hive sql 基本命令总结
一、hive简介
hive是基于Hadoop的一个数据仓库工具,用来进行数据提取、转化、加载,这是一种可以存储、查询和分析存储在Hadoop中的大规模数据的机制。hive可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能;可以将SQL语句转换为MapReduce任务运行,通过自己的SQL查询分析需要的内容,这套SQL简称Hive SQL。
二、hive sql与sql的区别
其实不同的数据库,比如oracle和mysql在sql语句上也有细微差别。Hive-sql与SQL基本上一样。一般情况下大胆使用SQL语句的,如果遇到不对的,再查;
hive sql固有的一些特点入下:
- Hive SQL不支持行级别的增、改、删,所有数据在加载时就已经确定,不可更改;
- 不支持等值连接,一般使用left join、right join 或者inner join替代;
- hive中不用not null ,SQL中有not null,hive 中用left join 代替 not null;
- hive不支持INSERT INTO 表 Values(), UPDATE, DELETE操作;
- hive sql包含一些复合字段类型,比如struct, array, map
- hive sql 包含一些collect_list,concat_ws等特殊功能函数,而且这些函数对于数据处理很有用
三、waterdrop简介
Waterdrop是为开发人员和数据库管理人员提供的数据库管理工具,它可进行跨平台管理,可作为Inceptor SQL客户端,除了Inceptor还支持并兼容其余多种数据库。它具有有四个功能模块:Database Navigator、SQL Editor、SQL Executor、Data Viewer/Eidtor,分别用来帮助用户实现数据库管理、SQL编 辑、SQL执行、数据操作这四项功能。总的来说,就是一个数据库管理软件,类似于navicat以及debaver等可视化管理工具。
四、hive sql基本命令
4.1 partition by 和group by的区别联系
- group by是分组函数,而partition by是分析函数,(sum()等是聚合函数);
- partiton by 应用在关键字之后,也就是在执行完select结果集之上进行partition;
- group by 是对检索结果单纯分组,一般会和聚合函数一块用,partition by 属于分析函数
- 比如 sum() group by 将分组内的某字段求和,只显示求和结果记录。而sum() over (partition by …)则是计算组中表达式的累计和
SELECT aa.uid,sum(aa.addr_no)
FROM stg.t_018_doc_address_spec_organization AS aa
GROUP BY aa.uid
输出结果为:

SELECT aa.uid,sum(aa.addr_no) over (partition by aa.uid order BY aa.addr_no) as sum
FROM stg.t_018_doc_address_spec_organization AS aa
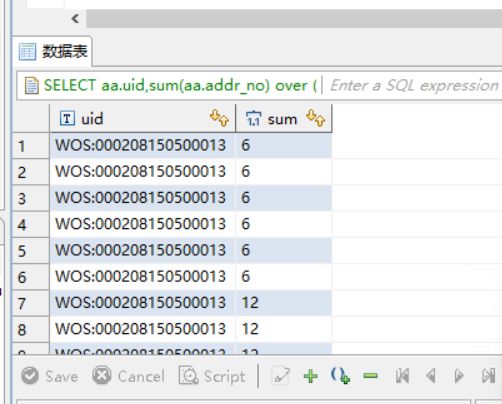
综上所述,可以理解为group by分组聚合结果唯一,partition by分组聚合结果显示全部行数据的记录记过,sum函数表现为累加求和。
partition by 通常和row_number() over一起使用,可以对分组内记录进行按照某一字段排序进行编号。
比如:
SELECT aa.uid,aa.org_name,aa.addr_no,row_number() over (partition by aa.uid order BY aa.才o) as rn
FROM stg.t_018_doc_address_spec_organization AS aa
按uid分组,按照addr_no地址序号排序进行编号,执行结果如下:
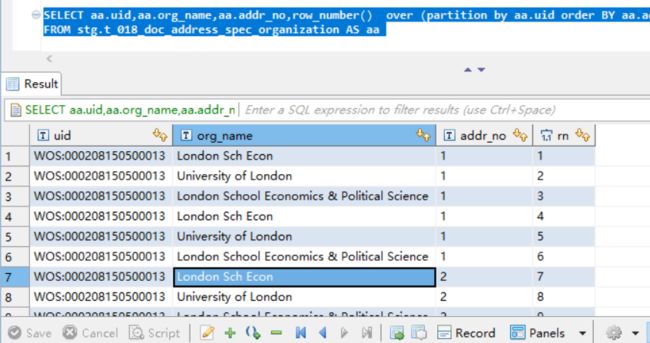
进一步结合where筛选可以实现单字段去重。
4.2 collect_list/collect_set函数实现列转行
- 相同点:将分组中的某列转换为一个数组返回;
- 不同点:collect_list不去重,而collect_set会去重;
具体可以参看博客: - Hive笔记之collect_list/collect_set(列转行)
4.3 concat/concat_ws函数
- 相同点:函数用于将多个字符串连接成一个字符串。
- 不同点:conncat默认使用‘,’作为分隔符,而concat_ws可以指定分隔符,CONCAT_WS(separator,str1,str2,…)
上述两个函数可以用于字符数组类型拼接为字符串,从而方便数据表的导出。
五、hive sql实战,从五张表中处理关联出需要的字段
5.1 需求分析
主要目标是从五张表中关联出需要的字段。
