变量
- 单因素方差分析
F值,P值+方差齐性,多重比较

- 多因素方差分析
考虑交互作用、几因素、

SAS : ANOVA, GLM
ANOVA 交互式 ;需要用QUIT语句结束
MODEL:模型选择
| 主效应模型 | y= a b | |
| 交互效应模型 | y= abc aXb aXc bXc aXbXc | |
| 嵌套设计模型 | y= a b c (a c) |
多重比较检验MEANS: LSD;TUKEY;SNK;…
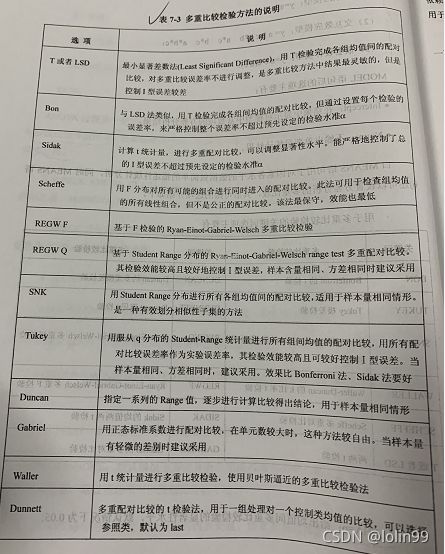
GLM过程 (非均衡数据做方差
PROC GLM;
CLASS [];
MODEL [];
MEANS C/SNK;
RUN;
QUIT;
EMS:误差均方
拉丁方设计/析因设计/正交设计/……
1.7 非参数统计分析
不服从正态分布、未知总体
| 类型 | 方法 | 过程步 |
|---|---|---|
| 单样本 | 符号检验;Wilcoxon符号秩和检验; | UNIVARIATE |
| 两个样本 | 独立:Wilcoxon秩和检验;中位数检验;VW;… | NPAR1WAY |
| 配对:符号检验;Wilcoxon符号秩和检验; | UNIVARIATE(预处理差值DIFF) | |
| 多个样本 | KS检验;中位数检验 | NPAR1WAY |
1.8 相关分析
有关联不存在确定性的关系 |r| ≤1
相关系数指标:Peason(两变量线性相关);Spearman(利用两变量的rank大小作线性相关) ;Kendall t(分类变量相关性;有序分类);……
偏相关系数:
SAS: CORR
PROC CORR
BY [];
FREQ [];
PARTIAL []; /*偏相关*/
VAR [];
WEIGHT [];
RUN;
典型相关分析
1.9 回归分析
- 线性回归(一元/多元
回归方程统计检验:一元中:拟合优度R2统计量,[0,1] 1:说明拟合优度高;多元中:Adjusted R2
回归方程显著性检验ANOVA:检验各自变量的回归系数是否为0;
回归系数的显著性检验:
残差分析:正态性/异方差/
其他:变量筛选(向前/向后/逐步);多重共线性(测量方法:容忍度,方差膨胀因子VIF,特征根和方差比,条件指数)
SAS REG
PROC REG [];
MODEL Y=Xn/[];
WEIGHT [];
BY [];
ID [];
OUTPUT OUT = DATASET KEYWORD = V;
PLOT Y*X="";/*散点图*/
RUN;
MODEL: CLI(预测值上下置信区间); CLM(因变量的置信区间); R(残差分析); P(计算回归预测模型);
SIMPLE:简单统计数 ;CORR:计算相关系数;
逐步回归算法:MODEL Y=Xn/ SELECTION= STEPWISE;
- 非线性回归
NLN过程
- LOGISTIC回归
Y:0/1变量;回归系数:考虑发生比;回归方程:似然比检验;回归系数检验:Wald统计量;拟合优度检验:OR值L:exp(B)
定性变量需要先哑变量操作后进行回归分析
SAS LOGISTIC
PROC LOGISTIC [];
BY [];
CLASS [];
FREQ [];
MODEL 变量[]=[效应]/[];
WEIGHT [];
OUTPUT OUT = [];
可加上:
ORDER 因变量水平顺序
SLE = 概率值(进入回归模型的显著水平); SLS= 概率值(保留回归模型的显著水平);
1.10 聚类分析
性质相近则归为一类
“亲疏程度”:个体间的相似程度;个体间的差异程度
| 变量 | 方法 | 解释 |
|---|---|---|
| 定量 | 欧氏距离/平方欧式距离 | |
| 二值 | 简单匹配/Jaccard雅科比系数 |
- 系统聚类
样本聚类(Q型);变量聚类(R型)
SAS CLUSTER
也可利用PROC TREE语句画谱系图
- 快速聚类
SAS FASTCLUS (不调整分类的结果)
1.11 主成分分析
降维,用较少的几个综合变量来解释原始数据的大部分变异;每个主成分为原始变量的线性组合(方差Var最大的几个,按累积贡献率取前k个包含80%以上的信息且特征值大于1即可)
SAS PRINCOMP
1.12因子分析
在主成分的基础上,不仅注意变量之间是否相关,而且考虑相关关系的强弱(因子载荷)
SAS FACTOR
1.13判别分析
根据已知样本的分类及所测定的指标,筛选出能够提供较多信息的指标,建立判别函数,使判错率最小从而实现对未知数据分类数据的判断。
一般判别:Fisher判别:多维投影到一维,基于类别之间的距离/Bayes判别:根据所属类的概率
SAS DISCRIM
典型判别分析–SAS CANDISC
逐步判别回归–SAS STEPDISC
1.14 生存分析
参数法:指数分布法,logistic回归分析
半参数法:Cox模型分析法
SAS LIFEREG
对指数分布、Weibull分布等拟合生存函数模型
PROC LIFEREG [];
MODEL Y[*截尾变量]=X效应[/选项];
OUTPUT OUT 关键词= [];
CLASS ;
PLOTS= [];/*概率图
RUN;
LIFETEST检验
两种秩检验:对数秩检验(Log-rank test),Wilcoxn检验;似然比方法检验两组或以上
PROC LIFETEST;
METHOD= ;/*PLIKM(默认),*/
TIME 生存时间因变量*截尾变量;
TEST ;
STRATA ;
FREQ ;
RUN;
SAS PHREG 半参数COX比例风险模型
PROC PHREG[];
MODEL 生存时间因变量[*截尾变量]=X效应[/选项];
STRATA [] ;
FREQ [];
BY [];
RUN;
1.15图形
- GPLOT: 散点图、曲线图、线图
- GCHART: 水平条形图、垂直条形图、饼图
- 茎叶图、QQ图(UNIVARIATE-plot)
PROC GPLOT[];
PLOT Y*X[]/[];
PLOT2 Y*X[]/[];
SYMBOLn [];
RUN;
V=;数据点图形符号
I=;数据点连接方式
COLORIC=;颜色