- 主表:stg.t_018_doc_meta,包含字段:first_author_full_name,uid,title,pubyear,source;
- 从表:stg.t_018_doc_address_spec_organization(论文地址机构表),由于每篇论文对应多个机构,需要对uid字段去重,并保留按地址序号顺序排名的第一条记录,进一步创建中间表:stg.t_018_doc_uid_organization,需求字段:uid,org_name;
- 从表:stg.t_018_doc_name,需要按照uid字段分组,将分组之后的display_name字段累加成行,用到collect_list函数。进一步创建中间表:stg.t_018_doc_author,需求字段:uid,author
- 从表: stg.t_018_doc_keyword,按照uid字段分组,将分组之后的keyword字段累加成行。创建中间表:stg.t_018_doc_keyword2,需求字段:uid,keyword
- 从表:stg.t_018_doc_abstract_text_paragraph,分组累加,创建中间表:stg.t_018_doc_abstract,需求字段:uid,abstract
进一步利用uid字段来关联五张表,从而得到需求字段:
5.2 hive sql脚本
--创建论文id机构对应表
CREATE TABLE stg.t_018_doc_uid_organization
AS
(
select t.uid,t.org_name,t.addr_no
from
(SELECT aa.uid,aa.org_name,aa.addr_no,row_number() over (partition by aa.uid order BY aa.addr_no) as rn
FROM stg.t_018_doc_address_spec_organization AS aa ) AS t
WHERE t.rn =1
);
--select count(distinct t.uid) from stg.t_018_doc_address_spec_organization AS t
--创建论文作者对应表
CREATE TABLE stg.t_018_doc_author
AS
(
SELECT aa.uid,collect_list(aa.display_name) AS author
FROM stg.t_018_doc_name AS aa group by aa.uid
);
--创建论文关键词对应表
CREATE TABLE stg.t_018_doc_keyword2
AS
(
SELECT aa.uid,collect_list(aa.doc_keyword) AS keyword
FROM stg.t_018_doc_keyword AS aa group by aa.uid
);
--创建论文摘要对应表
CREATE TABLE stg.t_018_doc_abstract
AS
(
SELECT aa.uid,collect_list(aa.abstract_text) AS abstract
FROM stg.t_018_doc_abstract_text_paragraph AS aa group by aa.uid
);
--关联五张表得到消歧数据表
CREATE TABLE stg.t_018_sci_disamb
AS
(
SELECT aa.first_author_full_name,aa.uid,dd.author,aa.title,bb.abstract,cc.keyword,ee.org_name,aa.pubyear,aa.source
FROM stg.t_018_doc_meta AS aa
LEFT JOIN stg.t_018_doc_abstract AS bb
ON aa.uid=bb.uid
LEFT JOIN stg.t_018_doc_keyword2 AS cc
ON aa.uid = cc.uid
LEFT JOIN stg.t_018_doc_author AS dd
ON aa.uid = dd.uid
LEFT JOIN stg.t_018_doc_uid_organization AS ee
ON aa.uid = ee.uid
);
--将字符数组字段,按照分隔符转为字符串字段(否则无法成功导出)
CREATE TABLE stg.t_018_sci_disamb_string
AS
(
SELECT aa.first_author_full_name,aa.uid,concat_ws('|',aa.author) AS author,aa.title,concat_ws(',',aa.abstract) AS abstract,concat_ws(',',aa.keyword) AS keyword,aa.org_name,aa.pubyear,aa.source
from stg.t_018_sci_disamb AS aa
);
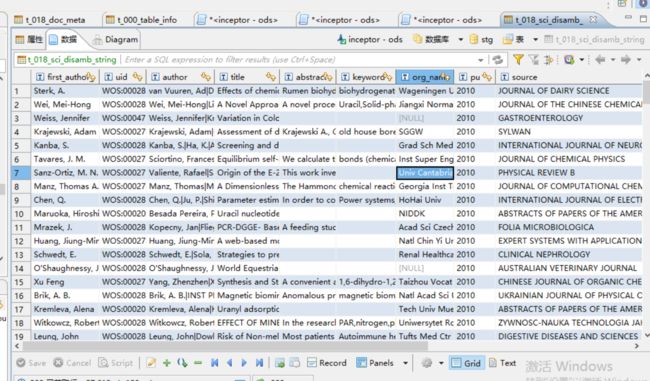
5.3 结果展示
运行上述sql脚本,可以得到最终最终筛选的结果表如下: